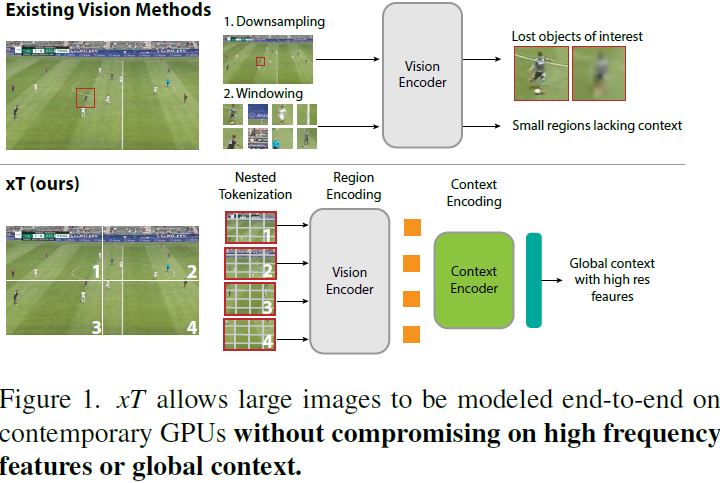
xT: Nested Tokenization for Larger Context in Large Images
公和众和号:EDPJ(进 Q 交流群:922230617 或加 VX:CV_EDPJ 进 V 交流群)

目录
0. 摘要
3. 背景
3.1. 长上下文模型作为上下文编码器
3.2. 线性注意机制
4. 方法
4.1. 嵌套标记化
4.2. 区域编码器
4.3. 上下文编码器
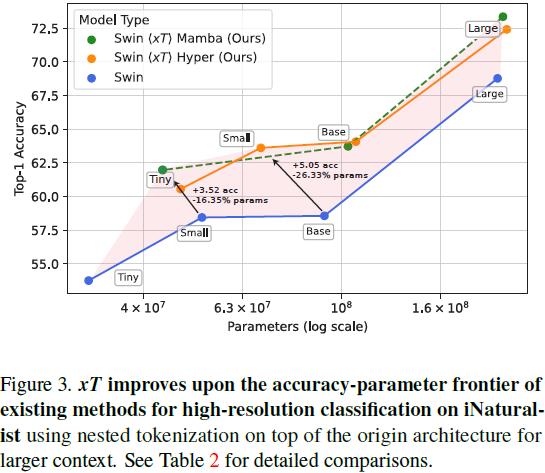
5. 实验
0. 摘要
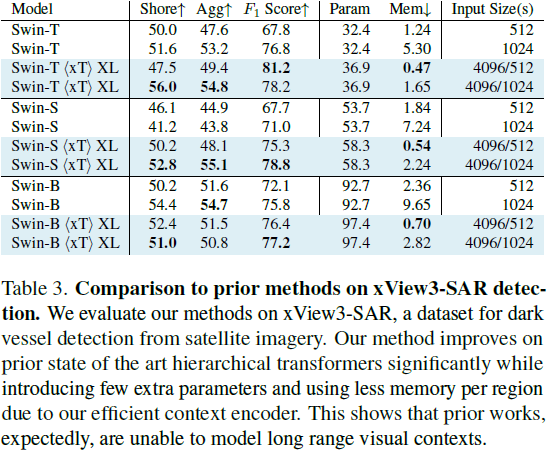
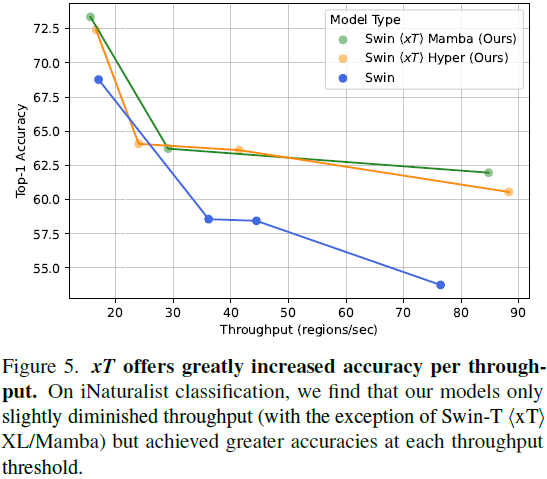
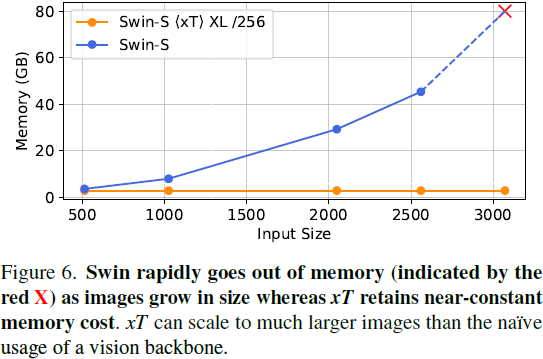
现代计算机视觉流水线处理大图像通常采用两种次优的方式之一:降采样或裁剪。这两种方法都会导致图像中信息和上下文的显著丢失。在许多下游应用中,全局上下文与高频细节一样重要,例如在真实世界的卫星图像中;在这种情况下,研究人员不得不做出舍弃哪些信息的尴尬选择。我们引入了 xT,这是一个简单的视觉 Transformer 框架,它有效地聚合了全局上下文和局部细节,并且可以在当今的 GPU 上端到端地建模大尺度图像。我们选择了一组经典视觉任务中的基准数据集,这些数据集准确反映了视觉模型理解真正大型图像并在大尺度上合并细节的能力,并评估了我们的方法在这些任务上的改进。通过引入针对大型图像的嵌套标记化(Nested Tokenization)方案,结合通常用于自然语言处理的长序列长度模型,我们能够在具有挑战性的分类任务上将准确度提高多达 8.6%,并将上下文相关分割中的 F1 分数提高 11.6%。
项目页面:https://github.com/bair-climate-initiative/xT
3. 背景
3.1. 长上下文模型作为上下文编码器
xT 利用了最初设计用于文本的长上下文模型,以便在大型图像之间混合信息。这些方法将上下文长度延伸到超出 transformer 的典型限制。以下我们简要回顾了作为我们上下文编码器的两种技术:Transformer-XL [3] 和 Mamba [9]。
Transformer-XL 使用循环将先前的信息通过先前的隐藏状态传递到未来的窗口。这种效应通过深度传播,因此能够处理长度为 L 的序列的 N 层 transformer 可以很容易地扩展到处理长度为 NL 的序列。
序列 τ 的第 n 层的每个隐藏状态 h^n_τ 是从前一层的隐藏状态 h^(n−1)_(τ−1) 和 h^(n−1)_τ 计算的,如下所示:
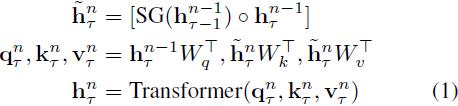
其中 SG 代表停止梯度。这与原始的 Transformer 相同,只是键和值 k^n_τ , v^n_τ 是使用前一个序列的隐藏状态 h^(n−1)_(τ−1) 以及当前序列的隐藏状态 h^(n−1)_τ 来计算的,使用了交叉注意力。这种机制允许隐藏状态 h^n_τ 在层之间循环。在序列之间应用停止梯度让信息在不承受完整序列反向传播所带来的内存成本的情况下传播。
状态空间和 Mamba。
(2023,SSM,门控 MLP,选择性输入,上下文压缩)Mamba:具有选择性状态空间的线性时间序列建模
3.2. 线性注意机制
具有多头自注意力的标准 Transformer 块对于完全全局上下文的序列长度 L 需要二次内存。这在有限的 GPU 内存面前并不理想。HyperAttention [12] 是一种注意机制,其复杂度与序列长度几乎呈线性关系。它通过首先使用局部敏感哈希(Locality Sensitive Hashing,LSH)找到注意力矩阵的大条目来减少朴素注意力的复杂性。然后,将这些主导条目与矩阵的另一个随机抽样子集结合起来,用于近似朴素注意力的输出。当长程上下文对应关系稀疏时,这种方法特别有帮助。
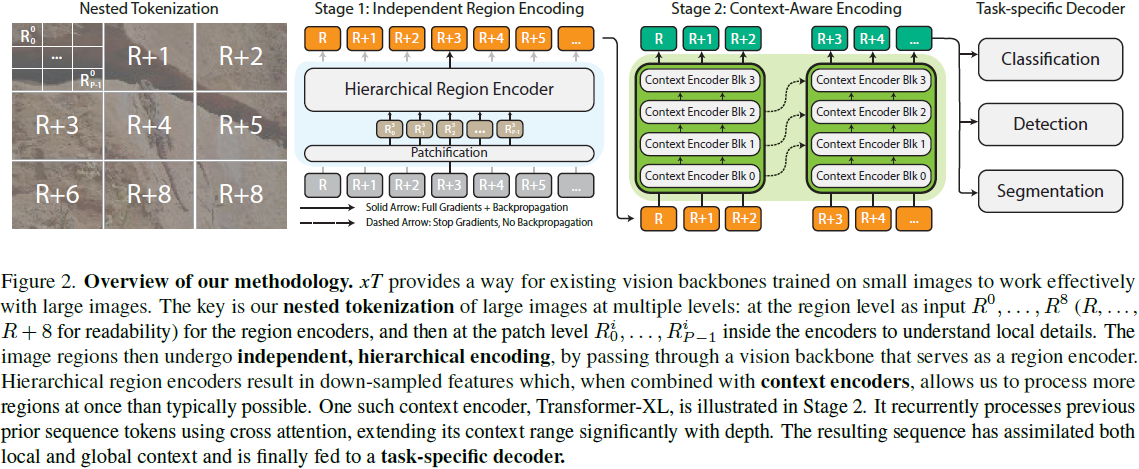
4. 方法
4.1. 嵌套标记化
给定形状为 αH×βW 的大输入图像,我们首先将图像细分为 H×W 的区域,以便我们的区域编码器能够充分处理它们。每个区域 R^i 都被进一步分成 P 个补丁(patch),R^i_0,...,R^i_(P−1),通过区域编码器骨干来为每个区域提取特征。当区域大小 H×W 不能整除图像大小时,这些区域是非重叠的,并且在实例化时进行零填充。 通常我们的图像和区域是正方形的,因此我们使用简化的符号来表示我们的管道参数。我们将接收尺寸为 αR×αR 的图像并将其细分为 R×R 的区域的管道称为 αR/R 设置。标准设置是 512/256 或 4096/512,其中我们分别将图像分割为 2×2 和 8×8 个区域。
4.2. 区域编码器
我们从一个用于典型小图像尺寸 H×W 的图像模型开始训练,通常是 224×224 或 256×256。区域编码器独立地为每个区域 R^i_(1...P) 生成特征图。我们的区域编码器是分层视觉 Transformer,其序列长度从开始处理时减少,并且小于等于等效长度的各向同性 ViTs [5] 生成的长度。因此,我们能够比使用其他体系结构时将更多区域特征组合在一起,因为我们的序列长度减少了 4 倍或更多倍。 当 GPU 内存允许时,我们同时为所有区域计算特征。然而,当图像太大,以至于其所有组成区域无法全部放入 GPU 内存时,我们会逐个处理每个区域。
4.3. 上下文编码器
输出的区域特征按行主序(row major order)连接形成一个序列。在 xT 框架中,上下文编码器是一个轻量级的序列到序列模型,可以在长序列长度上进行注意。关键是,我们将上下文编码器限制为具有近线性的内存和时间成本。这种设计使得 xT 能够查看大图像中许多其他区域,否则在内存中是不可行的。这显著扩展了现有视觉模型的感受野,同时在内存成本和参数数量上只有边缘增加。
我们的方法主要在两种情况下发挥作用:当我们的区域特征序列完全适合(fit)上下文编码器的上下文长度时,以及当它不适合时。在第一种情况下,我们只是一次性处理所有内容。我们使用标准的二维位置嵌入,将其添加到嵌套区域特征中。
我们尝试了三种具有线性 “注意力” 机制的上下文编码器:使用 HyperAttention 的 LLaMA 风格的架构(称为 Hyper),以及 Mamba。这两种设置分别称为〈xT〉 Hyper 和〈xT〉 Mamba,其中〈xT〉是将区域编码器选择与上下文编码器相结合的操作符。
当我们的输入序列不适合整个上下文长度时,我们需要额外压缩我们的区域,以保持未来区域的上下文信息。我们尝试了一种使用 HyperAttention、一种线性注意力形式和绝对位置嵌入的 Transformer-XL 的派生版本。我们将此设置表示为〈xT〉 XL。在撰写本文时,Mamba 没有用于实现 XL 风格循环的有效内核,因此我们无法将 Mamba 应用于此设置。
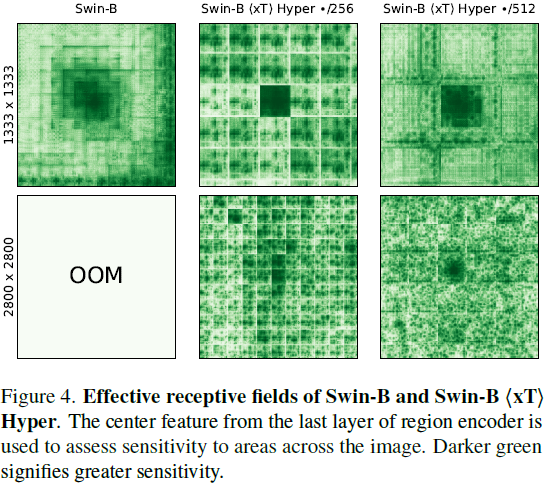
有效感受野计算我们提供了 Swin〈xT〉 XL 设置的有效感受野的计算。在第 7.1 节进一步对其进行了消融实验。
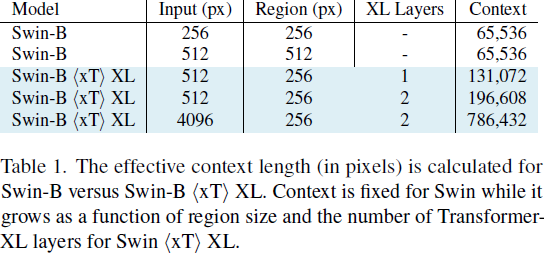
在上下文编码器中,我们将 C 个区域的特征连接成一个 “块”(chunk),因为我们的特征比来自分层区域编码器的输入要小。Transformer-XL 上下文编码器由于使用 HyperAttention 而具有降低的注意力内存需求,进一步改善了适合一个 “块” 的区域数量。每个区域都会关注这个块中的所有其他区域,并且它们还可以访问上一个块的隐藏状态,以便模型中的上下文流动。在 Transformer-XL 中,上下文随深度的增加而增加。
因此,我们可以计算我们在小图像上仅使用标准模型 query 所实现的上下文增强。如果我们使用输入大小为 R(通常为 256)的区域编码器,并收到大小为 αR×βR 的大图像,则我们将有 αβ 个区域可用于我们的上下文编码器。然后,我们通过增加块的大小增加上下文的长度,增加因子为 C,也从我们的循环内存中增加块(chunk)的大小,增加因子为 N,即上下文模型的深度。这些值在表 1 中进行了计算,并在图 4 中进一步可视化。
总的来说,我们的上下文以因子 αβNC 倍增。然而,请注意 αβ 和 C 之间存在着一个权衡,因为增加输入图像的大小会限制我们从区域特征中创建的块的大小。
5. 实验