泛型存在的意义?
为了使相同的代码适用于多种数据类型,也就是代码复用。
参数类型上下限限制
- <?> 无限制
- <? extends E> 声明了类型的上界,表示参数类型可以是他或他的子类。
- <? super E> 声明了类型的下界,表示参数类型可以是他或他的父类。
类型擦除
Java泛型这个特性是JDK 1.5才引入的,所以为了兼容之前没有泛型的版本,java的泛型策略是,Java在语法上支持泛型,但在编译阶段会进行类型擦除。
类型擦除,就是根据把原类型替换为其原生类型,如果没有限制就替换为Object,如果有上下界限定就替换为原类型的最上界(比如 <T extends number>的类型参数T就被替换为Number,<T super Number>的类型参数T就被替换为Object)
拓展:
这个类型擦除也可以引出另一个问题, 为什么要有包装类? 因为基本类型不能作为泛型参数,只有引用类型能作为泛型参数。为什么基本类型不能作为泛型参数? 因为java的泛型策略是,Java在语法上支持泛型,但在编译阶段会进行类型擦除。
以下一段代码可以证明Java泛型的类型擦除:
public class Main {
public static void main(String[] args) throws Exception {
ArrayList<Integer> list = new ArrayList<Integer>();
list.add(1); //这样调用 add 方法只能存储整形,因为泛型类型的实例为 Integer
list.getClass().getMethod("add", Object.class).invoke(list, "asd");
for (int i = 0; i < list.size(); i++) {
System.out.println(list.get(i));
}
}
}
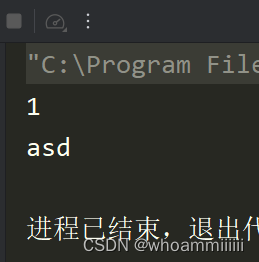
定义了一个泛型类型Integer为ArrayList,但当我们利用反射调用ArrayList的add()方法时,却可以存储字符串,说明Integer在编译之后被擦除掉了,只保留了原始类型。原始类型就是擦除了泛型信息后,最后在字节码中的真正类型。
类型擦除的流程
Java编译器是先检查泛型的类型,然后进行类型擦除,最后编译。
public static void main(String[] args) throws Exception {
ArrayList<String> list = new ArrayList<String>();
list.add("123");
list.add(123);//编译错误 java: 不兼容的类型: int无法转换为java.lang.String
}
这段代码编译会报错。说明检查在编译之前,如果检查在编译之后,编译之后变成原始类型Object了,那就不会报错了。
对谁检查?检查是对引用调用的方法进行类型检查,比如上面这段代码就是对list调用的方法里面的参数进行类型检查。





![状态压缩dp[详解 + 例题]](https://img-blog.csdnimg.cn/direct/ccc04e0d664143608f64d693908e1eac.png)