前言
大家好,我是jiantaoyab,这是我作为学习笔记总结应用篇第一篇,本章大量的参考了别的博主的文章。
我们今天就先从搭建一个大型的 DMP 系统开始,利用组成原理里面学到的存储器知识,来做选型判断,从而更深入地理解计算机组成原理。
DMP:数据管理平台
DMP 系统的全称叫作数据管理平台(Data Management Platform),目前广泛应用在互联网的广告定向(Ad Targeting)、个性化推荐(Recommendation)这些领域。
通常来说,DMP 系统会通过处理海量的互联网访问数据以及机器学习算法,给一个用户标注上各种各样的标签。然后,在我们做个性化推荐和广告投放的时候,再利用这些这些标签,去做实际的广告排序、推荐等工作。无论是 Google 的搜索广告、淘宝里千人千面的商品信息,还是抖音里面的信息流推荐,背后都会有一个 DMP 系统。

那么,一个 DMP 系统应该怎么搭建呢?对于外部使用 DMP 的系统或者用户来说,可以简单地把 DMP 看成是一个键 - 值对(Key-Value)数据库。
广告系统或者推荐系统,可以通过一个客户端输入用户的唯一标识(ID),然后拿到这个用户的各种信息。
这些信息中,有些是用户的人口属性信息(Demographic),比如性别、年龄;有些是非常具体的行为(Behavior),比如用户最近看过的商品是什么,用户的手机型号是什么;有一些是我们通过算法系统计算出来的兴趣(Interests),比如用户喜欢健身、听音乐;还有一些则是完全通过机器学习算法得出的用户向量,给后面的推荐算法或者广告算法作为数据输入。
基于此,对于这个 KV 数据库,我们的期望也很清楚,那就是:低响应时间(Low Response Time)、高可用性(High Availability)、高并发(High Concurrency)、海量数据(Big Data),同时我们需要付得起对应的成本(Affordable Cost)。如果用数字来衡量这些指标,那么我们的期望就会具体化成下面这样。
- 低响应时间:一般的广告系统留给整个广告投放决策的时间也就是 10ms 左右,所以对于访问 DMP 获取用户数据,预期的响应时间都在 1ms 之内。
- 高可用性:DMP 常常用在广告系统里面。DMP 系统出问题,往往就意味着我们整个的广告收入在不可用的时间就没了,所以我们对于可用性的追求可谓是没有上限的。Google 2018 年的广告收入是 1160 亿美元,折合到每一分钟的收入是 22 万美元。即使我们做到 99.99% 的可用性,也意味着每个月我们都会损失 100 万美元。
- 高并发:还是以广告系统为例,如果每天我们需要响应 100 亿次的广告请求,那么我们每秒的并发请求数就在 100 亿 / (86400) ~= 12K 次左右,所以我们的 DMP 需要支持高并发。
- 数据量:如果我们的产品针对中国市场,那么我们需要有 10 亿个 Key,对应的假设每个用户有 500 个标签,标签有对应的分数。标签和分数都用一个 4 字节(Bytes)的整数来表示,那么一共我们需要 10 亿 x 500 x (4 + 4) Bytes = 400 TB 的数据了。
- 低成本:我们还是从广告系统的角度来考虑。广告系统的收入通常用 CPM(Cost Per Mille),也就是千次曝光来统计。如果千次曝光的利润是 $0.10,那么每天 100 亿次的曝光就是 100 万美元的利润。这个利润听起来非常高了。但是反过来算一下,你会发现,DMP 每 1000 次的请求的成本不能超过 $0.10。最好只有 $0.01,甚至更低,我们才能尽可能多赚到一点广告利润。
虽然从外部看起来,DMP 特别简单,就是一个 KV 数据库,但是生成这个数据库需要做的事情更多。我们下面一起来看一看。

为了能够生成这个 KV 数据库,我们需要有一个在客户端或者 Web 端的数据采集模块,不断采集用户的行为,向后端的服务器发送数据。服务器端接收到数据,就要把这份数据放到一个数据管道(Data Pipeline)里面。数据管道的下游,需要实际将数据落地到数据仓库(Data Warehouse),把所有的这些数据结构化地存储起来。后续,我们就可以通过程序去分析这部分日志,生成报表或者或者利用数据运行各种机器学习算法。
除了这个数据仓库之外,我们还会有一个实时数据处理模块(Realtime Data Processing),也放在数据管道的下游。它同样会读取数据管道里面的数据,去进行各种实时计算,然后把需要的结果写入到 DMP 的 KV 数据库里面去。
MongoDB 真的万能吗?
面对这里的 KV 数据库、数据管道以及数据仓库,这三个不同的数据存储的需求,最合理的技术方案是什么呢?
**MongoDB **
MongoDB 的设计听起来特别厉害,不需要预先数据 Schema,访问速度很快,还能够无限水平扩展。作为 KV 数据库,我们可以把 MongoDB 当作 DMP 里面的 KV 数据库;除此之外,MongoDB 还能水平扩展、跑 MQL,我们可以把它当作数据仓库来用。至于数据管道,只要我们能够不断往 MongoDB 里面,插入新的数据就好了。从运维的角度来说,我们只需要维护一种数据库,技术栈也变得简单了。看起来,MongoDB 这个选择真是相当完美!
MongoDB的不足
对于数据管道来说,我们需要的是高吞吐量,它的并发量虽然和 KV 数据库差不多,但是在响应时间上,要求就没有那么严格了,1-2 秒甚至再多几秒的延时都是可以接受的。而且,和 KV 数据库不太一样,数据管道的数据读写都是顺序读写,没有大量的随机读写的需求。
数据仓库就更不一样了,数据仓库的数据读取的量要比管道大得多。管道的数据读取就是我们当时写入的数据,一天有 10TB 日志数据,管道只会写入 10TB。下游的数据仓库存放数据和实时数据模块读取的数据,再加上个 2 倍的 10TB,也就是 20TB 也就够了。
但是,数据仓库的数据分析任务要读取的数据量就大多了。一方面,我们可能要分析一周、一个月乃至一个季度的数据。这一次分析要读取的数据可不是 10TB,而是 100TB 乃至 1PB。我们一天在数据仓库上跑的分析任务也不是 1 个,而是成千上万个,所以数据的读取量是巨大的。另一方面,我们存储在数据仓库里面的数据,也不像数据管道一样,存放几个小时、最多一天的数据,而是往往要存上 3 个月甚至是 1 年的数据。所以,我们需要的是 1PB 乃至 5PB 这样的存储空间。

在 KV 数据库的场景下,需要支持高并发。那么 MongoDB 需要把更多的数据放在内存里面,但是这样我们的存储成本就会特别高了。
在数据管道的场景下,我们需要的是大量的顺序读写,而 MongoDB 则是一个文档数据库系统,并没有为顺序写入和吞吐量做过优化,看起来也不太适用。
而在数据仓库的场景下,主要的数据读取时顺序读取,并且需要海量的存储。MongoDB 这样的文档式数据库也没有为海量的顺序读做过优化,仍然不是一个最佳的解决方案。而且文档数据库里总是会有很多冗余的字段的元数据,还会浪费更多的存储空间。
那我们该选择什么样的解决方案呢?
对于 KV 数据库,最佳的选择方案自然是使用 SSD 硬盘,选择 AeroSpike 这样的 KV 数据库。高并发的随机访问并不适合 HDD 的机械硬盘,而 400TB 的数据,如果用内存的话,成本又会显得太高。
对于数据管道,最佳选择自然是 Kafka。因为我们追求的是吞吐率,采用了 Zero-Copy 和 DMA 机制的 Kafka 最大化了作为数据管道的吞吐率。而且,数据管道的读写都是顺序读写,所以我们也不需要对随机读写提供支持,用上 HDD 硬盘就好了。
到了数据仓库,存放的数据量更大了。在硬件层面使用 HDD 硬盘成了一个必选项。否则,我们的存储成本就会差上 10 倍。这么大量的数据,在存储上我们需要定义清楚 Schema,使得每个字段都不需要额外存储元数据,能够通过 Avro/Thrift/ProtoBuffer 这样的二进制序列化的方存储下来,或者干脆直接使用 Hive 这样明确了字段定义的数据仓库产品。很明显,MongoDB 那样不限制 Schema 的数据结构,在这个情况下并不好用。
关系型数据库:不得不做的随机读写
如果现在让你自己写一个最简单的关系型数据库,你的数据要怎么存放在硬盘上?
最简单最直观的想法是,用一个 CSV 文件格式。一个文件就是一个数据表。文件里面的每一行就是这个表里面的一条记录。如果要修改数据库里面的某一条记录,那么我们要先找到这一行,然后直接去修改这一行的数据。读取数据也是一样的。
要找到这样数据,最笨的办法自然是一行一行读,也就是遍历整个 CSV 文件。不过这样的话,相当于随便读取任何一条数据都要扫描全表,太浪费硬盘的吞吐量了。
那怎么办呢?我们可以试试给这个 CSV 文件加一个索引。比如,给数据的行号加一个索引。如果你学过数据库原理或者算法和数据结构,那你应该知道,通过 B+ 树多半是可以来建立这样一个索引的。
索引里面没有一整行的数据,只有一个映射关系,这个映射关系可以让行号直接从硬盘的某个位置去读。所以,索引比起数据小很多。我们可以把索引加载到内存里面。即使不在内存里面,要找数据的时候快速遍历一下整个索引,也不需要读太多的数据。
加了索引之后,我们要读取特定的数据,就不用去扫描整个数据表文件了。直接从特定的硬盘位置,就可以读到想要的行。索引不仅可以索引行号,还可以索引某个字段。我们可以创建很多个不同的独立的索引。写 SQL 的时候,where 子句后面的查询条件可以用到这些索引。
不过,这样的话,写入数据的时候就会麻烦一些。我们不仅要在数据表里面写入数据,对于所有的索引也都需要进行更新。这个时候,写入一条数据就要触发好几个随机写入的更新
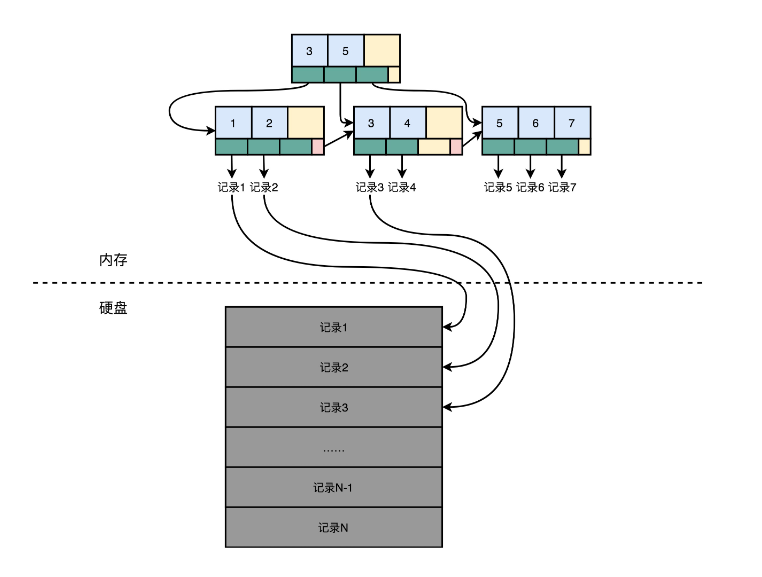
在这样一个数据模型下,查询操作很灵活。无论是根据哪个字段查询,只要有索引,我们就可以通过一次随机读,很快地读到对应的数据。但是,这个灵活性也带来了一个很大的问题,那就是无论干点什么,都有大量的随机读写请求。而随机读写请求,如果请求最终是要落到硬盘上,特别是 HDD 硬盘的话,我们就很难做到高并发了。毕竟 HDD 硬盘只有 100 左右的 QPS。
而这个随时添加索引,可以根据任意字段进行查询,这样表现出的灵活性,又是我们的 DMP 系统里面不太需要的。DMP 的 KV 数据库主要的应用场景,是根据主键的随机查询,不需要根据其他字段进行筛选查询。数据管道的需求,则只需要不断追加写入和顺序读取就好了。即使进行数据分析的数据仓库,通常也不是根据字段进行数据筛选,而是全量扫描数据进行分析汇总。
后面的两个场景还好说,大不了我们让程序去扫描全表或者追加写入。但是,在 KV 数据库这个需求上,刚才这个最简单的关系型数据库的设计,就会面临大量的随机写入和随机读取的挑战。
所以,在实际的大型系统中,大家都会使用专门的分布式 KV 数据库,来满足这个需求。那么下面,我们就一起来看一看,Facebook 开源的 Cassandra 的数据存储和读写是怎么做的,这些设计是怎么解决高并发的随机读写问题的。
Cassandra:顺序写和随机读
作为一个分布式的 KV 数据库,Cassandra 的键一般被称为 Row Key。其实就是一个 16 到 36 个字节的字符串。每一个 Row Key 对应的值其实是一个哈希表,里面可以用键值对,再存入很多你需要的数据。
Cassandra 本身不像关系型数据库那样,有严格的 Schema,在数据库创建的一开始就定义好了有哪些列(Column)。但是,它设计了一个叫作列族(Column Family)的概念,我们需要把经常放在一起使用的字段,放在同一个列族里面。比如,DMP 里面的人口属性信息,我们可以把它当成是一个列族。用户的兴趣信息,可以是另外一个列族。这样,既保持了不需要严格的 Schema 这样的灵活性,也保留了可以把常常一起使用的数据存放在一起的空间局部性。
往 Cassandra 的里面读写数据,其实特别简单,就好像是在一个巨大的分布式的哈希表里面写数据。我们指定一个 Row Key,然后插入或者更新这个 Row Key 的数据就好了。

Cassandra 解决随机写入数据的解决方案,简单来说,就叫作“不随机写,只顺序写”。
对于 Cassandra 数据库的写操作,通常包含两个动作。第一个是往磁盘上写入一条提交日志(Commit Log)。
另一个操作,则是直接在内存的数据结构上去更新数据。后面这个往内存的数据结构里面的数据更新,只有在提交日志写成功之后才会进行。每台机器上,都有一个可靠的硬盘可以让我们去写入提交日志。写入提交日志都是顺序写(Sequential Write),而不是随机写(Random Write),这使得我们最大化了写入的吞吐量。
无论是 HDD 硬盘还是 SSD 硬盘,顺序写入都比随机写入要快得多。内存的空间比较有限,一旦内存里面的数据量或者条目超过一定的限额,Cassandra 就会把内存里面的数据结构 dump 到硬盘上。这个 Dump 的操作,也是顺序写而不是随机写,所以性能也不会是一个问题。除了 Dump 的数据结构文件,Cassandra 还会根据 row key 来生成一个索引文件,方便后续基于索引来进行快速查询。
随着硬盘上的 Dump 出来的文件越来越多,Cassandra 会在后台进行文件的对比合并。在很多别的 KV 数据库系统里面,也有类似这种的合并动作,比如 AeroSpike 或者 Google 的 BigTable。这些操作我们一般称之为 Compaction。合并动作同样是顺序读取多个文件,在内存里面合并完成,再 Dump 出来一个新的文件。整个操作过程中,在硬盘层面仍然是顺序读写。
Cassandra 的读操作
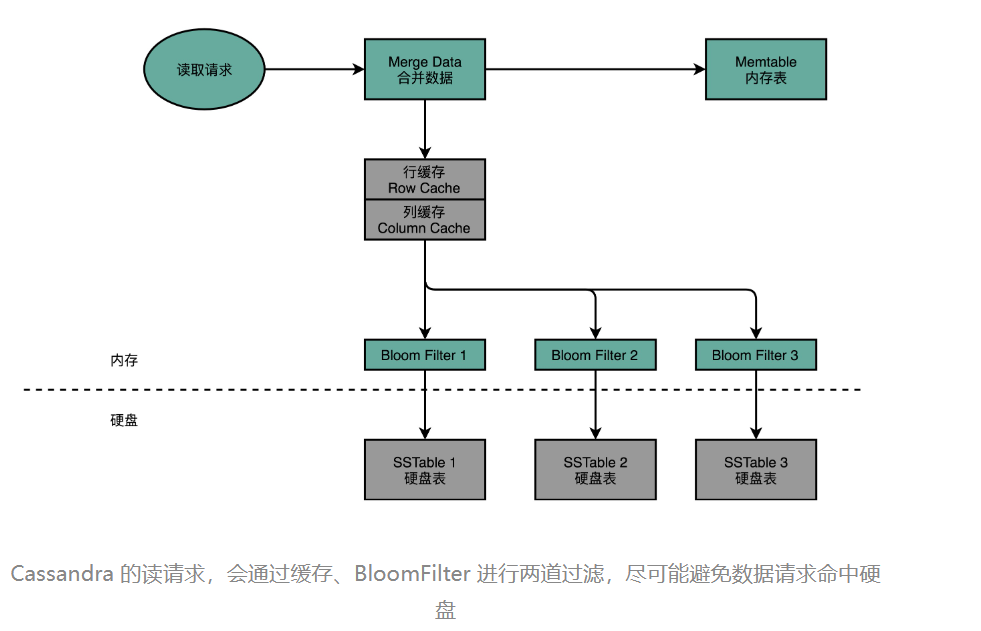
当我们要从 Cassandra 读数据的时候,会从内存里面找数据,再从硬盘读数据,然后把两部分的数据合并成最终结果。这些硬盘上的文件,在内存里面会有对应的 Cache,只有在 Cache 里面找不到,我们才会去请求硬盘里面的数据。
如果不得不访问硬盘,因为硬盘里面可能 Dump 了很多个不同时间点的内存数据的快照。所以,找数据的时候,我们也是按照时间从新的往旧的里面找。
这也就带来另外一个问题,我们可能要查询很多个 Dump 文件,才能找到我们想要的数据。
所以,Cassandra 在这一点上又做了一个优化。那就是,它会为每一个 Dump 的文件里面所有 Row Key 生成一个 BloomFilter,然后把这个 BloomFilter 放在内存里面。这样,如果想要查询的 Row Key 在数据文件里面不存在,那么 99% 以上的情况下,它会被 BloomFilter 过滤掉,而不需要访问硬盘。
这样,只有当数据在内存里面没有,并且在硬盘的某个特定文件上的时候,才会触发一次对于硬盘的读请求。
SSD:DBA 们的大救星
Cassandra 是 Facebook 在 2008 年开源的。那个时候,SSD 硬盘还没有那么普及。可以看到,它的读写设计充分考虑了硬件本身的特性。在写入数据进行持久化上,Cassandra 没有任何的随机写请求,无论是 Commit Log 还是 Dump,全部都是顺序写。
在数据读的请求上,最新写入的数据都会更新到内存。如果要读取这些数据,会优先从内存读到。这相当于是一个使用了 LRU 的缓存机制。只有在万般无奈的情况下,才会有对于硬盘的随机读请求。即使在这样的情况下,Cassandra 也在文件之前加了一层 BloomFilter,把本来因为 Dump 文件带来的需要多次读硬盘的问题,简化成多次内存读和一次硬盘读。
这些设计,使得 Cassandra 即使是在 HDD 硬盘上,也能有不错的访问性能。因为所有的写入都是顺序写或者写入到内存,所以,写入可以做到高并发。HDD 硬盘的吞吐率还是很不错的,每秒可以写入 100MB 以上的数据,如果一条数据只有 1KB,那么 10 万的 WPS(Writes per seconds)也是能够做到的。这足够支撑我们 DMP 期望的写入压力了。
而对于数据的读,就有一些挑战了。如果数据读请求有很强的局部性,那我们的内存就能搞定 DMP 需要的访问量。
但是,问题就出在这个局部性上。DMP 的数据访问分布,其实是缺少局部性的。你仔细想一想 DMP 的应用场景就明白了。DMP 里面的 Row Key 都是用户的唯一标识符。普通用户的上网时长怎么会有局部性呢?每个人上网的时间和访问网页的次数就那么多。上网多的人,一天最多也就 24 小时。大部分用户一天也要上网 2~3 小时。我们没办法说,把这些用户的数据放在内存里面,那些用户不放。
那么,我们可不可能有一定的时间局部性呢?
如果是 Facebook 那样的全球社交网络,那可能还有一定的时间局部性。毕竟不同国家的人的时区不一样。我们可以说,在印度人民的白天,把印度人民的数据加载到内存里面,美国人民的数据就放在硬盘上。到了印度人民的晚上,再把美国人民的数据换到内存里面来。
如果你的主要业务是在国内,那这个时间局部性就没有了。大家的上网高峰时段,都是在早上上班路上、中午休息的时候以及晚上下班之后的时间,没有什么区分度。
面临这个情况,如果你们的 CEO 或者 CTO 问你,是不是可以通过优化程序来解决这个问题?如果你没有仔细从数据分布和原理的层面思考这个问题,而直接一口答应下来,那你可能之后要头疼了,因为这个问题很有可能是搞不定的。
因为缺少了时间局部性,我们内存的缓存能够起到的作用就很小了,大部分请求最终还是要落到 HDD 硬盘的随机读上。但是,HDD 硬盘的随机读的性能太差了,也就是 100QPS 左右。
而如果全都放内存,那就太贵了,成本在 HDD 硬盘 100 倍以上。
不过,幸运的是,从 2010 年开始,SSD 硬盘的大规模商用帮助我们解决了这个问题。它的价格在 HDD 硬盘的 10 倍,但是随机读的访问能力在 HDD 硬盘的百倍以上。也就是说,用上了 SSD 硬盘,我们可以用 1/10 的成本获得和 HDD 硬盘同样的 QPS。同样的价格的 SSD 硬盘,容量则是内存的几十倍,也能够满足我们的需求,用较低的成本存下整个互联网用户信息。
回到我们看到的 Cassandra 的读写设计,Cassandra 的写入机制完美匹配了 SSD 硬盘的优缺点。
在数据写入层面,Cassandra 的数据写入都是 Commit Log 的顺序写入,也就是不断地在硬盘上往后追加内容,而不是去修改现有的文件内容。一旦内存里面的数据超过一定的阈值,Cassandra 又会完整地 Dump 一个新文件到文件系统上。这同样是一个追加写入。
数据的对比和紧凑化(Compaction),同样是读取现有的多个文件,然后写一个新的文件出来。写入操作只追加不修改的特性,正好天然地符合 SSD 硬盘只能按块进行擦除写入的操作。在这样的写入模式下,Cassandra 用到的 SSD 硬盘,不需要频繁地进行后台的 Compaction,能够最大化 SSD 硬盘的使用寿命。这也是为什么,Cassandra 在 SSD 硬盘普及之后,能够获得进一步快速发展。
总结
传统的关系型数据库,我们把一条条数据存放在一个地方,同时再把索引存放在另外一个地方。这样的存储方式,其实很方便我们进行单次的随机读和随机写,数据的存储也可以很紧凑。但是问题也在于此,大部分的 SQL 请求,都会带来大量的随机读写的请求。这使得传统的关系型数据库,其实并不适合用在真的高并发的场景下。
我们的 DMP 需要的访问场景,其实没有复杂的索引需求,但是会有比较高的并发性。 Cassandra 这个分布式 KV 数据库的读写设计。通过在追加写入 Commit Log 和更新内存,Cassandra 避开了随机写的问题。内存数据的 Dump 和后台的对比合并,同样也都避开了随机写的问题,使得 Cassandra 的并发写入性能极高。
在数据读取层面,通过内存缓存和 BloomFilter,Cassandra 已经尽可能地减少了需要随机读取硬盘里面数据的情况。不过挑战在于,DMP 系统的局部性不强,使得我们最终的随机读的请求还是要到硬盘上。幸运的是,SSD 硬盘在数据海量增长的那几年里价格不断下降,使得我们最终通过 SSD 硬盘解决了这个问题。
而 SSD 硬盘本身的擦除后才能写入的机制,正好非常适合 Cassandra 的数据读写模式,最终使得 Cassandra 在 SSD 硬盘普及之后得到了更大的发展。
对于数据管道,因为主要是顺序读和顺序写,所以我们不一定要选用 SSD 硬盘,而可以用 HDD 硬盘。不过,对于最大化吞吐量的需求,使用 zero-copy 和 DMA 是必不可少的,所以现在的数据管道的标准解决方案就是 Kafka 了。
对于数据仓库,我们通常是一次写入、多次读取。并且,由于存储的数据量很大,我们还要考虑成本问题。于是,一方面,我们会用 HDD 硬盘而不是 SSD 硬盘;另一方面,我们往往会预先给数据规定好 Schema,使得单条数据的序列化,不需要像存 JSON 或者 MongoDB 的 BSON 那样,存储冗余的字段名称这样的元数据。所以,最常用的解决方案是,用 Hadoop 这样的集群,采用 Hive 这样的数据仓库系统,或者采用 Avro/Thrift/ProtoBuffer 这样的二进制序列化方案。
在大型的 DMP 系统设计当中,我们需要根据各个应用场景面临的实际情况,选择不同的硬件和软件的组合,来作为整个系统中的不同组件。








![慧天[HTWATER]:采用CUDA框架实现耦合模型并行求解](https://img-blog.csdnimg.cn/direct/d37df7539516484cb7b6e8c237e41901.png)