1、基本语法
REGEXP_SUBSTR(String, pattern, position,occurrence, modifier)
String:需要进行处理的字符串。
pattern:正则表达式。
position:起始位置(从字符串的第几个开始,默认为1,注:数据库中的字符串起始位置为1)。
occurrence:获取第几组通过正则表达式分割出来的组。
modifier:模式(‘i’不区分大小写,‘c’区分大小写。其中默认没‘c’)。
2、解析
SELECT DISTINCT REGEXP_SUBSTR('A,B,C,D,E,F', '[^,]+',1) FROM DUAL;
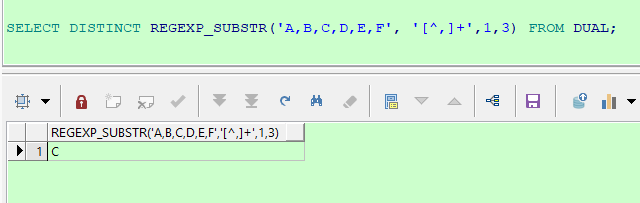
SELECT DISTINCT REGEXP_SUBSTR('A,B,C,D,E,F', '[^,]+',1,3) FROM DUAL;

在oracle中rownum和level都是自动生成数字序列集合,结合connect by使用
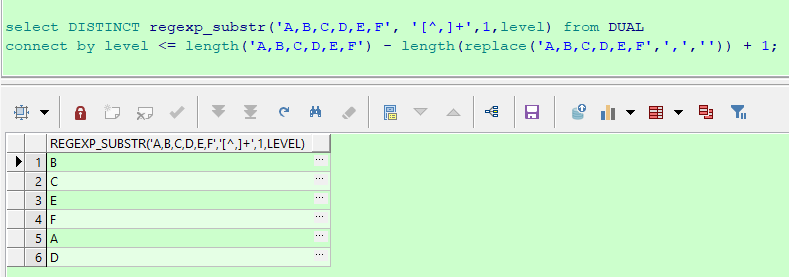
select DISTINCT regexp_substr('A,B,C,D,E,F', '[^,]+',1,level) from DUAL
connect by level <= length('A,B,C,D,E,F') - length(replace('A,B,C,D,E,F',',','')) + 1;
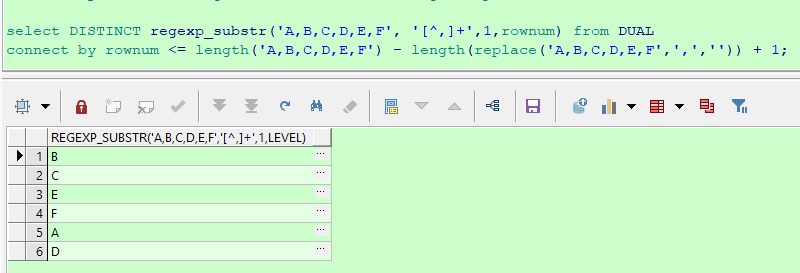
select DISTINCT regexp_substr('A,B,C,D,E,F', '[^,]+',1,rownum) from DUAL
connect by rownum <= length('A,B,C,D,E,F') - length(replace('A,B,C,D,E,F',',','')) + 1;
结果如下:




![慧天[HTWATER]:采用CUDA框架实现耦合模型并行求解](https://img-blog.csdnimg.cn/direct/d37df7539516484cb7b6e8c237e41901.png)