北大202402的RAG综述
1 intro
1.1 AICG
- 近年来,人们对人工智能生成内容(AIGC)的兴趣激增。各种内容生成工具已经精心设计,用于生产各种模态下的多样化对象
- 文本&代码:大型语言模型(LLM),包括GPT系列和LLAMA系列
- 图像:DALL-E和Stable Diffusion
- 视频:Sora
- "AIGC"这一词强调内容是由高级生成模型而非人类或基于规则的方法产生的
- 基础模型的架构最初由数百万参数组成,现在已增长到包含数十亿参数
1.2 信息检索
- 检索旨在从庞大的资源池中定位相关的现有对象
- 在当前时代,高效的信息检索系统可以处理高达数十亿的文档集合
- 除了文档外,检索还已应用于其他模态
1.3 AICG的挑战
- 难以保持知识的最新性
- 无法整合长尾知识
- 泄露私有训练数据的风险
1.4 RAG
- 为了缓解上述挑战,提出了检索增强生成(RAG)
- 用于检索的知识可以被概念化为非参数记忆
- 这种形式的记忆容易修改,能够容纳广泛的长尾知识,并且还能编码机密数据
- 检索还可以用来降低生成成本
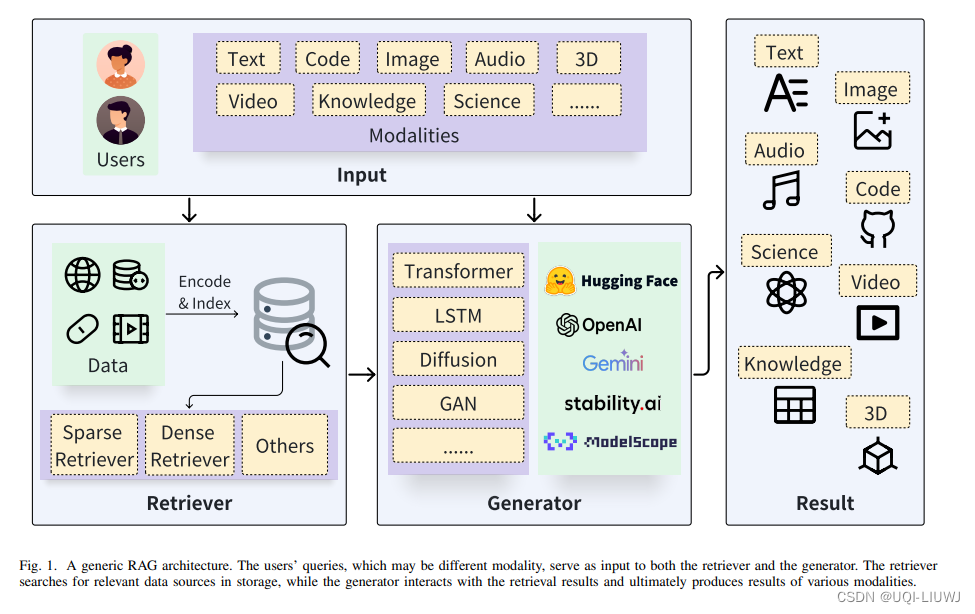
- 一个典型的RAG过程包括:
- 给定一个输入查询,检索器定位并查找相关的数据源
- 检索到的结果与生成器互动,以增强整体的生成过程
- 可以通过不同的方式与生成过程交互
- 作为生成器的增强输入
- 在生成的中间阶段以潜在表征的形式加入
- 以logits的形式贡献到最终的生成结果中
- 影响或省略某些生成步骤
- 可以通过不同的方式与生成过程交互
- 虽然RAG的概念最初出现在文本到文本的生成中,但它也已被适应于各种领域
- 代码
- 音频
- 图像
- 视频
- 知识
- 科学领域
1.5 本文贡献
- 提供了关于RAG的全面概述,覆盖了基础、增强、应用、基准测试、限制和潜在的未来方向
2 preliminary
- 整个RAG系统由两个核心模块组成:检索器和生成器
- 检索器负责从构建的数据存储中搜索相关信息
- 生成器负责产生生成的内容
2.1 生成器
- 将生成器分类为4个主要组别:Transformer、LSTM、扩散模型和GAN
2.1.1 Transformer

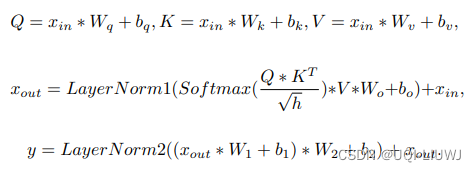
2.1.2 LSTM

2.1.3 扩散模型

- 扩散模型通过逐渐向数据添加噪声直至变成随机,然后反转这一过程从噪声生成新数据
- 这一过程基于概率建模和神经网络
- 扩散模型主要有三种等效表述:
- 去噪扩散概率模型
- 基于分数的生成模型
- 随机微分方程
- 记x0是一个随机变量,遵循数据分布q(x0);xt是一个在时间步t添加噪声后遵循分布q(xt|x0)的随机变量,DDPM可以如下表述:
- 前向过程
- 通过一系列高斯噪声注入扰乱数据,将数据分布q(x0)转化为一个简单的先验分布q(xT) ≈ N(0, I)
- 每个时间步的转移核由以下给出:

- βt∈(0,1)是超参数

- 反向过程
- 通过一个可学习的马尔可夫链反转前向过程,生成新的数据样本

- 反向过程从采样xT∼p(xT)开始,迭代地采样xt−1∼pθ(xt−1∣xt)直到t=0
- 模型训练
- 模型训练的目标是最大化数据x0的对数似然的变分下界(VLB)

- 前向过程
2.1.4 GAN

- 典型的GAN由两个主要组成部分:一个生成器和一个鉴别器。
- 这两部分通过对抗学习相互竞争,使得生成器不断提高其生成逼真样本的能力,同时鉴别器不断提高其区分真伪样本的能力。
2.2 检索
- 检索旨在识别和获取与信息需求相关的信息系统资源
- 存储的信息资源为
,k为键值,v为value
- 给定一个查询q,目标是使用相似度函数s搜索最相似的前k个键,并获取配对的值
2.2.1 稀疏检索器
- 广泛用于文档检索
- 利用词项匹配度量如TF-IDF、查询似然和BM2,分析文本中的词项统计并构建倒排索引以实现高效搜索
- 其中,BM25是工业规模网络搜索中难以超越的基线
- 对于包含关键词
的查询q,文档D的BM25得分是

2.2.2 密集检索器
- 使用密集嵌入向量表示查询和键,并构建近似最近邻(ANN)索引以加速搜索
2.2.3 其他
- 自然语言文本之间的编辑距离
- 代码片段的抽象语法树(AST)
- 涉及知识图谱的RAG方法可以使用k跳邻居搜索作为检索过程
3 RAG基础

3.1 基于查询的RAG

- 将用户的查询与检索过程中获取的文档,直接集成到语言模型输入的初始阶段
3.2 基于潜在表征的RAG

- 在基于潜在表示的RAG框架中,生成模型与检索对象的潜在表示交互,从而提高模型的理解能力和生成内容的质量
- 这里常见的交互方法包括简单的拼接以及设计注意力机制等
- 比如:Fusion-in-Decoder技术利用BM25和DPR检索支持性段落、
- 将每个检索到的段落及其标题与查询串联起来,通过编码器单独处理它们
- FiD通过在解码器中融合多个检索段落的信息,而不是在编码器中处理每个段落,降低了计算复杂性,并有效利用相关信息生成答案
3.3基于对数几率的RAG

- 在基于对数几率的RAG中,生成模型在解码过程中通过对数几率结合检索信息
- 比如:KNN-LM模型将预训练的语言模型与K近邻搜索结合
- 利用预训练模型生成候选词及其概率分布的列表
- 同时执行从数据库中检索,找到基于当前上下文最相关的k个邻居
- ————>增强原始语言模型的输出
3.4 基于推测的RAG

- 利用检索过程替代部分或全部的生成过程
- 当检索器的成本低于生成器的生成成本时,这种方法具有很大的应用潜力
- 比如:在使用类似 ChatGPT 接口作为生成器的场景下,调用次数越多意味着成本越高,因此可以搜索过往的相同或极度相似的问题来直接得到回答。
4 RAG的性能增强
4.1 输入增强

4.1.1 查询改写(Query Transformation)
- 修改输入查询来增强检索结果
- Query2doc[164]和HyDE[165]
- 首先使用查询生成一个伪文档,然后使用这个文档作为检索的关键。
- 这样做的优势是,伪文档将包含更丰富的相关信息,这有助于检索更准确的结果。
Query2doc: Query expansion with large language models,EMNLP 2023Precise zero-shot dense retrieval without relevance labels, ACL 2023
4.1.2 数据增强(Data Augmentation)
- 在检索之前提前改善数据
- 移除无关信息
- 消除歧义
- 更新过时文档
- 合成新数据
- ——>可以有效提升最终RAG系统的性能
4.2 检索器提升
- 在RAG系统中,检索过程至关重要。
- 通常,内容质量越好,就越容易激发LLMs在上下文学习以及其他生成器和范式中的能力。内容质量越差,就越有可能导致模型产生幻觉
4.2.1 递归检索
- 检索前对查询进行分割,并执行多次搜索以检索更多更高质量的内容的过程
- 比如:
- [166]使用思维链(COT),使模型能够逐步拆分查询并提供更丰富的相关知识
- LLMCS[168]将这项技术应用于对话系统,并通过重写对话记录获得了更好的检索结果
Query expansion by prompting large language models, arxiv 2023Large language models know your contextual search intent: A prompting framework for conversational search, EMNLP 2023
4.2.2 块优化
- 块优化技术指的是调整块的大小以获得更好的检索结果
- 比如
- 句子窗口检索
- 一种有效的方法,通过获取小块的文本并返回围绕检索段的相关句子窗口来增强检索
- 这种方法确保了目标句子之前和之后的上下文被包含在内,提供了对检索信息更全面的理解
- 自动合并检索
- LlamaIndex的另一种高级RAG方法
- 以树状结构组织文档,父节点包含所有子节点的内容【文章和段落以及段落和句子,都遵循父子关系】
- 在检索过程中,对子节点的细粒度搜索最终返回父节点,有效地提供了更丰富的信息
- 句子窗口检索
4.2.3 微调检索器
- 一个好的嵌入模型可以在向量空间中将语义上相似的内容聚集在一起。
- 检索器能力越强,就能为后续的生成器提供更多有用信息,从而提高RAG系统的效果
- 对于已经具有良好表达能力的嵌入模型,我们仍然可以使用高质量的领域数据或任务相关数据对其进行微调,以提高其在特定领域或任务中的性能。
- 【也即embedding的微调】
- 比如:
- REPLUG[127]
- 将LM视为黑盒,并根据最终结果更新检索器模型
-
Replug: Retrieval-augmented black-box language models, arxiv 2023
- APICoder[129]
- 使用Python文件和API名称、签名、描述对检索器进行微调
-
When language model meets private library, EMNLP 2022
- SYNCHROMESH[120]
- 在损失中添加AST的树距离,并使用目标相似性调整对检索器进行微调
-
Synchromesh: Reliable code generation from pre-trained language models,ICLR 2022
- EDITSUM[138]
- 微调检索器以减少检索后摘要之间的杰卡德距离
-
Editsum: A retrieve-and-edit framework for source code summarization, ASE 2021
- REPLUG[127]
4.2.4 混合检索
- 同时使用多种类型的检索方法
- 比如:
- Rencos[119]
- 使用稀疏检索器在句法层面检索相似的代码片段
- 使用密集检索器在语义层面检索相似的代码片段
-
Retrieval-based neural source code summarization, icse 2020
- BASHEXPLAINER[139]
- 首先使用密集检索器捕获语义信息
- 然后使用稀疏检索器获取词汇信息
-
Bashexplainer: Retrieval-augmented bash code comment generation based on finetuned codebert, ICSME 2022
- RetDream[48]
- 首先使用文本检索,然后使用图像嵌入进行检索
-
Retrieval-augmented score distillation for text-to-3d generation, ARXIV 2022
- Rencos[119]
4.2.5 重新排序
- 重新排序检索到的内容,以实现更大的多样性和更好的结果
- 比如:
- Re2G[175]
- 在传统检索器之后应用了重排模型
- 重排模型的效果是重新排序检索到的文档,其目的是减少将文本压缩成向量所导致的信息损失对检索质量的影响
-
Re2g: Retrieve, rerank, generate,NAACL 2022
- AceCoder[177]
- 使用选择器对检索到的程序进行重排。
- 引入选择器的目的是减少冗余程序并获得多样化的检索程序
-
Acecoder: Utilizing existing code to enhance code generation, 2023 ARXIV
- Re2G[175]
4.2.6 元数据过滤
元数据过滤[179]是另一种处理检索文档的方法,它使用元数据(如时间、目的等)过滤检索到的文档以获得更好的结果。
4.3生成器增强
在RAG系统中,生成器的质量往往决定了最终输出结果的质量。因此,生成器的能力决定了整个RAG系统效果的上限。
4.3.1提示工程
- 专注于提高LLMs输出质量的提示工程技术,如提示压缩、Stepback提示、Active提示、思维链提示等,都适用于RAG系统中的LLM生成器
- 比如:
- LLMLingua[183]
- 应用一个小模型压缩查询的总长度以加速模型推理,减轻不相关信息对模型的负面影响,缓解“中途迷失”现象
-
Llmlingua: Compressing prompts for accelerated inference of large language models,EMNLP 2023
- ReMoDiffuse[49]
- ]通过使用ChatGPT将复杂描述分解成解剖文本脚本
-
Remodiffuse: Retrieval-augmented motion diffusion model ICCV 2023
- ASAP[185]
- 在提示中添加示例元组以获得更好的结果
- 示例元组由输入代码、函数定义、分析该定义及其关联评论的结果组成
-
Automatic semantic augmentation of language model prompts (for code summarization) ARXIV 2024
- CEDAR[130]
- 使用设计好的提示模板将代码演示、查询和自然语言指令整合到提示中
-
Retrieval-based prompt selection for code-related few-shot learning ICSE 2023
- LLMLingua[183]
4.3.2 解码调优
- 在生成器处理过程中添加额外控制,可以通过
- 调整超参数来实现更大的多样性
- 以某种形式限制输出词汇
- 比如:
- InferFix[131]
- 通过调整解码器的温度来平衡结果的多样性和质量
-
Inferfix: End-to-end program repair with llms, FSE 2023
- SYNCHROMESH[120]
- 通过实现一个完成引擎来限制解码器的输出词汇,以消除实现错误
-
Synchromesh: Reliable code generation from pre-trained language models,ICLR 2022
- InferFix[131]
4.3.3 微调生成器
- 微调生成器可以增强模型在具有更精确的领域知识或更好地与检索器匹配方面的能力
- 比如
- APICoder[129]
- 使用API信息和代码块与重新洗牌的新文件一起微调生成器CODEGEN-MONO 350M
-
When language model meets private library EMNLP 2022
- CARE[158]
- 首先使用图像数据、音频数据和视频-文本对来训练编码器
- 然后以减少字幕损失和概念检测损失为目标微调解码器(生成器),在此过程中编码器和检索器被冻结。
- RetDream[48]
- 使用渲染图像微调LoRA适配器[188]
- APICoder[129]
4.4 结果增强
- 在许多场景中,RAG的最终结果可能无法达到预期效果,一些结果增强技术可以帮助缓解这个问题。
4.4.1 重写输出
- SARGAM[189]
- 通过使用Levenshtein Transformer对生成的代码相关任务结果进行修改
- 通过分类删除分类器、占位符分类器和插入分类器,以更好地适应实际代码上下文。
-
Concept-aware video captioning: Describing videos with effective prior information TIP 2023
- CBR-KBQA[52]
- 通过将生成的关系与知识图谱中查询实体的本地邻域中呈现的关系对齐,修订结果
-
Case-based reasoning for natural language queries over knowledge bases,EMNLP 2021
4.5 RAG流程增强
4.5.1 自适应检索
- 对RAG的一些研究和实践表明,检索并不总是对最终生成结果有益。
- 当模型本身的参数化知识足以回答相关问题时,过度检索会导致资源浪费,并可能增加模型的混乱。
4.5.1.1 基于规则的方法
- FLARE[191]
- 在生成过程中通过概率主动决定是否以及何时进行搜索
-
Active retrieval augmented generation 2023
- Efficient-KNNLM[36]
- 结合了KNN-LM和NPM的生成概率,并使用超参数λ来确定生成和检索的比例
- Mallen等人[192]
- 在生成答案之前对问题进行统计分析,允许模型直接回答高频问题,并为低频问题引入RAG
-
When not to trust language models: Investigating effectiveness of parametric and non-parametric memories,ACL 2023
- Jiang等人[193]
- 研究了模型不确定性、输入不确定性和输入统计,以全面评估模型的信心水平。
- 最终,基于模型的信心水平,做出是否检索的决定。
- Kandpal等人[194]
- 通过研究训练数据集中相关文档的数量与模型掌握相关知识的程度之间的关系,帮助确定是否需要检索。
4.5.1.2 基于模型的方法
- Self-RAG[126]
- 使用训练好的生成器基于不同指令下的检索令牌决定是否进行检索
- 通过自我反思令牌评估检索文本的相关性和支持程度。
- 最后,基于批判令牌评估最终输出结果的质量
-
Selfrag: Learning to retrieve, generate, and critique through self-reflection 2023
- Ren等人[195]
- 使用“判断提示”来确定LLMs是否能回答相关问题以及它们的答案是否正确,从而协助确定检索的必要性
-
Investigating the factual knowledge boundary of large language models with retrieval augmentation 2023
- SKR[196]
- 利用LLMs自身的能力预先判断它们是否能回答问题,如果能回答,则不进行检索。
-
How can we know When language models know? on the calibration of language models for question answering TACL 2023
4.5.2 迭代RAG
- RepoCoder[197]
- 应用迭代检索-生成流程,以更好地利用代码完成任务中不同文件中散布的有用信息。
- 它在第i次迭代中用之前生成的代码增强检索查询,以获得更好的结果
-
Self-knowledge guided retrieval augmentation for large language models EMNLP 2023
- ITER-RETGEN[198]
- 以迭代的方式协同检索和生成。
- 生成器当前的输出在某种程度上可以反映它仍然缺乏的知识,而检索可以检索缺失的信息作为下一轮的上下文信息,这有助于提高下一轮生成内容的质量。
-
Enhancing retrieval-augmented large language models with iterative retrieval-generation synergy EMNLP 2023
5 RAG在不同模态上的具体应用
5.1 文本
| 问题回答 |
|
| 事实验证 |
|
| 常识推理 |
|
| 人机对话 |
|
| 神经网络机器翻译 | 将文本从源语言翻译成目标语言的自动化过程 |
| 事件提取 |
|
| 摘要 | 从冗长的文本中提取重要信息,并产生一个简洁,连贯的概括主题的摘要 |
5.2 代码
| 代码生成 | 将自然语言描述转换为代码实现,是一个从文本到代码的过程 |
| 代码总结 | 其目标是将代码转换为自然语言描述,这是一个代码到文本的过程 |
| 代码补全 | 码补全在编码层面可以被认为是“下一个句子预测”任务 |
| 自动程序修复 | 存在bug的代码可能需要花费大量的精力来修复。自动程序修复技术则利用生成模型输出正确的版本 |
5.3 音频
| 音频生成 | 音频生成的目标是通过自然语言输入来生成对应的音频 |
| 音频字幕 | 音频字幕的目标是用音频数据生成自然语言,这是一个序列到序列的任务 |
5.4 图像
| 图像生成 | RAG通过整合信息检索系统来增强生成模型。 对于图像生成,这意味着利用检索数据生成高保真度和可靠的图像,即使是罕见的或看不见的实体也可以生成 |
| 图像字幕 | 基于检索增强的图像字幕是一种受检索增强语言生成启发的创新方法。 与仅依赖于输入图像的传统图像字幕方法不同,这种新技术通常通过利用从数据存储中检索到的一组字幕以及图像本身来生成描述性句子。 |
5.5 视频
| 视频字幕 | 用描述性的话语来描述视觉内容 |
| 视频生成 | 文本到视频生成是在给定的自然语言描述下生成视频 |
5.6 知识
| 知识库问答 | 利用知识库来确定问题的正确答案 |
| 知识图谱补全 | 知识图谱由三元组组成,包括头部实体、关系和尾部实体。 知识图谱补全的任务是预测不完整三元组中缺失的实体 |
6 评估标准
- Chen等人[252]提出了一个RAG基准,该基准分别从噪声鲁棒性、负面拒绝性、信息整合性和反事实鲁棒性四个方面对RAG进行评估。
- 噪声鲁棒性评估LLM是否能够从包含噪声信息的文档中提取必要的信息
- 噪声信息与输入查询相关,但对回答查询无用
- 负面拒绝性衡量LLM是否会在检索到的内容不够时拒绝响应查询
- 信息整合评估LLM是否能够通过整合多个检索内容来获取知识并做出响应
- 反事实鲁棒性是指LLM识别检索内容中与事实不符的错误的能力。
- 噪声鲁棒性评估LLM是否能够从包含噪声信息的文档中提取必要的信息
- 另外三个基准,RAGAS [253], ARES [254] andTruLens [255]
,分别考虑了三个不同的方面:可信度,答案相关性和上下文相关性- 当正确答案能从检索到的事实推断出来时,可信度关注结果中的错误事实
- 回答相关性衡量生成的结果是否真正解决了问题
- 上下文相关性判断检索到的内容是否包含尽可能多的知识来回答查询,以及尽可能少的无关信息
7 RAG的局限性
7.1 检索结果中的噪声
- 检索结果中不可避免地存在一定程度的噪声,表现为不相关的对象或误导性信息
- 尽管常识是提高检索的准确性,将有助于 RAG 的有效性,但最近的一项研究[258]表明,噪声检索结果可能反而有助于提高生成质量
- 1个可能的解释是,检索结果的多样性对于快速构建也可能是必要的。
- 因此,噪声对检索结果的影响仍然不确定,导致人们对采用哪种度量进行检索以及如何促进检索器和生成器之间的交互仍感到困惑。
7.2 额外开销
- 虽然在某些情况下检索可以帮助降低生成成本,但检索的结合有时会带来不可忽略的开销
- 当与复杂的增强方法结合使用时,如递归检索和迭代RAG,额外开销将变得更明显。
- 此外,随着检索规模的扩大,与数据源相关的存储和访问复杂性也会增加。
7.3 检索和生成的交互
- 鉴于检索器和生成器的目标不一致,并且两个模型可能不共享相同的潜在空间,设计和优化这两个组件之间的交互会遇到挑战
- 虽然已经提出了许多方法来实现有效的 RAG,这些方法要么将检索和生成过程分开,要么在中间阶段将它们集成
- 前者更加模块化,但后者可能会从联合训练中受益
- 到目前为止,还缺乏对不同场景下不同交互方式的充分比较
7.4 长上下文生成
- 最近出现了一个观点:“像 Gemini 1.5 这样的长上下文模型将取代 RAG”。
- 然而,这种说法并不成立——RAG 在管理动态信息方面表现出更大的灵活性,涵盖最新的和长尾知识。
- RAG 未来将利用长上下文生成来实现更好的性能,而不是简单地被它淘汰。
8 未来趋势
8.1 关于RAG方法、增强和应用的更高级研究
- 开发RAG更先进的方法、增强和应用
- 现有的工作已经探索了检索器和生成器之间的各种交互模式。
- 然而,由于这两个组件的优化目标不同,实际的增强过程对最终的生成结果有很大影响。
- 对更先进的增强基础的研究有望充分释放 RAG 的潜力。
- RAG 是一种通用技术,已应用于多种模式和任务。
- 然而,大多数现有工作直接将外部知识与特定的生成任务相结合,而没有彻底考虑目标领域的关键特征。
- 因此,对于未充分利用 RAG 功能的生成任务,设计适当的 RAG 将是更利于模型表现的。
8.2 高效部署和处理
- 目前,已经提出了几种针对LLM的基于查询的RAG部署解决方案,例如LangChain和LLAMA-Index。
- 然而,对于其他类型的 RAG 和生成任务,缺乏即插即用的解决方案。
- 此外,考虑到检索带来的额外开销,并考虑到检索器和生成器的复杂性将继续增长,在 RAG 中实现高效处理仍然是一个挑战,需要有针对性的系统优化。
8.3 结合长尾和实时知识
- 虽然RAG的一个关键动机是利用实时和长尾知识,但知识更新和扩展的管道仍未探索。
- 许多现有的工作仅用生成器的训练数据构成检索源,从而忽略了检索本来可以提供的动态和灵活的信息优势。
- 因此,设计一个具有不断更新的知识或灵活的知识源的有用的RAG系统,以及相应的系统级优化,是一个不断发展的研究方向。
8.4与其他技术相结合
- 本质上,RAG 与其他技术正交,这些技术的目标都是提高 AIGC 的有效性,包括微调、强化学习、思想链、基于代理的生成和其他潜在的优化。
- 然而,同时应用这些技术的探索仍处于早期阶段,需要进一步研究深入算法设计并充分发挥其潜力。