本文参考TI的一种适用于汽车雷达的聚类算法研究和实现.pdf文档,原文链接如下:https://www.ti.com.cn/cn/lit/an/zhca739/zhca739.pdfts=1672973254109&ref_url=https%253A%252F%252Fwww.google.com.hk%252F。
由于不涉及硬件,因此本文仅对算法部分进行分析,需要用到硬件分析部分的读者,可以直接参考原文。
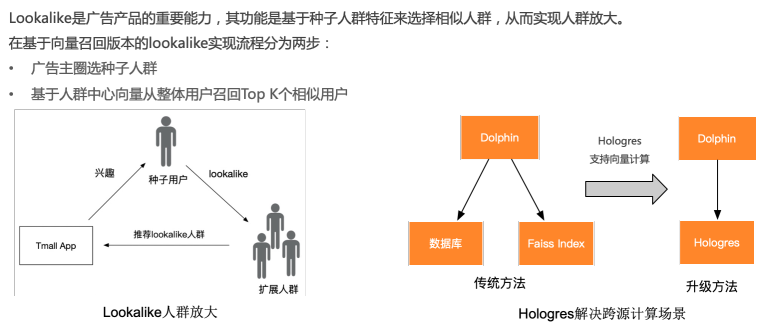
1.概述
雷达接收处理包括射频前端,基带信号处理和后处理算法三部分:
(1)射频前端完成高频雷达接收信号的模拟域信号处理和数模转换(ADC);
(2)基带信号处理在零中频上完成雷达接收信号的数字信号处理(DSP)和目标检测;
(3)在目标检测之后的高层算法被统称为后处理算法,如聚类(Clustering)、 关联(Association)、跟踪(Tracking)、分类(Classification)等。
这三部分是雷达工程师需要重视的,建议进行系统性地学习,多看、多思考、多动手实践。本文主要是针对后处理算法中的一种聚类算法做分析,解决汽车雷达目标由于目标尺寸、雷达发射系数(RCS)和检测算法的不同所带来的一系列问题。
聚类算法的本质是“物以类聚,人以群分”思想,只有“志同道合”的点云才会被归为一类。本文选取了 DBSCAN(Density-Based Spatial Clustering of Application with Noise)作为适合汽车雷达的聚类算法,重点研究了这种算法的性能和参数敏感性,并提出了一种简单可行的参数调整(有点类似于自适应)方法。
2.算法背景
线性快速频率调制连续波(Linear Fast FMCW) 是一种频率随时间快速线性变化(斜率在几十 MHz/us)的雷达波形,由于它可以提供较高的分辨率,同时有效地解决距离-速度模糊性的问题,当前已经成为主流的汽车雷达波形。
常用的信号处理链流程如下图所示:

(图1:雷达信号处理链)
首先,通过第一维和第二维 FFT 计算获得目标距离和速度,然后采用特定的角度估计算法(例如 FFT,MUSIC 等)来获得目标的角度,最后再通过特定的目标检测算法(例如 CFAR-CA、CFAR-OS 等)从噪声中检测获得反射点。随着目标的尺寸、雷达发射系数(RCS)和检测算法的不同,一个物体在目标检测后可能产生从几个到几百个不同的反射点。
如果通过聚类算法分析这些反射点的内部结构,将属于同一 个物体的反射点归为一个簇,这样每一个检测到的物体都形成一个簇,最后再通过对聚类以后的簇进行目标跟踪和分类, 可以获得可靠的物体的距离和移动速度。
3.汽车雷达聚类算法
聚类在无监督机器学习领域是一个非常热门的研究课题,近年来出现了许多的算法。现有的聚类算法可以大致分为:原型聚类(Prototype-based clustering)、密度聚类 (Density-based clustering) 和层次聚类 (Hierarchical clustering)三个类别。
(1)原型聚类
通常,假设聚类结构能通过一组原型刻画,在现实聚类算法中比较常用。通常情况下,算法先对原型进行初始化,然后对原型进行迭代更新求解。采用不同的原型表示,不同的求解方式,将产生不同的算法。常见的原型聚类算法有 k 均值方法 (k-means)、高斯混合聚类方法 (Mixture-of-Gaussian) ,在数据挖掘领域被广泛应用,但是这些算法都要求在聚类之前就确定输出的簇的数量。对于汽车雷达来说,也就是要求在聚类之前就确定目标的数量,这显然是无法做到的,因为汽车雷达无法确定当前的目标数量是多少。
(2)层次聚类
层次聚类尝试在不同层次对数据集进行划分,从而形成树形的聚类结构。层次聚类可以采用“自下而上”的聚类策略,也可以采用“自上而下”的聚类策略。AGNES 方 法 (AGglomerative NESting)是一种常用的“自下而上”的层次聚类算法。然而这种算法面临和原型聚类相同的问 题,也需要在聚类之前确定输出的簇的数量,因此也无法直接应用到汽车雷达上,因此就只剩下了密度聚类。
(3)密度聚类
密度聚类(Density-based clustering)没有其它两种聚类的限制,不需要事先确定簇的数量。密度聚类假设簇的 结构能通过目标点分布的紧密程度来确定。在密度聚类中,簇被认为是数据空间中目标点密集的区域,在簇之间出 现的低密度的目标点被认为是噪声. 这些簇可以有任意的形状,并且簇内的目标点也可以任意分布,这一点和汽车 雷达上的检测目标特性十分接近。汽车雷达对应同一个目标的检测点之间距离接近,并且这些点的密度分布是一定 的(这个密度分布和物体的反射特性相关)。因为具备以上这些特性,密度聚类更加适合于汽车雷达的应用,DBSCAN 算法是一种常用的密度聚类算法(可以清晰地知道,DBSCAN能够用于汽车雷达的本质原因)。
4.聚类算法指标
一个好的聚类结果的目标点应该具有高的簇内相似性和低的簇间相似性,在低维度数据集上, 聚类性能的好坏通过可视化的数据分布图就可以直观的看出来,但是通过度量指标来定量地衡量聚类性能的好坏更加准确。
参考文献[2] 给出了常用的聚类性能度量 DI (Dunn Index), DBI (Davies-Bouldin Index) ,这两种度量在原理上类似,本文选择 DI 作为分析聚类性能的度量指标。假设数据集𝐷𝐷 = {𝑥1, 𝑥2, … , 𝑥𝑚}被划分成了𝑘个簇 𝐶 = {𝐶1, 𝐶2,… , 𝐶𝑘}, DI 的定义如下:
D I = min 1 ≤ i ≤ k { min j ≠ i ( d min ( C i , C j ) max 1 ≤ l ≤ k diam ( C l ) ) } D I=\min _{1 \leq i \leq k}\left\{\min _{j \neq i}\left(\frac{d_{\min }\left(C_i, C_j\right)}{\max _{1 \leq l \leq k} \operatorname{diam}\left(C_l\right)}\right)\right\} DI=min1≤i≤k{minj=i(max1≤l≤kdiam(Cl)dmin(Ci,Cj))}
上式中的分母对应的是所有簇内目标点之间的最大距离,分子对应的是所有簇间目标点之间的最小距离。显然同于同一个数据集,一个聚类结果对应的 DI 越大,聚类的性能越好。即:最大距离越小,说明点云越集中,则点云越相似。
5.DBSCAN算法分析
5.1 算法定义
DBSCAN算法比较容易理解,它基于一组“邻域” (neighborhood) 参数(𝜀, 𝑀inPts)来刻画样本分布的紧密程度。给定数据集𝐷 = {𝑥1, 𝑥2, … , 𝑥𝑚}, 定义下面几个概念:

DBSCAN 算法先任选数据集中的一个核心对象为种子 (seed), 将它的 ε-邻域 中的所有样本加入一个簇,新加入的样本如果是核心对象,再将这个核心对象的 ε-邻域中的所有样本加入本簇。通过这种递归搜索,将所有密度相连的样本归入一个簇。如果此时数据集中还有未处理的核心对象,再重复上述的过程开始一个新簇的搜索。DBSCAN 算法的伪代码描述如下图所示:

(图2:DBSCAN算法描述)
5.2 算法代码
读者根据上述算法流程编写仿真代码应该是不难的,这也是一名工程师必备的职业素养。如果实在有困难,那可以参照下面的代码(https://blog.csdn.net/yuanshixin_/article/details/117409961),这也是网友编写的,调皮哥验证过,好使。
clc;clear all;close all;
%% 数据
X1 =[5.1,3.5,1.4,0.2;%,Iris-setosa
4.9,3.0,1.4,0.2;
4.7,3.2,1.3,0.2;
4.6,3.1,1.5,0.2;
5.1,3.7,1.5,0.4;
4.6,3.6,1.0,0.2;
5.1,3.3,1.7,0.5;
5.0,3.6,1.4,0.2;
5.4,3.9,1.7,0.4;
4.6,3.4,1.4,0.3;
5.0,3.4,1.5,0.2;
4.4,2.9,1.4,0.2;
4.9,3.1,1.5,0.1;
5.4,3.7,1.5,0.2;
4.8,3.4,1.6,0.2;
4.8,3.0,1.4,0.1;
4.3,3.0,1.1,0.1;
5.8,4.0,1.2,0.2;
5.7,4.4,1.5,0.4;
5.4,3.9,1.3,0.4;
5.1,3.5,1.4,0.3;
5.7,3.8,1.7,0.3;
5.1,3.8,1.5,0.3;
5.4,3.4,1.7,0.2;
6.4,3.2,4.5,1.5;%Iris-versicolor
6.9,3.1,4.9,1.5;
5.5,2.3,4.0,1.3;
6.5,2.8,4.6,1.5;
5.7,2.8,4.5,1.3;
6.3,3.3,4.7,1.6;
4.9,2.4,3.3,1.0;
4.9,2.4,3.3,1.0;
6.6,2.9,4.6,1.3;
5.2,2.7,3.9,1.4;
5.0,2.0,3.5,1.0;
5.9,3.0,4.2,1.5;
6.0,2.2,4.0,1.0];
X=X1(:,3:4);
A = X;
%% 观察数据距离,估计epsilon
[index,Dist] = knnsearch(A(2:end,:),A(1,:));
Kdist(1) = Dist;
for i = 1:size(A,1)
[index,Dist] = knnsearch(A([1:i-1,i+1:end]😅,A(i,:));
Kdist(i) = Dist;
end
sortKdist = sort(Kdist,‘descend’);
distX = 1:size(A);
plot(distX,sortKdist,‘r±’);
grid on;
%% 运行DBSCAN
% parament1
epsilon = 0.15;
minPts = 3;
[IDC,isnoise] = DBSCAN(epsilon,minPts,A);
PlotClusterinResult(A,IDC,epsilon,minPts);
% parament2
epsilon= 0.25 ;
minPts= 3 ;
[IDC2,isnoise2] = DBSCAN(epsilon,minPts,A);
PlotClusterinResult(A,IDC2,epsilon,minPts);
function [IDC,isnoise] = DBSCAN(epsilon,minPts,X)
% DBSCAN
C = 0;
D = pdist2(X,X); % 各元素之间距离
IDC = zeros(size(X,1),1);
visited = false(size(X,1),1); % 访问标志
isnoise = false(size(X,1),1); % 噪声
for i = 1:size(X,1)
if ~visited(i)
visited(i) = true;
Neighbors = find(D(i,:)<=epsilon); % 找领域样本
if numel(Neighbors)<minPts
isnoise(i) = true;
else
C = C + 1;
[IDC,isnoise] = expandCluster(i,Neighbors,C,IDC,isnoise); % 以核心对象X(j)扩展簇
end
end
end
function [IDC,isnoise] = expandCluster(i,Neighbors,C,IDC,isnoise)
% 针对核心对象X(i)进行扩展
IDC(i) = C; % 将X(j)的领域元素规定为族C
k = 1;
while true
j = Neighbors(k);
if ~visited(j)
% 针对未访问元素继续寻找领域样本
visited(j) = true;
Neighbors2 = find(D(j,:)<=epsilon);
if numel(Neighbors2) >= minPts
Neighbors = [Neighbors,Neighbors2]; % X(j)也是核心对象
end
end
IDC(j) = C; %
k = k +1;
if k > numel(Neighbors)
break;
end
end
end
end
function PlotClusterinResult(X, IDC,epsilon,minPts)
figure;
k=max(IDC);
Colors=hsv(k);
Legends = {};
for i=0:k
Xi=X(IDC==i,:);
if i~=0
Style = ‘x’;
MarkerSize = 8;
Color = Colors(i,:);
Legends{end+1} = [‘Cluster #’ num2str(i)];
else
Style = ‘o’;
MarkerSize = 6;
Color = [0 0 0];
if ~isempty(Xi)
Legends{end+1} = ‘Noise’;
end
end
if ~isempty(Xi)
plot(Xi(:,1),Xi(:,2),Style,‘MarkerSize’,MarkerSize,‘Color’,Color);
end
hold on;
end
hold off;
axis equal;
grid on;
legend(Legends);
legend(‘Location’, ‘NorthEastOutside’);
title(['DBSCAN Clustering (\epsilon = ’ num2str(epsilon) ', MinPts = ’ num2str(minPts) ‘)’]);
end
执行效果:


(图3:DBSCAN聚类结果)
5.3 参数敏感性分析
通过上述的代码,相信读者也能够看出DBSCAN算法的性能对这两个参数非常敏感,因此如何设置算法的入参对聚类的效果非常重要,输入不合适的参数将会产生错误的聚类结果。
图 4 也给出了一个在不同入参下 DBSCAN 聚类结果的例子。在子图(1)的原始的数据集中我们很容 易发现存在 5 个簇,子图(2)的聚类结果输出了 5 个簇,比较接近真实的场景。子图(3)因为选取了过大的𝑀inPts 将原本比较稀疏的原始数据集中右上角的簇错误地分成了 2 个簇,而子图(4)因为选取了过小的ϵ导致聚类结果中出 现了过多的簇划分,并且错误地将原始数据集中右上角的簇当成了噪声。同样通过对子图(2),(3),(4)的聚类结果 计算的 DI 分别为 0.8323, 0.1234 和 0.1145,同样说明子图(2)的聚类效果比较好,而子图(3) 和(4)的聚类效 果不太令人满意。

图4:DBSCAN 参数敏感性 (1)原始数据(左上角), (2)MinPts=5, 𝜺=0.2 下聚类结果(右上角), (3)MinPts=10, 𝜺=0.2 下聚类结果(左下角),(4)MinPts=5, 𝜺=0.1 下聚类结果(右下角)
5.4 参数调整策略
大部分关于 DBSCAN 的文献都讨论的是算法本身,而很少涉及如何为算法选择合适的参数,而从上一节的介绍中 可以看到参数的选取对聚类结果非常重要。
汽车雷达使用 DBSCAN 时需要根据探测场景和目标检测算法的性能对 参数有针对性地进行一些调整。实践中,通常选取一些典型的测试场景,对 DBSCAN 的入参进行调教以获得期望的聚类效果,最后对不同测试场景下的理想参数进行综合来确定车上实际使用的参数,比如:道路上的两个靠近的行人不被聚类为一个簇,以及一辆汽车因为点云太稀疏不被聚类为多个簇,主要是想解决掉这个问题。
本文将提出一种创新的方法针对一个特定测试场景,确定最优的𝑀inPts和ϵ。𝑀inPts是区别于噪声的一个簇内的最少点数,在理论上噪声和它的邻点之间的距离要大于目标点和它的邻点之间的距离。
如果定义点p和它的第k个最近的邻点之间的k近邻距离为k_neighbor_dis§,理论上噪声点的k近邻距离要大于目标点的k近邻距离。如果对一个数据集中的所有点分别计算k近邻距离并进行从大到小排序,k近邻距离较大的一些点对应的是噪声,而k近邻距离较小的一些点对应的是簇中的目标点。
另外,如果分别计算一个数据集中所有 点的 1 近邻,2 近邻,…k近邻距离,并对近邻距离最大的n 个点的近邻距离分别进行平均,会发现这个平均值随 着k的增加而增加,但是平均值的增量随着k的增加而降低,会发现一个特定的k,超过这个k后,k + 1近邻距离, k + 2近邻距离…会越来越接近。
从理论上讲,这个k值接近于合理的𝑀inPts值,因为对于近邻距离最大的 n 个点 (主要是噪声点),其k近邻,k + 1近邻, k + 2近邻距离趋向接近,也就是对应的k近邻,k + 1近邻,k + 2近邻更 加接近于簇中的目标点。
基于这种思想,设计了下面的𝑀inPts搜索算法:
-
计算数据集𝐷中所有样点的 1 近邻,2 近邻,…n 近邻距离,并对所有的近邻距离从大到小进行排序 ;
-
选定一个 n 值,从 1)中得到的 1 近邻,2 近邻,…n 近邻距离选择出最大的 n 个值,并求平均值 ;
-
计算 2)中得到的相邻两个平均值之间的差值,找到一个𝑘值使得𝑘𝑘近邻的平均值大于𝑘 + 1近邻的平均值,并 且𝑘近邻的平均值减去𝑘 + 1近邻的平均值最小
-
定义𝑀inPts= 𝑘 − 1。
上述过程本质上讲就是一个用统计的思路,来区分噪声和目标点,得到二者之间的大概界限,然后把这个界限作为𝑀inPts。
图 5 中画出了对于图 4 数据集中最大的 3 个𝑘 + 1近邻和𝑘𝑘近邻的平均值之间的差值(例如图中第一个柱状图对应的是 3 个最大的 2 近邻距离平均值减去 3 个最大的 1 近邻距离平均值的差值)。从这张图中我们可以发现𝑘 = 6下有最小的近邻距离增量,因此建议的𝑀inPts设置为 5。

(图 5. 图 4 数据集的 k+1 近邻和 k 近邻距离中最大 n 个数值的平均值之差(n=3))
5.5 Optics算法
𝑀inPts谈完了,我们继续来搞ϵ。
ϵ决定了聚类时邻域搜索的半径,DBSCAN 算法中一个点的ϵ-邻域中的邻点的数目大于𝑀inPts的时候被定义为核心 节点,并且这个点和所有它的ϵ-邻域中的点都被归入同一个簇。通常一个数据集越密集,聚类时选取的ϵ应该越小, 因此在调整ϵ参数的时候,需要分析数据集的密度结构。怎么分析?是一个问题。
参考文献[3]介绍了一种 OPTICS (Ordering Points To Identify the Clustering Structure) 算法可以获得一个数据集的密度信息。作者基于 OPTICS 算法进行了一些 改进,提出了一种更有效的ϵ搜索的算法。作者设计的ϵ搜索算法分为两步:
第一步通过改进的 OPTICS 算法对数据集的密度信息进行分析,得到一个大致的ϵ搜索区间;
第二步在第一步获得的ϵ搜索区中,按照一定的步长尝试进行DBSCAN 聚类,对聚类的结果分别计算DI 进行评估,从而选择出最优的ϵ。
作者给出的改进的 OPTICS 算法的伪代码描述如图 6 所示:

(图6:改进的 OPTICS 算法描述)
对于图 4 中的数据集,采用改进的 OPTICS 算法对样本重新排序后输出的包含可达距离的曲线如图 7 所示。

(图7:图 4 数据集采用改进的 OPTICS 算法排序输出的可达距离)
图中的峰值突起对应的是一个簇中样本和其前序样本(通常是另一个簇中的样本) 之间的可达距离。从图中可以直观地发现,簇中样本之间的可达距离(对应曲线的底部)要远远小于簇间样本之间的可达距离(对应曲线的峰值突起),同时也能直观的发现数据集中簇中样本之间和簇间样本之间的可达距离的大致范围。可以设置ϵ搜索的大致范围在曲线的最低峰值和底部平均值之间,比如在图 7 中可以设置ϵ的搜索范围为 0.1 到 0.6 之间。
在 0.1 到 0.6 之间选择搜索步长为 0.1,对数据集进行 DBSCAN 聚类, 并计算聚类结果的 DI,可以得到表 1 中对应的 DI 数值。从表 1 中可以发现,ϵ = 0.1时,DI 最小,而对于其他的 ϵ值,DI 较大且取值相同,也就是说采用这些ϵ值的聚类效果都比较理想。
综合本节前面的内容,对于图 4 数据集, 采用MinPts = 5,ε = 0.2 − 0.6是一个比较合理的 DBSCAN 算法入参,这与图 4 本身显示的聚类效果一致。
其实,这里读者可以采用MATLAB自带的OPTICS算法模块(具体见帮助文档)来对上述DBSCAN代码中自带的数据参数进行验证,就能够绘制出与图5类似的图,用于确定DBSCAN的参数。
6.总结
DBSCAN的主要优点有:
(1)可以对任意形状的稠密数据集进行聚类,而K-Means之类的聚类算法一般只适用于凸数据集。
(2)可以在聚类的同时发现异常点,对数据集中的异常点不敏感。
(3)聚类结果没有偏倚,而K-Means之类的聚类算法初始值对聚类结果有很大影响。
(4)DBSCAN不需要输入类别数,而K-Means之的聚类算法需要输入类别数。
DBSCAN的主要缺点有:
(1)如果样本集的密度不均匀、聚类间距差相差很大时,聚类质量较差,这时用DBSCAN聚类一般不适合。
(2) 如果样本集较大时,聚类收敛时间较长,此时可以对搜索最近邻时建立的KD树或者球树进行规模限制来改进。
(3)调参相对于传统的K-Means之类的聚类算法稍复杂,主要需要对距离阈值ϵ,邻域样本数阈值MinPts联合调参,不同的参数组合对最后的聚类效果有较大影响。
参考文献:
1.Sriram Murali and Pankaj Gupta, “FMCW Radar System Overview, Session #1: FMCW Radar Signal Processing”, TI internal document, 2015
2.周志华, “机器学习”, 清华大学出版社,2016, 202-217 页
3.Mihael Ankerst, Markus M. Breunig, Hans-Peter Krieegel and Jorg Sander, “OPTICS: Ordering Points To Identify the Clustering Structure”, in SIG-MOD, 1999, pp49-60
4.https://blog.csdn.net/yuanshixin_/article/details/117409961
5.https://www.ti.com.cn/cn/lit/an/zhca739/zhca739.pdfts=1672973254109&ref_url=https%253A%252F%252Fwww.google.com.hk%252F






![LeetCode[373]查找和最小的K对数字](https://img-blog.csdnimg.cn/img_convert/6a97303eaaaa4f4997fd504504638703.png)