RepVGG: Making VGG-style ConvNets Great Again 是2021 CVPR的一篇论文,正如他的名字一样,使用structural re-parameterization的方式让类VGG的架构重新获得了最好的性能和更快的速度。将RepVGG的设计思想融合进入到yolov5目标检测模型中是否有性能的提升呢?这里也是想基于实地的数据做一下实验探索尝试,首先看下效果图:

改进后的yaml模型文件如下:
#Parameters
nc: 3 # number of classes
depth_multiple: 1 # model depth multiple
width_multiple: 1 # layer channel multiple
#Anchors
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
#Backbone
backbone:
# [from, number, module, args]
[[-1, 1, Focus, [32, 3]], # 0-P1/2
[-1, 1, RepVGGBlock, [64, 3, 2]], # 1-P2/4
[-1, 1, C3, [64]],
[-1, 1, RepVGGBlock, [128, 3, 2]], # 3-P3/8
[-1, 3, C3, [128]],
[-1, 1, RepVGGBlock, [256, 3, 2]], # 5-P4/16
[-1, 3, C3, [256]],
[-1, 1, RepVGGBlock, [512, 3, 2]], # 7-P4/16
[-1, 1, SPP, [512, [5, 9, 13]]],
[-1, 1, C3, [512, False]], # 9
]
#Head
head:
[[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 1, C3, [256, False]], # 13
[-1, 1, Conv, [128, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 1, C3, [128, False]], # 17 (P3/8-small)
[-1, 1, RepVGGBlock, [128, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 1, C3, [256, False]], # 20 (P4/16-medium)
[-1, 1, RepVGGBlock, [256, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 1, C3, [512, False]], # 23 (P5/32-large)
[[17, 20, 23], 1, Detect, [nc, anchors]],
# Detect(P3, P4, P5)
]
首先是BackBone部分:

下图展示了原生模型与改进后的模型在BackBone部分的差异对比。
其次是Head部分:
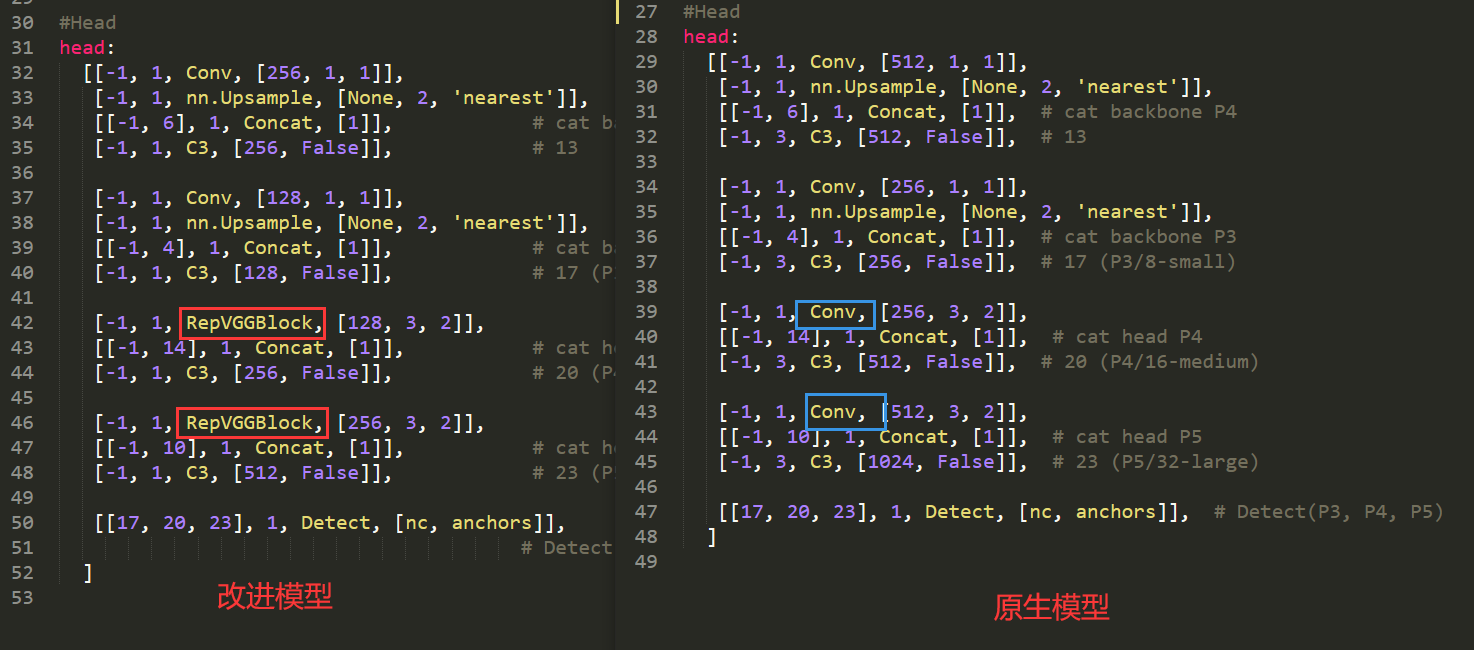
上图框出来了改进后的模型和原生模型的核心差异,其余部分的差异主要是为了适配替换conv模块为RepVGGBlock模块后改变的参数。
接下来看下数据集:

YOLO格式标注数据如下:

实例标注数据如下:
2 0.544141 0.750694 0.205469 0.493056
1 0.414062 0.720139 0.203125 0.554167VOC格式标注数据如下:

实例标注数据如下:
<annotation>
<folder>motorcycle</folder>
<filename>2b482c1a-99b6-4cc5-a98e-a263b3cf2134</filename>
<path>dataset</path>
<source>
<database>Unknown</database>
</source>
<size>
<width>1280</width>
<height>720</height>
<depth>3</depth>
</size>
<segmented>0</segmented>
<object>
<name>person</name>
<pose>Unspecified</pose>
<truncated>1</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>605</xmin>
<ymin>210</ymin>
<xmax>828</xmax>
<ymax>720</ymax>
</bndbox>
</object>
<object>
<name>person</name>
<pose>Unspecified</pose>
<truncated>0</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>377</xmin>
<ymin>192</ymin>
<xmax>551</xmax>
<ymax>554</ymax>
</bndbox>
</object>
<object>
<name>person</name>
<pose>Unspecified</pose>
<truncated>0</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>525</xmin>
<ymin>379</ymin>
<xmax>654</xmax>
<ymax>573</ymax>
</bndbox>
</object>
</annotation>
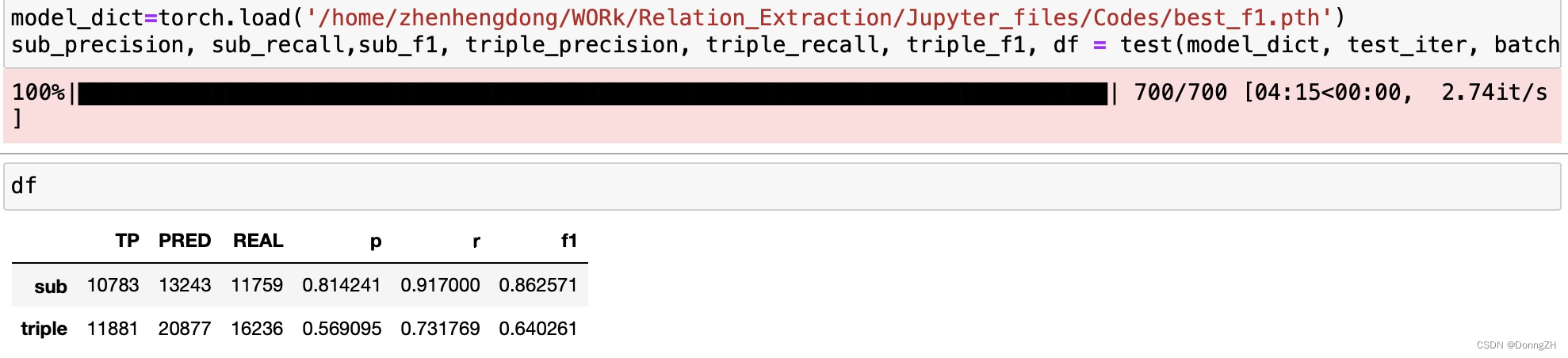
默认设定100个epoch的迭代计算,在CPU模式下完成训练,日志输出如下:

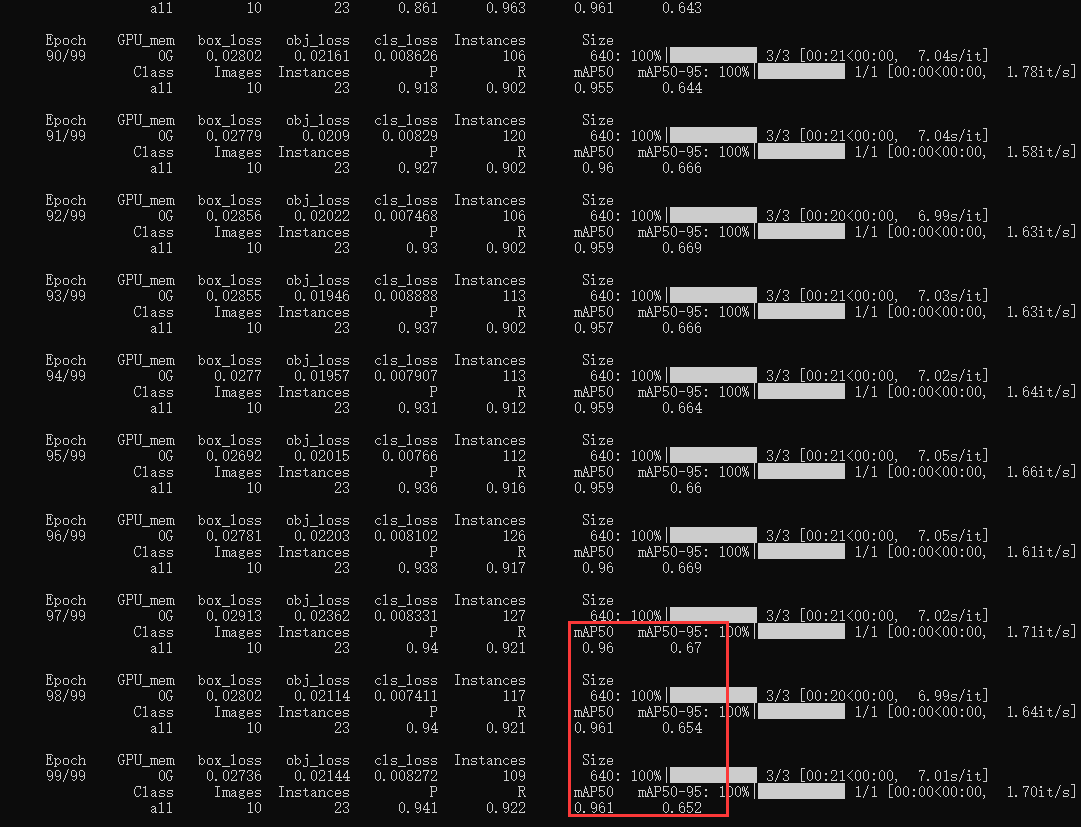
可以看到:最终的检测效果还是很不错的。
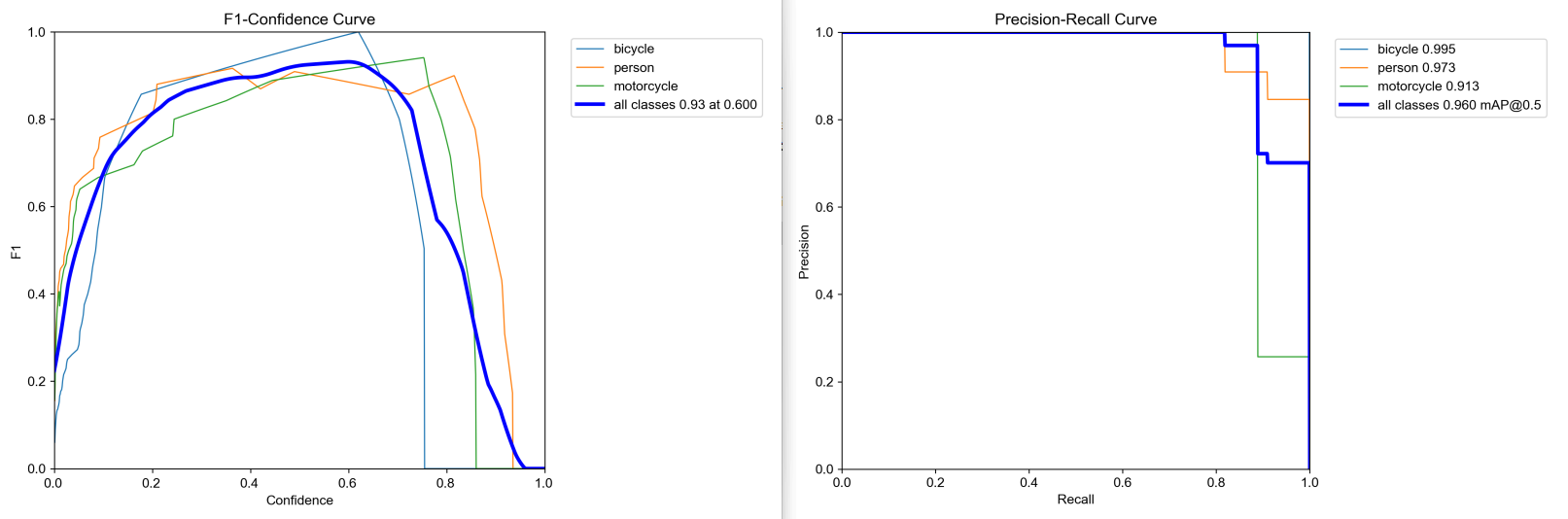
F1值曲线和PR曲线如下所示:
LABEL数据可视化如下:

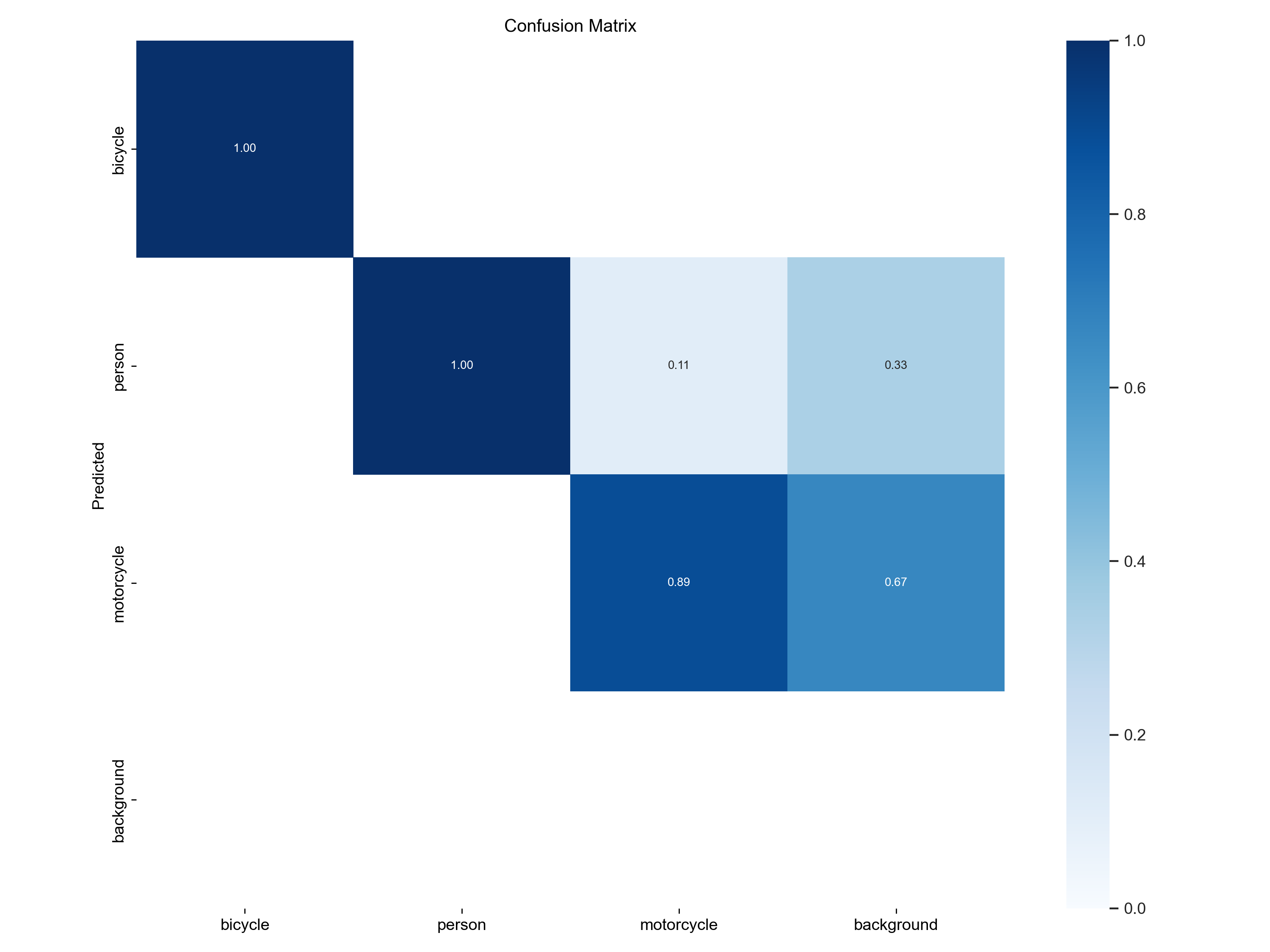
混淆矩阵如下所示:
训练过程评估可视化如下:

训练batch检测样例如下所示:
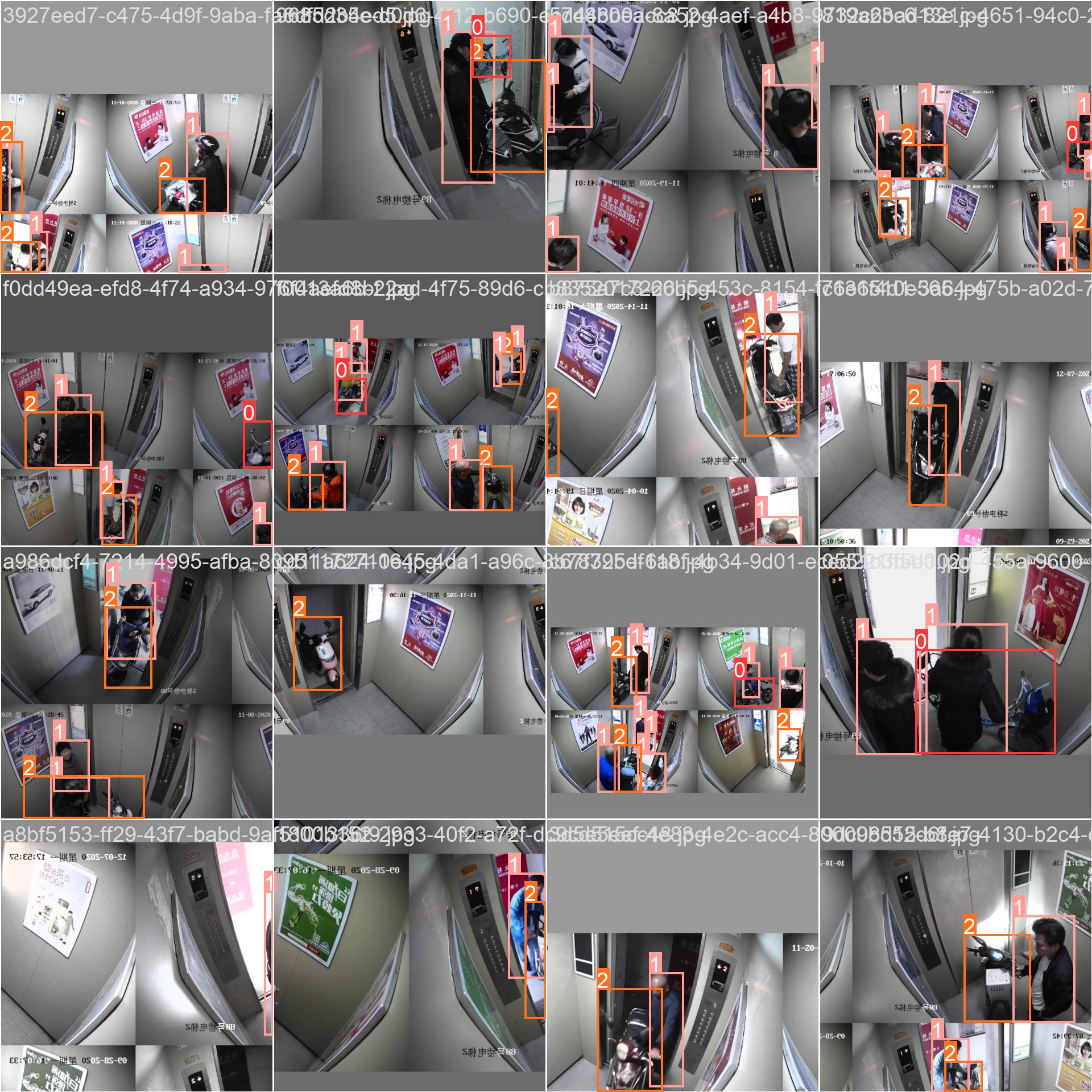
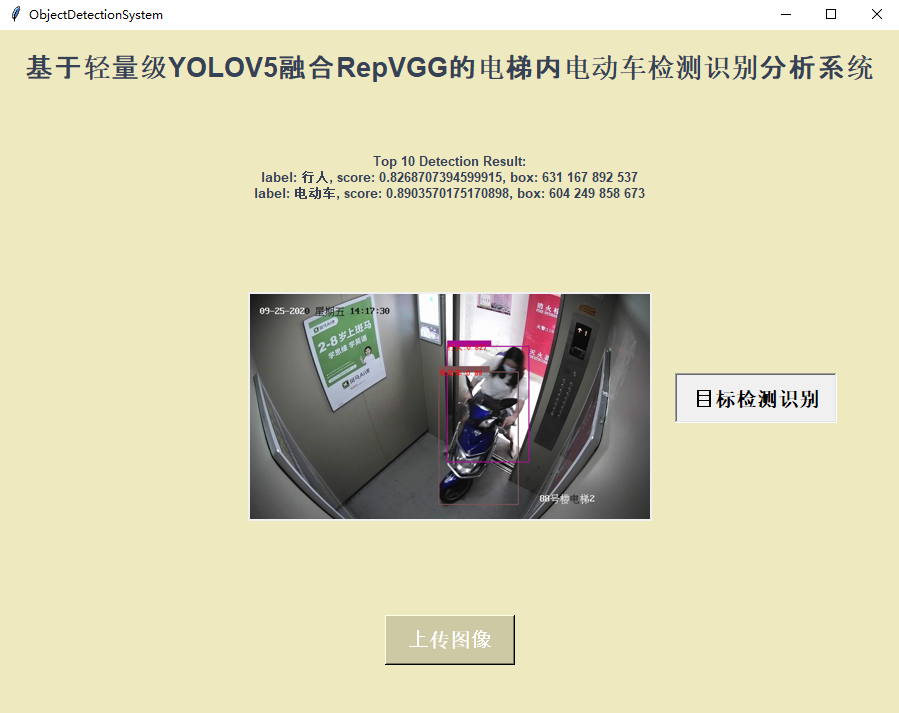
最后我们基于专门的界面实现可视化推理计算如下:

上传图像:

检测推理:


![LeetCode[373]查找和最小的K对数字](https://img-blog.csdnimg.cn/img_convert/6a97303eaaaa4f4997fd504504638703.png)