目录
- 模型推理过程
- KV Cache原理
- KV Cache的存储
模型推理过程
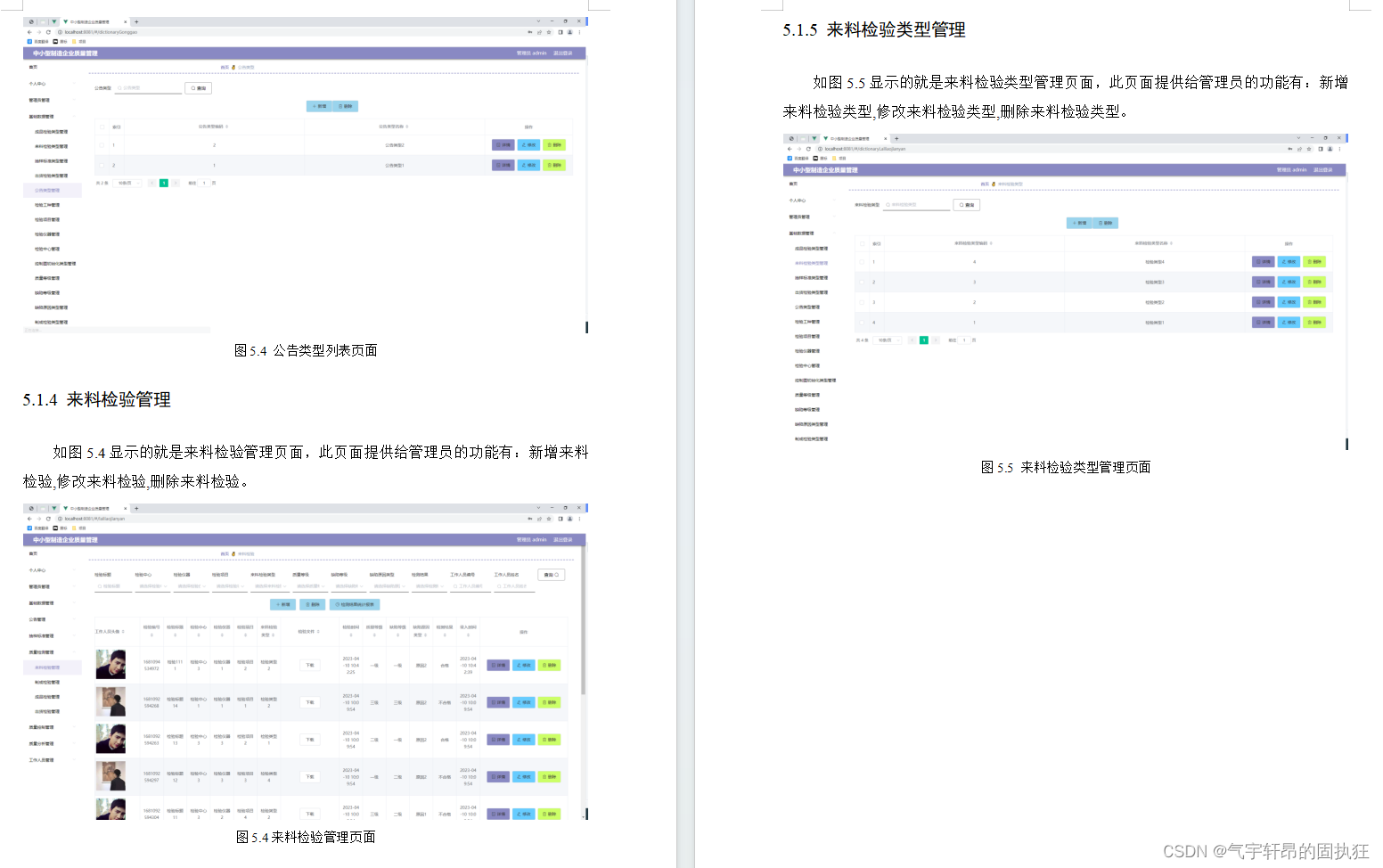
在了解KVCache之前,我们需要知道Transformer类大模型的推理过程。
对于LLM进行一次前向传播也就是生成一个token的过程可以被分解成以下步骤:
- 文本 T i n p u t T_{input} Tinput经过Tokenizer后得到n个Token,即 { T 1 , T 2 , . . . , T n } \{T_1,T_2,...,T_n\} {T1,T2,...,Tn}
- Token经过嵌入层后得到Token Embedding { x 1 0 , x i 0 , . . . , x n 0 } \{x_1^0,x_i^0,...,x_n^0\} {x10,xi0,...,xn0},其中0代表第0层, x x x是D维向量
- Token Embedding 经过L层变换之后,得到 { x 1 L , x i L , . . . , x n L } \{x_1^L,x_i^L,...,x_n^L\} {x1L,xiL,...,xnL}
- generation阶段,将最后一层的最后一个Token Embedding即 x n L x_n^L xnL取出,与lm_head中的vocabulary Embedding { e 1 , e 2 , . . . , e V } \{e_1,e_2,...,e_V\} {e1,e2,...,eV}进行运算,得到概率 { p 1 , p 2 , . . . , p V } \{p_1,p_2,...,p_V\} {p1,p2,...,pV},最后从概率采样中选择一个产生新的 T n + 1 T_{n+1} Tn+1
流程如图所示
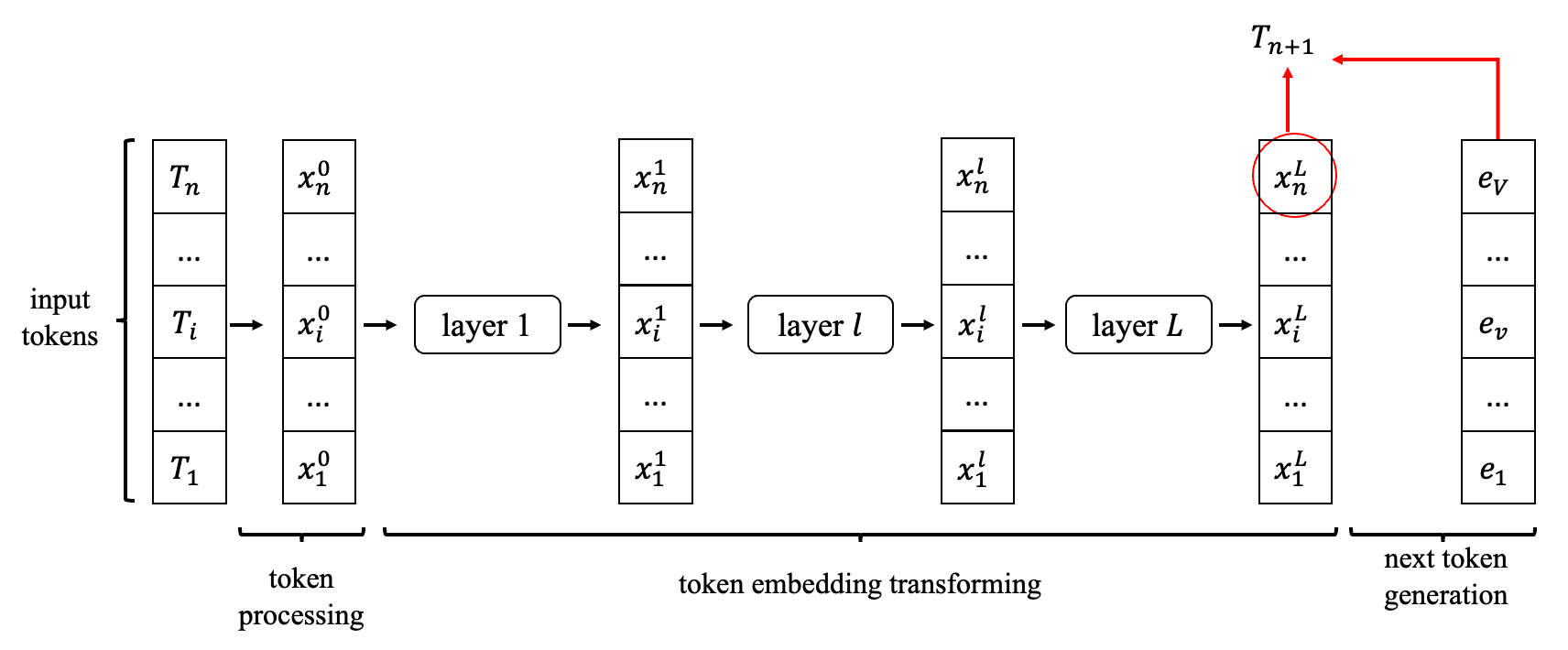
如果我们一直用
T
[
1
,
i
]
T_{[1,i]}
T[1,i]去生成
T
i
+
1
T_{i+1}
Ti+1也是可行的,但很容易发现一个问题,Token Embedding中
[
1
,
i
]
[1,i]
[1,i]这部分的值是不需要重新计算的。
我们发现每次计算 T i + 1 T_{i+1} Ti+1时,只需要额外计算 x i 0... L x_{i}^{0...L} xi0...L的值就可以了。
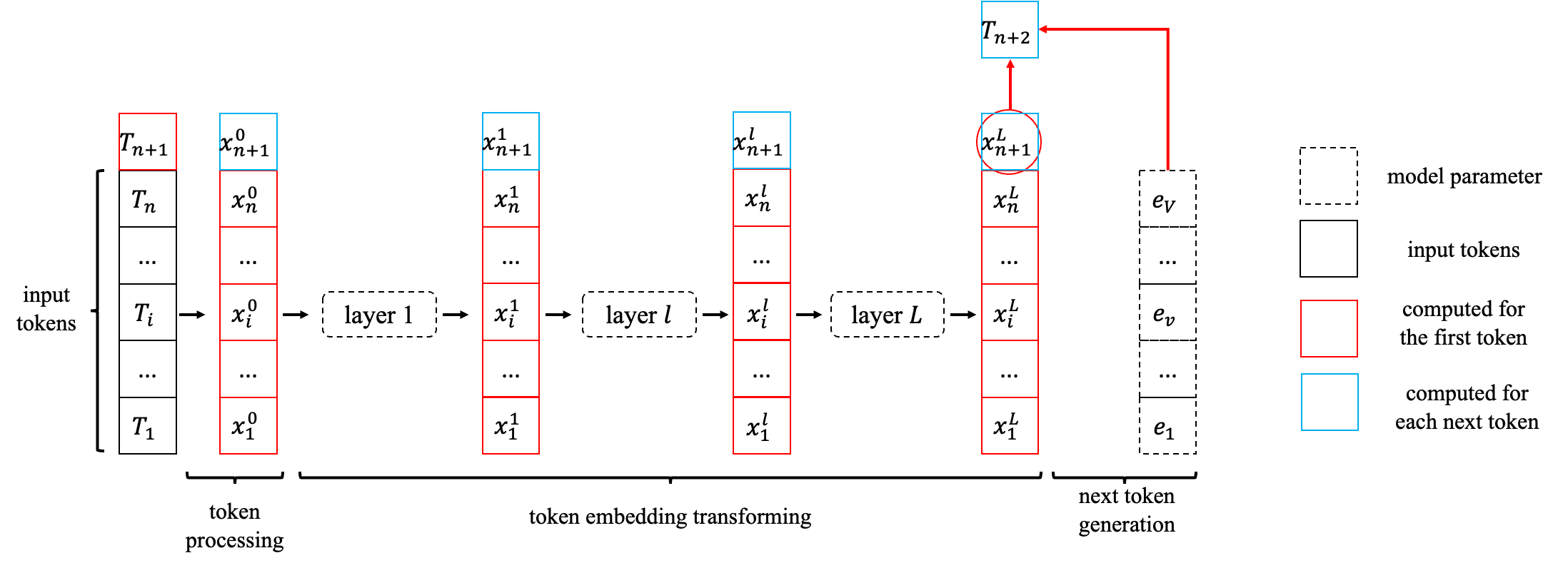
KV Cache原理
当我们有了 { x 1 l , x 2 l , . . . , x n l } \{x_1^l,x_2^l,...,x_n^l\} {x1l,x2l,...,xnl}的数据,再加上新来的 x n + 1 l x_{n+1}^l xn+1l计算 x n + 1 l + 1 x_{n+1}^{l+1} xn+1l+1的计算量只是一次attention query。
我们只关注
x
n
+
1
l
+
1
x_{n+1}^{l+1}
xn+1l+1:
s
i
=
(
W
Q
x
n
+
1
l
)
T
(
W
K
x
i
l
)
,
1
≤
i
≤
n
+
1
s_i = (W_Qx_{n+1}^l)^T(W_Kx_i^l),1≤i≤n+1
si=(WQxn+1l)T(WKxil),1≤i≤n+1
y h = ∑ i = 1 n + 1 s i ∑ j = 1 n + 1 e j W V x i l , 1 ≤ i ≤ n + 1 y_h=\sum_{i=1}^{n+1}\frac{s_i}{\sum_{j=1}^{n+1}e_j}W_Vx_i^l,1≤i≤n+1 yh=i=1∑n+1∑j=1n+1ejsiWVxil,1≤i≤n+1
x n + 1 l + 1 = C o n c a t 1 H y h x_{n+1}^{l+1}=Concat_{1}^Hy_h xn+1l+1=Concat1Hyh
其中 W Q / K / V W_{Q/K/V} WQ/K/V是QKV的投影矩阵,H是多头自注意力中head的个数。中间省略了dot product、layernorm、feed forward等步骤。
过程如图片所示。图片来源
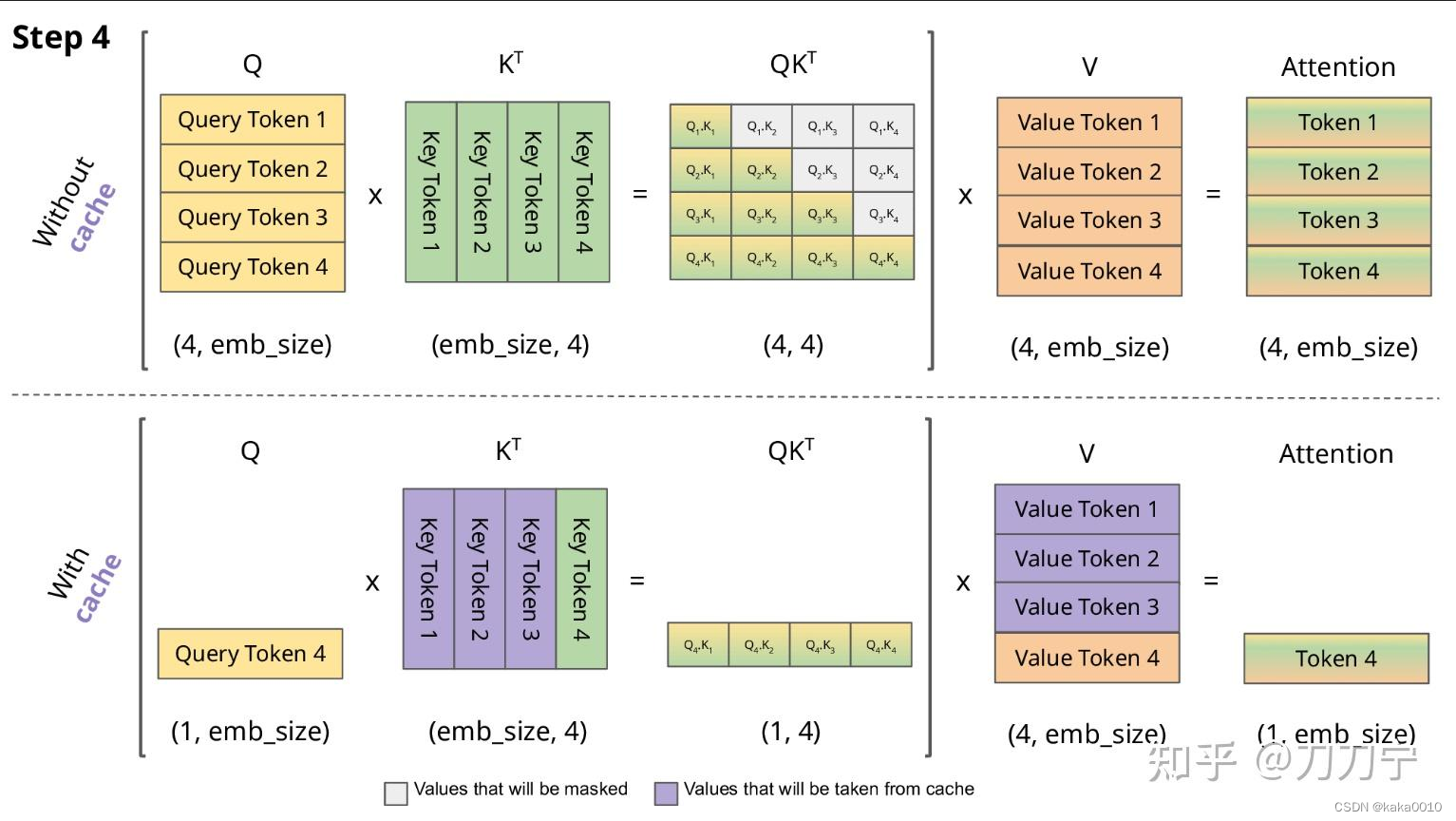
在每次计算过程中得到的中间值
W
K
x
i
l
W_Kx_{i}^l
WKxil和
W
V
x
i
l
W_Vx_{i}^l
WVxil,将它们保存下来,就得到了K Cache和V Cache。
KV Cache的存储
KV Cache的总大小是2nHD,其中n是token数量,H是head数量,D是
x
i
l
x_i^l
xil的维度。
目前有三种解决方案:
- 分配一个最大容量的缓冲区,但需要提前知道最大的token数量。
- 动态分配缓冲区大小,类似vector的方式。
- 将数据拆散,按最小单元格存储,用一份元数据记录每一块数据的位置。
最后一种方式也就是现在常用的PageAttention,也是vllm的核心技术。