Flink SQL Gateway简介
从官网的资料可以知道Flink SQL Gateway是一个服务,这个服务支持多个客户端并发的从远程提交任务。Flink SQL Gateway使任务的提交、元数据的查询、在线数据分析变得更简单。
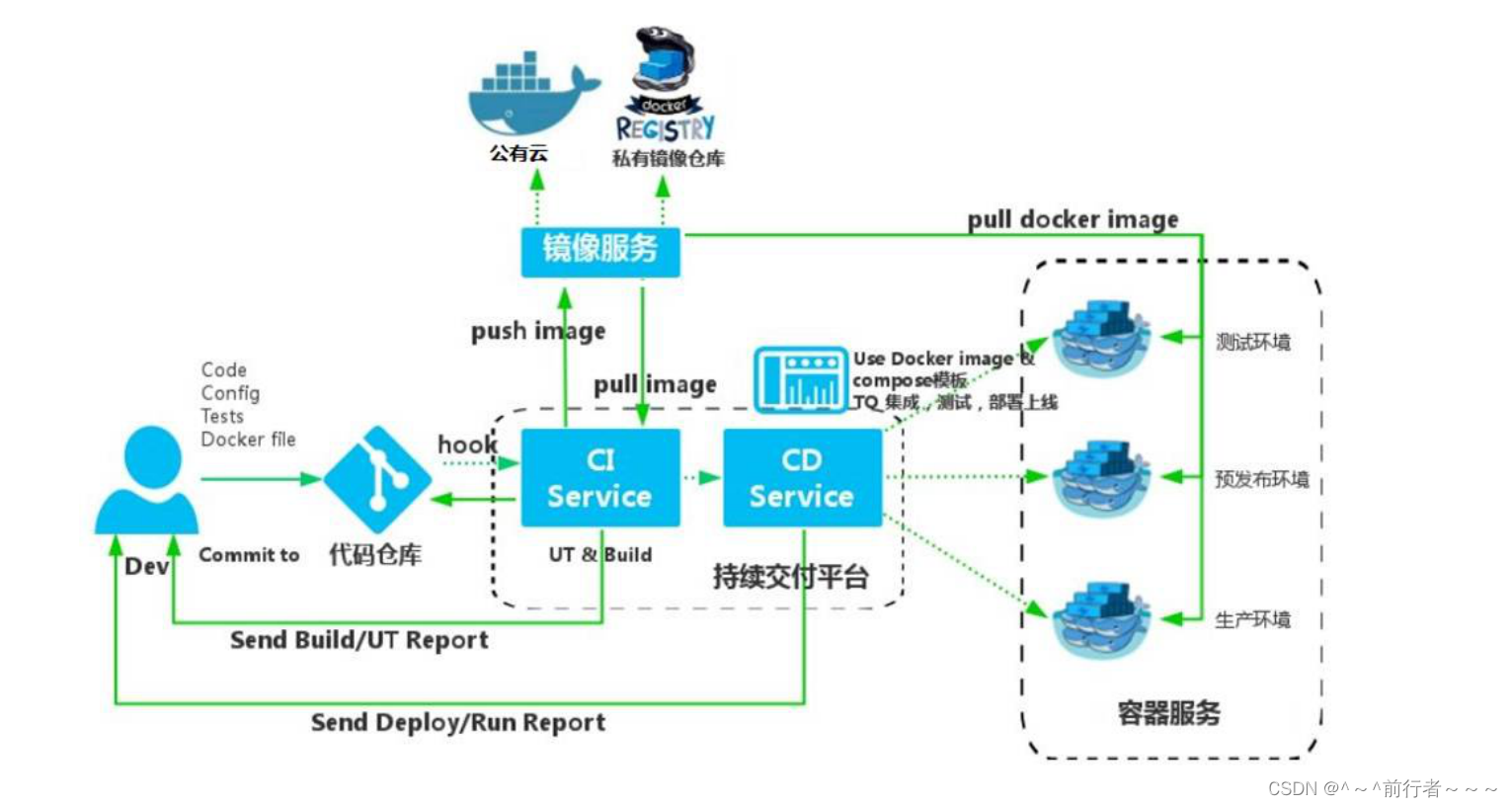
Flink SQL Gateway的架构如下图,它由插件化的Endpoints和SqlGatewayService两部分组成。SqlGatewayService是可复用的处理客户端请求的服务。Endpoint是对外暴露的用户可以连接的接口。
Flink SQL Gateway作业提交流程
Flink SQL Gateway的处理流程如下
1.创建Session
当客户端连接Flink SQL Gateway时,Flink SQL Gateway会创建一个Session来存储客户端和 SQL Gateway交互的信息。Session创建完成后Flink SQL Gateway会返回给客户端一个SessionHandle标识
2.提交SQL
客户端创建完Session后就可以提交SQL到SQL Gateway。提交SQL时,SQL会被翻译成一个Operation,并且每个Operation会对应一个OperationHandle标识。使用OperationHandle可以获取查询的结果、取消Operation的执行或者关闭Operation
3. 获取结果
用户可以通过OperationHandle获取Operation的执行结果。如果Operation准备好了,SQL Gateway会返回一批数据和一个获取下一批数据的URI。当所有数据都获取完了,SQL Gateway会将resultType的值设置为EOS,并且将获取下一批数据的URI设置为null。
如果想了解flink sql gateway连接hiveserver2,参考:
Flink SQL Gateway的使用 - 知乎 (zhihu.com)
本质上就是把hive变成flink的一个catalog,就像doris外部表集成mysql一样,mysql就是doris的一个catalog,可以直接用doris语句操作mysql了。这里也一样,hive变成了flinksql的一个catalog。
怎么连接hive并直接可以用hive的代码(虽然这个需求我们是执行flink来跑hive数据),用hiveserver2最高效,下面有hiveserver2的介绍。
那为什么不直接使用 Flink SQL 而使用 Gateway 呢?
-
远程访问需求: 有时用户可能需要从不同的位置或者不同的应用程序中访问 Flink SQL 引擎,这就需要一个中心化的访问点,而 Gateway 提供了这样的功能。
-
集中管理和监控需求: 在大型生产环境中,可能需要一个统一的管理界面来管理和监控 Flink SQL 作业,而 Gateway 提供了这样的功能。
-
安全性需求: 在企业环境中,安全性通常是一个重要考虑因素,而 Gateway 可以提供身份验证和授权机制,帮助确保系统的安全性。
Hiveserver2介绍:
在启动Hive的时候,除了必备的MetaStore服务外 , 我们前面还有提到过2种方式使用Hive :
- bin/hive , 就是Hive Shell的客户端 , 直接写SQL
- bin/hive --service hiveserver2
HiveServer2是Hive的一个服务组件,它提供了一个多客户端访问的接口,允许用户通
过多种方式 (如JDBC、ODBC等) 连接Hive,并执行HiveQL语句。HiveServer2可以
独立于Hive运行,并且可以与其他应用程序进行集成,使得用户可以更加灵活地使用H
ive.
HiveServer2的主要作用有:
1.支持多客户端连接
HiveServer2可以同时处理多个客户端的连接请求,每个客户端可以独立地执行HiveQ
L语句。这使得多个用户可以同时访问Hive,并且不会相互影响。同时,HiveServer2
还支持连接池,可以有效地管理连接资源,提高系统的并发性能。
2.提供安全访问控制
HiveServer2支持基于Kerberos的认证和授权机制,可以对用户进行身份验证,并目可
以通过角色和权限管理来限制用户的访问权限。这样可以确保数据的安全性,并且可
以按需控制用户对数据的访问和操作
3.支持长连接和会话管理
HiveServer2支持长连接和会话管理,客户端可以通过保持连接的方式避免多次建立和
关闭连接的开销,提高了系统的性能和响应速度。同时,HiveServer2还提供了会话管
理功能,可以为每个用户分配一个独立的会话,可以在会话级别上进行状态管理和资
源隔离。
4.支持异步查询和结果集缓存
HiveServer2支持异步查询和结果集缓存,客户端可以提交一个查询请求后立即返回
然后通过轮询的方式获取查询结果。这样可以减少客户端的等待时间,并且可以利用
结果集缓存提高查询的性能
启动Hive后,
此时后台执行脚本 : nohup bin/hive --service hiveserver2 >> logs/hiveserver2.log 2>&1 &
bin/hive --service metastore , 启动的是元数据管理服务
bin/hive --service hiveserver2 , 启动的是hiveserver2服务
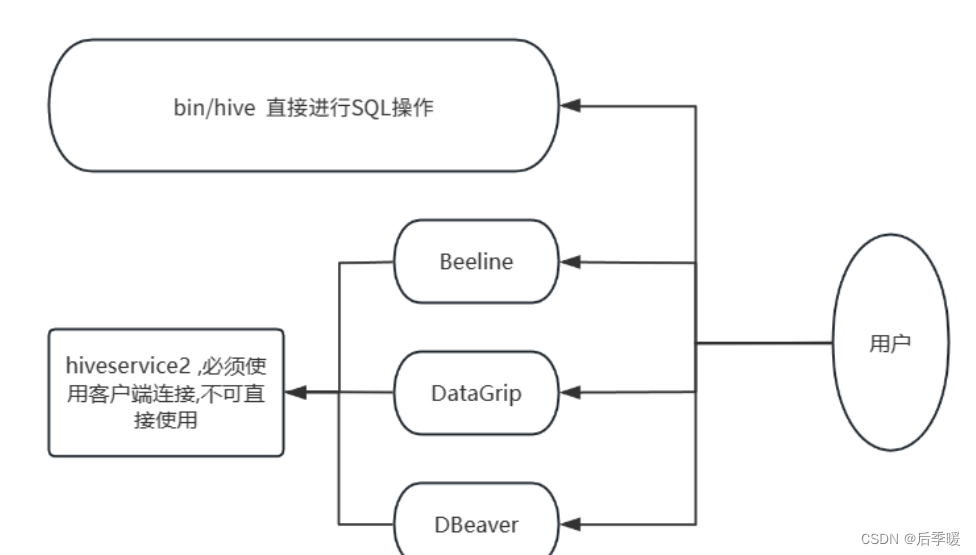
所以 , HiveServer2其实就是Hive内置的一个ThriftServer服务 , 提供Thrift端口供其他客户端连接
这时可以连接ThrifServer的客户端有 :
Hive内置的beeline客户端工具(命令行形式)
第三方的图形化工具 , 如DataGrip这些
下面就是它们之间的关系:
话不多说, 我们开始实际操作
在安装hive的服务器上, 首先启动metastore服务 , 然后启动hiveserver2服务
#启动metastore服务
nohup bin/hive --service metastore >> logs/metastore.log 2>&1 &
#启动hiveserver2服务
nohup bin/hive --service hiveserver2 >> logs/hiveserver2.log 2>&1 &
Beeline连接
在hive的服务器上可以直接使用beeline客户端进行连接 , Beeline是JDBC的客户端 , 通过JDBC和HiveServer2进行通信, 协议的地址是 :
jdbc:hive2://node:10000
这个10000端口是hiveserver2默认向外开发的端口
#进入beeline的连接界面
bin/beeline
#开始连接
!connect jdbc:hive2://node:10000
#接下来会开始输入hive的启动用户名密码,然后就可以开始连接了
这是beeline客户端界面

这时hive的原生界面

DataGrip连接
这种第三方的客户端页面美观大方 , 操作简洁 , 更重要的是sql编辑环境优雅 , sql语法智能提示补全 , 关键字高亮 , 查询结果智能显示 , 按钮操作大于命令操作
接下来是具体的连接步骤
打开DataGrip
选择Apach Hive进行连接

填写相关信息
连上后的操作就跟平常操作mysql一样了。
Hive on Spark
spark和hive本质上是没有关系的,两者可以互不依赖。但是在企业实际应用中,经常把二者结合起来使用。而业界spark和hive结合使用的方式,主要有以下三种:
-
hive on spark。在这种模式下,数据是以table的形式存储在hive中的,用户处理和分析数据,使用的是hive语法规范的 hql (hive sql)。 但这些hql,在用户提交执行时(一般是提交给hiveserver2服务去执行),底层会经过hive的解析优化编译,最后以spark作业的形式来运行。事实上,hive早期只支持一种底层计算引擎,即mapreduce,后期在spark 因其快速高效占领大量市场后,hive社区才主动拥抱spark,通过改造自身代码,支持了spark作为其底层计算引擎。目前hive支持了三种底层计算引擎,即mr, tez和spark.用户可以通过set hive.execution.engine=mr/tez/spark来指定具体使用哪个底层计算引擎。
-
spark on hive。上文已经说到,spark本身只负责数据计算处理,并不负责数据存储。其计算处理的数据源,可以以插件的形式支持很多种数据源,这其中自然也包括hive。当我们使用spark来处理分析存储在hive中的数据时,这种模式就称为为 spark on hive。这种模式下,用户可以使用spark的 java/scala/pyhon/r 等api,也可以使用spark语法规范的sql ,甚至也可以使用hive 语法规范的hql 。而之所以也能使用hql,是因为 spark 在推广面世之初,就主动拥抱了hive,通过改造自身代码提供了原生对hql包括hive udf的支持(其实从技术细节来将,这里把hql语句解析为抽象语法书ast,使用的是hive的语法解析器,但后续进一步的优化和代码生成,使用的都是spark sql 的catalyst),这也是市场推广策略的一种吧。
-
spark + spark hive catalog。这是spark和hive结合的一种新形势,随着数据湖相关技术的进一步发展,这种模式现在在市场上受到了越来越多用户的青睐。其本质是,数据以orc/parquet/delta lake等格式存储在分布式文件系统如hdfs或对象存储系统如s3中,然后通过使用spark计算引擎提供的scala/java/python等api或spark 语法规范的sql来进行处理。由于在处理分析时针对的对象是table, 而table的底层对应的才是hdfs/s3上的文件/对象,所以我们需要维护这种table到文件/对象的映射关系,而spark自身就提供了 spark hive catalog来维护这种table到文件/对象的映射关系。注意这里的spark hive catalog,其本质是使用了hive 的 metasore 相关 api来读写表到文件/对象的映射关系(以及一起其他的元数据信息)到 metasore db如mysql, postgresql等数据库中。(由于spark编译时可以把hive metastore api等相关代码一并打包到spark的二进制安装包中,所以使用这种模式,我们并不需要额外单独安装hive);
-
Hive 2.0 之后,MR执行引擎已经出于deprecated 状态,“It may be removed without further warning.”,hive官方推荐使用的是 hive on tez 或 hive on spark; Hiv3.0 之后, hive官方推荐使用的是 hive on tez,并在Hive4.0中,移除了 hive on spark;
概括起来,SparkOnHive和 HiveOnSpark的核心区别:
- 不在于是否访问HIVE数仓中的数据(二者都访问);
- 也不在于客户端的SQL语法规范是 HIVE SQL 还是 SPARK SQL(Spark支持绝大部分HiveSqly语法);
- 二者的核心区别在于,客户端的 SQL 是否提交给了服务角色 HiveServer2 (org.apache.hive.service.server.HiveServer2),且该hs2配置了 hive.execution.engine=spark;
Spark SQL gateway 的解决方案-Kyuubi
•HiveServer2 本质上是 HIVE 提供的 SQL gateway服务;
•Spark原生提供的 SQL gateway 服务,只有 spark thrift Server($SPARK_HOME/sbin/start-thriftserver.sh) ,但因为功能和稳定性等各种原因,不推荐在生产环境使用($SPARK_HOME/bin/spark-sql 只是一个spark 应用,不是服务);
•网易的开源组件 Kyuubi,起到了 Spark SQL gateway服务的角色,该项目目前已经是 Apache 顶级开源项目,可以在生产环境使用;