文章目录
- 端口号
- 端口号理解
- 端口号的划分
- netstat
- UDP协议
之前结束了对于应用层的理解,那么从本篇开始往后,将会深入到传输层当中进行理解,尝试打通整个网络的协议栈
从对于之前的理解来说,在应用层涉及到的知识体系是相当庞大的,比如说有序列化反序列化,对于正确的读取和写入,还有在进行网络通信的时候要设计到应用层协议的定制,还有对于序列化反序列化的区别,还有关于https协议的加密过程,引入了关于CA机构和证书的概念
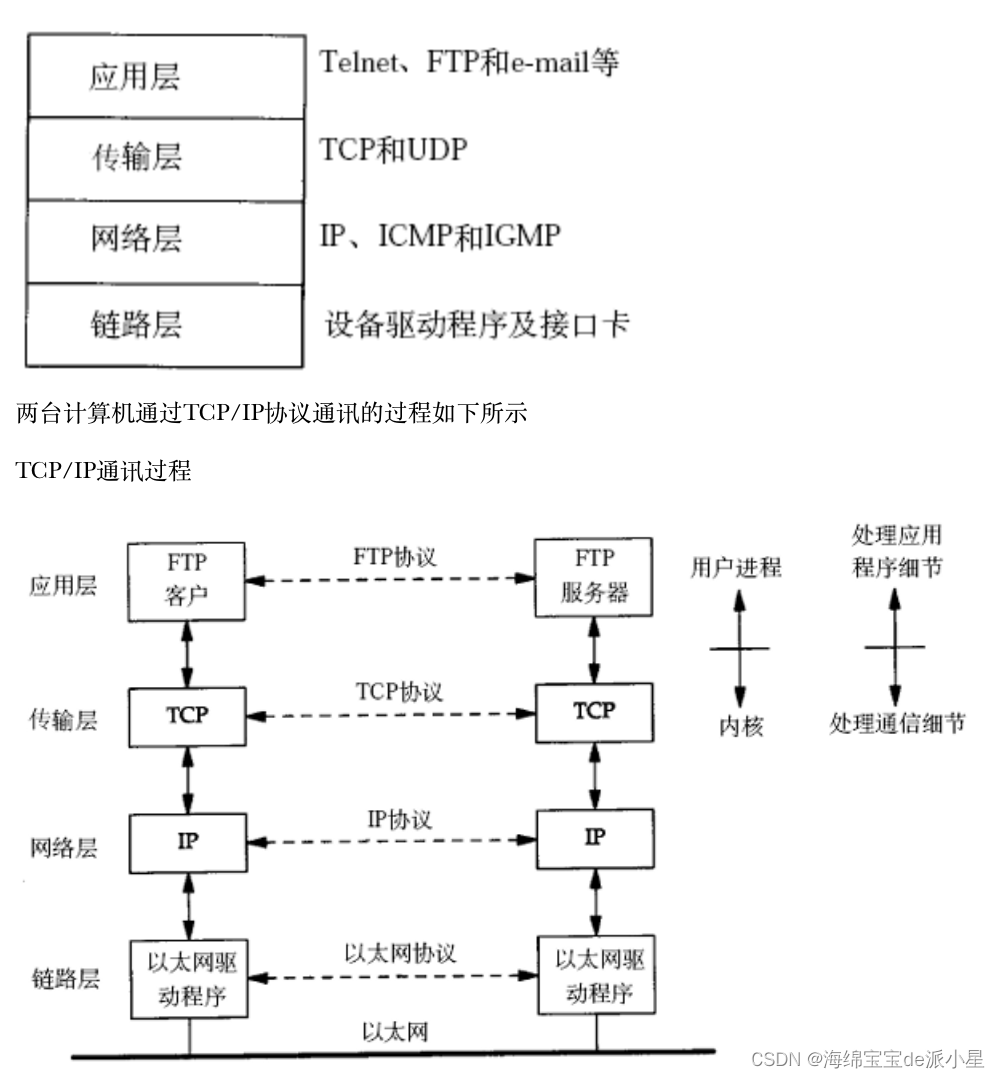
再拿出我们这张图,中间的传输层和网络层是在内核实现的,而应用层是在用户层实现的,这也就注定了在进行学习传输层的时候必然就是要学习在Linux内核中的关于网络的部分,实际上传输层在操作系统的内部是提供了一套对应的系统调用,然后进行正常的数据读取,那对于这部分系统调用也有很多的接口,比如在创建套接字的时候有listen,bind,receive这样的接口,所以下一步要学习的内容就在传输层当中
端口号
端口号理解
在学传输层前,先谈谈端口号,对于端口号的话题在之前已经学习过了,这里只是想说对于端口号的认识,作为一台主机来说,服务器可能会有很多的应用服务,每一个应用服务都要绑定一个明确的端口号,那这个端口号的意义就是能够保证让数据传输给上面的那一个应用程序,因为对于进程的区分就可以借助这个端口号来进行区分,借助ip地址和端口号就可以做到在全网找到唯一的一台主机,而从这个主机上找到唯一的一个进程,这样就能精确的找到对应的网络服务了,所以有了下面的概念:

在网络的通信中,可以用源ip地址,目标ip地址,源端口号,目标端口号,协议号这几个内容来实现一组通信,这也叫做是用五元组来实现通信,换句话说只要有这五个东西,就能实现一组通信的过程
所以未来不管是内核中的TCP协议还是UDP协议,他们必然都必须要有这五元素的概念来实现通信
端口号的划分
在之前的内容中已经使用了很多次端口号了,这里对于端口号的划分进行一个详解,端口号也是有区分的,比如在0-1023这个区间内的端口号默认是绑定不了的,如果想要绑定可能会需要有root权限来帮助进行绑定,但是像是8080,8888这样的端口号是可以进行绑定的,而把从0-1023这样的端口号我们就叫做是知名端口号,那所谓知名端口号的意思就是这些端口号比如要有一个特定的协议进行相关联,一般对应的关系就是端口号,比如前面所学习过的http对应的就是80,那https对应的端口号就是443,这样的端口号还有很多,换句话说就是不同的网络通信协议必须要有自己绑定的通讯端口
那除了0-1023这个区间内的端口号以外,其余的内容都是由操作系统动态分配的端口号,这些是可以自己完成服务器后进行绑定的,不过也有特例,例如在MySQL这样的网络服务当中,也有特定的端口号,比如说是有3306这样的端口号要进行绑定,那端口号怎么看呢?如何规避呢?在Linux系统中有这样的文件,其实可以看到对应知名端口号的信息:
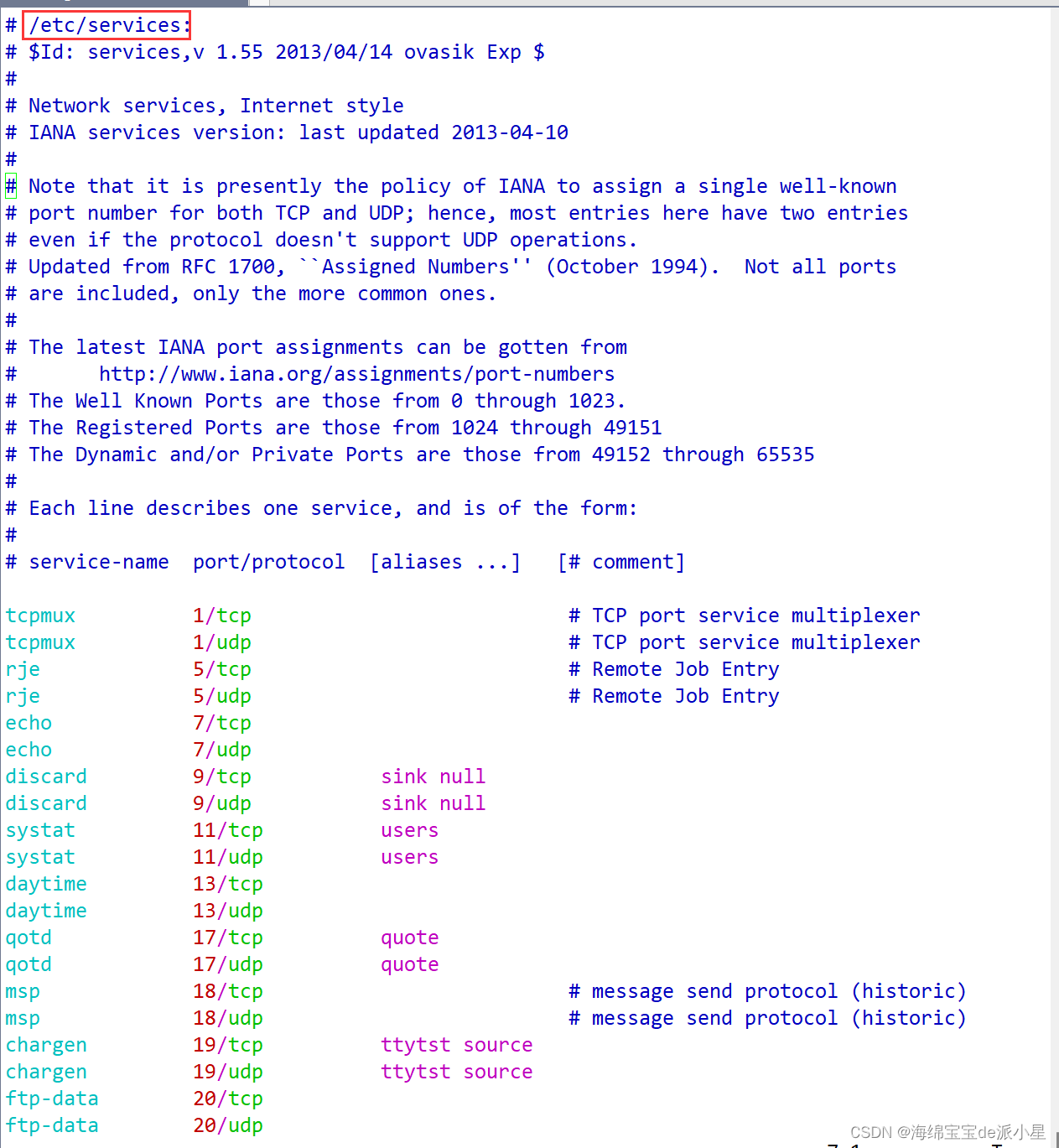
netstat
这是一个用来查看网络状态的工具,前面已经使用了很多次了,这里主要是介绍另外一个命令,叫做pidof,它可以查看当前服务器的进程id:通过进程名就可以查到对应的进程id

UDP协议
学习传输层的协议,要从UDP协议入手,其中一个原因是UDP协议还是相对简单一些
任何协议进行封装后都要进行解包,那如何辨别有效载荷和报头呢?
对于这个问题在自定义协议当中,我们采取的策略是使用了一个\n来进行标记,在前面也有对应的字符串长度来进行解析,而在http协议中采用的方案是用了空行来进行对应的分割工作,那在UDP当中呢?
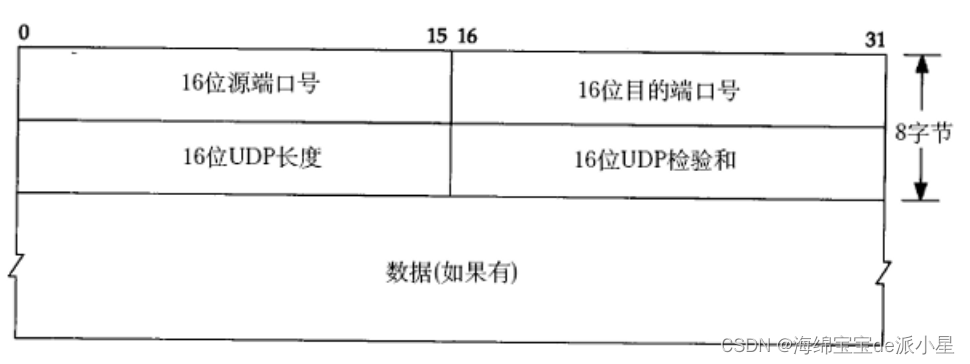
UDP的定义十分简单粗暴,就是一个定长报头,规定前面的这些字段就是定长的,规定前8个字节就是报头,剩下的部分就是有效载荷
UDP如何知道要交给上层的哪一个协议?
答案是依据对应的16位目标端口号,有这个端口号就可以进行进程的交互,也能来标定对应的目标进程了,所以实际上报头将有效载荷交付给上层的协议,就是根据目的端口来做的
由此,如果站在UDP的角度来讲,现在已经可以做到把报头和有效载荷进行分离的操作了
UDP的信息完整性
那下一个问题是UDP的信息问题,进行网络通信的时候,UDP内部是如何维系到底数据是否有没有出问题呢?在UDP协议当中,对于报文的提取该从哪里提取,最终提取到哪里呢?其实也很简单,因为当前已经存在了对应的UDP的长度了,所以在得到了一份UDP的报文之后,随后的下一步就是要对于UDP的这些信息进行解析,之后进行校验,如果要是校验成功了就说明此次的传输是有效的,如果校验失败了就说明这次的传输是一个无效的过程,因此就直接把当前的包丢弃了,那传输的那一端知道它发送的包被丢弃了吗?显然是不知道的,所以这也就突出了UDP的一个特点,叫做不保障可靠性
UDP协议的特点
对于UDP这种协议的传输特点来说,就是无链接,对于这个概念也已经提及过了,直接进行绑定后就能使用UDP进行通信了,而不是需要进行connect进行链接,那第二个特点就是不可靠,所以在使用UDP协议的时候是可能会出现丢包的情况出现的,但是UDP并不会对这样的行为进行处理,只是会直接进行丢掉,第三个特点是UDP是面向数据报的,那我们该如何理解这个特点呢?
在进行UDP的套接字中其实可以发现的一个特点是,面相数据报的一个特点是发送多少次,对方就要收多少次,一个UDP的报文和另外一个UDP的报文本质上是没有任何直接关系的,比如当前的UDP报文发送了十份,那么就必须要对于这十份报文都进行接收,就如同在日常当中邮件的性质是一样的
缓冲区的概念
严格意义来说,UDP是只有接收缓冲区的,这个缓冲区是用来保存用户暂时来不及处理的报文,把这些报文暂时的存储在缓冲区中,而UDP本身是不存在发送的概念的,它要做的就是把包装好的内容传递到上层就可以了,不需要什么发送缓冲的概念
UDP在内核中本质上可以理解为是存在一个接收缓冲区,不管是用户端还是服务端都有,那如果想进行数据的发送,就从对应的接收缓冲区去读取,然后发送到对方的接收缓冲区中,这样确实看起来是比较的方便,但是这也就带来了一个问题是,UDP本身的安全性是一个问题
理解UDP
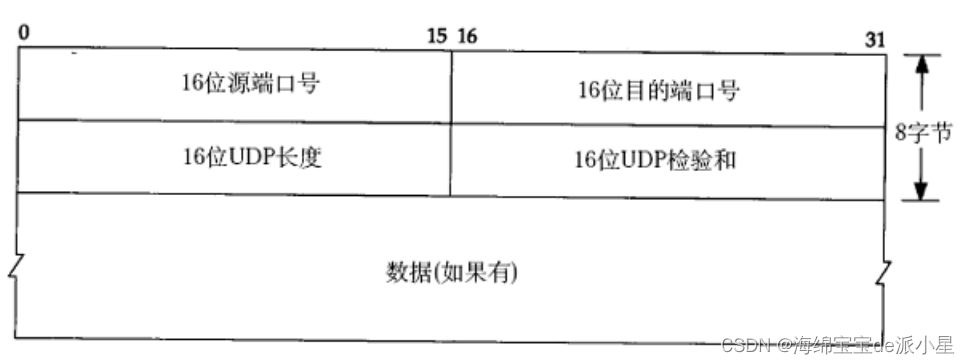
所以基于这样的理论,我们对于UDP其实可以这样理解
在内核中会定义一个结构体,在这个结构体中其实维护的就是UDP的报头信息:
struct udp_header
{
uint32_t src_port:16;
uint32_t dst_port:16;
uint32_t lenth:16;
uint32_t check_code:16;
};
这个结构体中的内容其实都与上面的图中所示的报头字段一一对应,而实际上对于UDP的报头理解确实可以理解为是对于UDP的字段填充的过程
那么如果要是使用UDP协议向网络中发送Hello World这样的字段,该如何理解这个过程呢?
操作系统会提供一个类似于缓冲区的这样的一段区域,那在这个缓冲区中就会构建对应的UDP请求,未来都是会在这个地方通过操作系统向对方发送UDP对应的报文,那这段UDP的报文会在内核中进行流动,它未来是要向下交互到底层硬件进行发送的,这就必然意味着在操作系统的内部会存在很多的UDP的报文
站在接收方的角度来讲,未来它也会受到大量的UDP的报文,所以操作系统必然要对于这么多的UDP报文进行管理,因此在操作系统内部会存在这个叫做sk_buff的结构体
在这个结构体中会有对应的start,end,pos指针,那当未来要构建一个UDP的报文,在内核的层面上就会定义一段缓冲区,之后把前面定义的报头部分拷贝进来,然后再把用户空间的Hello World拷贝进来,然后把对应的start,end,pos这样的指针进行一个描述,这样对于当前UDP的报文就管理起来了,之后在内核中可以使用链表,来把这一个一个的UDP报文进行链接管理起来,这样就能实现对于内核中UDP报文的管理工作
至此,UDP的传输原理其实就是这样,虽然在内核中的实际实现并不是这样,但是基本思想确实如此,未来有机会再对于源码中的UDP部分进行分析详解