目录
一、命名管道
1、概念
2、特点
3、原理
4、创建
5、匿名管道与命名管道的区别
6、命名管道的打开规则
二、命名管道—实现客户端和服务器之间的通信
1、Makefile
2、comm.hpp
3、Log.hpp
4、server.cxx
5、client.cxx
运行测试:
三、system V共享内存
1、概念
2、共享内存数据结构
3、原理
4、共享内存函数
shmget函数
参数key的作用:
ftok()函数
shmat函数
shmdt函数
shmctl函数
四、进程中实现共享内存
1、Makefile
2、Log.hpp
3、comm.hpp
4、shmServer.cc
5、shmClient.cc
运行测试:
一、命名管道
1、概念

2、特点
-
命名特性: 命名管道通过一个在文件系统层次结构中的路径名称来标识,这使得任何知道该名称的进程都能打开并使用这个管道,不论它们之间是否存在父子或兄弟进程关系。
-
跨进程通信: 不同于仅限于具有直接亲缘关系进程之间的匿名管道,命名管道可以被任意两个独立的进程所访问,从而实现非亲缘进程间的通信。
-
持久性(某种程度上): 由于其存在文件系统的特性,即使创建管道的进程已经终止,只要管道没有被删除,其他进程仍能继续通过指定的名称找到并使用该管道。
-
单向或双向通信: 命名管道可以是单向的,即只能用于从一个进程发送数据到另一个进程;也可以是双向的,允许两个方向的数据传输。
-
安全性: 系统可以对命名管道设置权限和所有权,从而控制哪些用户或进程能够访问管道,提供了一定的安全保障。
3、原理
命名管道是一种允许不同进程通过共享的、命名的“虚拟文件”进行半双工(单向流)通信的机制。
- 当一个进程(如进程A)将数据写入命名管道时,该数据首先被暂存于操作系统内核空间的一个缓冲区中。此时,进程B可以通过打开相同的命名管道来读取这些数据,实现了进程间的信息传递。
命名管道依赖于其全局唯一的标识名,这使得任何知道这个名称的进程都能够连接到管道并进行数据的读取或写入。
- 这种机制与文件路径类似,为数据传输提供了一个清晰的寻址方式。此外,命名管道的数据流遵循FIFO(先进先出)原则,确保数据的顺序性和完整性。
操作系统对命名管道内部的读写操作进行了严格的同步和互斥控制,以维护数据的一致性和防止竞争条件。
- 例如,如果管道为空,读取操作将被阻塞,直到有数据写入;
- 反之,如果管道已满,写入操作也会被阻塞,直到管道中有足够空间。
- 这种同步机制确保了数据的稳定传输和进程间通信的高效性。
因此,进程B能够通过打开与进程A相同的命名管道获取数据,归功于操作系统的协调和命名管道这一高效的共享通信资源。只要进程获取了正确的命名管道名称并拥有适当的访问权限,它就可以利用系统提供的接口打开该管道,并成功读取其他进程写入的数据。这不仅展示了操作系统在进程间通信方面的强大功能,也体现了命名管道作为一种灵活且可靠的通信机制的价值。

两个不同的进程(A和B)可以通过访问同一个命名管道来实现数据交换。具体来说:
- 进程A首先打开并写入数据到命名管道(fifo.ipc),这些数据会存储在内存中,并不会立即刷新到磁盘。
- 然后,进程B可以打开同一命名管道进行读取操作,从而获取到进程A写入的数据。
- 在整个过程中,双方都通过管道文件的路径来访问同一份资源,实现了进程间的通信。
4、创建
命令行方法: 通过系统命令行界面,可以使用mkfifo命令轻松创建一个命名管道。具体操作如下:
$ mkfifo filenamefilename是您要为命名管道指定的名称。
编程方式创建: 在C/C++程序中,可以调用标准库函数mkfifo()来创建命名管道。函数原型如下:
#include <sys/stat.h>
int mkfifo(const char *filename, mode_t mode);该函数接收两个参数:
filename:指向一个以空字符结尾的字符串,用于指定命名管道的路径名。mode:指定管道的访问权限,类似于文件权限,采用与chmod命令相同的模式表示法。
返回值:
- 若函数调用成功,
mkfifo()会返回0。 - 如果调用失败,
mkfifo()会返回-1,并设置errno错误码以指示具体的错误原因,如权限不足(EACCES)、路径名已存在并且不是一个文件(EEXIST)或其他系统错误。
5、匿名管道与命名管道的区别
创建与标识:
-
匿名管道(Anonymous Pipe)由系统调用
pipe()函数直接创建并打开。它没有显式的名称,仅存在于调用进程的上下文中,通过返回的一对文件描述符进行引用,一端用于读取,另一端用于写入。 -
命名管道(FIFO或Named Pipe)则通过系统调用
mkfifo()来创建,并且它具有一个全局唯一的路径名,在文件系统中表现为一个特殊的设备文件。后续任何进程都可以通过标准的open()函数打开这个路径来访问命名管道。
使用范围:
- 匿名管道主要用于有亲缘关系的进程间通信,即父进程创建后可以将其传递给子进程使用。
- 命名管道则打破了这种亲缘关系限制,允许任意两个进程之间进行通信,只要它们能够访问到同一命名管道的路径即可。
通信模式:
- 匿名管道在创建时就绑定了两个进程,不支持网络间的通信,也不支持多客户端连接。
- 命名管道由于其命名特性,不仅支持本地进程间的通信,而且在网络文件系统中也可以跨主机使用,支持多客户端同时连接,并且可以实现双向通信。
异步性和持久性:
- 匿名管道通常是短暂存在的,与创建它的进程生命周期相关联。
- 命名管道即使在创建它的进程终止后仍然存在,直到被明确删除或者系统重启,这使得它可以服务于多个独立的进程交互,同时也支持异步重叠I/O操作。
6、命名管道的打开规则
-
针对读取操作:
-
当进程以读取模式打开一个命名管道,并且未设置
O_NONBLOCK标志(即阻塞模式启用),系统会保持阻塞状态直到有其他进程成功为写入而打开该命名管道。这意味着读取端将等待数据的到来。 -
若进程在打开命名管道时指定了
O_NONBLOCK标志(即非阻塞模式启用),则系统不会进行阻塞,而是立即返回成功。然而,在这种模式下,如果没有相应的写入进程已打开该FIFO,则实际的读取操作可能会返回无可用数据的错误。
-
-
针对写入操作:
-
当进程试图以写入模式打开一个命名管道,但在未设置
O_NONBLOCK标志的情况下,操作系统将阻塞该进程,直至有另一个进程以读取模式打开了同一个命名管道。这样确保了当写入者开始写入时,至少有一个读者准备接收数据。 -
如果进程在打开命名管道时启用了
O_NONBLOCK标志,那么系统不会进入阻塞状态,而是会立刻返回失败,并设置错误码为ENXIO(设备不存在或请求的操作无效)。这意味着在非阻塞模式下,如果此时没有读取进程已经打开了该FIFO,写入操作将无法执行,直接返回错误。
-
二、命名管道—实现客户端和服务器之间的通信
1、Makefile
Makefile 主要负责编译并链接源代码文件 client.cxx 和 server.cxx 分别生成 client 和 mutiServer 两个可执行文件,并提供了一个清理目标来删除已编译好的二进制文件。
.PHONY:all
all:client mutiServer
client:client.cxx
g++ -o $@ $^ -std=c++11
mutiServer:server.cxx
g++ -o $@ $^ -std=c++11
.PHONY:clean
clean:
rm -f client mutiServer2、comm.hpp
comm.hpp文件主要作用是定义了一些与进程间通信(通过命名管道实现)相关的常量和全局变量,以及包含了日志记录功能所需的Log.hpp头文件。
#ifndef _COMM_H_
#define _COMM_H_
#include <iostream>
#include <string>
#include <cstdio>
#include <cstring>
//Unix系统的标准头文件,其中包含了许多系统调用函数的声明,例如open、close和mkfifo等。
#include <unistd.h>
//定义了基本系统数据类型,比如pid_t等。
#include <sys/types.h>
//提供了与文件状态和权限相关的信息和函数,如struct stat和mkfifo的原型声明。
#include <sys/stat.h>
//包含了文件控制操作的函数声明,如open的多种模式参数。
#include <fcntl.h>
#include "Log.hpp"
using namespace std;
#define MODE 0666
#define SIZE 128
string ipcPath = "./fifo.ipc";/命名管道(FIFO)的路径,
#endif-
#ifndef _COMM_H_和#define _COMM_H_:这是预处理器指令,创建了头文件保护(也称为include guards),防止当同一个头文件被多个源文件包含时导致的多重声明问题。 -
#define MODE 0666:定义了一个宏常量MODE,用于指定创建命名管道时的权限模式。这里的数字0666以八进制形式表示所有用户都具有读写权限(对于文件系统对象来说是常见的设置)。 -
#define SIZE 128:定义了一个宏常量SIZE,用来指定缓冲区的大小,在这个项目中可能用于读取或写入到管道的数据缓冲区。 -
string ipcPath = "./fifo.ipc";:定义了一个全局字符串变量ipcPath,它指定了命名管道(FIFO)的路径,该管道将在客户端和服务端之间用于传递消息。在这个案例中,命名管道将创建在当前工作目录下,并命名为“fifo.ipc”。
3、Log.hpp
Log.hpp 是一个简单的日志模块,用于在控制台输出带有时间戳和消息级别的信息。
#ifndef _LOG_H_
#define _LOG_H_
#include <iostream>
#include <ctime>
#define Debug 0
#define Notice 1
#define Warning 2
#define Error 3
const std::string msg[] = {
"Debug",
"Notice",
"Warning",
"Error"
};
std::ostream &Log(std::string message, int level)
{
std::cout << " | " << (unsigned)time(nullptr) << " | "
<< msg[level] << " | " << message;
return std::cout;
}
#endif宏定义:
- 定义了四种日志级别:
Debug、Notice、Warning和Error,分别对应整数值0、1、2和3。 - 定义了一个字符串数组
msg[],其中存储了每个日志级别的名称。
全局函数 Log():
- 函数原型:
std::ostream &Log(std::string message, int level) - 功能:接收一个字符串
message作为日志内容和一个整数level表示日志级别,然后在控制台上输出格式化的日志信息。 - 输出格式:当前时间戳 | 日志级别名称 | 消息内容
- 返回值:返回 std::cout,允许连续输出(如
Log("Message", Debug) << " additional info";)。
4、server.cxx
server.cxx的目的是实现一个简单的服务器,监听命名管道,当有客户端通过管道发送数据时,由多个子进程并发地读取消息并在控制台输出。
#include "comm.hpp"
#include <sys/wait.h>
static void getMessage(int fd)
{
char buffer[SIZE];
while (true)
{
memset(buffer, '\0', sizeof(buffer));
ssize_t s = read(fd, buffer, sizeof(buffer) - 1);
if (s > 0)
{
cout <<"[" << getpid() << "] "<< "client say> " << buffer << endl;
}
else if (s == 0)
{
// end of file
cerr <<"[" << getpid() << "] " << "read end of file, clien quit, server quit too!" << endl;
break;
}
else
{
// read error
perror("read");
break;
}
}
}
int main()
{
// 1. 创建管道文件
if (mkfifo(ipcPath.c_str(), MODE) < 0)
{
perror("mkfifo");
exit(1);
}
Log("创建管道文件成功", Debug) << " step 1" << endl;
// 2. 正常的文件操作
int fd = open(ipcPath.c_str(), O_RDONLY);
if (fd < 0)
{
perror("open");
exit(2);
}
Log("打开管道文件成功", Debug) << " step 2" << endl;
int nums = 3;
for (int i = 0; i < nums; i++)
{
pid_t id = fork();
if (id == 0)
{
// 3. 编写正常的通信代码了
getMessage(fd);
exit(1);
}
}
for(int i = 0; i < nums; i++)
{
waitpid(-1, nullptr, 0);
}
// 4. 关闭文件
close(fd);
Log("关闭管道文件成功", Debug) << " step 3" << endl;
unlink(ipcPath.c_str()); // 通信完毕,就删除文件
Log("删除管道文件成功", Debug) << " step 4" << endl;
return 0;
}首先,包含必要的头文件 comm.hpp 以及 <sys/wait.h>,用于子进程管理和等待。
#include "comm.hpp"
#include <sys/wait.h>getMessage;
定义一个辅助函数 getMessage(int fd),它负责从管道中读取客户端发送的消息,并在控制台上打印出来。这个函数会不断循环读取直到遇到EOF(end of file)或者发生错误。
static void getMessage(int fd)
{
char buffer[SIZE];
while (true)
{
memset(buffer, '\0', sizeof(buffer));
ssize_t s = read(fd, buffer, sizeof(buffer) - 1);
if (s > 0)
{
cout <<"[" << getpid() << "] "<< "client say> " << buffer << endl;
}
else if (s == 0)
{
// end of file
cerr <<"[" << getpid() << "] " << "read end of file, clien quit, server quit too!" << endl;
break;
}
else
{
// read error
perror("read");
break;
}
}
}- 函数首先声明一个固定大小(大小为
SIZE)的字符数组buffer,用于暂存接收到的消息。 - 接着,函数进入一个无限循环,在循环内部不断尝试从
fd读取数据。每次读取前,都会使用memset函数清空buffer,确保每次接收的是新的完整消息。 - 然后,调用
read系统调用从fd读取数据,试图读取buffer所能容纳的(减去1个字节以留出空间存放字符串结束符\0)数据量。 - 根据
read函数的返回值ssize_t s进行判断:- 如果
s大于0,表示成功读取到客户端发送的消息,函数会在控制台上打印一条格式化的输出,包含当前进程ID以及读取到的消息内容。 - 若
s等于0,意味着到达了文件结束符(EOF),通常在这种情况下,可以理解为客户端已经关闭连接。函数会在标准错误输出流cerr上打印一条提示信息,并退出循环,从而使得服务器端也随之停止运行。 - 如果
s小于0,则表示在读取过程中遇到了错误,函数会调用perror打印错误信息,并同样退出循环,结束消息接收过程。
- 如果
在主函数 main() 中执行如下步骤:
- 创建管道:调用
mkfifo(ipcPath.c_str(), MODE)创建一个名为 "./fifo.ipc" 的命名管道,权限设置为MODE==0666。 - 日志记录:通过
Log函数记录创建管道成功的信息,级别为 Debug。int main() { // 1. 创建管道文件 if (mkfifo(ipcPath.c_str(), MODE) < 0) { perror("mkfifo"); exit(1); } Log("创建管道文件成功", Debug) << " step 1" << endl; - 打开管道:以只读模式
O_RDONLY打开刚刚创建的管道,获取文件描述符fd。 - 日志记录:同样记录打开管道成功的操作。
int fd = open(ipcPath.c_str(), O_RDONLY); if (fd < 0) { perror("open"); exit(2); } Log("打开管道文件成功", Debug) << " step 2" << endl; - 多进程处理:通过
fork()创建多个子进程(在这个例子中是3个)。每个子进程都会运行getMessage(fd)函数来接收和处理客户端消息。int nums = 3; for (int i = 0; i < nums; i++) { pid_t id = fork(); if (id == 0) { // 3. 编写正常的通信代码了 getMessage(fd); exit(1); } } - 等待子进程结束:父进程使用
waitpid(-1, nullptr, 0)等待所有子进程退出。 - 关闭管道文件描述符:在所有子进程结束后,关闭管道文件描述符
fd,并记录关闭成功信息。 - 删除管道:通信完毕后,删除已创建的命名管道,避免资源泄露,并记录删除成功信息。
for(int i = 0; i < nums; i++)
{
waitpid(-1, nullptr, 0);
}
// 4. 关闭文件
close(fd);
Log("关闭管道文件成功", Debug) << " step 3" << endl;
unlink(ipcPath.c_str()); // 通信完毕,就删除文件
Log("删除管道文件成功", Debug) << " step 4" << endl;
return 0;
}5、client.cxx
client.cxx的主要任务是从标准输入读取用户的输入,并将其通过命名管道传递给服务器。由于没有添加任何终止条件,因此程序会在接收到Ctrl+C或者其他中断信号后停止运行。在实际应用中,可能需要增加适当的退出条件或者错误处理机制。
#include "comm.hpp"
int main()
{
// 1. 获取管道文件
int fd = open(ipcPath.c_str(), O_WRONLY);
if(fd < 0)
{
perror("open");
exit(1);
}
// 2. ipc过程
string buffer;
while(true)
{
cout << "Please Enter Message Line :> ";
std::getline(std::cin, buffer);
write(fd, buffer.c_str(), buffer.size());
}
// 3. 关闭
close(fd);
return 0;
}打开管道文件:
- 首先,包含
comm.hpp头文件以获取全局变量ipcPath,该变量表示了命名管道的位置。 - 使用
open系统调用函数尝试以只写模式 (O_WRONLY) 打开命名管道,获取文件描述符fd。如果打开失败,会输出错误信息并退出程序。
循环接收用户输入并发送给服务器:
- 初始化一个字符串变量
buffer用于存储用户输入的消息。 - 循环无限期运行,提示用户输入消息,并使用
std::getline函数从标准输入(通常是键盘)读取一行文本。 - 调用
write系统调用函数,将用户输入的消息(转换为C风格字符串buffer.c_str())写入已打开的命名管道文件描述符fd中。
关闭管道和结束程序:
- 在循环之外,当程序需要终止时(在这个示例中,程序在实际运行时不会自然结束),会调用
close(fd)来关闭之前打开的命名管道文件描述符。 - 程序返回0,表示成功执行完毕。
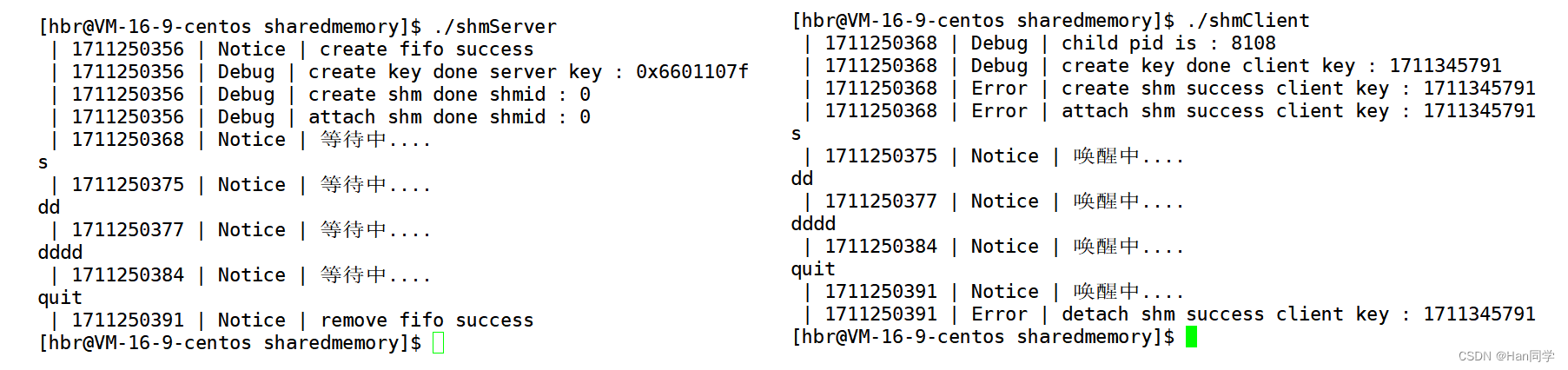
运行测试:

三、system V共享内存
1、概念

2、共享内存数据结构
struct shmid_ds {
struct ipc_perm shm_perm; /* operation perms */
int shm_segsz; /* size of segment (bytes) */
__kernel_time_t shm_atime; /* last attach time */
__kernel_time_t shm_dtime; /* last detach time */
__kernel_time_t shm_ctime; /* last change time */
__kernel_ipc_pid_t shm_cpid; /* pid of creator */
__kernel_ipc_pid_t shm_lpid; /* pid of last operator */
unsigned short shm_nattch; /* no. of current attaches */
unsigned short shm_unused; /* compatibility */
void* shm_unused2; /* ditto - used by DIPC */
void* shm_unused3; /* unused */
};struct shmid_ds 是 Linux 系统下用于描述共享内存段属性的数据结构,它是内核维护的一个数据结构,与特定的共享内存标识符(shmid)相关联。当你创建或操作共享内存段时,可以通过 shmctl() 系统调用读取或修改这个结构体中的成员变量。下面是对该结构体各个字段的解释:
-
shm_perm: 结构类型
ipc_perm描述了共享内存的权限信息,包括:- uid:所有者的用户ID
- gid:所有者的组ID
- cuid:创建此共享内存段的进程的有效用户ID
- cgid:创建此共享内存段的进程的有效组ID
- mode:访问权限模式(类似于文件权限)
-
shm_segsz: 表示共享内存段的实际大小(以字节为单位)。
-
shm_atime: 最后一次成功连接(attach)此共享内存段的时间戳。
-
shm_dtime: 最后一次从进程中分离(detach)此共享内存段的时间戳。
-
shm_ctime: 最后一次更改此共享内存段属性的时间戳。
-
shm_cpid: 创建此共享内存段的进程ID。
-
shm_lpid: 最后一次执行对此共享内存段的任何操作(如attach、detach或改变其属性)的进程ID。
-
shm_nattch: 当前已连接到此共享内存段的进程数。
-
shm_unused 和 shm_unused2、shm_unused3: 这些字段通常在不同的内核版本或不同的实现中可能有不同的用途,或者是预留供未来扩展使用的。在一些实现中它们可能是未使用的或不再支持的遗留字段。
3、原理
动态链接库在被加载到进程地址空间时,通常会被映射到一个共享内存区域。这个区域内存储的并非函数的实际代码,而是指向这些函数所在位置的偏移量。
在链接阶段,当程序需要调用动态库中的某个函数时,编译器或链接器会记录下该函数相对于库起始地址的偏移量,而不是其实际地址。
因此,在运行时,只要确定了动态库在进程虚拟地址空间中的加载基址(起始地址),程序就可以通过将自身内部存储的函数偏移量与库的基址相加,从而定位到库中所需调用的函数的实际代码。这种机制确保了动态库可以被多个进程以只读、共享的方式高效加载,并且每个进程都能够根据自身的地址空间布局正确地访问库函数。
当一个程序需要使用动态库时,并非一次性加载整个库到内存,而是按需加载。当多个进程都使用同一份动态库时,操作系统只需将该库加载至物理内存一次,并将其映射到每个进程的地址空间,这样就能实现内存资源的有效利用。
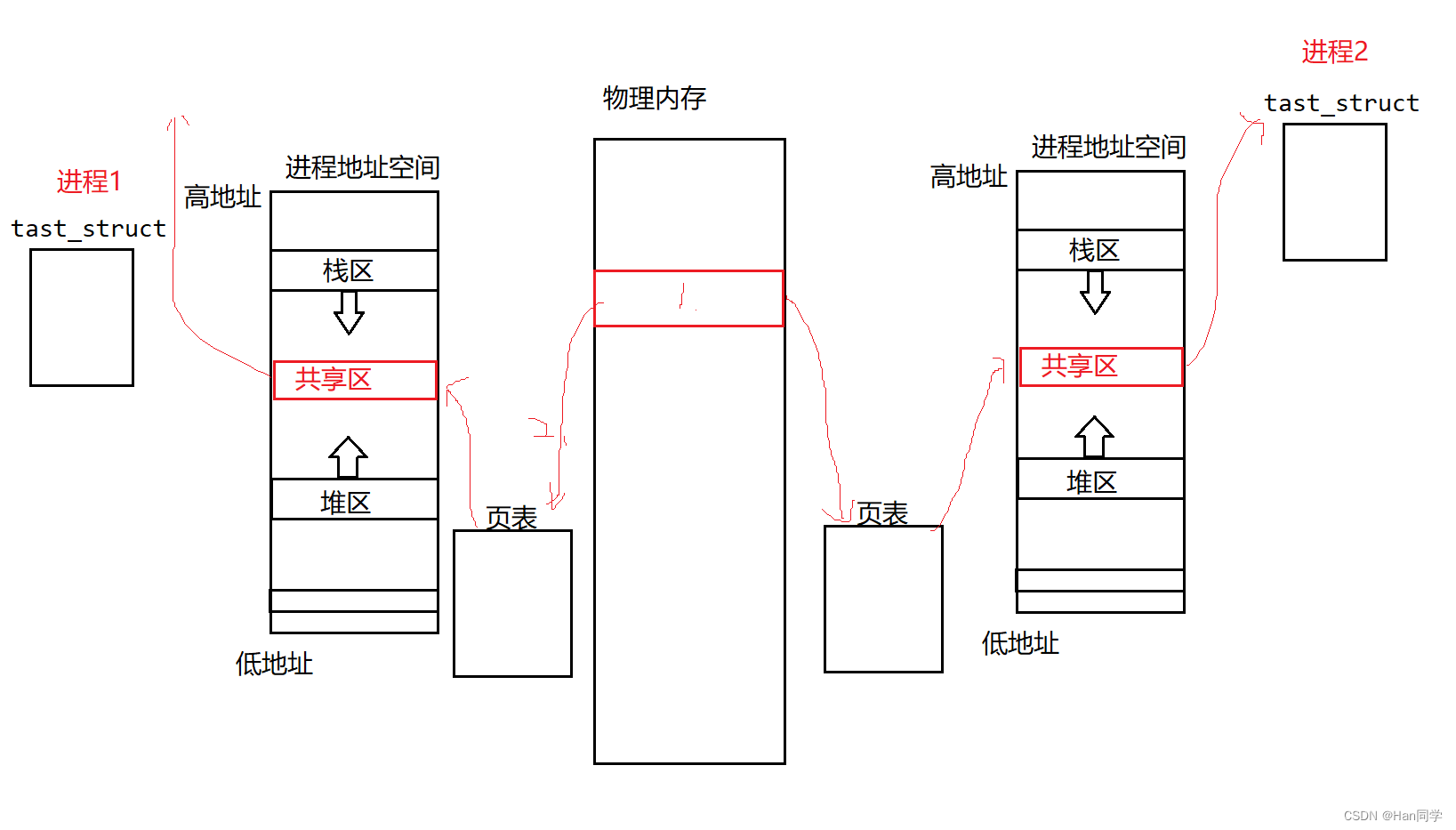 具体过程如下:
具体过程如下:
-
内存分配与映射:操作系统首先会在物理内存中为动态库分配一块空间,然后通过页表机制,将这块物理内存映射到发起请求的进程的虚拟地址空间。这个映射的过程通常由系统调用(如
mmap系统调用)完成,返回的是该进程虚拟地址空间中的起始地址。 -
共享内存创建:当另一个进程也需要访问该动态库时,操作系统并不会再次加载动态库到物理内存,而是同样采用页表映射的方式,将之前已分配的物理内存区域映射到新的进程地址空间。这样一来,两个进程就可以通过各自的虚拟地址访问到相同的物理内存内容,即实现了共享内存。
-
独立寻址、共享内容:尽管每个进程都有自己独立的地址空间和页表,但它们可以通过自己的虚拟地址访问同一个物理内存区域。这意味着对同一块共享内存区域进行的读写操作,在不同进程中都能看到结果。
-
同步控制:由于多个进程可以同时访问同一块共享内存,为了保证数据的一致性和正确性,通常还需要配合互斥锁、信号量等同步机制进行访问控制。
4、共享内存函数
shmget函数
shmget 函数是POSIX IPC(进程间通信)机制中用于创建或获取共享内存段的核心函数。该函数使得多个进程能够通过一个共同的键值标识符访问同一块内存区域,从而实现高效的数据交换。
#include <sys/shm.h>
int shmget(key_t key, size_t size, int shmflg);参数详解:
-
key: 这是一个用于唯一识别共享内存段的关键字,通常由ftok()函数生成。它在系统范围内起着类似于文件路径的作用,不同进程之间只要使用相同的键值,就能关联到同一个共享内存段。 -
size: 表示需要创建或获取的共享内存段的大小,单位为字节。指定的大小将决定进程间可共享数据区域的容量。 -
shmflg: 这个参数是一个标志位组合,包含了权限模式以及控制共享内存行为的选项。其中涉及了九个权限标志,它们与文件权限模式类似,比如读、写和执行权限。同时,shmflg中还可以包含特殊标志:IPC_EXCL:与IPC_CREAT。
单独使用 IPC_CREAT:
当仅指定 IPC_CREAT 标志调用 shmget() 函数时,系统的行为如下:
- 如果请求的共享内存段基于给定键值已经存在,则函数将不会创建新的共享内存,而是直接返回该已存在的共享内存段的标识符。
- 如果指定的共享内存段尚不存在,则函数将创建一个新的共享内存段,并返回其标识符。
单独使用 IPC_EXCL(无意义):
- 如果仅使用
IPC_EXCL标志而不配合IPC_CREAT使用,在大多数实现中,此操作没有实际意义,因为IPC_EXCL的效果只有在与IPC_CREAT一起使用时才会体现出来。
联合使用 IPC_CREAT 和 IPC_EXCL:
当同时设置 IPC_CREAT 和 IPC_EXCL 标志调用 shmget() 函数时,行为规则为:
- 如果请求的共享内存段根据提供的键值并不存在于底层系统中,则函数会创建一个新的共享内存段,并返回新创建段的标识符。
- 然而,若该键值对应的共享内存段已经存在,则
shmget()函数会失败,并返回错误状态,而不是简单地获取已存在的共享内存段。因此,通过这种方式,可以确保成功返回的共享内存段一定是刚刚创建的新段,不会与任何现有段冲突。
返回值说明:
- 成功调用时,
shmget()函数返回一个非负整数,即分配给所操作的共享内存段的标识符(也称为ID)。这个标识符对于用户层就如同打开文件后得到的文件描述符(fd),用于后续对共享内存的附加(attach)、读写和删除等操作。 - 如果失败,函数返回 -1,并设置全局变量
errno以指示具体错误原因。
参数key的作用:
在进程间通过共享内存进行通信时,为了确保双方都能访问到同一片共享内存,并且看到的是由对方创建的内存段,关键在于正确使用一个系统范围内唯一的键值(key)。具体步骤如下:
-
生成唯一键值:首先,无论是服务器进程还是客户端进程,都需调用
ftok()函数或其他方法来生成一个在整个系统中具有唯一性的键值。这个键值作为参数传递给shmget()函数。 -
共享键值:服务端和客户端必须事先约定好或以某种方式传递这个唯一的键值,确保双方使用的键值是相同的。
-
使用相同键值创建/获取共享内存:当服务端调用
shmget()创建共享内存时,它会使用这个预先确定好的键值。随后,客户端同样使用该键值调用shmget()来获取已存在的共享内存段。 -
一致性保证:只要服务端与客户端成功地采用了相同的键值执行
shmget()操作,那么无论哪一方创建了共享内存,另一方都能够准确无误地找到并连接到同一块共享内存区域进行数据交换。
ftok()函数
ftok() 函数是Linux系统 API 中的一个函数,主要用于生成一个用于进程间通信(IPC)的唯一键值。在诸如 System V IPC(包括消息队列、信号量和共享内存)这样的设施中,应用程序需要一个唯一的标识符来标识它们使用的特定资源。ftok() 函数就是用来生成这个键值的。
函数原型一般如下:
#include <sys/ipc.h>
key_t ftok(const char *pathname, int proj_id);参数说明:
pathname:一个已存在的文件路径名。ftok()会结合这个文件名及其索引节点(inode)号码和给定的项目标识符(proj_id)来生成键值。proj_id:一个整数值,通常选择程序的某种标识符,例如宏定义或者是程序内部的常数。这个值在生成键时起到辅助作用,有助于提高键的唯一性,但也可能受限于系统位宽限制,只使用了低8位或更少位。
返回值:
ftok()函数的返回值是一个键值(类型为key_t),这个键值可用于调用msgget(),semget(), 或shmget()等函数来创建或操作相应的 IPC 资源。
注意:
- 需要注意的是,由于 inode 数字可能重复,特别是在大量创建 IPC 键的情况下,单纯依赖
ftok()可能不足以产生完全唯一的键值。 - 在一些现代系统中,
ftok()的可靠性受到质疑,因为它生成的键可能不够唯一,尤其是当文件系统中有大量文件时。因此,在编写高并发或大型系统时,可能需要采用更复杂的方式来生成唯一的 IPC 键值。
shmat函数
shmat()函数是用于将一个已创建的共享内存段关联到当前进程地址空间的系统调用。其主要功能是建立进程与共享内存区域的连接,以便进程能够通过指针直接访问和操作这块共享内存。
原型定义如下:
void *shmat(int shmid, const void *shmaddr, int shmflg);参数说明:
-
shmid:这是共享内存标识符,它唯一标识了系统中要连接的共享内存段。 -
shmaddr:这是一个指向内存地址的指针,用于指定共享内存应被映射到进程地址空间中的位置。-
如果设置为NULL,则由内核自动选择一个合适的地址进行映射;
-
若非NULL且
shmflg中未包含SHM_RND标志,则尝试在指定地址shmaddr处进行映射; -
若
shmaddr非NULL且shmflg设置了SHM_RND标志,则实际映射的地址会向下调整至最接近且大于等于shmaddr的、对SHMLBA取整数倍的地址,计算公式为:shmaddr - (shmaddr % SHMLBA),其中SHMLBA通常是一个系统特定的页大小。
-
-
shmflg:此参数用于指定连接共享内存的方式。当shmflg设置为SHM_RDONLY时,表明该进程将以只读方式连接共享内存,不允许对其进行写操作。
函数返回值:
- 成功执行时,
shmat()函数返回一个指向共享内存首字节的指针。(虚拟地址) - 若发生错误,如无法找到指定的共享内存标识符或无法完成映射操作,则返回-1,并根据errno变量提供相应的错误信息。
shmdt函数
shmdt()函数是用于解除当前进程与指定共享内存段关联的系统调用,它的主要功能在于断开进程对之前映射到其地址空间内的共享内存区域的访问连接。
原型定义如下:
int shmdt(const void *shmaddr);参数说明:
shmaddr:此参数是一个指针,它是由先前成功调用shmat()函数时返回的指向共享内存首字节的地址。通过提供这个地址,系统能够确定要从当前进程中脱离关联的具体共享内存段。
返回值:
- 当
shmdt()函数成功执行并切断了当前进程与指定共享内存的联系后,将返回0。 - 若在执行过程中发生错误(例如,提供的
shmaddr无效或不再指向有效的共享内存区域),则函数会返回-1,并相应地设置errno变量来指示具体的错误原因。
特别提示:
使用shmdt()函数与某个共享内存段脱离关联并不意味着该共享内存段被删除或释放。即使所有进程都已与其断开关联,该共享内存仍然存在于系统中,直到显式调用shmctl()函数并设置适当的命令标志来删除它为止。这样可以确保在多个进程间灵活地管理和共享资源,每个进程可以根据需要独立地连接和断开与共享内存段的关联。
shmctl函数
shmctl()函数是一个用于管理和控制共享内存的系统调用,它提供了对已创建共享内存段进行各种操作的能力。
原型定义如下:
int shmctl(int shmid, int cmd, struct shmid_ds *buf);参数说明:
-
shmid:这是由先前成功调用shmget()函数时返回的共享内存标识符,它唯一地标识了系统中要执行控制操作的共享内存段。 -
cmd:这是一个指定操作类型的整数,可取值包括但不限于以下三个主要选项:- IPC_STAT:读取共享内存的状态信息并存入
buf指向的结构体中。 - IPC_SET:根据
buf指向的结构体中的内容更新共享内存段的状态和权限设置。 - IPC_RMID:删除指定的共享内存段,即使还有进程与之关联。
- IPC_STAT:读取共享内存的状态信息并存入
-
buf:这是一个指向shmid_ds结构体的指针,该结构体包含了关于共享内存的各种状态信息,如大小、所有者、所属组、访问模式以及最近一次存取的时间戳等。在执行某些cmd操作时,需要通过buf传递或接收共享内存的相关属性。
返回值:
- 若
shmctl()函数成功完成所请求的操作,则返回0。 - 如果在执行过程中遇到错误,例如无效的
shmid、非法的cmd参数或者无法执行相应的控制操作,函数将返回-1,并设置errno变量以反映具体的错误情况。
四、进程中实现共享内存
1、Makefile
.PHONY:all
all:shmClient shmServer
shmClient:shmClient.cc
g++ -o $@ $^ -std=c++11
shmServer:shmServer.cc
g++ -o $@ $^ -std=c++11
.PHONY:clean
clean:
rm -f shmClient shmServer.PHONY:声明 all 和 clean 是phony目标(伪目标),它们不是实际的文件名,而是仅表示一组操作。即使名为 all 或 clean 的文件存在,Make也会执行相应的操作。
all 目标:
- 这是默认的目标,当你在终端输入
make而没有指定具体目标时,会自动执行all目标下的命令。 - 它依赖于
shmClient和shmServer两个目标,意味着在执行all之前需要先构建这两个目标。
shmClient 和 shmServer 目标:
- 每个目标对应一个可执行程序的生成规则。
shmClient目标由shmClient.cc文件生成,使用g++编译器编译并链接,输出为shmClient可执行文件,并指定了-std=c++11标志来启用C++11标准支持。shmServer目标同样由shmServer.cc文件生成,采用与shmClient相同的编译和链接过程。
clean 目标:
- 清理目标,当执行
make clean时,将删除shmClient和shmServer两个可执行文件。 rm -f命令用于强制删除(如果存在)指定的文件。
2、Log.hpp
Log.hpp 文件提供了简单的日志输出功能,主要用于方便地在程序中添加各种级别的日志信息。
#ifndef _LOG_H_
#define _LOG_H_
// 预处理器防止多次包含该头文件
// 当第一次包含此头文件时,定义标识符_LOG_H_
// 如果再次包含,由于已有定义,就不会执行后续代码
#include <iostream>
#include <ctime> // 引入时间相关库,用于获取当前时间戳
#include <string>
// 定义日志级别枚举常量
// Debug:调试信息
// Notice:普通通知信息
// Warning:警告信息
// Error:错误信息
#define Debug 0
#define Notice 1
#define Warning 2
#define Error 3
// 定义与日志级别对应的消息字符串数组
const std::string msg[] = {
"Debug",
"Notice",
"Warning",
"Error"
};
// 定义日志输出流函数
// 参数message是要输出的日志信息,level是日志级别
std::ostream &Log(std::string message, int level)
{
// 获取当前时间戳(Unix时间,单位秒)
std::cout << " | " << (unsigned)time(nullptr) << " | ";
// 输出日志级别对应的字符串
std::cout << msg[level] << " | ";
// 输出具体的消息内容
std::cout << message;
// 返回std::cout,允许链式调用
return std::cout;
}
#endif // 结束条件编译块,避免多次包含这个头文件设计了一个非常基础的日志系统,主要特点如下:
- 提供了四个预定义的日志级别,分别是Debug、Notice、Warning和Error,这些级别可以通过整数值0、1、2、3来表示。
- 定义了一个静态字符串数组
msg[],其中包含了每个日志级别的文字描述。 - 定义了一个全局函数
Log,它接受一个字符串类型的消息和一个整数类型日志级别作为参数,然后按照特定格式输出日志信息,包括当前时间戳、日志级别和消息内容。 - 函数返回
std::cout引用,这意味着可以继续在日志输出语句后面添加更多的输出操作,例如换行符\n。
通过在程序中调用Log(message, level)函数,开发人员能够快速地将不同级别的日志信息输出到控制台(此处未涉及文件输出或其他更复杂的功能)。例如:
Log("A debug message", Debug) << "\n";这将会输出类似于这样的日志条目:
| 1678300000 | Debug | A debug message3、comm.hpp
这段代码提供了一个基于命名管道(FIFO)的基本同步机制,通过创建、打开、读写和关闭FIFO来实现在多个进程间的简单通信。
#pragma once
// 包含必要的系统头文件,包括IO流处理、Unix系统调用(如文件操作、进程间通信)
#include <iostream>
#include <cstdio>
#include <unistd.h> // 提供Unix标准函数,如fork、read、write等
#include <sys/types.h> // 提供类型定义,如pid_t、mode_t等
#include <sys/ipc.h> // 提供进程间通信相关功能
#include <sys/shm.h> // 提供共享内存管理功能
#include <cassert> // 提供断言宏assert
#include <cstring> // 提供字符串处理函数
#include <sys/stat.h> // 提供文件和文件系统状态信息的结构及函数声明
#include <fcntl.h> // 提供文件描述符的操作函数声明
// 引入自定义的日志模块
#include "Log.hpp"
using namespace std;
// 定义常量
// 命名管道(FIFO)的路径
#define PATH_NAME "/home/hbr/linux/procIPC"
// 用于ftok函数生成IPC键的项目标识符
#define PROJ_ID 0x66
// 共享内存大小,通常设为系统页面大小的整数倍以提高效率
#define SHM_SIZE 4096
// 定义FIFO(命名管道)的名称,相对路径相对于执行程序所在位置
#define FIFO_NAME "./fifo"
//READ和WRITE文件打开模式的简写标记,它们对应于Unix/Linux系统中的文件访问标志。
#define READ O_RDONLY
#define WRITE O_WRONLY
// 定义Init类,负责在构造时创建FIFO并在析构时删除FIFO
class Init
{
public:
// 构造函数,在创建对象时创建FIFO
Init()
{
// 设置umask,确保FIFO创建时具有合适的权限
umask(0);
// 创建FIFO
int n = mkfifo(FIFO_NAME, 0666); // 权限为所有用户可读写
// 断言检查FIFO创建是否成功
assert(n == 0); // 如果mkfifo返回0,表示成功创建
// 忽略返回值,仅用于编译器消除“未使用的变量”警告
(void)n;
// 记录日志,表示FIFO创建成功
Log("create fifo success", Notice) << "\n";
}
// 析构函数,在对象销毁时删除FIFO
~Init()
{
// 删除已创建的FIFO
unlink(FIFO_NAME);
// 记录日志,表示FIFO删除成功
Log("remove fifo success", Notice) << "\n";
}
};
// 定义OpenFIFO函数,用于打开并返回FIFO的文件描述符
int OpenFIFO(std::string pathname, int flags)
{
// 使用open函数打开FIFO,传入路径名和打开方式标志
int fd = open(pathname.c_str(), flags);
// 断言检查FIFO是否成功打开
assert(fd >= 0); // 如果fd大于等于0,表示成功打开
// 返回打开后的文件描述符
return fd;
}
// 定义Wait函数,用于阻塞等待FIFO上的数据,并读取固定大小的数据
void Wait(int fd)
{
// 记录日志,表示进程开始等待FIFO上的数据
Log("等待中....", Notice) << "\n";
// 定义临时变量,用于接收从FIFO读取的数据
uint32_t temp = 0;
// 从FIFO中读取固定大小(sizeof(uint32_t)字节)的数据
ssize_t s = read(fd, &temp, sizeof(uint32_t));
// 断言检查是否成功读取预期大小的数据
assert(s == sizeof(uint32_t)); // 如果读取字节数与预期相符,则认为读取成功
// 忽略返回值s,仅为避免编译器警告
(void)s;
}
// 定义Signal函数,用于向FIFO写入数据,唤醒等待的进程
void Signal(int fd)
{
// 定义一个临时变量,存储要发送至FIFO的信号数据(在此案例中为1)
uint32_t temp = 1;
// 向FIFO写入固定大小(sizeof(uint32_t)字节)的数据
ssize_t s = write(fd, &temp, sizeof(uint32_t));
// 断言检查是否成功写入预期大小的数据
assert(s == sizeof(uint32_t)); // 如果写入字节数与预期相符,则认为写入成功
// 记录日志,表示进程正在通过FIFO唤醒其他进程
Log("唤醒中....", Notice) << "\n";
// 忽略返回值s,仅为避免编译器警告
(void)s;
}
// 定义CloseFifo函数,用于关闭已打开的FIFO文件描述符
void CloseFifo(int fd)
{
// 关闭指定文件描述符所对应的FIFO
close(fd);
}常量定义:
PATH_NAME是FIFO的路径,默认设置为/home/whb,这是FIFO将在其中创建的目录。PROJ_ID是一个标识符,用于ftok()函数生成一个唯一的IPC键,虽然在这个示例中未直接使用FIFO与共享内存(shmget),但在其他上下文中,这个键可能用于关联共享内存或其他形式的IPC资源。SHM_SIZE定义了共享内存的大小,尽管在这个例子中没有直接用到共享内存的创建,但这是一个常见的做法,使得共享内存大小是系统页面大小的整数倍,有助于减少内存碎片。-
O_RDONLY:这是Unix系统中的一个常量,它代表只读打开模式。当一个文件被以O_RDONLY模式打开时,进程只能从中读取数据,不能进行写入操作。 -
O_WRONLY:这是另一个Unix系统中的常量,它代表只写打开模式。当一个文件被以O_WRONLY模式打开时,进程只能向其中写入数据,不能从中读取。
Init类:
- 构造函数初始化时会创建一个FIFO,通过
mkfifo()函数实现,同时修改当前进程的umask以便FIFO具有适当的权限(0666意味着所有用户都有读写权限)。 - 析构函数会在对象销毁时删除FIFO,通过
unlink()函数实现。
OpenFIFO() 函数:
- 用于打开给定路径下的FIFO,传入路径名和标志位(比如读写模式),返回FIFO的文件描述符。
Wait() 函数:
- 该函数会让调用进程进入阻塞状态,等待FIFO中有数据可读。当有数据时,它会尝试读取固定大小的数据(这里是
uint32_t类型的)。如果成功读取,表明接收到一个信号。
Signal() 函数:
- 将一个信号(在这里是整数值1)写入到指定FIFO中,从而唤醒正在等待该FIFO上读取数据的进程。
CloseFifo() 函数:
- 用于关闭先前由
OpenFIFO()打开的FIFO文件描述符,释放系统资源。
4、shmServer.cc
shmServer.cc 文件展示了如何在C++中使用共享内存(shared memory)进行进程间通信(IPC),同时结合命名管道(FIFO)进行同步。
#include "comm.hpp"
// 全局变量init在程序开始时被实例化,触发FIFO的创建
Init init;
string TransToHex(key_t k)
{
// 将key_t类型的键转换成十六进制字符串
char buffer[32];
snprintf(buffer, sizeof buffer, "0x%x", k);
return buffer;
}
int main()
{
// 1. 生成共享内存的唯一键值
key_t k = ftok(PATH_NAME, PROJ_ID);
assert(k != -1);
Log("create key done", Debug) << " server key : " << TransToHex(k) << endl;
// 2. 创建一个新的共享内存段(如果不存在则创建,设置只允许创建者访问,可读写)
int shmid = shmget(k, SHM_SIZE, IPC_CREAT | IPC_EXCL | 0666);
if (shmid == -1)
{
perror("shmget"); // 输出错误信息
exit(1);
}
Log("create shm done", Debug) << " shmid : " << shmid << endl;
// 3. 将共享内存映射到当前进程的地址空间
char *shmaddr = (char *)shmat(shmid, nullptr, 0);
Log("attach shm done", Debug) << " shmid : " << shmid << endl;
// 打开FIFO以读模式
int fd = OpenFIFO(FIFO_NAME, READ);
// 循环等待客户端发来的信号
for(;;)
{
// 当FIFO中有数据时,即视为客户端准备好了
Wait(fd);
// 临界区:此时假设客户端已将数据写入共享内存
printf("%s\n", shmaddr);
if(strcmp(shmaddr, "quit") == 0) break; // 如果收到“quit”,退出循环
}
// 4. 解除共享内存映射
int n = shmdt(shmaddr);
assert(n != -1);
(void)n;
Log("detach shm done", Debug) << " shmid : " << shmid << endl;
// 5. 删除共享内存段(即使还有其他进程连接到它)
n = shmctl(shmid, IPC_RMID, nullptr);
assert(n != -1);
(void)n;
Log("delete shm done", Debug) << " shmid : " << shmid << endl;
// 关闭FIFO文件描述符
CloseFifo(fd);
return 0;
}全局变量初始化:
Init init;这里假设Init类的实例化会在程序启动时自动创建所需的FIFO管道(可能通过构造函数实现)。
将key_t类型转换为十六进制字符串:
string TransToHex(key_t k)这个函数接受一个key_t类型的键,并将其转换为一个十六进制格式的字符串,以便于输出和调试。
printf("%s\n", shmaddr);主函数:
- 生成共享内存唯一键: 使用
ftok函数根据给定的路径名和项目标识符生成一个唯一的共享内存键。key_t k = ftok(PATH_NAME, PROJ_ID); - 创建共享内存段: 调用
shmget函数创建一个共享内存段,如果不存在则创建,同时设置权限位(创建者可读写)。如果创建失败,会输出错误信息并退出程序。int shmid = shmget(k, SHM_SIZE, IPC_CREAT | IPC_EXCL | 0666); - 映射共享内存到进程地址空间: 使用
shmat函数将共享内存段映射到当前进程的地址空间,这样就可以像操作普通内存一样操作共享内存。char *shmaddr = (char *)shmat(shmid, nullptr, 0); - 打开FIFO以读模式: 调用
OpenFIFO自定义函数打开FIFO管道,用于从客户端接收消息。 - 循环等待客户端信号: 进入无限循环,等待客户端通过FIFO管道发送信号。
- 读取共享内存中的数据: 当检测到FIFO中有数据时(
Wait(fd)可能是对FIFO有数据可读状态的检查),假定客户端已经将数据写入共享内存,然后直接从共享内存中读取数据并打印。printf("%s\n", shmaddr); - 退出循环条件: 如果读取到的数据内容为字符串"quit",则退出循环,停止服务。
- 同步注意事项: 注释中指出,在实际应用中,应该在此处加入适当的同步措施(如互斥锁或信号量),以确保在多进程环境下对共享内存区域的安全并发访问。
- 解除共享内存映射: 在退出循环后,使用
shmdt函数解除共享内存映射,释放本进程中与共享内存相关的资源。 - 删除共享内存段: 调用
shmctl函数删除共享内存段,即使还有其他进程连接到该内存段。 - 关闭FIFO文件描述符: 最后,关闭之前打开的FIFO文件描述符。
5、shmClient.cc
该客户端程序的主要任务是从标准输入读取数据,并将其写入预先创建好的共享内存中,然后通过FIFO通知服务器读取共享内存中的新数据。当接收到特定的"quit"指令时,客户端终止循环并解除对共享内存的映射关系。整个过程中,客户端仅对共享内存进行读写操作,而不负责其生命周期管理。
// 引入自定义库文件 "comm.hpp",假设其中包含日志记录功能、共享内存和FIFO相关操作的声明和定义
int main()
{
// 记录当前子进程的ID,并以调试级别输出
Log("child pid is : ", Debug) << getpid() << endl;
// 使用ftok函数根据PATH_NAME和PROJ_ID生成一个用于访问共享内存的唯一键值
key_t k = ftok(PATH_NAME, PROJ_ID);
if (k < 0)
{
// 创建key失败时,记录错误日志并退出程序
Log("create key failed", Error) << " client key : " << k << endl;
exit(1);
}
// 成功生成key后记录日志
Log("create key done", Debug) << " client key : " << k << endl;
// 尝试使用生成的key获取预设大小的共享内存
int shmid = shmget(k, SHM_SIZE, 0);
if(shmid < 0)
{
// 创建共享内存失败时,记录错误日志并退出程序
Log("create shm failed", Error) << " client key : " << k << endl;
exit(2);
}
// 记录成功获取共享内存的日志
Log("create shm success", Error) << " client key : " << k << endl;
// 程序在此处原本可能有一个暂停10秒的操作(已注释掉)
// 将共享内存连接到当前进程的地址空间
char *shmaddr = (char *)shmat(shmid, nullptr, 0);
if(shmaddr == nullptr)
{
// 连接共享内存失败时,记录错误日志并退出程序
Log("attach shm failed", Error) << " client key : " << k << endl;
exit(3);
}
// 记录成功连接共享内存的日志
Log("attach shm success", Error) << " client key : " << k << endl;
// 打开与服务器通信的FIFO,设置为写模式
int fd = OpenFIFO(FIFO_NAME, WRITE);
// 使用无限循环,将共享内存当作字符缓冲区
while(true)
{
// 从标准输入(一般是键盘)读取数据至共享内存缓冲区,允许的最大数据量为SHM_SIZE-1个字节(预留一个字节存放结束符)
ssize_t s = read(0, shmaddr, SHM_SIZE-1);
if(s > 0)
{
// 在读取的数据末尾添加字符串结束符
shmaddr[s-1] = 0;
// 发送信号至FIFO,通知服务器有新数据可用
Signal(fd);
// 检查读取的字符串内容是否为"quit",若是则跳出循环
if(strcmp(shmaddr,"quit") == 0) break;
}
}
// 解除当前进程与共享内存的关联
int n = shmdt(shmaddr);
// 断言解关联操作成功(如果失败,实际应用中通常不会继续而是处理错误)
assert(n != -1);
// 记录成功解除共享内存关联的日志
Log("detach shm success", Error) << " client key : " << k << endl;
// 客户端无需调用shmctl删除共享内存,因为它的生命周期管理通常由其他进程负责
// 程序执行完毕,返回0表示正常退出
return 0;
}这段C++代码描述的是一个客户端程序,它同样利用了进程间通信(IPC)机制,包括共享内存和FIFO(先进先出队列)。下面是代码逐行解释:
-
初始化日志输出,记录子进程的PID。
Log("child pid is : ", Debug) << getpid() << endl; -
使用
ftok函数基于指定的路径名和项目标识符生成一个共享内存键。key_t k = ftok(PATH_NAME, PROJ_ID);如果生成失败,则输出错误信息并退出程序。
-
调用
shmget函数尝试获取已创建的共享内存段。这里传入0作为权限标志,表示客户端只想获取已存在的共享内存,不创建新的内存段。int shmid = shmget(k, SHM_SIZE, 0);如果获取失败,也会输出错误信息并退出程序。
-
成功获取共享内存段后,将共享内存映射到客户端进程的地址空间,以便进行读写操作。
char *shmaddr = (char *)shmat(shmid, nullptr, 0);若映射失败,同样会输出错误信息并退出程序。
-
打开FIFO以写模式,准备向服务器发送信号。
int fd = OpenFIFO(FIFO_NAME, WRITE); -
客户端进入无限循环,从标准输入(通常是键盘输入)读取数据,然后填充到共享内存缓冲区中。
ssize_t s = read(0, shmaddr, SHM_SIZE-1);read函数读取标准输入的内容到共享内存地址,限制最大读取字节数为SHM_SIZE-1,留出一个字节存储结束符'\0'。 -
给字符串添加结束符,并检查是否收到"quit"指令来决定是否跳出循环。
shmaddr[s-1] = 0; if(strcmp(shmaddr,"quit") == 0) break; -
发送一个信号(通过
Signal(fd)函数,这里是模拟的,具体实现未给出)告知服务器共享内存中有新数据可供读取。 -
循环结束后,解除共享内存的映射关系。
int n = shmdt(shmaddr); assert(n != -1); -
客户端并不需要调用
shmctl去删除共享内存段,因为它是共享资源,应当由服务器或其他合适的角色负责清理。
最后,程序返回0,表示正常执行完毕。
运行测试: