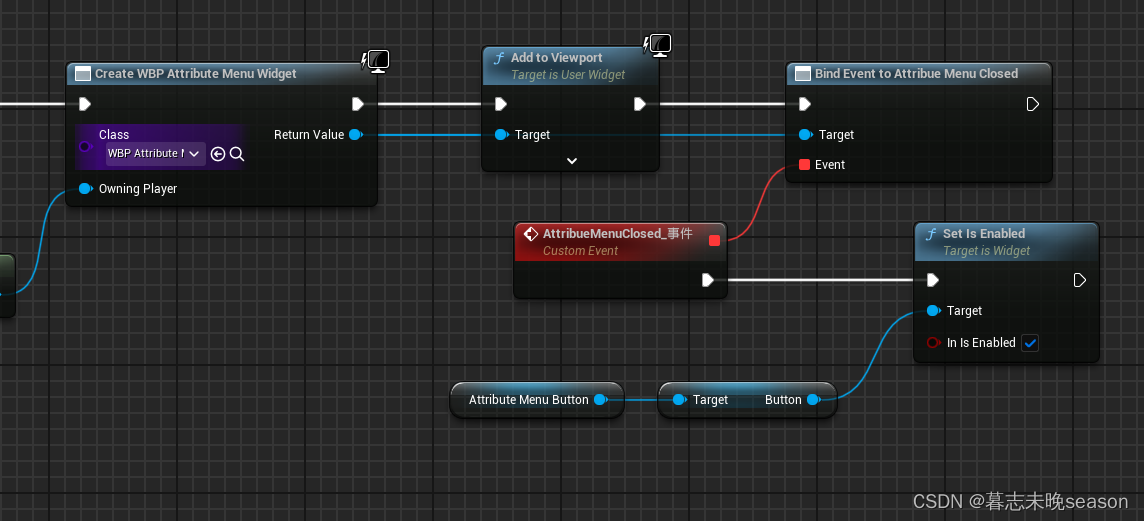
百度出了如图所示的验证码,需要拖动滑块,与如图所示的曲线轨迹进行重合。经过不断研究,终于解决了这个问题。我把识别代码分享给大家。
下面是使用selenium进行验证的,这样可以看到轨迹滑动的过程,如果需要使用js逆向的大神,可以自行研究,谢谢。
运行下面代码会直接进入验证码页面,可能会出现百度旋转验证码,我会通过刷新的方式,刷出百度曲线轨迹验证码。当出现验证码后会进行识别,然后计算滑动像素距离,然后进行拖动滑块,最后自动判断是否验证通过,并记录正确率,大家可以自行尝试。
具体的代码分享在下发,可能会因为selenium版本不同,导致部分语法略有不同,大家可以使用GPT进行一下转换。
想了解更多验证码识别,请访问:得塔云
import os
import sys
import time
import random
import base64
import requests
import io
from io import BytesIO
from PIL import Image, ImageDraw
from selenium import webdriver
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.common.action_chains import ActionChains
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support.select import Select
from selenium.webdriver import FirefoxOptions
#PIL图片保存为base64编码
def PIL_base64(img, coding='utf-8'):
img_format = img.format
if img_format == None:
img_format = 'JPEG'
format_str = 'JPEG'
if 'png' == img_format.lower():
format_str = 'PNG'
if 'gif' == img_format.lower():
format_str = 'gif'
if img.mode == "P":
img = img.convert('RGB')
if img.mode == "RGBA":
format_str = 'PNG'
img_format = 'PNG'
output_buffer = BytesIO()
# img.save(output_buffer, format=format_str)
img.save(output_buffer, quality=100, format=format_str)
byte_data = output_buffer.getvalue()
base64_str = 'data:image/' + img_format.lower() + ';base64,' + base64.b64encode(byte_data).decode(coding)
return base64_str
# 识别滑动距离
def shibie(img):
# 图片转base64
img_base64 = PIL_base64(img)
# 验证码识别接口
url = "http://www.detayun.cn/openapi/verify_code_identify/"
data = {
# 用户的key
"key": "CcoAB3Cd78wXFQ07Zz3",
# 验证码类型
"verify_idf_id": "43",
# 大图
"img_base64": img_base64,
}
header = {"Content-Type": "application/json"}
# 发送请求调用接口
response = requests.post(url=url, json=data, headers=header)
data = response.json()
if data['code'] == 200:
return data['data']['distance']
else:
print('状态码异常:',data)
return
# 运行程序
def run():
# 打开邮政页面
option = FirefoxOptions()
# option.add_argument('--headless')
driver = webdriver.Firefox(executable_path=r'webdriver\geckodriver.exe', options=option)
# 记录成功次数
t = 0
#记录失败次数
f = 0
for i in range(2000):
driver.get('https://seccaptcha.baidu.com/v1/webapi/verint/svcp.html?ak=M7bcdh2k6uqtYV5miaRiI8m8x6LIaONq&backurl=https%3A%2F%2Fwenku.baidu.com%2F%3F_wkts_%3D1705066238641&ext=ih2lW9VV3PmxmO%2B%2Bx8wZgk9i1xGx9WH05J9hI74kTEVkpokzRQ8QxLB082MG2VoQUUT15llYBwsC%2BAaysNoPxpuKg0Hkpo4qMzBjXDEGhuQ%3D&subid=pc_home&ts=1705066239&sign=1cebe634245cd92fc9eca10d0850a36b')
time.sleep(3)
html_str = driver.page_source
if 'canvas' in html_str:
if '曲线' in html_str:
print('曲线验证码')
# 等待画布加载完成
WebDriverWait(driver, 20).until(lambda x: x.find_element_by_xpath('/html/body/div/div[2]/div/div/div/div[2]/canvas'))
canvas_list = driver.find_elements_by_xpath('/html/body/div/div[2]/div/div/div/div[2]/canvas')
# 图片列表
img_list = []
# 遍历所有的画布元素
for canvas in canvas_list:
# 使用JavaScript获取canvas的内容,并在WebDriver对象上调用execute_script
canvas_content = driver.execute_script("return arguments[0].toDataURL('image/png');", canvas)
# 将base64编码的图片内容解码为字节
img_bytes = base64.b64decode(canvas_content.split(',')[1])
# 将字节转换为图片对象
img = Image.open(io.BytesIO(img_bytes))
img_list.append(img)
# 合并所有图片为一张
# 创建一个新的图片对象,用于合并所有的图片
merged_img = Image.new('RGBA', (max(img.size[0] for img in img_list), max(img.size[1] for img in img_list)))
# 将每个图片合并到merged_img上,保持透明度
y_offset = 0
for img in img_list:
# 计算x偏移量以保持图片对齐(这里假设所有图片宽度相同)
x_offset = 0
# 将图片合并到merged_img上,保持透明度
merged_img.paste(img, (x_offset, y_offset), img)
# png图片转
# 如果是png图片
if str(merged_img.format).lower() == 'png':
# 输出颜色模式
if merged_img.mode == 'RGBA':
# 创建一个新的白色背景图像
white_background = Image.new('RGBA', merged_img.size, (255, 255, 255, 255))
# 创建一个可以在白色背景上绘图的对象
draw = ImageDraw.Draw(white_background)
# 将原始的PNG图像粘贴到白色背景上,使用一个全白色的图像作为蒙版
white_background.paste(merged_img, mask=merged_img)
merged_img = white_background
# img = img.convert('RGB')
# 转换为JPG格式
# 创建一个BytesIO对象
output = io.BytesIO()
# 将PNG图像转换为JPG格式并保存到BytesIO对象中
merged_img.convert('RGB').save(output, 'JPEG')
# 通过BytesIO对象创建PIL对象
merged_img = Image.open(output)
# 识别滑动位置
y = shibie(merged_img)
print('滑动距离为:', y)
# 等待滑块出现
WebDriverWait(driver, 10).until(lambda x: x.find_element_by_xpath('/html/body/div/div[2]/div/div/div/div[3]/div/div[2]'))
yzm_button = driver.find_element_by_xpath('/html/body/div/div[2]/div/div/div/div[3]/div/div[2]')
# 滑动滑块
action = ActionChains(driver)
action.click_and_hold(yzm_button).perform()
# 计算实际滑动距离 = 像素距离 + 前面空白距离
action.move_by_offset(y, 0)
action.release().perform()
# 判断是否成功 app
try:
WebDriverWait(driver, 5).until(lambda x: x.find_element_by_xpath('//div[@id="app"]'))
t += 1
print('成功')
except:
f += 1
print('失败')
print('总次数:{},成功:{},失败:{},正确率:{}'.format(t + f, t, f, t/(t+f)))
if __name__ == '__main__':
run()