下载代码:https://github.com/asagar60/TableNet-pytorch
下载模型:https://drive.usercontent.google.com/download?id=13eDDMHbxHaeBbkIsQ7RSgyaf6DSx9io1&export=download&confirm=t&uuid=1bf2e85f-5a4f-4ce8-976c-395d865a3c37
原理:https://asagar60.medium.com/tablenet-deep-learning-model-for-end-to-end-table-detection-and-tabular-data-extraction-from-b1547799fe29
tablenet
通过端到端的训练来同时优化表格区域检测和表格结构识别,从而实现更高的准确性和效率。
任务:
-
精确检测称为表检测的表格区域。
-
检测到的表的行和列中检测和提取信息,称为表结构识别。
tablenet使用一个网络来同时解决这两个任务。它是一个端到端模型,将文档分辨率为 1024x1024 的图像作为输入,并生成两个语义标记的输出,一个用于图像中的表,另一个用于表中的列,分别称为表和列掩码。生成这些掩码后,使用表掩码从图像中过滤表格。
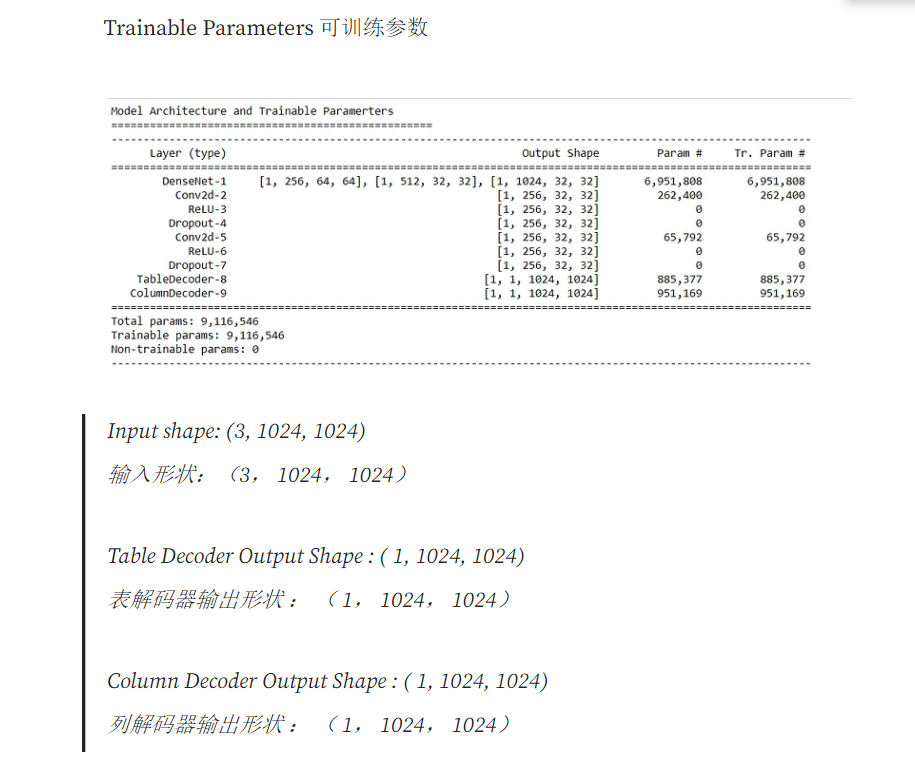
模型架构:

类似于编码器-解码器模型,编码器对图像中表的位置和结构信息进行编码,解码器使用这些信息为表和列生成掩码。
对于编码器,使用在 ImageNet 数据集上预训练的 VGG-19 模型。
接下来是两个单独的解码器分支,分别用于对表和列进行分段。解码器分支相互独立训练,而编码器可以使用两个解码器的梯度进行微调。
VGG-19 的全连接层(pool5 之后的层)被替换为两个 (1x1) 卷积层。这些卷积层 (conv6) 中的每一个都使用 ReLU 激活,然后是概率为 0.8 的 dropout 层。
来自 3 个池化层的输出与表解码器和列解码器连接,然后多次upscale。值得一提的是,ResNet-18 和 EfficientNet 的性能几乎接近 DenseNet,但选择了基于测试数据的最佳 F1 分数的模型。
训练策略:

与 VGG19、ResNet-18 和 EfficientNet 相比,Densenet121 作为编码器效果最好。
模型:
→DenseNet121 编码器块
→Table 解码器块
→Column 解码器模块
loss函数
BCEWithLogitsLoss() 在这里用作损失。这是 Sigmoid + 二进制交叉熵损失的组合。这将分别应用于列掩码和表掩码。

class TableNetLoss(nn.Module):
def __init__(self):
super(TableNetLoss, self).__init__()
self.bce = nn.BCEWithLogitsLoss()
def forward(self, table_pred, table_gt, col_pred = None, col_gt = None, ):
table_loss = self.bce(table_pred, table_gt)
column_loss = self.bce(col_pred, col_gt)
优化器
用的adam
原有模型测试效果
下载github TableNet-pytorch 代码
安装pytesseract
设置环境变量
下载语言包
更改app的pytesseract路径, pytesseract.pytesseract.tesseract_cmd
设置环境:pt.image_to_string(thresh1,lang=“chi_sim”)
streamlit run app.py
效果不是太好
训练模型
python train.py
报错内存不足,将测试集的batch_size也调整为2
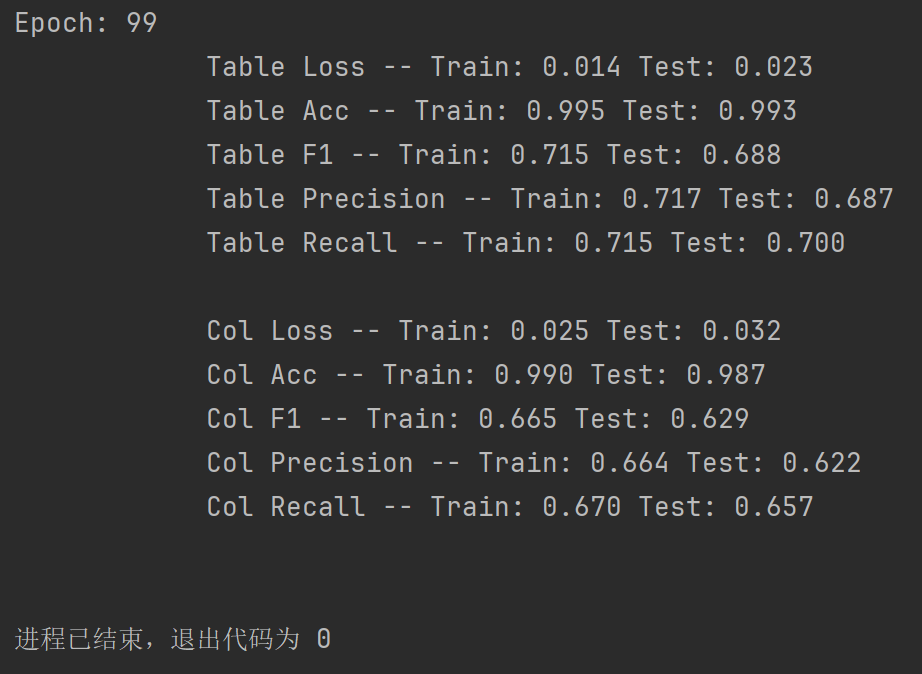
使用原始数据集,训练结果: