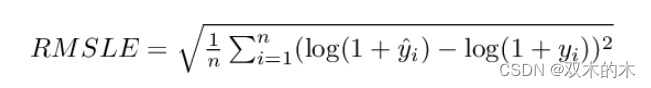PP-YOLO系列,均是基于百度自研PaddlePaddle深度学习框架发布的算法,2020年基于YOLOv3改进发布PP-YOLO,2021年发布PP-YOLOv2和移动端检测算法PP-PicoDet,2022年发布PP-YOLOE和PP-YOLOE-R。由于均是一个系列,所以放一起解读,方便对比前后改进地方。
PP-YOLO系列算法解读:
- PP-YOLO算法解读
- PP-YOLOv2算法解读
- PP-PicoDet算法解读
- PP-YOLOE算法解读
- PP-YOLOE-R算法解读
YOLO系列算法解读:
- YOLOv1通俗易懂版解读
- SSD算法解读
- YOLOv2算法解读
- YOLOv3算法解读
- YOLOv4算法解读
- YOLOv5算法解读
文章目录
- 1、算法概述
- 2、PP-YOLOv2细节
- 3、实验
- 3.1 消融实验
- 3.2 与其他检测算法比较
- 3.3 不起作用的trick
PP-YOLOv2(2021.4.21)
论文:PP-YOLOv2: A Practical Object Detector
作者:Xin Huang, Xinxin Wang, Wenyu Lv, Xiaying Bai, Xiang Long, Kaipeng Deng, Qingqing Dang, Shumin Han, Qiwen Liu, Xiaoguang Hu, Dianhai Yu, Yanjun Ma, Osamu Yoshie
链接:https://arxiv.org/abs/2104.10419
代码:https://github.com/PaddlePaddle/PaddleDetection
1、算法概述
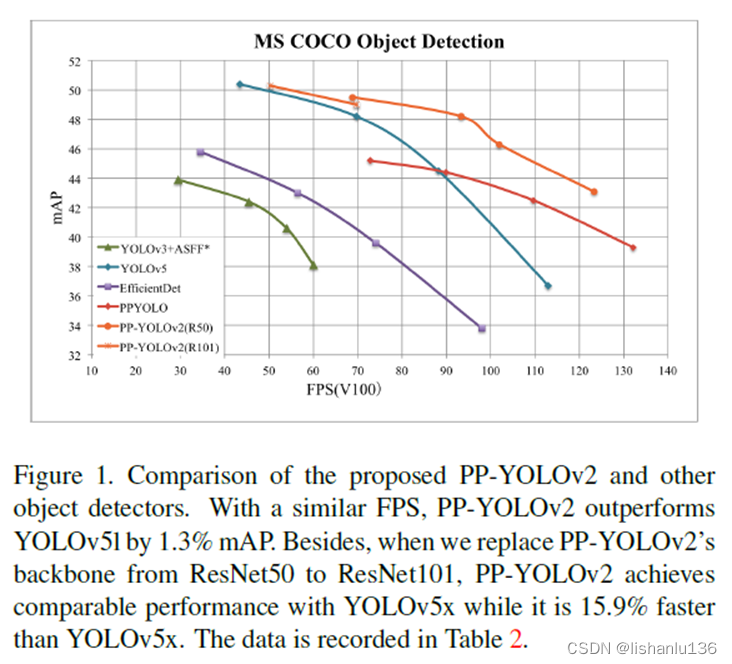
基于现有的改进trick,在保持推理时间基本不变的情况下,尽量提升PP-YOLO的mAP指标。通过结合多种有效的改进,作者将PP-YOLO在COCO2017test-dev数据集中的性能从45.9%mAP提高到49.5%mAP。PP-YOLOv2在640x640输入尺寸下运行速率为68.9FPS。如果将模型转换为TensorRT并且以FP16的推理精度在batchsize为1的情况下,推理速度可以提升至106.5FPS,远远超越了相同参数量下的YOLOv4-CSP和YOLOv5l。另外,如果用ResNet101作为PP-YOLOv2的主干网络,在COCO2017test-dev集上的mAP可达到50.3%mAP。和其他算法mAP及FPS指标对比如图:
2、PP-YOLOv2细节
论文通篇看下来改进的地方不多,都是借助现有trick在PP-YOLO基础上改,主要改的地方还是集中在Neck和head部分,直接看网络结构图:
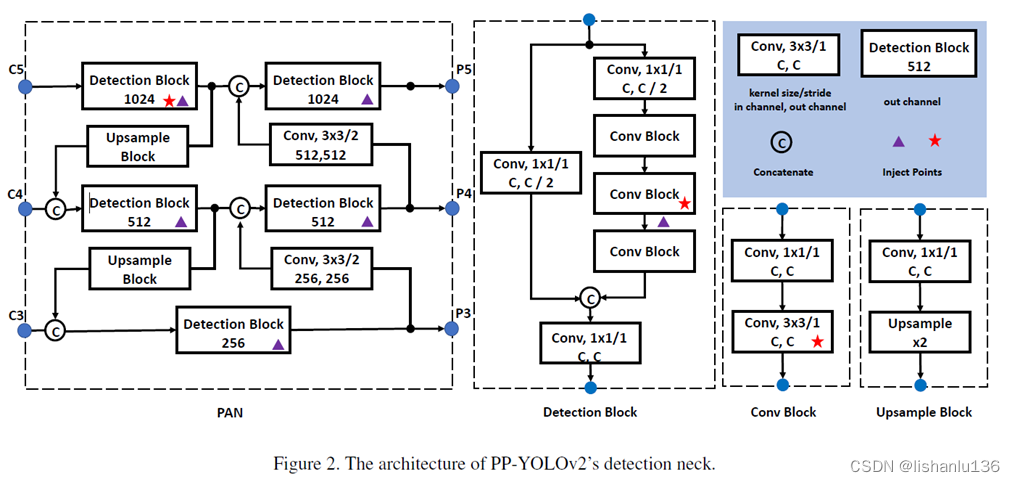
改进的地方如下:
- Path Aggregation Network: 直接翻译叫路径增强网络,用于加强不同层特征图进行融合。PP-YOLO中neck部分仅仅使用了FPN,特征融合还不够,现在增强特征金字塔融合的子网络有很多,比如:BiFPN,PAN,RFP等等;参考YOLOv4,PP-YOLOv2也在neck部分使用了PAN。
- Mish Activation Function: YOLOv4和YOLOv5中都使用了Mish激活函数用于提升检测器的性能,但是它们是在主干网络中使用的。我们为了保持强大的主干预训练模型不变,所以只在neck部分使用mish激活函数。
- Larger Input Size: 输入尺寸由608变到768,多尺度训练变换集为[320,352,384,…,704,736,768]
- IoU Aware Branch: 改进IoU感知分支的损失计算方式,PP-YOLO是以软权重方式计算,这里改为以软标签形式计算损失:
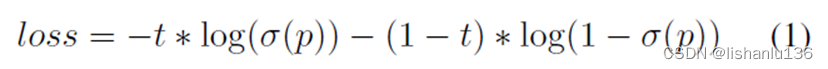
其中t代表anchor和匹配到的gt框的IoU大小,p是IoU感知分支的预测输出,σ代表sigmoid激活函数。注意这里只有正样本的anchor才参与损失的计算。通过这个改进,IoU感知分支比上一个版本工作得更好。
3、实验
3.1 消融实验
同PP-YOLO一样,作者对如上改进实验做了消融实验以得到改进措施对应提升多少mAP,实验结果如下:
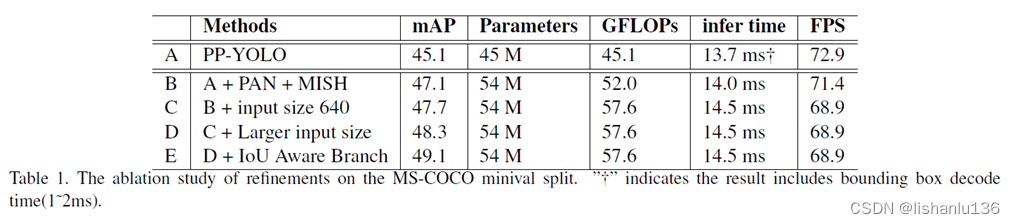
从表中可以看出,提升最大的还是从A->B,增加neck部分的特征融合及改进激活函数,直接提升2%mAP;虽然增加收入尺寸可以提升少许mAP,但这是以减少FPS为代价的;改进IoU感知分支在不影响推理速度的情况下也可以直接带来近1%mAP的提升。
3.2 与其他检测算法比较
PP-YOLOv2与现如今最新检测算法在COCO数据集上的mAP比较如下表所示。
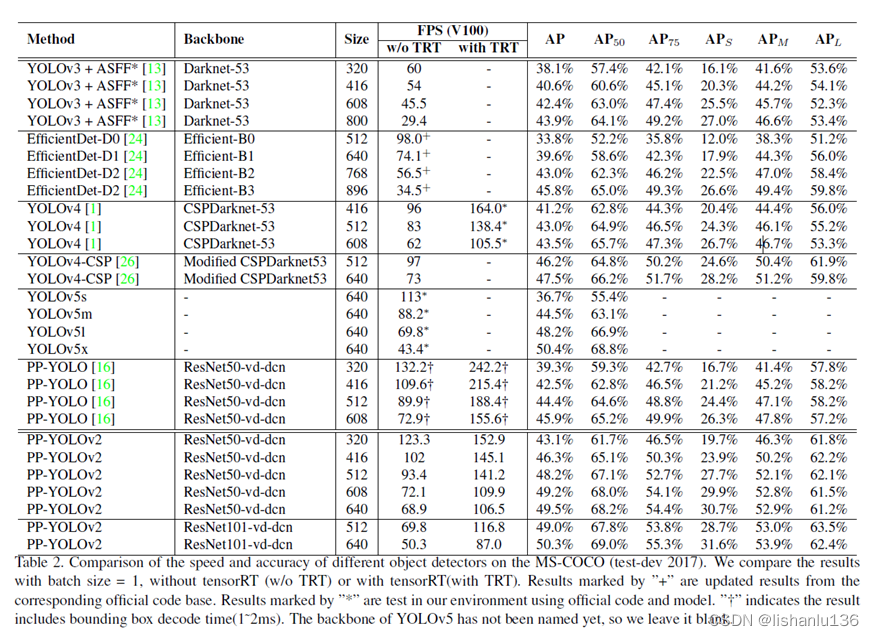
从表中可以看出,PP-YOLOv2和YOLOv4、YOLOv5比较,相近FPS情况下,mAP都好于后者。
3.3 不起作用的trick
- Cosine Learning Rate Decay: 由于余弦学习率衰减策略对初始学习率、预热步数和结束学习率等超参数敏感,所以作者没有采用这种方式。
- Backbone Parameter Freezing: 在对下游任务的ImageNet预训练参数进行微调时,通常在前两个阶段冻结参数。作者在COCO minitrain数据集上确实提升了1%mAP,但在COCOtrain2017上下降了0.8%mAP,所以作者最终没有冻结训练backbone参数。
- SiLU激活函数: 在neck部分采用SiLU激活函数会不如Mish激活函数。