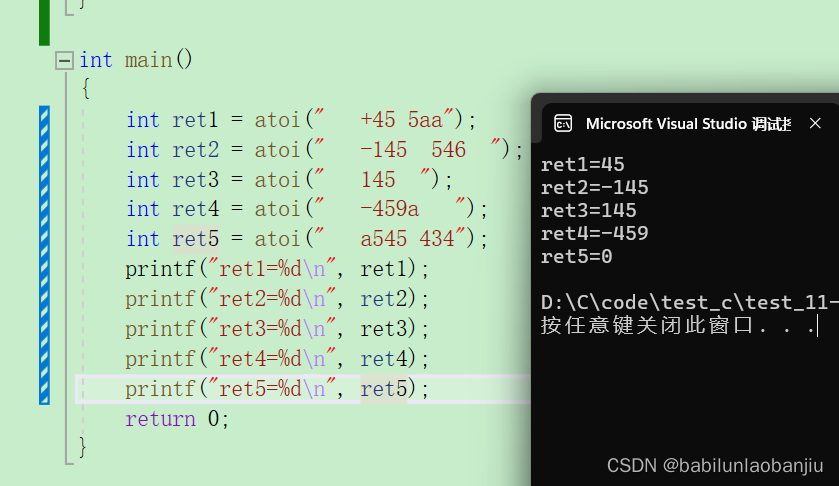
在上一课时我们了解了 LoadBalance 接口定义以及 AbstractLoadBalance 抽象类的内容,还详细介绍了 ConsistentHashLoadBalance 以及 RandomLoadBalance 这两个实现类的核心原理和大致实现。本课时我们将继续介绍 LoadBalance 的剩余三个实现。
LeastActiveLoadBalance 最小活跃数
LeastActiveLoadBalance 使用的是最小活跃数负载均衡算法。它认为当前活跃请求数越小的 Provider 节点,剩余的处理能力越多,处理请求的效率也就越高,那么该 Provider 在单位时间内就可以处理更多的请求,所以我们应该优先将请求分配给该 Provider 节点。
LeastActiveLoadBalance 需要配合 ActiveLimitFilter 使用,ActiveLimitFilter 会记录每个接口方法的活跃请求数,在 LeastActiveLoadBalance 进行负载均衡时,只会从活跃请求数最少的 Invoker 集合里挑选 Invoker。
在 LeastActiveLoadBalance 的实现中,首先会选出所有活跃请求数最小的 Invoker 对象,之后的逻辑与 RandomLoadBalance 完全一样,即按照这些 Invoker 对象的权重挑选最终的 Invoker 对象。下面是 LeastActiveLoadBalance.doSelect() 方法的具体实现:
protected <T> Invoker<T> doSelect(List<Invoker<T>> invokers, URL url, Invocation invocation) {
// 初始化Invoker数量
int length = invokers.size();
// 记录最小的活跃请求数
int leastActive = -1;
// 记录活跃请求数最小的Invoker集合的个数
int leastCount = 0;
// 记录活跃请求数最小的Invoker在invokers数组中的下标位置
int[] leastIndexes = new int[length];
// 记录活跃请求数最小的Invoker集合中,每个Invoker的权重值
int[] weights = new int[length];
// 记录活跃请求数最小的Invoker集合中,所有Invoker的权重值之和
int totalWeight = 0;
// 记录活跃请求数最小的Invoker集合中,第一个Invoker的权重值
int firstWeight = 0;
// 活跃请求数最小的集合中,所有Invoker的权重值是否相同
boolean sameWeight = true;
for (int i = 0; i < length; i++) { // 遍历所有Invoker,获取活跃请求数最小的Invoker集合
Invoker<T> invoker = invokers.get(i);
// 获取该Invoker的活跃请求数
int active = RpcStatus.getStatus(invoker.getUrl(), invocation.getMethodName()).getActive();
// 获取该Invoker的权重
int afterWarmup = getWeight(invoker, invocation);
weights[i] = afterWarmup;
// 比较活跃请求数
if (leastActive == -1 || active < leastActive) {
// 当前的Invoker是第一个活跃请求数最小的Invoker,则记录如下信息
leastActive = active; // 重新记录最小的活跃请求数
leastCount = 1; // 重新记录活跃请求数最小的Invoker集合个数
leastIndexes[0] = i; // 重新记录Invoker
totalWeight = afterWarmup; // 重新记录总权重值
firstWeight = afterWarmup; // 该Invoker作为第一个Invoker,记录其权重值
sameWeight = true; // 重新记录是否权重值相等
} else if (active == leastActive) {
// 当前Invoker属于活跃请求数最小的Invoker集合
leastIndexes[leastCount++] = i; // 记录该Invoker的下标
totalWeight += afterWarmup; // 更新总权重
if (sameWeight && afterWarmup != firstWeight) {
sameWeight = false; // 更新权重值是否相等
}
}
}
// 如果只有一个活跃请求数最小的Invoker对象,直接返回即可
if (leastCount == 1) {
return invokers.get(leastIndexes[0]);
}
// 下面按照RandomLoadBalance的逻辑,从活跃请求数最小的Invoker集合中,随机选择一个Invoker对象返回
if (!sameWeight && totalWeight > 0) {
int offsetWeight = ThreadLocalRandom.current().nextInt(totalWeight);
for (int i = 0; i < leastCount; i++) {
int leastIndex = leastIndexes[i];
offsetWeight -= weights[leastIndex];
if (offsetWeight < 0) {
return invokers.get(leastIndex);
}
}
}
return invokers.get(leastIndexes[ThreadLocalRandom.current().nextInt(leastCount)]);
}
ActiveLimitFilter 以及底层的 RpcStatus 记录活跃请求数的具体原理,在前面的[第 30 课时]中我们已经详细分析过了,这里不再重复,如果有不清楚的地方,你可以回顾之前课时相关的内容。
RoundRobinLoadBalance 加权轮询
RoundRobinLoadBalance 实现的是加权轮询负载均衡算法。
轮询指的是将请求轮流分配给每个 Provider。例如,有 A、B、C 三个 Provider 节点,按照普通轮询的方式,我们会将第一个请求分配给 Provider A,将第二个请求分配给 Provider B,第三个请求分配给 Provider C,第四个请求再次分配给 Provider A……如此循环往复。
轮询是一种无状态负载均衡算法,实现简单,适用于集群中所有 Provider 节点性能相近的场景。 但现实情况中就很难保证这一点了,因为很容易出现集群中性能最好和最差的 Provider 节点处理同样流量的情况,这就可能导致性能差的 Provider 节点各方面资源非常紧张,甚至无法及时响应了,但是性能好的 Provider 节点的各方面资源使用还较为空闲。这时我们可以通过加权轮询的方式,降低分配到性能较差的 Provider 节点的流量。
加权之后,分配给每个 Provider 节点的流量比会接近或等于它们的权重比。例如,Provider 节点 A、B、C 权重比为 5:1:1,那么在 7 次请求中,节点 A 将收到 5 次请求,节点 B 会收到 1 次请求,节点 C 则会收到 1 次请求。
在 Dubbo 2.6.4 版本及之前,RoundRobinLoadBalance 的实现存在一些问题,例如,选择 Invoker 的性能问题、负载均衡时不够平滑等。在 Dubbo 2.6.5 版本之后,这些问题都得到了修复,所以这里我们就来介绍最新的 RoundRobinLoadBalance 实现。
每个 Provider 节点有两个权重:一个权重是配置的 weight,该值在负载均衡的过程中不会变化;另一个权重是 currentWeight,该值会在负载均衡的过程中动态调整,初始值为 0。
当有新的请求进来时,
- RoundRobinLoadBalance 会遍历 Invoker 列表,并用对应的 currentWeight 加上其配置的权重。
- 遍历完成后,再找到最大的 currentWeight,将其减去权重总和,然后返回相应的 Invoker 对象。
下面我们通过一个示例说明 RoundRobinLoadBalance 的执行流程,这里我们依旧假设 A、B、C 三个节点的权重比例为 5:1:1。
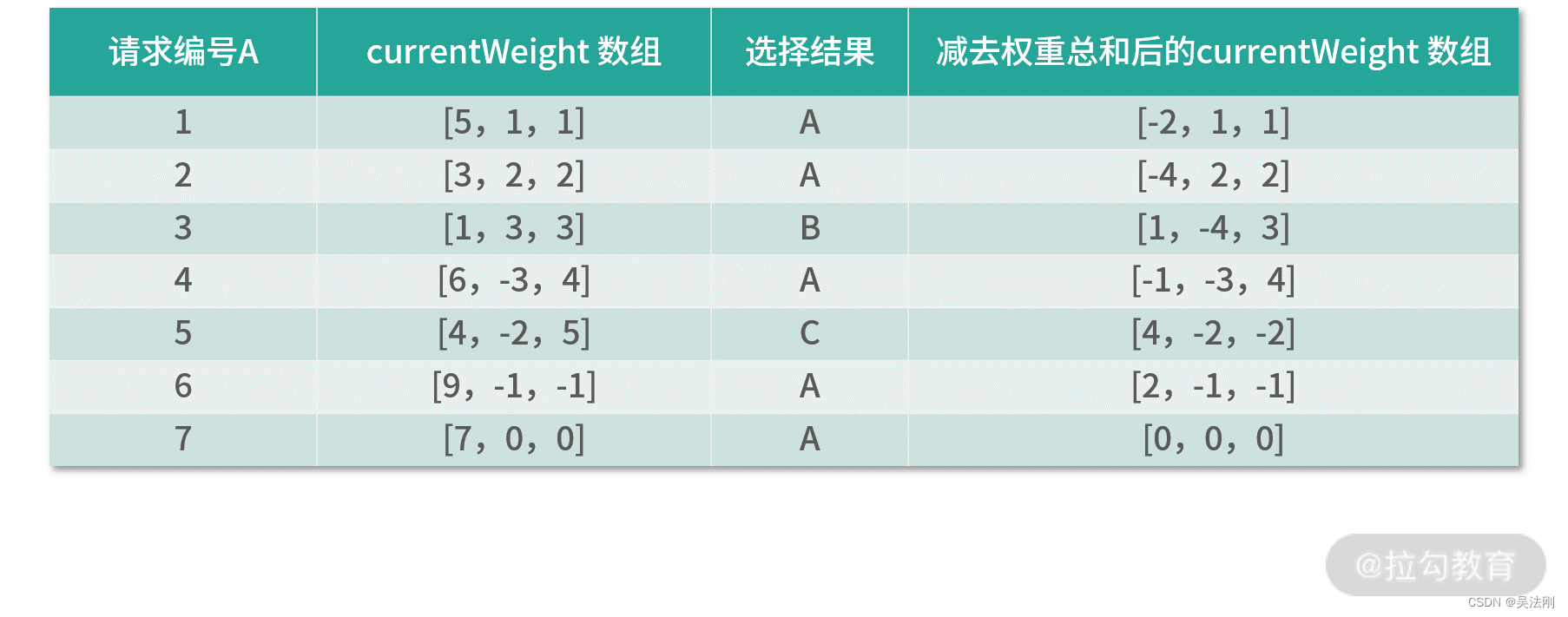
- 处理第一个请求,currentWeight 数组中的权重与配置的 weight 相加,即从 [0, 0, 0] 变为 [5, 1, 1]。接下来,从中选择权重最大的 Invoker 作为结果,即节点 A。最后,将节点 A 的 currentWeight 值减去 totalWeight 值,最终得到 currentWeight 数组为 [-2, 1, 1]。
- 处理第二个请求,currentWeight 数组中的权重与配置的 weight 相加,即从 [-2, 1, 1] 变为 [3, 2, 2]。接下来,从中选择权重最大的 Invoker 作为结果,即节点 A。最后,将节点 A 的 currentWeight 值减去 totalWeight 值,最终得到 currentWeight 数组为 [-4, 2, 2]。
- 处理第三个请求,currentWeight 数组中的权重与配置的 weight 相加,即从 [-4, 2, 2] 变为 [1, 3, 3]。接下来,从中选择权重最大的 Invoker 作为结果,即节点 B。最后,将节点 B 的 currentWeight 值减去 totalWeight 值,最终得到 currentWeight 数组为 [1, -4, 3]。
- 处理第四个请求,currentWeight 数组中的权重与配置的 weight 相加,即从 [1, -4, 3] 变为 [6, -3, 4]。接下来,从中选择权重最大的 Invoker 作为结果,即节点 A。最后,将节点 A 的 currentWeight 值减去 totalWeight 值,最终得到 currentWeight 数组为 [-1, -3, 4]。
- 处理第五个请求,currentWeight 数组中的权重与配置的 weight 相加,即从 [-1, -3, 4] 变为 [4, -2, 5]。接下来,从中选择权重最大的 Invoker 作为结果,即节点 C。最后,将节点 C 的 currentWeight 值减去 totalWeight 值,最终得到 currentWeight 数组为 [4, -2, -2]。
- 处理第六个请求,currentWeight 数组中的权重与配置的 weight 相加,即从 [4, -2, -2] 变为 [9, -1, -1]。接下来,从中选择权重最大的 Invoker 作为结果,即节点 A。最后,将节点 A 的 currentWeight 值减去 totalWeight 值,最终得到 currentWeight 数组为 [2, -1, -1]。
- 处理第七个请求,currentWeight 数组中的权重与配置的 weight 相加,即从 [2, -1, -1] 变为 [7, 0, 0]。接下来,从中选择权重最大的 Invoker 作为结果,即节点 A。最后,将节点 A 的 currentWeight 值减去 totalWeight 值,最终得到 currentWeight 数组为 [0, 0, 0]。
到此为止,一个轮询的周期就结束了。
而在 Dubbo 2.6.4 版本中,上面示例的一次轮询结果是 [A, A, A, A, A, B, C],也就是说前 5 个请求会全部都落到 A 这个节点上。这将会使节点 A 在短时间内接收大量的请求,压力陡增,而节点 B 和节点 C 此时没有收到任何请求,处于完全空闲的状态,这种“瞬间分配不平衡”的情况也就是前面提到的“不平滑问题”。
在 RoundRobinLoadBalance 中,我们为每个 Invoker 对象创建了一个对应的 WeightedRoundRobin 对象,用来记录配置的权重(weight 字段)以及随每次负载均衡算法执行变化的 current 权重(current 字段)。
了解了 WeightedRoundRobin 这个内部类后,我们再来看 RoundRobinLoadBalance.doSelect() 方法的具体实现:
protected <T> Invoker<T> doSelect(List<Invoker<T>> invokers, URL url, Invocation invocation) {
String key = invokers.get(0).getUrl().getServiceKey() + "." + invocation.getMethodName();
// 获取整个Invoker列表对应的WeightedRoundRobin映射表,如果为空,则创建一个新的WeightedRoundRobin映射表
ConcurrentMap<String, WeightedRoundRobin> map = methodWeightMap.computeIfAbsent(key, k -> new ConcurrentHashMap<>());
int totalWeight = 0;
long maxCurrent = Long.MIN_VALUE;
long now = System.currentTimeMillis(); // 获取当前时间
Invoker<T> selectedInvoker = null;
WeightedRoundRobin selectedWRR = null;
for (Invoker<T> invoker : invokers) {
String identifyString = invoker.getUrl().toIdentityString();
int weight = getWeight(invoker, invocation);
// 检测当前Invoker是否有相应的WeightedRoundRobin对象,没有则进行创建
WeightedRoundRobin weightedRoundRobin = map.computeIfAbsent(identifyString, k -> {
WeightedRoundRobin wrr = new WeightedRoundRobin();
wrr.setWeight(weight);
return wrr;
});
// 检测Invoker权重是否发生了变化,若发生变化,则更新WeightedRoundRobin的weight字段
if (weight != weightedRoundRobin.getWeight()) {
weightedRoundRobin.setWeight(weight);
}
// 让currentWeight加上配置的Weight
long cur = weightedRoundRobin.increaseCurrent();
// 设置lastUpdate字段
weightedRoundRobin.setLastUpdate(now);
// 寻找具有最大currentWeight的Invoker,以及Invoker对应的WeightedRoundRobin
if (cur > maxCurrent) {
maxCurrent = cur;
selectedInvoker = invoker;
selectedWRR = weightedRoundRobin;
}
totalWeight += weight; // 计算权重总和
}
if (invokers.size() != map.size()) {
map.entrySet().removeIf(item -> now - item.getValue().getLastUpdate() > RECYCLE_PERIOD);
}
if (selectedInvoker != null) {
// 用currentWeight减去totalWeight
selectedWRR.sel(totalWeight);
// 返回选中的Invoker对象
return selectedInvoker;
}
return invokers.get(0);
}
ShortestResponseLoadBalance 最短响应时间
ShortestResponseLoadBalance 是Dubbo 2.7 版本之后新增加的一个 LoadBalance 实现类。它实现了最短响应时间的负载均衡算法,也就是从多个 Provider 节点中选出调用成功的且响应时间最短的 Provider 节点,不过满足该条件的 Provider 节点可能有多个,所以还要再使用随机算法进行一次选择,得到最终要调用的 Provider 节点。
了解了 ShortestResponseLoadBalance 的核心原理之后,我们一起来看 ShortestResponseLoadBalance.doSelect() 方法的核心实现,如下所示:
protected <T> Invoker<T> doSelect(List<Invoker<T>> invokers, URL url, Invocation invocation) {
// 记录Invoker集合的数量
int length = invokers.size();
// 用于记录所有Invoker集合中最短响应时间
long shortestResponse = Long.MAX_VALUE;
// 具有相同最短响应时间的Invoker个数
int shortestCount = 0;
// 存放所有最短响应时间的Invoker的下标
int[] shortestIndexes = new int[length];
// 存储每个Invoker的权重
int[] weights = new int[length];
// 存储权重总和
int totalWeight = 0;
// 记录第一个Invoker对象的权重
int firstWeight = 0;
// 最短响应时间Invoker集合中的Invoker权重是否相同
boolean sameWeight = true;
for (int i = 0; i < length; i++) {
Invoker<T> invoker = invokers.get(i);
RpcStatus rpcStatus = RpcStatus.getStatus(invoker.getUrl(), invocation.getMethodName());
// 获取调用成功的平均时间,具体计算方式是:调用成功的请求数总数对应的总耗时 / 调用成功的请求数总数 = 成功调用的平均时间
// RpcStatus 的内容在前面课时已经介绍过了,这里不再重复
long succeededAverageElapsed = rpcStatus.getSucceededAverageElapsed();
// 获取的是该Provider当前的活跃请求数,也就是当前正在处理的请求数
int active = rpcStatus.getActive();
// 计算一个处理新请求的预估值,也就是如果当前请求发给这个Provider,大概耗时多久处理完成
long estimateResponse = succeededAverageElapsed * active;
// 计算该Invoker的权重(主要是处理预热)
int afterWarmup = getWeight(invoker, invocation);
weights[i] = afterWarmup;
if (estimateResponse < shortestResponse) {
// 第一次找到Invoker集合中最短响应耗时的Invoker对象,记录其相关信息
shortestResponse = estimateResponse;
shortestCount = 1;
shortestIndexes[0] = i;
totalWeight = afterWarmup;
firstWeight = afterWarmup;
sameWeight = true;
} else if (estimateResponse == shortestResponse) {
// 出现多个耗时最短的Invoker对象
shortestIndexes[shortestCount++] = i;
totalWeight += afterWarmup;
if (sameWeight && i > 0
&& afterWarmup != firstWeight) {
sameWeight = false;
}
}
}
if (shortestCount == 1) {
return invokers.get(shortestIndexes[0]);
}
// 如果耗时最短的所有Invoker对象的权重不相同,则通过加权随机负载均衡的方式选择一个Invoker返回
if (!sameWeight && totalWeight > 0) {
int offsetWeight = ThreadLocalRandom.current().nextInt(totalWeight);
for (int i = 0; i < shortestCount; i++) {
int shortestIndex = shortestIndexes[i];
offsetWeight -= weights[shortestIndex];
if (offsetWeight < 0) {
return invokers.get(shortestIndex);
}
}
}
// 如果耗时最短的所有Invoker对象的权重相同,则随机返回一个
return invokers.get(shortestIndexes[ThreadLocalRandom.current().nextInt(shortestCount)]);
}
总结
我们紧接上一课时介绍了 LoadBalance 接口的剩余三个实现。
我们首先介绍了
- LeastActiveLoadBalance 实现,它使用最小活跃数负载均衡算法,选择当前请求最少的 Provider 节点处理最新的请求;
- 接下来介绍了 RoundRobinLoadBalance 实现,它使用加权轮询负载均衡算法,弥补了单纯的轮询负载均衡算法导致的问题,同时随着 Dubbo 版本的升级,也将其自身不够平滑的问题优化掉了;
- 最后介绍了 ShortestResponseLoadBalance 实现,它会从响应时间最短的 Provider 节点中选择一个 Provider 节点来处理新请求。