论文:YOLOR-You Only Learn One Representation: Unifified Network for Multiple Tasks
作者:Chien-Yao Wang, I-Hau Yeh, Hong-Yuan Mark Liao
链接:https://arxiv.org/abs/2105.04206
代码:https://github.com/WongKinYiu/yolor
YOLO系列算法解读:
- YOLOv1通俗易懂版解读
- SSD算法解读
- YOLOv2算法解读
- YOLOv3算法解读
- YOLOv4算法解读
- YOLOv5算法解读
- YOLOR算法解读
- YOLOX算法解读
PP-YOLO系列算法解读:
- PP-YOLO算法解读
- PP-YOLOv2算法解读
- PP-PicoDet算法解读
- PP-YOLOE算法解读
- PP-YOLOE-R算法解读
文章目录
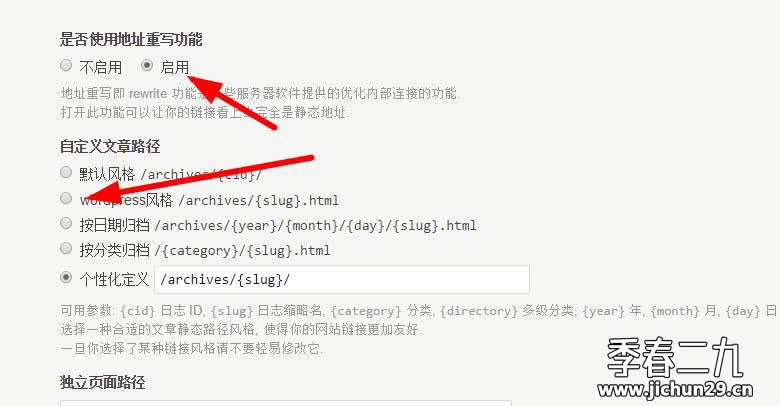
- 1、算法概述
- 2、YOLOR细节
- 2.1 隐性知识如何工作
- 2.2 统一网络的隐性知识
- 3、实验结果
- 3.1 实验设置
- 3.2 FPN特征对齐消融实验
- 3.3 目标检测预测细化消融实验
- 3.4 多任务规范表征消融实验
- 3.5 隐式知识建模不同算子比较
- 3.6 隐式知识提升目标检测
1、算法概述
人类可以通过视觉、听觉、触觉以及过去的经验来“理解”世界。经验可以通过正常学习(作者称之为显性知识),也可以通过潜意识(作者称之为隐性知识)来学习。即对于一段数据,人类可以从显性知识中直接学习到它,也可以从大脑中以前的经验(潜意识)中推导分析它。然而,经过训练的卷积神经网络(CNN)模型通常只能实现一个目标,即直接从数据中学习。一般来说,从训练过的CNN中提取出来的特征通常对其他类型的问题适应性较差。造成上述问题的主要原因是我们只从神经元中提取特征,而没有利用CNN中丰富的隐性知识。在真实人脑运行时,上述隐性知识可以有效地辅助大脑完成各种任务,如下图所示:

隐性知识是指在潜意识中学习到的知识。然而,对于隐性学习如何运作以及如何获得隐性知识,目前还没有一个系统的定义。在神经网络的一般定义中,从浅层获得的特征通常称为显性知识,从深层获得的特征称为隐性知识。论文中将与观测数据(网络输入)直接对应的知识称为显性知识。对于模型中隐含的与观测无关的知识,我们称之为隐性知识。
作者提出了一个统一的网络来整合隐性知识和显性知识,使学习模型包含一个通用的表示,这个通用的表示使得子表示适合于各种任务。图2©说明了该统一网络体系结构。本文构建统一网络的方法是将压缩感知和深度学习结合起来。
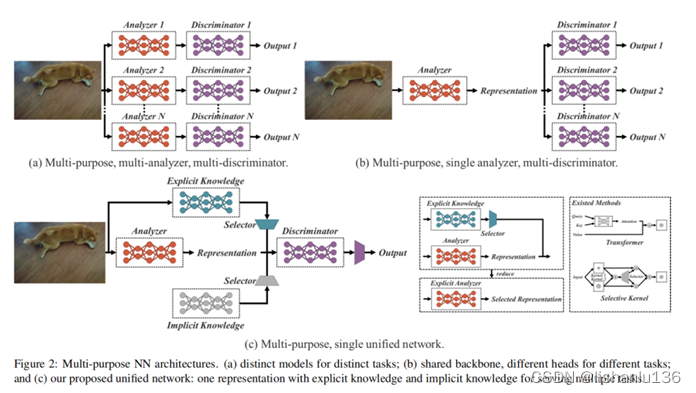
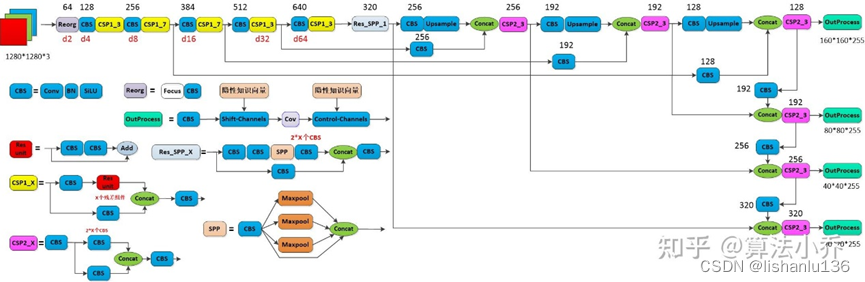
借鉴知乎@算法小乔画的YOLOR网络结构图,可以看到作者主要在输出层OutProcess中增加了两个隐性知识向量shift-Channels和Control-Channels,这里的隐性知识向量,就是单独初始化一个向量shape为[1,C,1,1], 其中C与前一层的输出outchannels一致,有点类似于通道注意力的意思,然后在训练过程中,参数随着训练优化更新。shift-Channels将隐性知识向量与前一层的特征通过相加Add的方式进行融合;Control-Channels将隐性知识向量与前一层的特征通过相乘Mul的方式进行融合。
2、YOLOR细节
2.1 隐性知识如何工作
本文的主要目的是建立一个能够有效训练隐性知识的统一网络,因此在后续的研究中,我们首先将重点放在如何训练隐性知识和快速推理上。由于隐性表示zi与观测无关,我们可以把它看作一组常数张量Z={z1,z2,⋯,zk}。在本节中,我们将介绍作为常量张量的隐性知识如何应用于各种任务。
- 多维空间降维
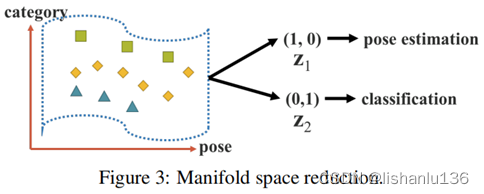
一个好的表征应该能够在它所属的多维空间中找到一个合适的投影,并有助于后续目标任务的顺利完成。例如,如图3所示,如果目标类别可以通过投影空间中的超平面成功分类,那将是最好的结果。在上面的例子中,我们可以利用投影向量的内积和隐式表示来达到降低流形空间维数的目的,有效地完成各种任务。 - 内核空间对齐
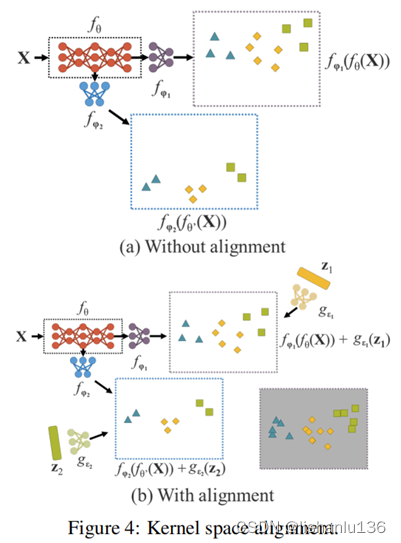
在多任务和多头神经网络中,核空间失调是一个常见的问题,图4(a)举例说明了多任务和多头神经网络中的核空间失调。为了解决这个问题,我们可以对输出特征和隐式表示进行加法和乘法,这样就可以对核空间进行平移、旋转和缩放,以对齐神经网络的每个输出核空间,如图4(b)所示。上述操作模式可广泛应用于不同领域,如特征金字塔网络(FPN)中大目标与小目标的特征对齐、利用知识蒸馏来对齐大模型与小模型、零样本迁移等问题。 - 更多的功能
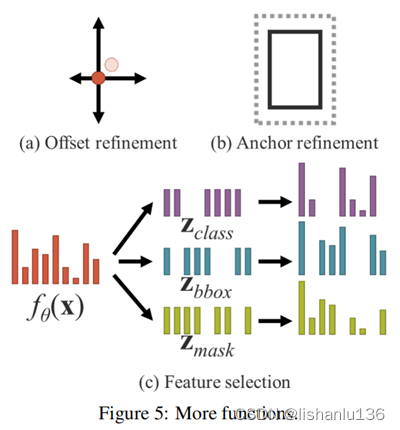
除了可以应用于不同任务的功能外,隐性知识还可以扩展为更多的功能。如图5所示,通过引入加法,可以使神经网络预测中心坐标的偏移量。还可以引入乘法来自动搜索锚点的超参数集,这是基于anchor的目标检测经常需要的。此外,点乘法和串联可分别用于执行多任务特征选择和为后续计算设置前提条件。
2.2 统一网络的隐性知识
在本节中,我们将比较传统网络和提出的统一网络的目标函数,并解释为什么引入隐性知识对训练多用途网络很重要。同时,我们还将详细阐述本文提出的方法。
- 卷积网络
对于卷积网络的目标函数,如下:
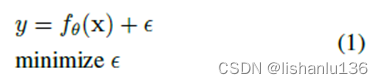
其中x是观测量,即网络的输入,θ代表卷积网络的参数集,fθ(.)代表卷积网络运行;卷积网络训练,即最小化误差ε,使输入x经过卷积网络尽可能贴近真实数据y。
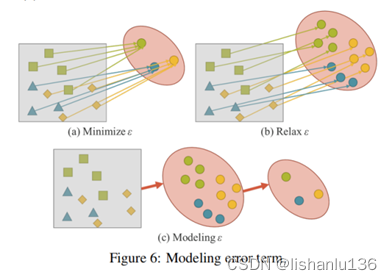
如图6(a)所示,我们需要对同一标注有不同的样本,以获取数据的丰富性。换句话说,我们期望得到的解空间仅对当前任务ti是有区别的,而对各种除ti以外的潜在任务是不变的,其中T={t1,⋯,tn}。
对于一般用途的神经网络,我们希望所得到的表示能服务于T。因此,我们需要放松ε,以便在流形空间上同时找到每个任务的解,如图6(b)所示。然而,上述要求使得我们不可能用简单的数学方法,如一个one-hot向量的最大值或欧氏距离的阈值来求解ti。为了解决这个问题,我们必须对错误项ε进行建模,以便为不同的任务找到解决方案,如图6( c)所示。 - 统一网络
为了训练所提出的统一网络,我们将显性知识和隐性知识结合起来对误差项进行建模,然后用它来指导多用途网络的训练过程。相应的训练公式如下:
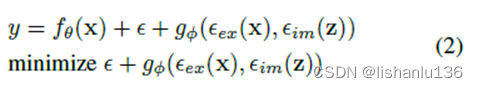
其中ϵex和ϵim是分别对观测值x和潜在编码z的显式误差和隐式误差进行建模的运算。gϕ这里是一个特定于任务的操作,用于从显性知识和隐性知识中组合或选择信息。
已有的将显性知识整合到fθ(.)的方法,可以将(2)改写为(3)。
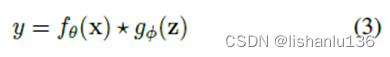
其中*表示了f和g之间的可能操作。可能是加法、乘法或者串联。
如果我们把误差项的推导过程扩展到处理多个任务,我们可以得到如下公式:
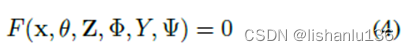
其中,Z={z1,z2,⋯,zT}是不同任务的隐式编码,Φ是用于从Z生成隐性知识表示的参数,Ψ用于从显式表示和隐式表示的不同组合中计算最终输出参数。
对于不同的任务 ,我们可以使用下面的公式获得预测:
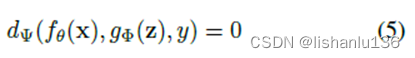
对于所有的任务我们都从一个统一表示fθ(x),完成特定任务的隐式表示gϕ(z)开始,最后用任务识别器dΨ完成不同的任务。 - 隐性知识的建模
隐性知识可用如下方式建模:
对于Vector/Matrix/Tensor,使用向量z直接作为隐性知识的先验,直接作为隐式表示。(z)
对于Neural Network,使用向量z作为隐性知识的先验,然后使用权值矩阵进行线性组合或非线性化,从而成为隐式表示。(Wz)
对于Matrix Factorization,使用多个向量作为隐性知识的先验,这些隐性先验由Z和系数c形成隐式表示。(ZTc) - Training
如果模型一开始没有任何先验的隐性知识,也就是说,它不会对显式表征fθ(x)产生任何影响。那我们就直接初始化一个向量z即可,对于结合操作是相加或串连的,z服从N(0,σ),对于结合操作是乘法的,z服从N(1,σ),这里σ初始化的时候都是接近于0的。z和Φ都是在训练过程中遵循梯度反向传播算法进行优化的。 - Inference
因为隐性知识与观测量x无关,所以无论gϕ多么复杂,在推理过程之前都可以被简化为一组常数张量。
3、实验结果
3.1 实验设置
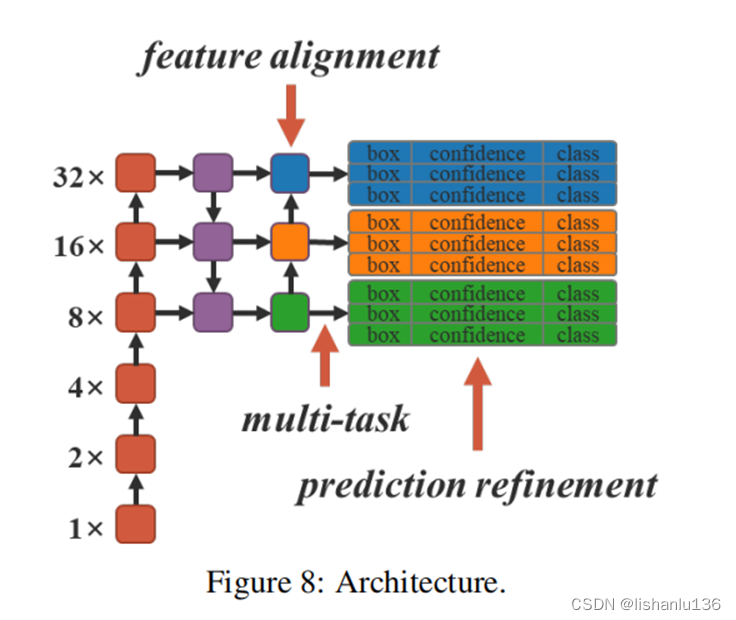
本文通过FPN中的feature alignment(特征对齐)、目标检测中的prediction refinement(预测细化)、单模型中的multi-task learning(多任务学习)来应用implicit knowledge(隐式知识)(注:本文的多任务学习指特征嵌入、多标签图像分类和目标检测)。使用YOLOV4-CSP作为baseline model,隐式知识添加位置如上图所示,所有训练超参数与Scaled-YOLOv4一致。
3.2 FPN特征对齐消融实验
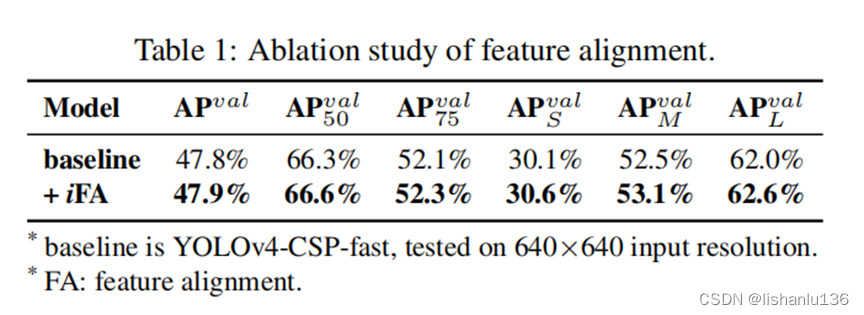
使用简单的向量隐式表征和加法算子,在FPN的每一个特征映射层添加隐式知识进行特征对齐,各个指标均获得了提升,如表1所示。
3.3 目标检测预测细化消融实验
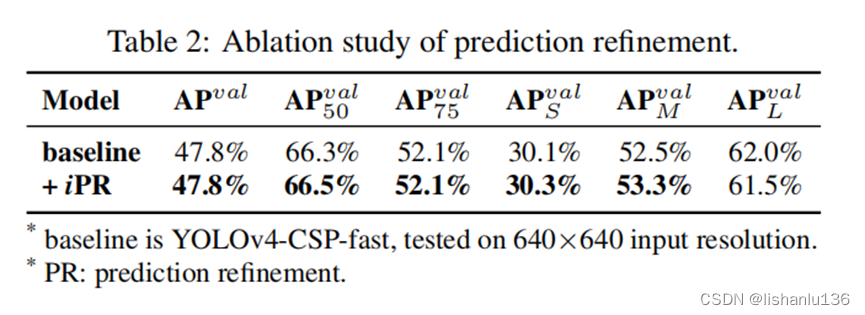
使用简单的向量隐式表征和加法算子,在YOLO的每一个输出层添加隐式知识进行预测细化,大部分指标都获得到了一定的增益,如表2所示。
3.4 多任务规范表征消融实验
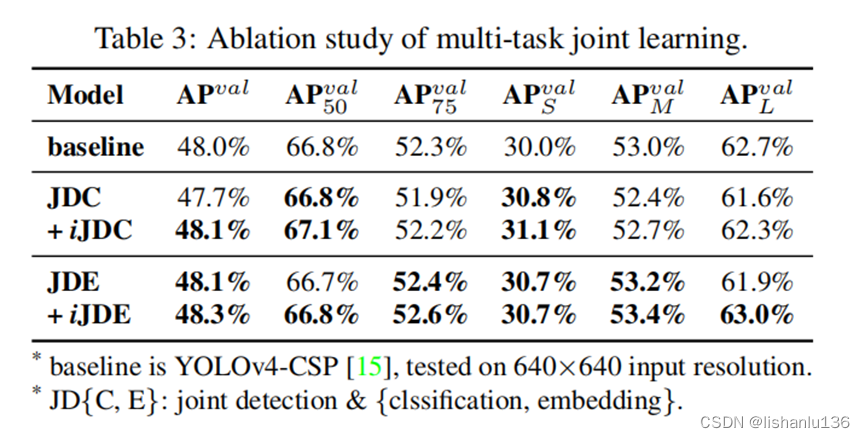
当需要同时训练一个被多个任务共享的模型时,由于损失函数的联合优化过程是必须执行的,因此在执行过程中往往会出现多方相互拉动的情况,这种情况将导致最终的整体性能比单独训练多个模型然后集成它们要差。为了解决这个问题,作者提出为训练多任务训练一个规范的表征,通过给每个任务分支引入隐式表征增强表征能力,表3展示了使用简单的向量隐式表征和加法算子进行不同联合训练方式的结果,(检测和特征嵌入联合训练,引入加法隐式表征)取得了最好的对比结果。
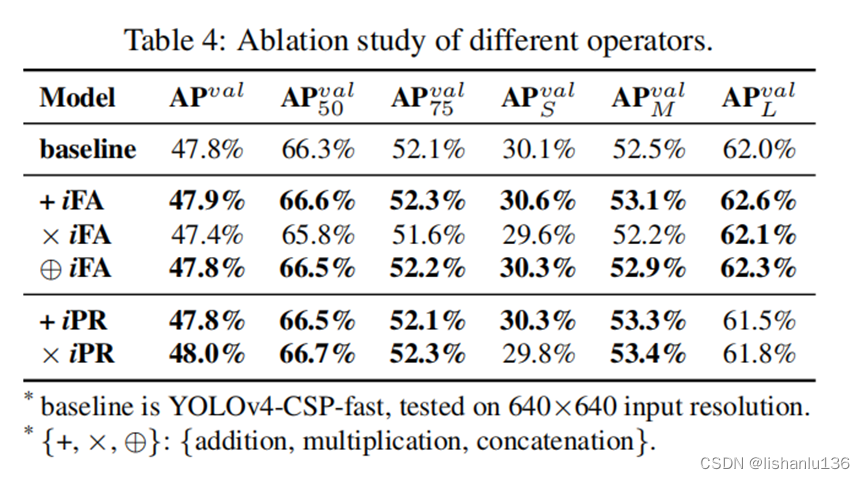
3.5 隐式知识建模不同算子比较

表4显示了图10中不同算子融合显式表征与隐式表征的结果。
在特征对齐实验中,相加与串联(concat)操作能够提升性能表现,相乘有所下降。特征对齐的实验结果完全符合其物理特性,因为它必须处理全局偏移和所有单个簇的缩放。
在预测细化实验中,由于concat会增加输出维度,所以只比较相加与相乘的效果,在这里相乘的效果更好。这是由于中心偏移在执行预测时使用加法解码,而锚框尺度使用乘法解码,而中心坐标是以网格为界的,影响较小,但人工设置的锚框具有较大的优化空间,因此改进更为显著。
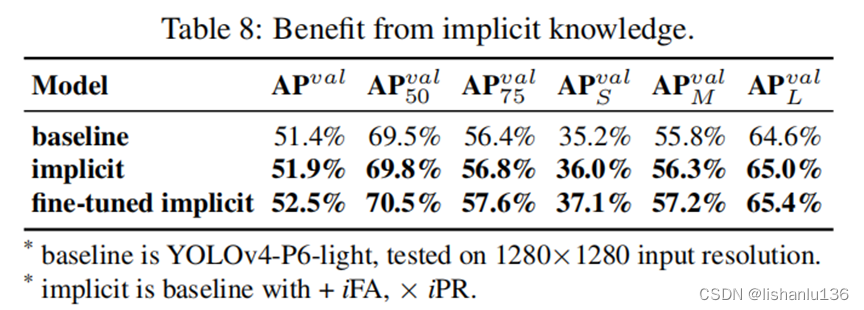
3.6 隐式知识提升目标检测
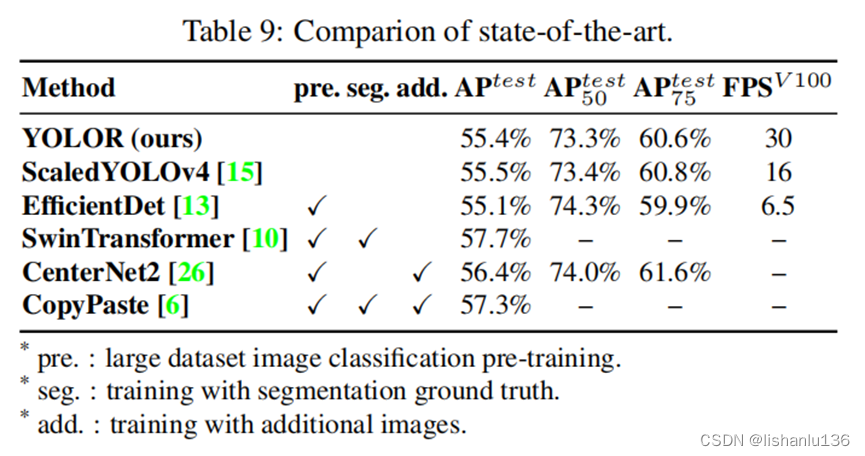
按照Scaled-YOLOv4训练过程,先从头训练 300 epochs,然后微调150 epochs,表8展示了目标检测中引入隐式知识的优势。表9与SOTA方法进行了比较,值得注意的是YOLOR并没有增加额外的数据和标注做训练,只通过引入隐式知识的统一网络,YOLOR不仅达到了足可以和SOTA方法比拟的结果,而且速度非常快。