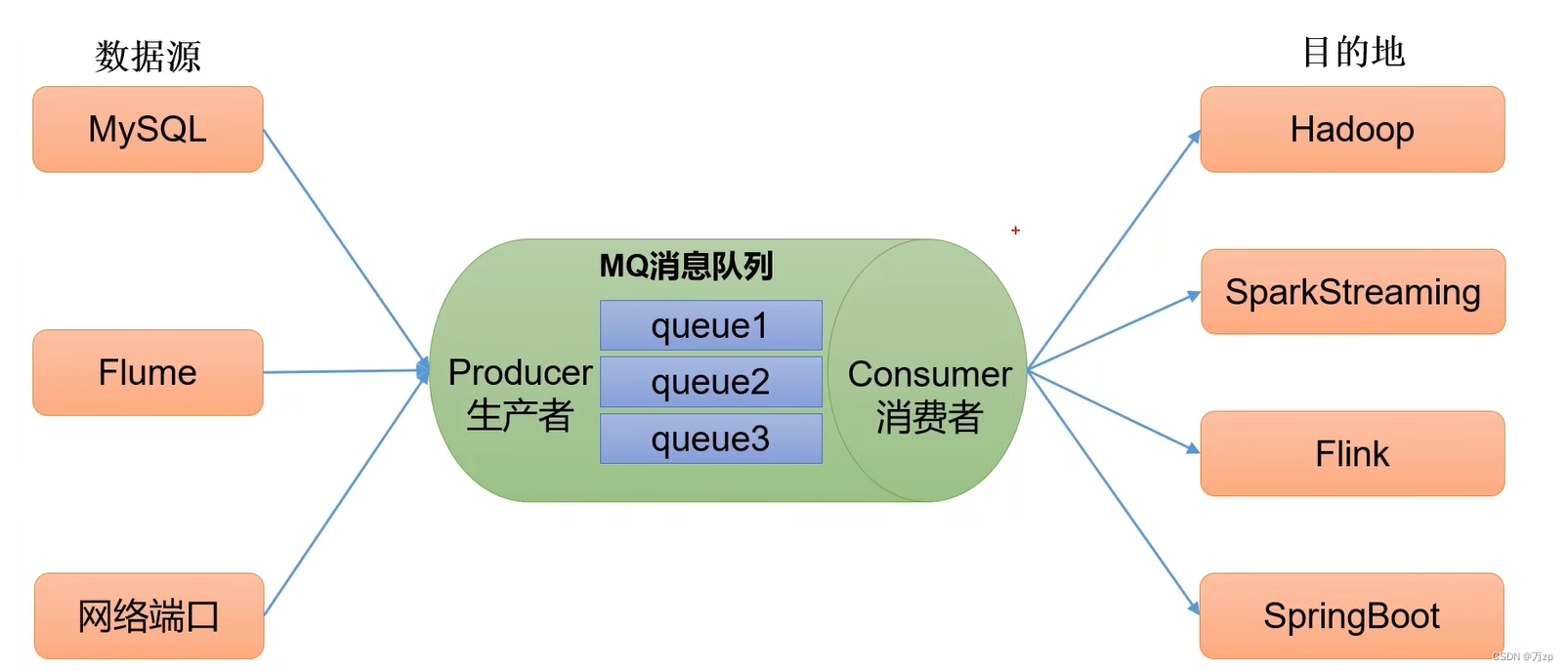
一、service的概念
1、什么是service
- 在Kubernetes中,pod是应用程序的载体,当我们需要访问这个应用时,可以通过Pod的IP进行访问,但是这里有两个问题:
- 1、Pod的IP地址不固定,一旦Pod异常退出、节点故障,则会造成Pod发生重建,一旦发生重建客户端则会访问失败;
- 2、Pod如果扩展多份,会造成客户端无法有效使用新增Pod,如果Pod进行缩容又会造成客户端访问错误;
为了解决以上问题,kubernetes引入了service负载均衡资源,Service为动态的一组Pod提供一个固定的访问入口;service资源基于标签选择器把筛选出的一组Pod对象定义成一个逻辑组合,而后Service对外提供自己的IP和端口。
当客户端请求Service的IP和端口时,Service将请求调度给标签所匹配的所有Pod,Service向客户端隐藏了真实处理请求的Pod资源,使得客户端的请求看上去是由Service直接处理并进行响应。
Service对象的IP地址(可称为ClusterIP或ServiceIP)是虚拟IP地址,由Kubernetes系统在Service对象创建时在专有网络(ServiceNetwork)地址中自动分配或由用户手动指定。其次Service是基于端口过滤,并根据事先定义好的规则将请求转发至其后端Pod对应的端口上,因此这种代理机制也称为“端口代理"或“四层代理”,工作在TCP/IP协议栈的传输层;
2、service的作用
- 暴露流量:让用户可以通过ServiceIP+ServicePort访问对应后端的Pod应用;
- 负载均衡:提供基于4层的TCP/IP负载均衡,并不提供HTTP/HTTPS等负载均衡;
- 服务发现:当发现新增Pod则自动加入至Service的后端,如发现Pod异常则自动剔除Service后端;
3、service的工作逻辑
Service持续监视APIServer,监视Service标签选择器所匹配的后端Pod,并实时跟踪这些Pod对象的变动情况,例如IP地址发生变化、或Pod对象新增与减少
不过Service并不直接与Pod建立关联关系,它们之间还有一个中间层Endpoints,Endpoints对象是一个由IP地址和端口组成的列表,这些IP地址和端口则来自于Service标签选择器所匹配到的Pod,默认情况下,创建Service资源时,其关联的Endpoints对象会被自动创建。
4、service的具体实现
在Kubernetes中,Service只是抽象的一个概念,真正起作用实现负载均衡规则的其实是Kube-Proxy这个进程。它在每个节点上都需要运行一个Kube-Proxy,用来完成负载均衡规则的创建。
- 1、创建Service资源后,会分配一个随机的ServiceIP,返回给用户,然后写入etcd;
- 2、endpoints controller负责生成和维护所有endpoints,它会监听Service和pod的状态,当 pod处于running 且准备就绪时,endpoints controller会将 podip 更新到对应Service的 endpoints 对象中,然后写入Etcd;
- 3、kube-proxy通过API-Server监听Service、Endpoints的资源变动,-旦Service或Endpoints资源发生变化,Kube-Proxy会将最新的信息转换为对应的Iptables、IPVS访问规则,而后在本地主机上执行。
- 4、当客户端想要访问Service的时候,其实访问的就是本地节点上的iptables、IPVS规则,由它们路由到对应节点;
5、service的实现主要协调主件
- Service:用户通过kubectl命令向apiServer发送创建Service的请求,APIServer收到后存入Etcd;
- Endpoints:获取Service所匹配的Pod地址,而后将信息写入与Service同名的endpoints资源中;
- Kube-Proxy:获取Service和Endpoints资源的变动,而后生成Iptables、IPVS规则,在本机执行;
- Iptables:当用户请求serviceIP时,使用iptables的DNAT技术将ServiceIP的请求调度至endpoint保存ip列表;
6、Kube-Proxy代理模式
6.1、 userSpace(目前这种规则已经被废弃)
userspace模式下,kube-proxy为ServiceIP创建一个监听端口,当用户向ServiceIP发送请求,
- 1、首先请求会被Iptables规则拦截,然后重定向到Kube-Proxy对应的端口;
- 2、然后Kube-Proxy根据调度算法选择挑选一个Pod,将请求调度到该Pod上;
总结:Pod请求ServiceIP时,会被Iptables将请求拦截给用户空间的Kube-Proxy,然后再经过内核空间路由到对应的Pod;
6.2 、Iptables模式
iptables模式下,kube-proxy为Service后端的所有Pod创建对应的iptables规则,当用户向ServiceIP发送请求;
- 1、首先Iptables会拦截用户请求:
- 2、然后直接将请求调度到后端的Pod;
总结:Pod请求ServiceIP时,Iptables将请求拦截并且直接完成调度,然后路由到对应的Pod,所以效率比userspace高;
问题:-个Service会创建出大量的规则,且不支持更高级的调度算法当Pod不可用也无法重试;
6.3、 IPVS
ipvs模式和iptables类似,kube-proxy为Service后端所有的Pod创建对应的IPVS规则,一个Service只会生成一条规则,所以规模较大的场景下,应该使用IPVS模式。其次IPVS更多更高级的调度算法。
二、service的资源类型
无论使用那一种代理模型Service资源都可以其工作逻辑分为ClusterIP, NodePort,toadBalance、ExternalName这四种类型。
1、clusterIP
ClusterIP:通过集群的内部 IP 暴露服务,选择ServiceIP只能够在集群内部访问。 这也是默认的ServiceType
2、Nodeport
NodePort:NodePort类型是对ClusterIP类型Service资源的扩展。它通过每个节点上的IP和端口接入集群外部流量,并分发给后端的Pod处理和响应。因此通过<节点IP>:<节点端口>,可以从集群外部访问服务。
3、LoadBalance
LoadBalancer:这类Service依赖云厂商,需要通过云厂商调用API接口创建软件负载均衡将服务暴露到集群外部。当创建LoadBalance类型的Service对象时,它会在集群上自动创建一个NodePort类型的Service。集群外部的请求流量会先路由至该负载均衡,并由该负载均衡调度至各个节点的NodePort。
4、ExternalName
ExternalName:此类型不是用来定义如何访问集群内服务的,而是把集群外部的某些服务以DNSCANME方式映射到集群内,从而让集群内的Pod资源能够访问外部服务的一种实现方式。
总结:
service资源类型:
ClusterIP: ServiceIP,为集群内部提供一个虚拟IP,实现负载均衡功能;
NodePort: 将集群外部的请求引入到集群内部; 为所有的节点开启对应的端口; 当用户请求节点IP+port会将请求调度给对应的Pod;
LoadBalance: 需要依赖云厂商;自动创建外部的负载均衡,负载均衡将流量调度给NodePort开放的端口;自动创建NodePort;就会创建ClusterIP;
externalName: 将外部的服务引入到集群内部;Pod请求一个域名就可以访问到外部的服务;
三、Service的实践-clusterIP
1、 clusterIP
1、创建deployment
在这里插入代码片
apiVersion: apps/v1
kind: Deployment
metadata:
name: daemon-app
spec:
replicas: 3
selector:
matchLabels:
app: web
template:
metadata:
labels:
app: web
spec:
containers:
- name: webservice
#image: 192.168.1.20/k8s-test/daemon-app:v1.0
image: registry.cn-hangzhou.aliyuncs.com/mokeyking/k8s-oldxu:daemon-app-v1
imagePullPolicy: IfNotPresent
ports:
- containerPort: 80
2、创建svc
apiVersion: v1
kind: Service
metadata:
name: daemon-svc
spec:
type: ClusterIP
selector:
app: web
ports:
- name: http
port: 8888
targetPort: 80
3、验证查看
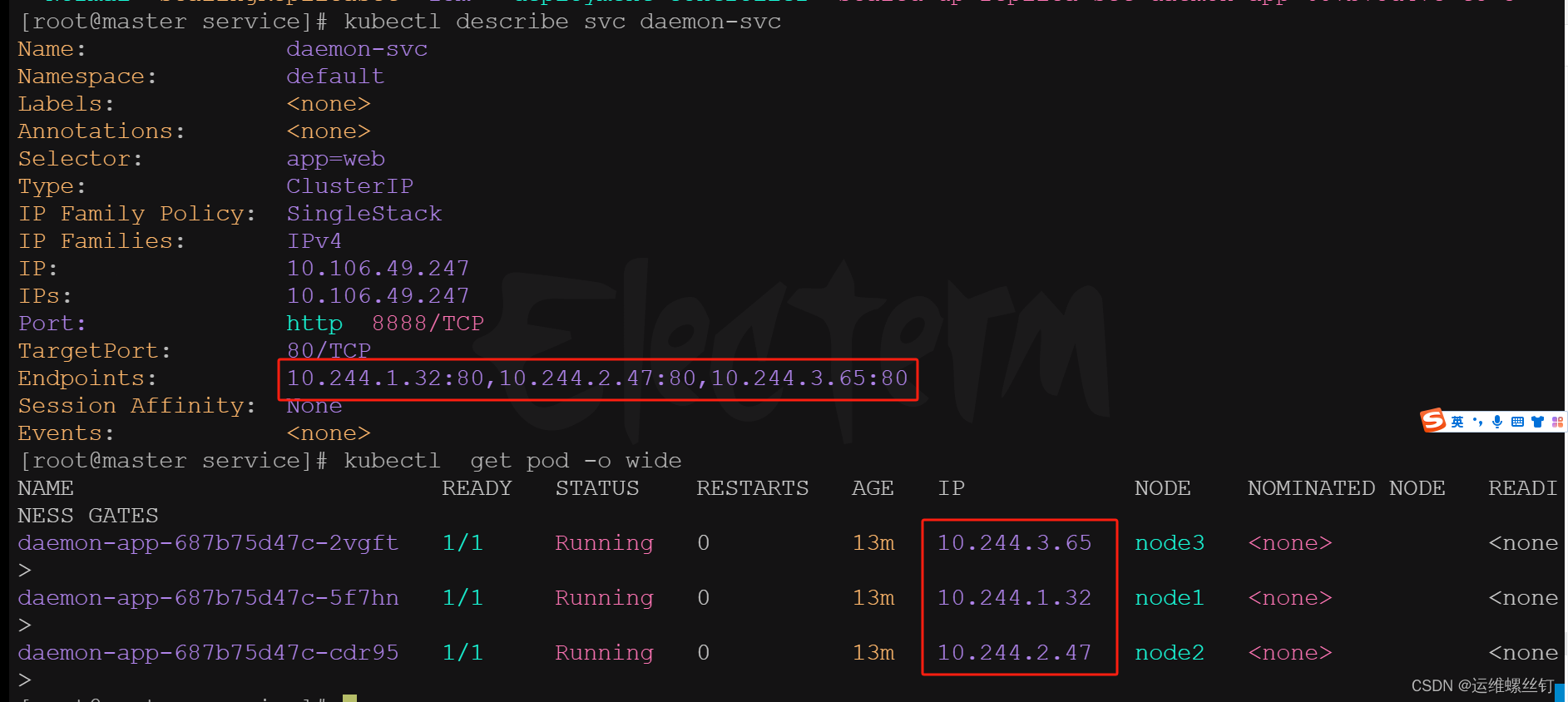
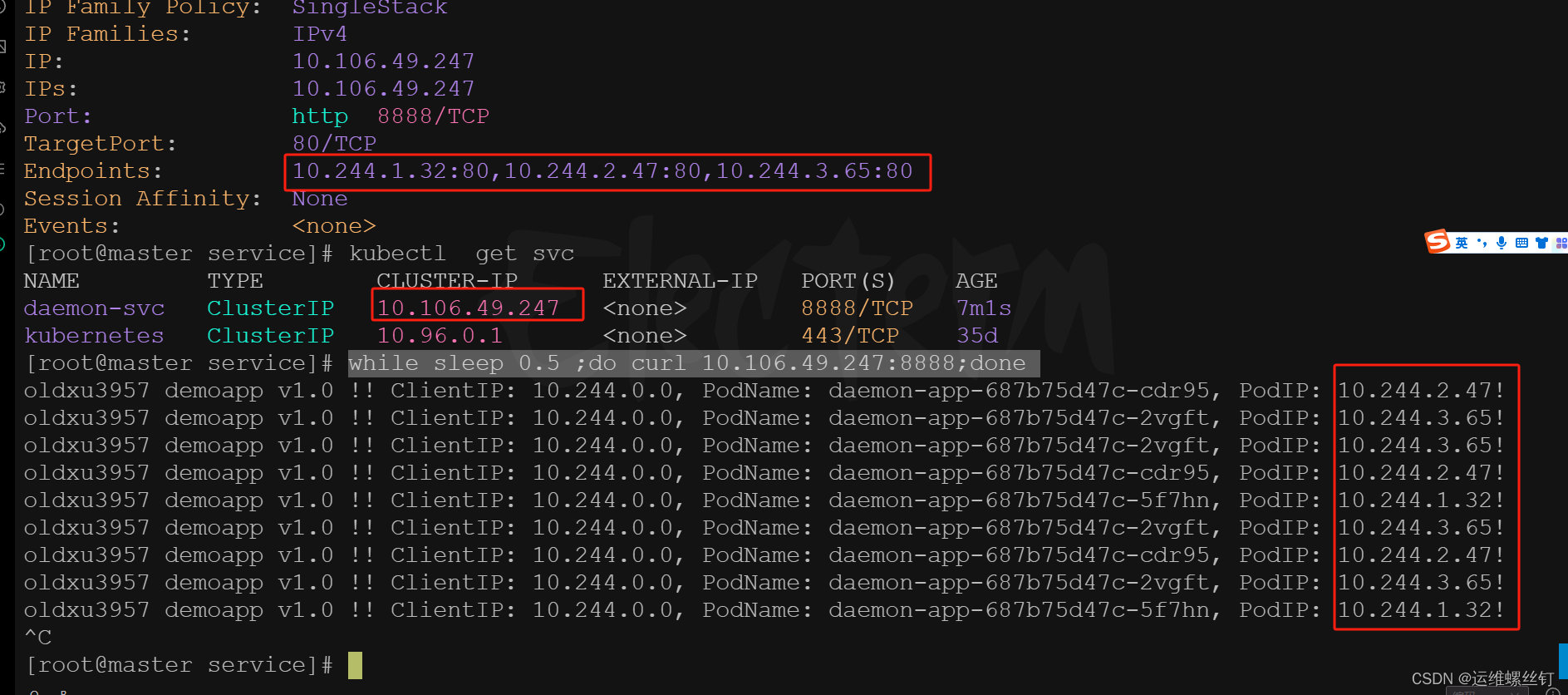
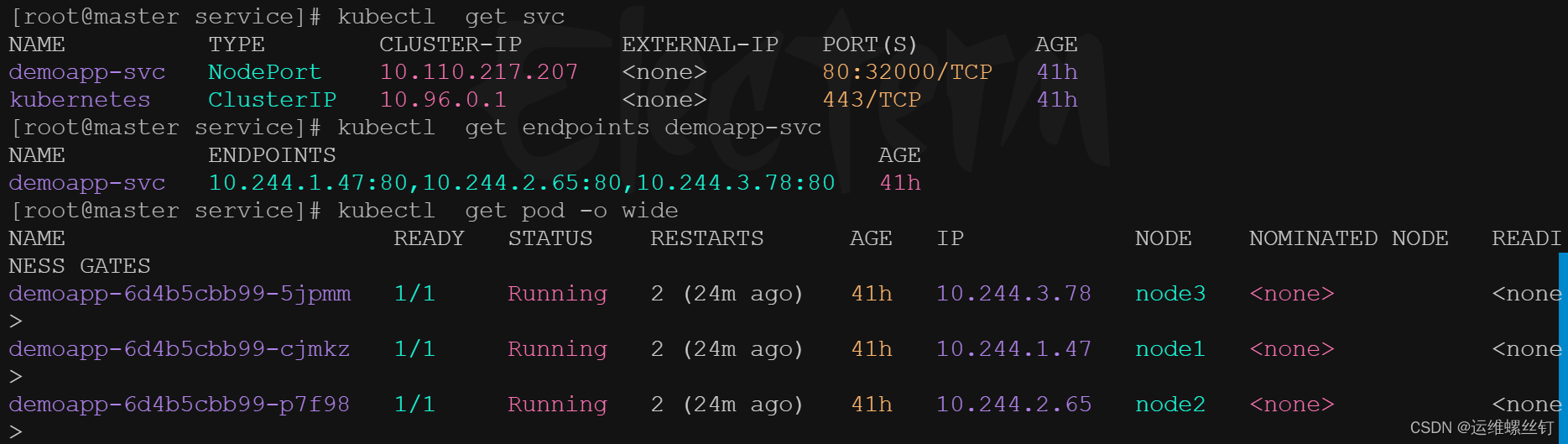
查看endpoints与pod的绑定
kubectl get endpoints daemon-svc
kubectl get pod -o wide
kubectl describe svc daemon-svc

4、在集群内进行访问测试验证
访问service默认,默认的是采用iptables的转发策略,如果pod的新增会自动加入service中,删除会自动在service进行清除
while sleep 0.5 ;do curl 10.106.49.247:8888;done
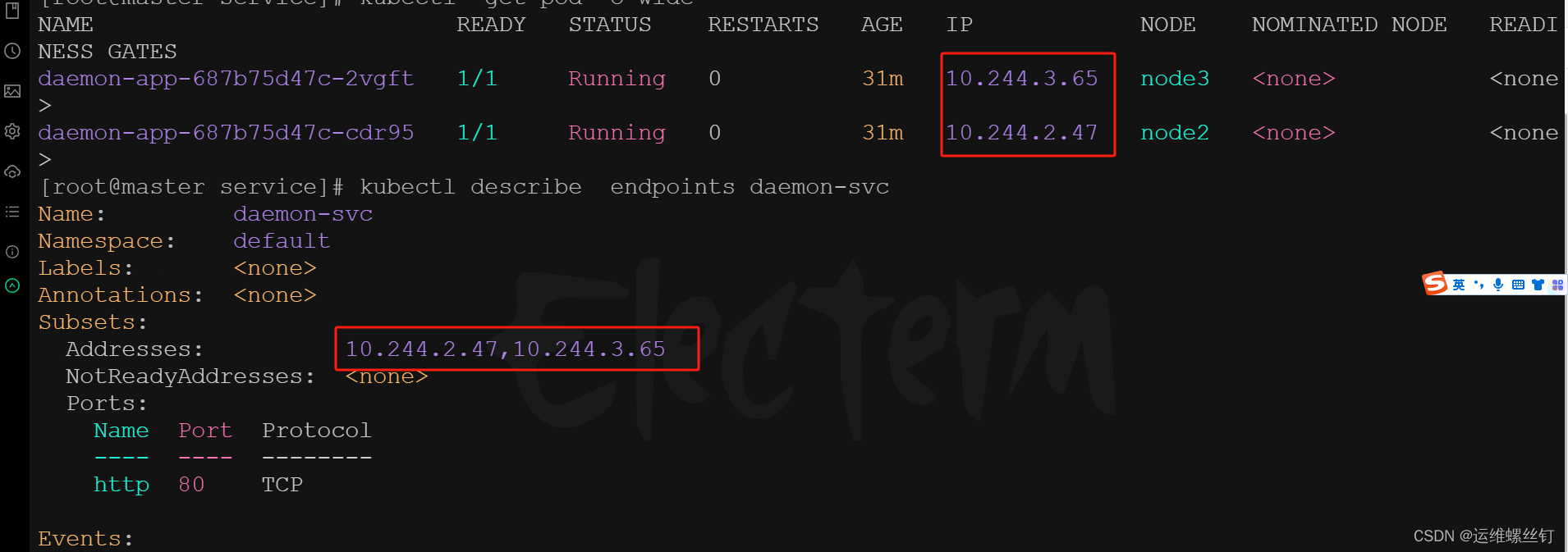
5、测试自动加入service和退出service
只需要修改replicaset副本数量
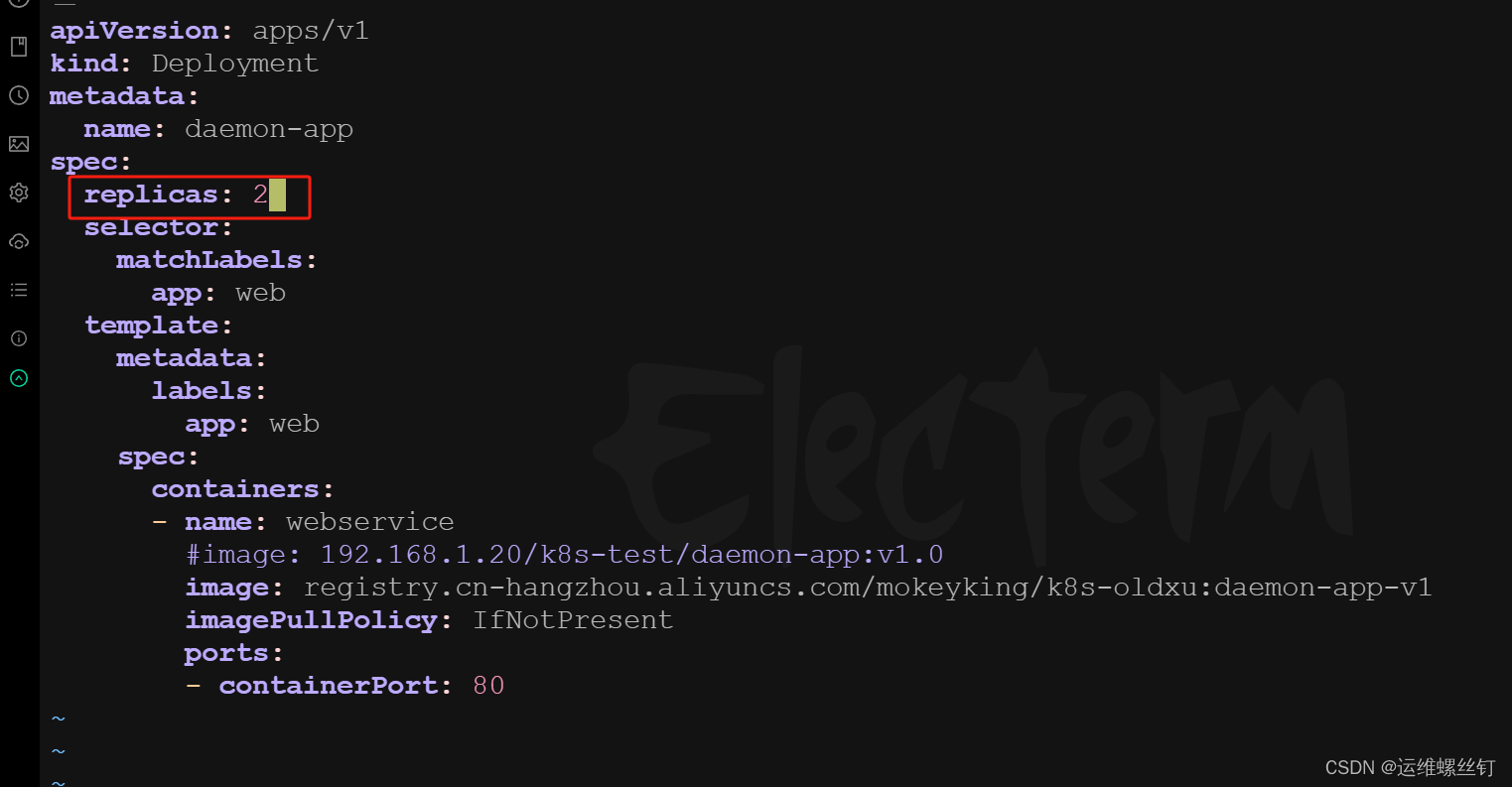
增加
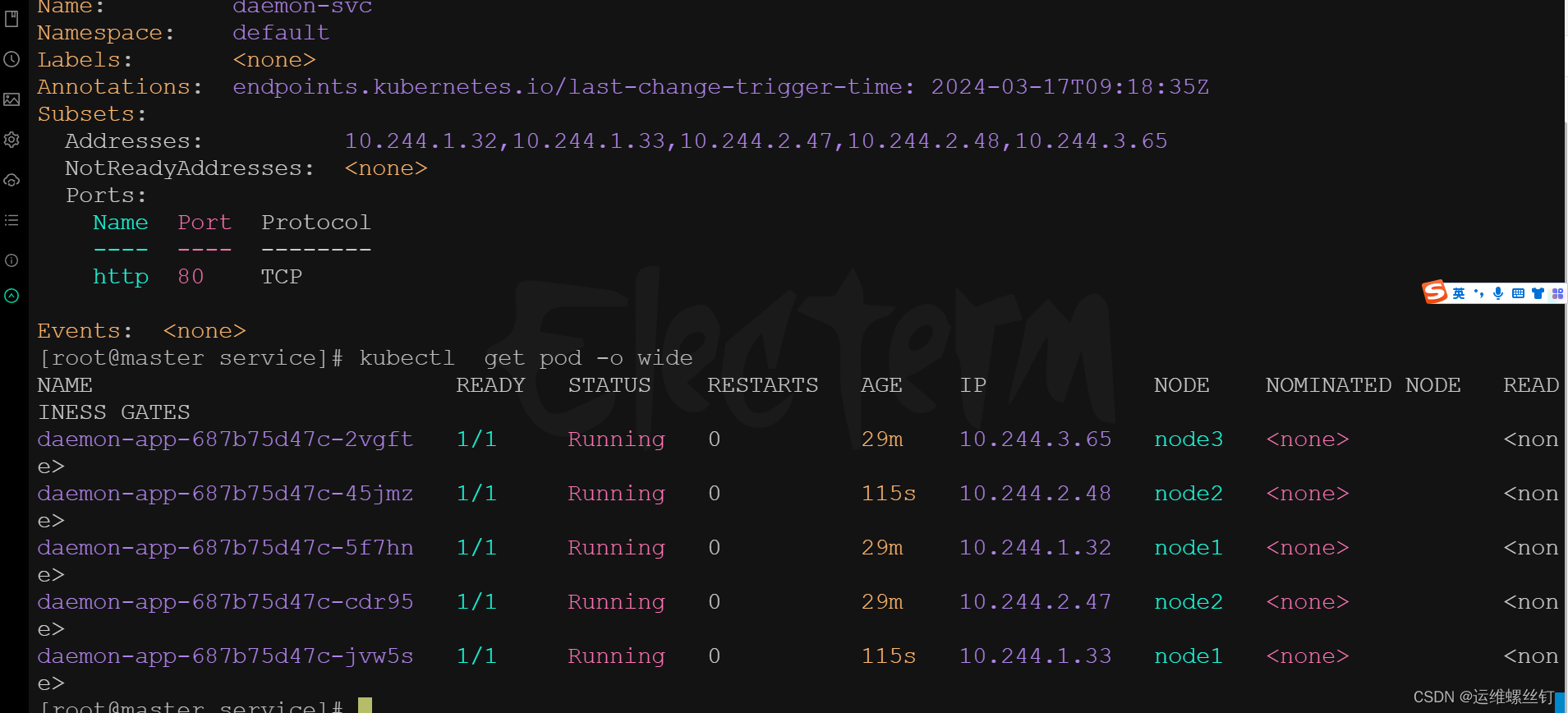
减少
6、编写固定的clusterIP地址,方便记忆
运行以下命令查看 Kubernetes 集群中 Service IP 地址范围的配置:

apiVersion: v1
kind: Service
metadata:
name: daemon-svc-02
spec:
clusterIP: 10.96.1.1
type: ClusterIP
selector:
app: web
ports:
- name: http
port: 8888
targetPort: 80
验证
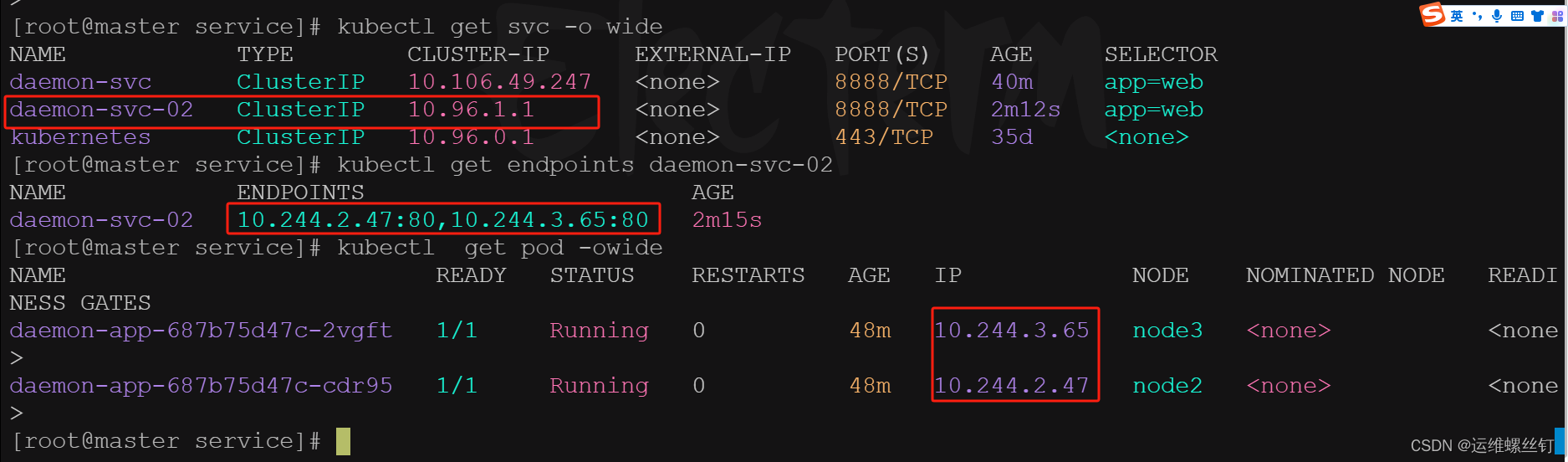
while sleep 0.5 ;do curl 10.96.1.1:8888;done
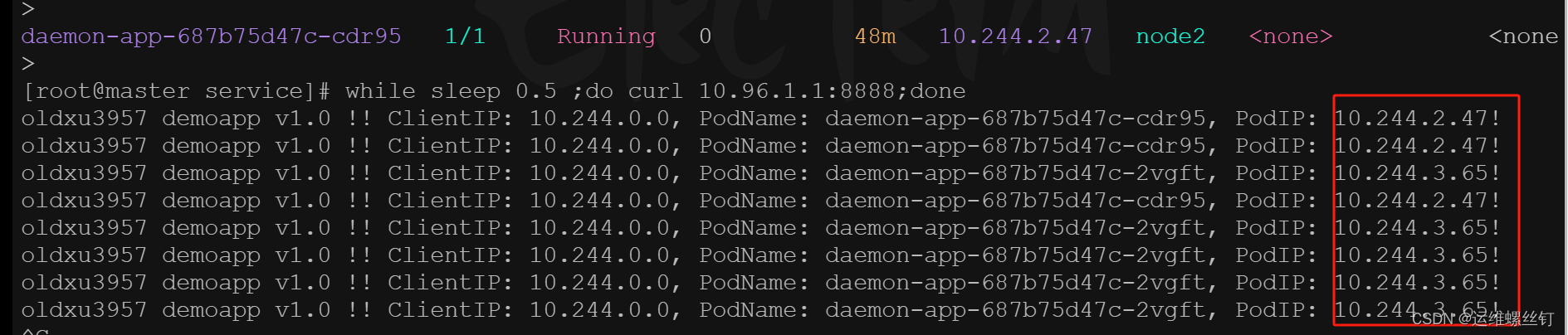
四、Service的实践-NodePort
1、 NodePort
apiVersion: v1
kind: Service
metadata:
name: daemon-svc-03
spec:
type: NodePort
selector:
app: web
ports:
- name: http
port: 8888
targetPort: 80
通过浏览器访问:nodeIP + 30695


2、NodePort的端口范围
在 Kubernetes 集群中,Service 的端口范围是由 kube-apiserver 的 --service-node-port-range 标志来定义的。这个标志用于指定允许使用的 NodePort 端口范围。
要查看 Kubernetes 集群中 Service 端口范围的配置,可以按照以下步骤进行操作:
1、登录到 Kubernetes 集群的主节点或任意一个运行 kube-apiserver 的节点。
2、查看 kube-apiserver 的配置文件,通常为 /etc/kubernetes/manifests/kube-apiserver.yaml(根据你的安装方式和配置可能会有所不同)。
3、在该配置文件中找到 kube-apiserver 容器的启动参数部分,查找 --service-node-port-range 参数。
4、–service-node-port-range 参数的值将指定 Service 允许使用的 NodePort 端口范围。默认情况下,NodePort 的范围是从30000到32767。
如果你无法直接查看 kube-apiserver 的配置文件,你也可以通过以下命令查看当前 kube-apiserver 的运行参数:
ps aux | grep kube-apiserver
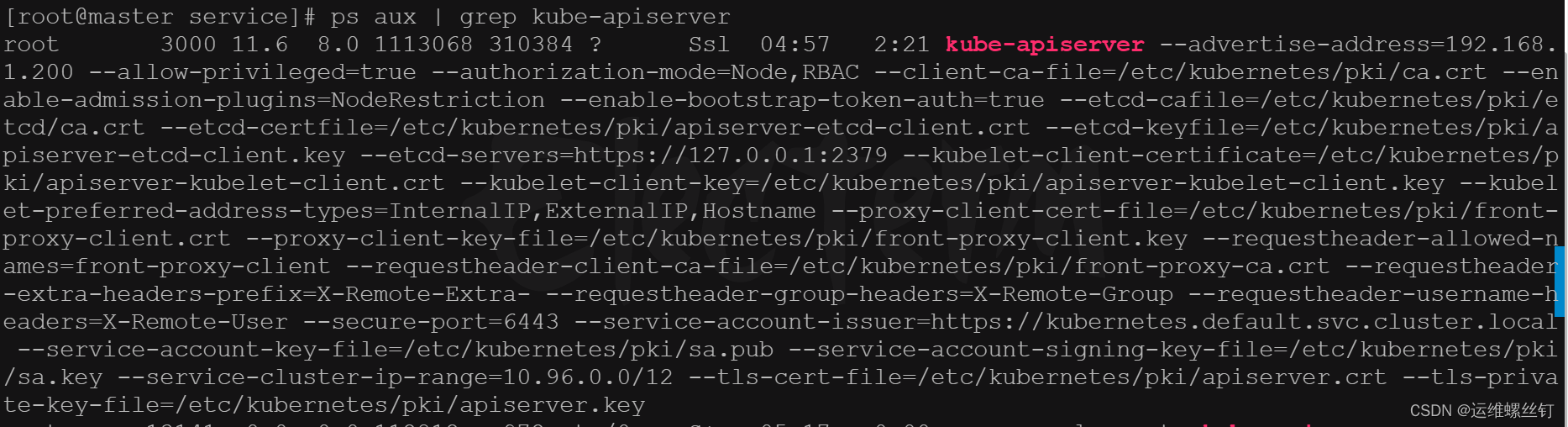
cat /etc/kubernetes/manifests/kube-apiserver.yaml
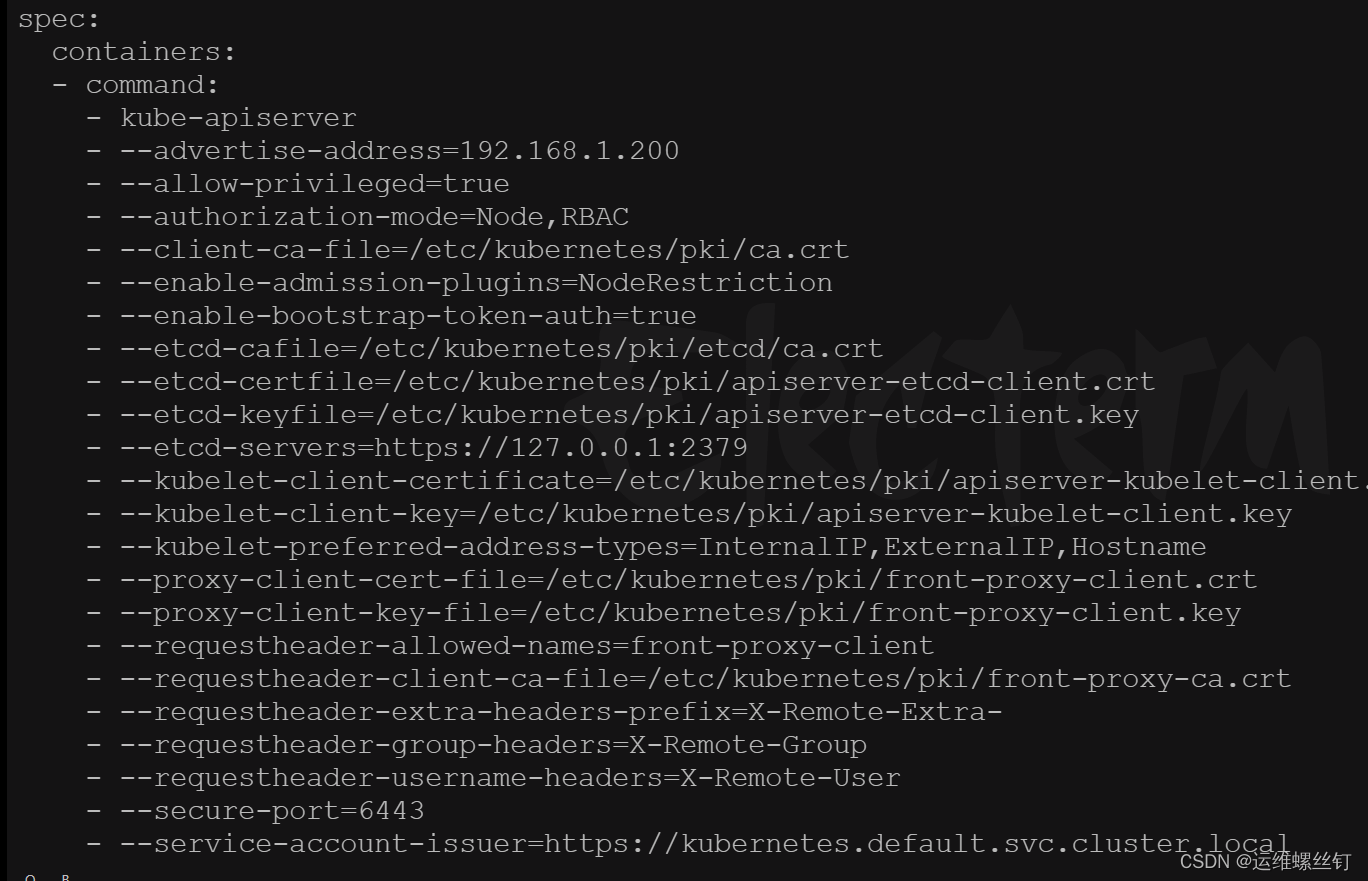
两者输出的信息是一样的
3、修改NodePort的端口范围
(因实验失败后续补充)
4、指定nodePort的端口
apiVersion: v1
kind: Service
metadata:
name: daemon-svc-03
spec:
type: NodePort
selector:
app: web
ports:
- name: http
port: 8888 ## 这个service+ IP 进行访问
targetPort: 80 ## pod服务端口
nodePort: 32000 ## Nodeport + IP进行访问
五、Service的实践-externalname
1、externalname
apiVersion: v1
kind: Service
metadata:
name: daemon-external
spec:
type: ExternalName
externalName: www.king.com
2、验证测试
启动一个tools的pod进行测试
(存在疑问后续补充)
六、service和Endpoints关系
1、Endpoints与容器探针
Service对象借助Endpoint资源来跟踪其关联的后端端点,Endpoint对象会根据Service标签选择器筛选出的后端端点的IP地址分别保存在subsets.address字段和subsets.notReadyAddress字段中,它通过APIServer持续、动态跟踪每个端点的状态变化,并即使反应到端点IP所属的字段中。
- subsets.address:保存就绪的容器IP,也就意味着service可以直接将请求调度至该地址段。
- subsets.notReadyAddress:保存未就绪容器IP,也就意味着Service不会将请求调度至该地址段。
apiVersion: v1
kind: Service
metadata:
name: demoapp-readiness-service
spec:
publishNotReadyAddresses: true
selector:
role: web-readiness
ports:
- protocol: TCP
port: 8888
targetPort: 80
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: demoapp2
spec:
replicas: 2
selector:
matchLabels:
role: web-readiness
template:
metadata:
labels:
role: web-readiness
spec:
containers:
- name: demoapp2
image: registry.cn-hangzhou.aliyuncs.com/mokeyking/k8s-oldxu:daemon-app-v1
readinessProbe: # 就绪探针
httpGet:
path: '/readyz'
port: 80
initialDelaySeconds: 15 # 初次检测延时时长
periodSeconds: 10 # 检测周期
通过修改deployment的replicaset的副本数量
kubectl scale deployment demoapp2 --replicas=3
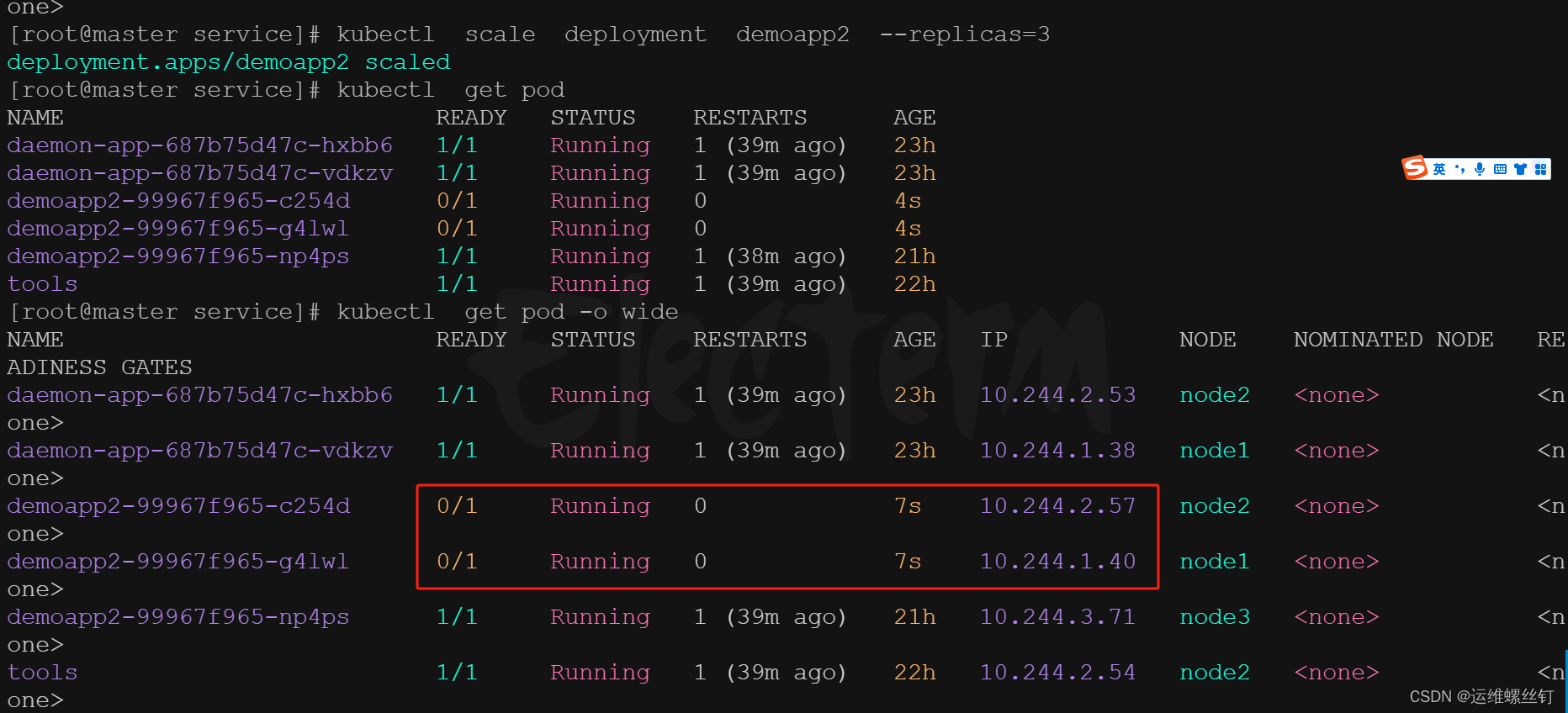
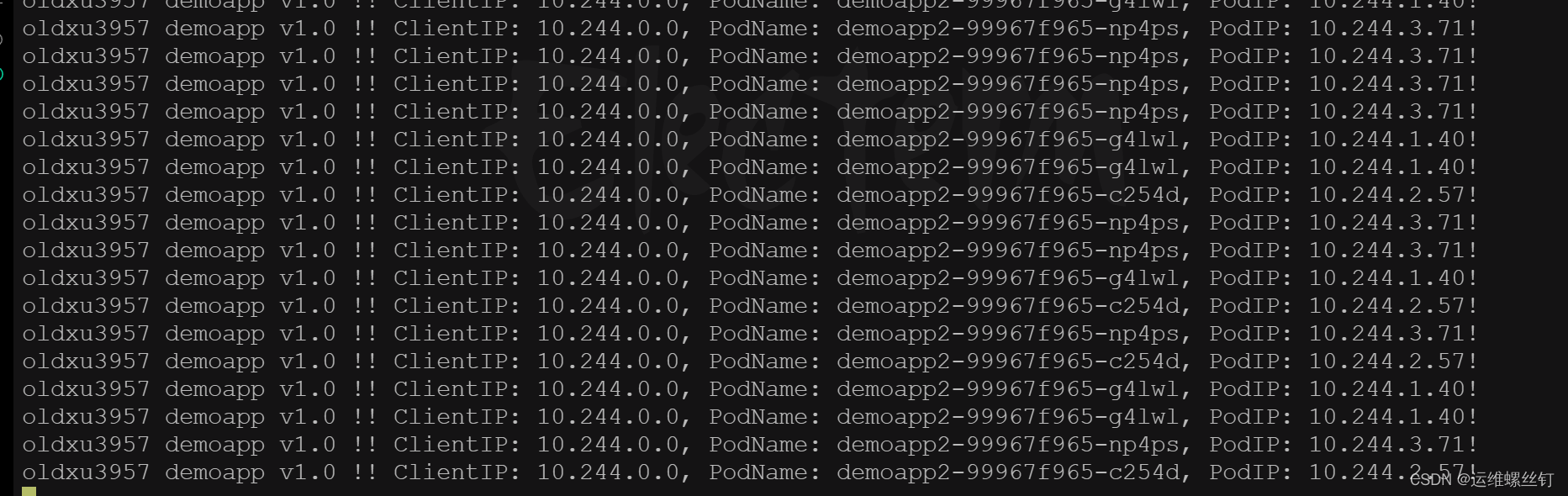
while sleep 10s ;do curl 10.101.87.51 ;done
七、自定义endpoint实践
service通过selector和pod建立关联,k8s会根据service关联到的pOdIP信息组合成-个endpoint。若service定义中没有selector字段,service被创建时,endpoint controller不会自动创建endpoint。
我们可以通过配置清单创建Service,而无需使用标签选择器,而后自行创建一个同名的endpoint对象,指定对应的IP。这种一般用于将外部MySQL\Redis等应用引入Kubernetes集群内部,让内部通过Service的方式访问外部资源。
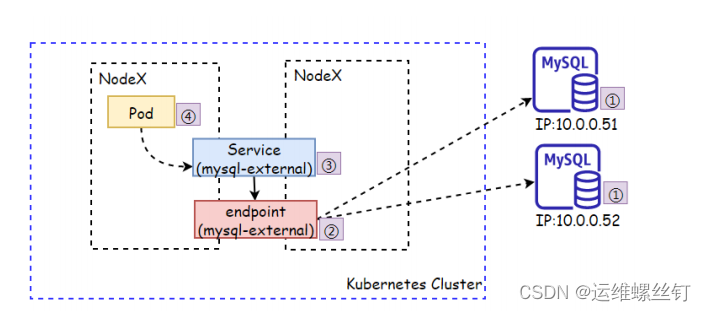
实验一: 将外部mysql数据库引入service集群中
1、准备外部数据库
# 安装mariadb
yum install mariadb mariadb-server -y
systemctl enable mariadb --now
#登陆maridb数据库
mysql
# 授权
grant all privileges on *.* to 'king' identified by 'king395';
flush privileges;
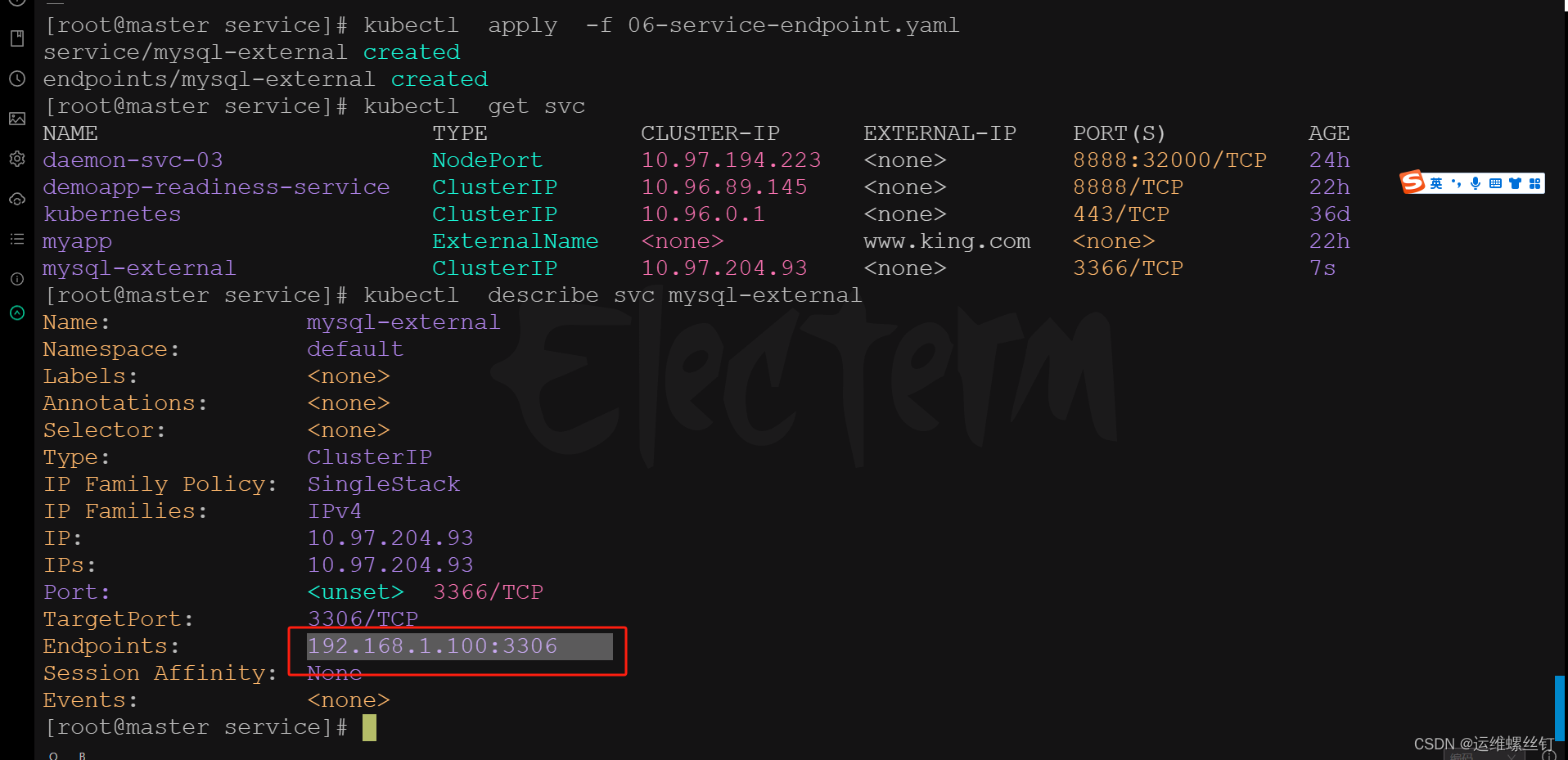
2、创建Endpoints资源清单
# 自定义 service和endpoints
apiVersion: v1
kind: Service
metadata:
name: mysql-external
spec:
type: ClusterIP
ports:
- port: 3366
targetPort: 3306
---
apiVersion: v1
kind: Endpoints
metadata:
name: mysql-external
subsets:
- addresses:
- ip: 192.168.1.100
ports:
- protocol: TCP
port: 3306 # 定义后端的端口是多少
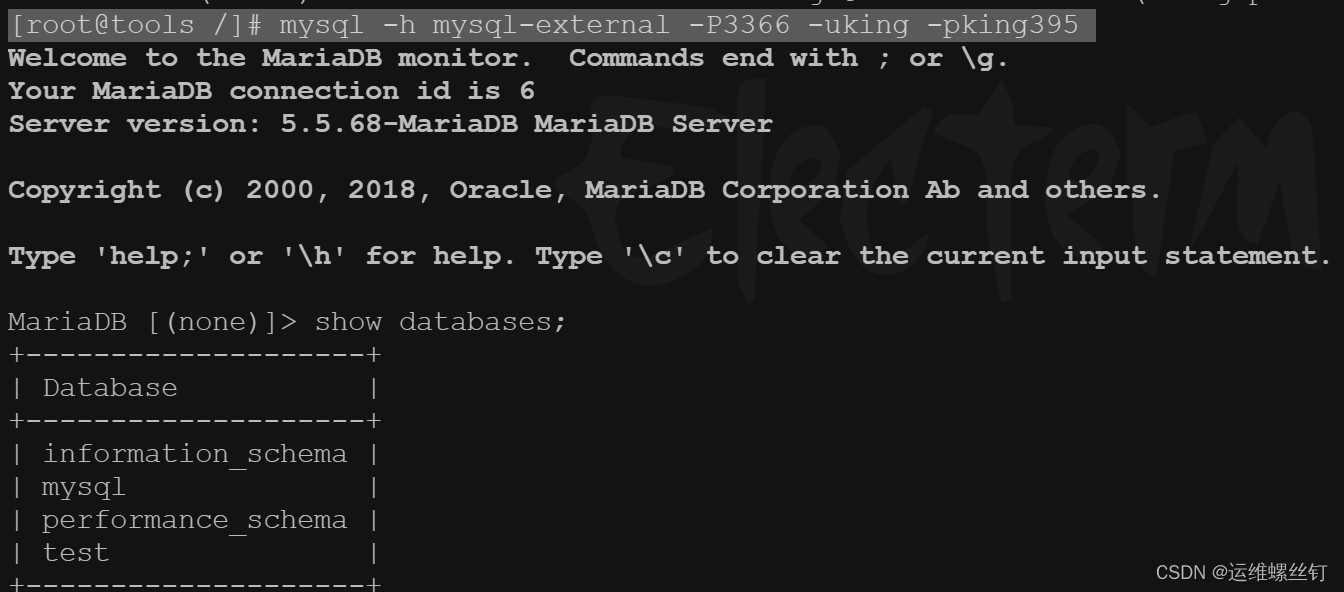
4、测试验证
# 使用tools,该镜像带有mysql命令
[root@master service]# kubectl exec -it tools -- /bash/bin
# 登陆数据库
[root@tools /]# mysql -h mysql-external -P3366 -uking -pking395
# 创建库,创建表
create database king;
use king;
CREATE TABLE users (
id INT AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(50)
);
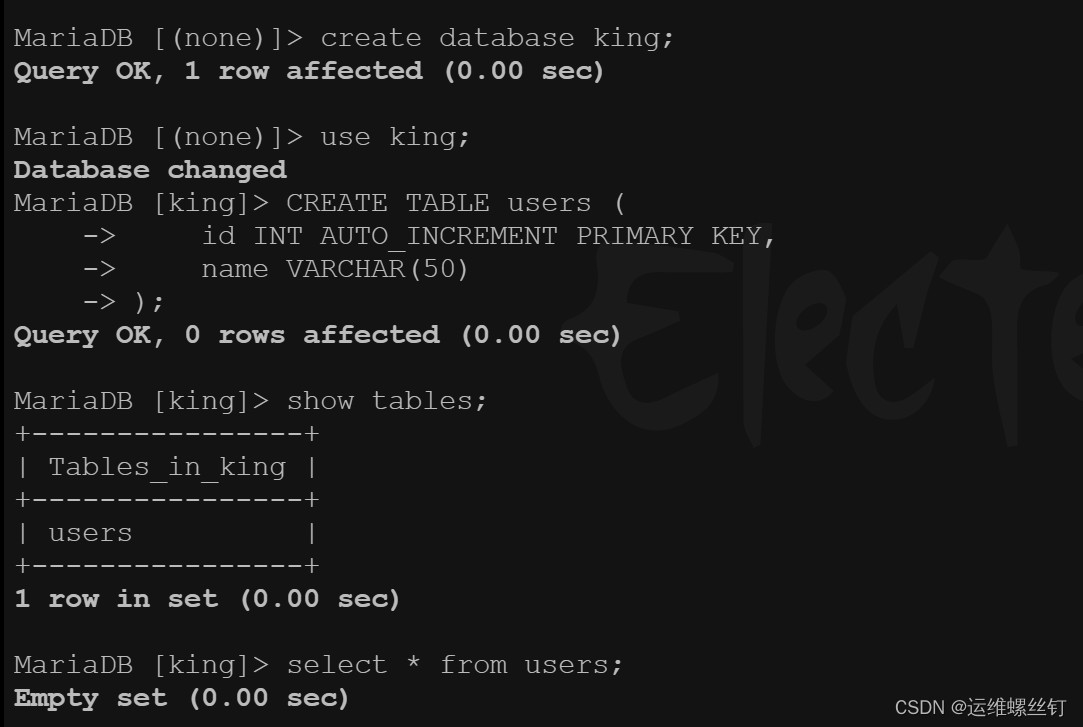
5、登陆数据库再次验证
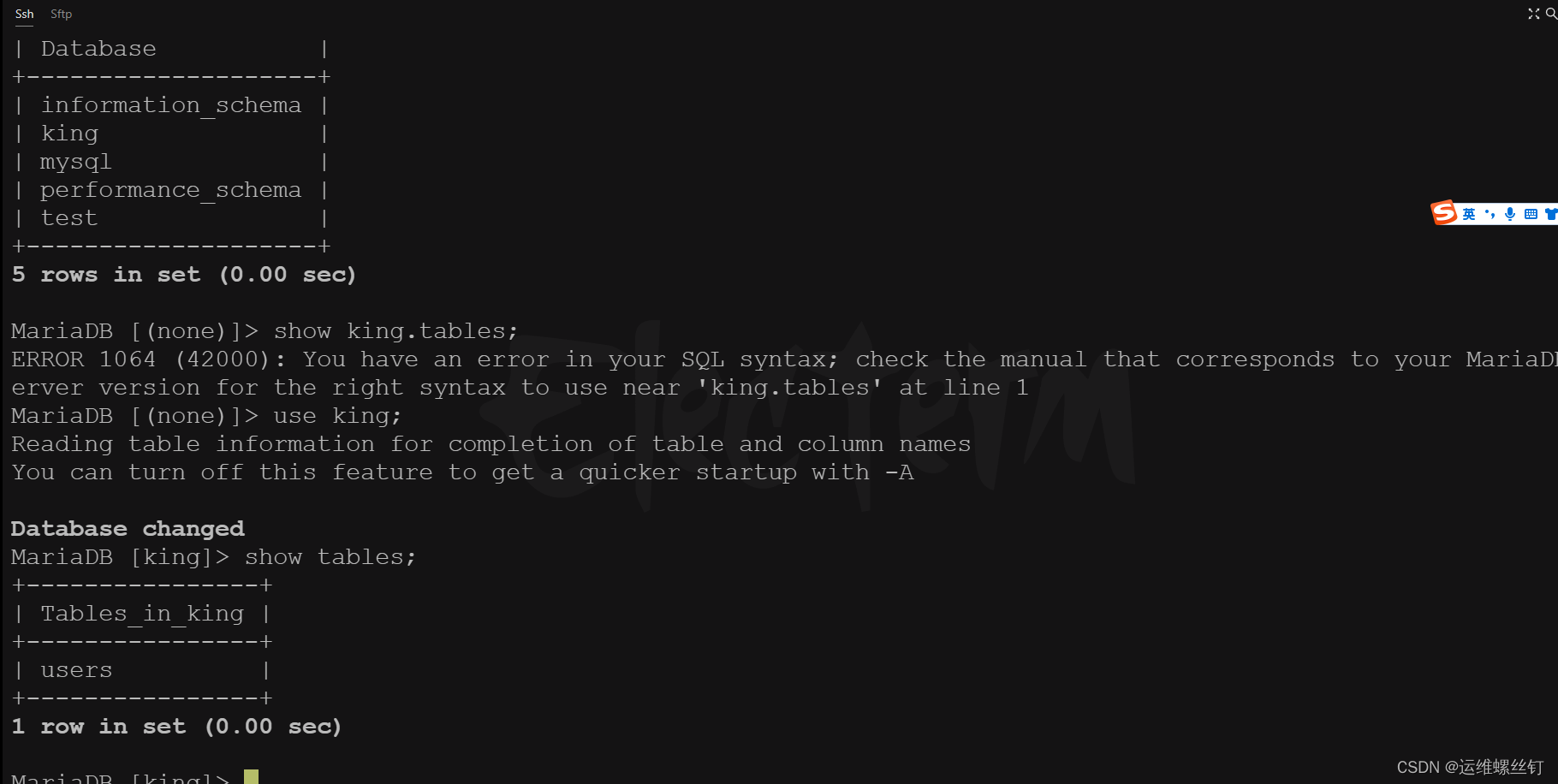
本次实验试验成功
八、service相关字段
1、sessionAffinity
如果要将来自于特定客户端的连接调度至同一Pod,可以使用sessionAffinity 基于客户端的 IP 地址进行会话保持。
还可以通过sessionAffinityConfig.clientIP.timeoutSeconds来设置最大会话停留时间。(默认10800秒,即3小时)
apiVersion: v1
kind: Service
metadata:
name: session-svc
spec:
type: ClusterIP
selector:
app: web
ports:
- name: http
port: 80 # Service的端口,后期所有的用户通过该端口进行访问
targetPort: 80 # Pod的端口
sessionAffinity: ClientIP
sessionAffinityConfig:
clientIP:
timeoutSeconds: 60 #会话保持60秒
curl 10.101.87.51
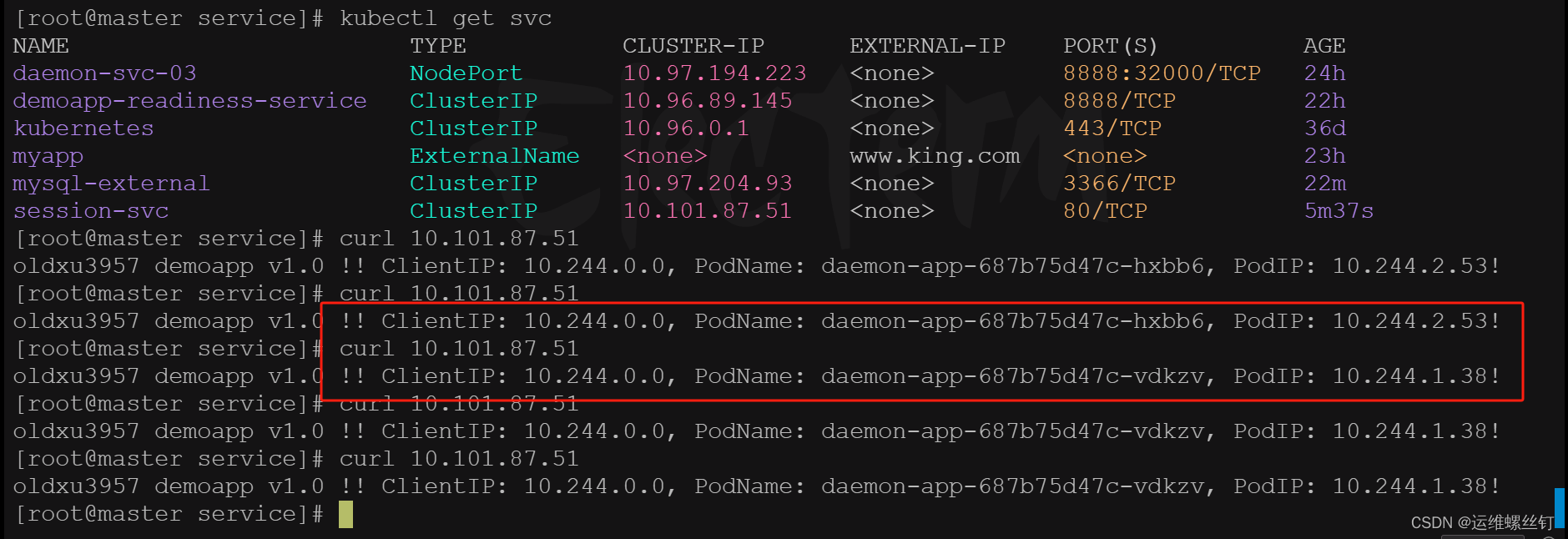
会话记录会保持60秒
2、externalTrafficPolicy
外部流量策略:当外部用户通过NodePort请求Service,是将外部流量路由到本地节点上的Pod,还是路由到集群范围的Pod:
- Cluster(默认):将用户请求路由到集群范围的所有Pod节点,具有良好的整体负载均衡。
- Local:仅会将流量调度至请求的目标节点本地运行的Pod对象之上,以减少网络跳跃,降低网络延迟,但当请求指向的节点本地不存在目标Service相关的Pod对象时直接丢弃该报文。
2.1 Cluster模式
apiVersion: v1
kind: Service
metadata:
name: demoapp-svc-external-traffic
spec:
externalTrafficPolicy: Cluster # 有两种模式Cluster和Local
type: NodePort
selector:
app: web
ports:
- name: http
port: 8888 # Service的端口,后期所有的用户通过该端口进行访问
targetPort: 80 # Pod的端口
nodePort: 32001 #
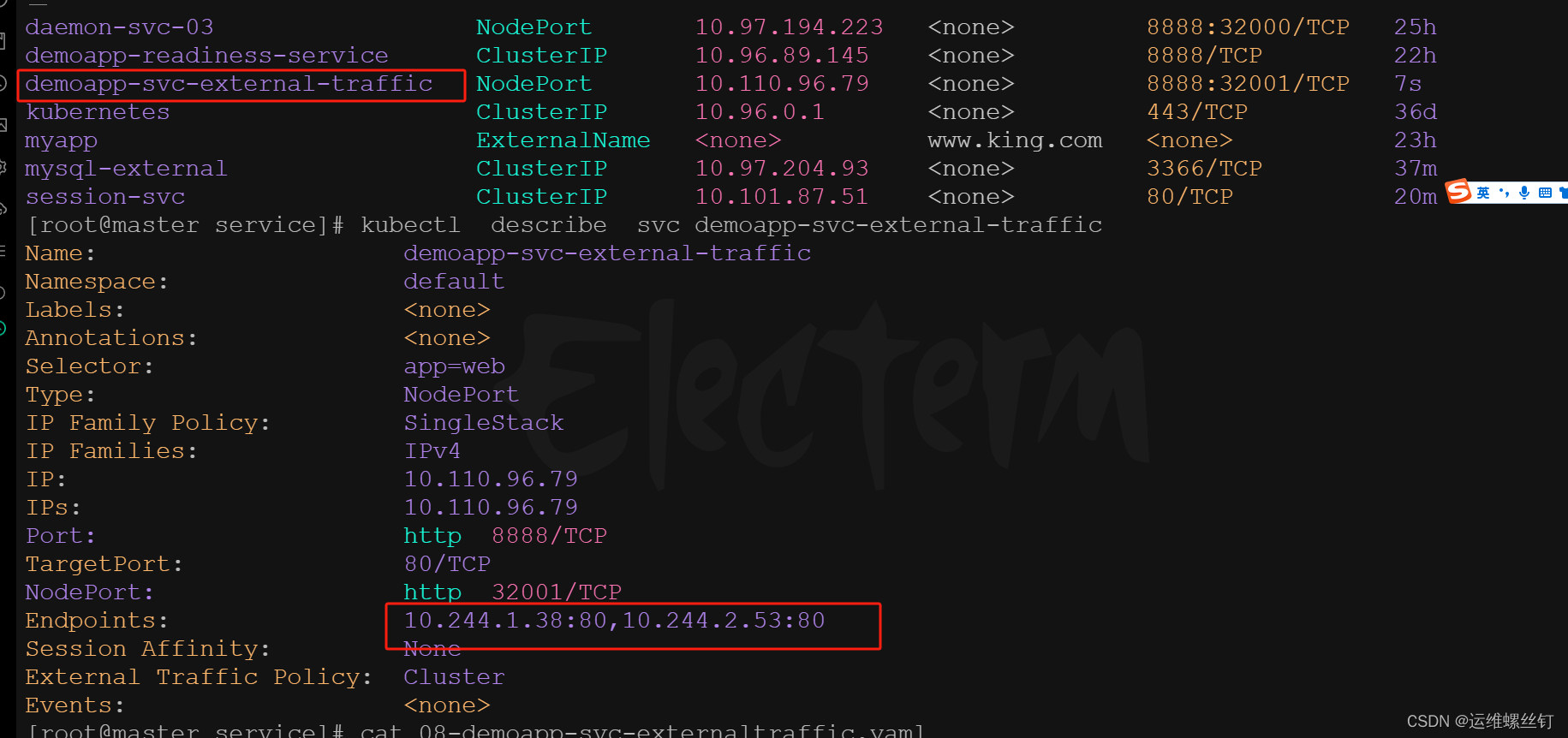


会分别到不同的node节点中去
2.1 Local模式
apiVersion: v1
kind: Service
metadata:
name: demoapp-svc-external-traffic
spec:
externalTrafficPolicy: Local # 有两种模式Cluster和Local
type: NodePort
selector:
app: web
ports:
- name: http
port: 8888 # Service的端口,后期所有的用户通过该端口进行访问
targetPort: 80 # Pod的端口
nodePort: 32001 #
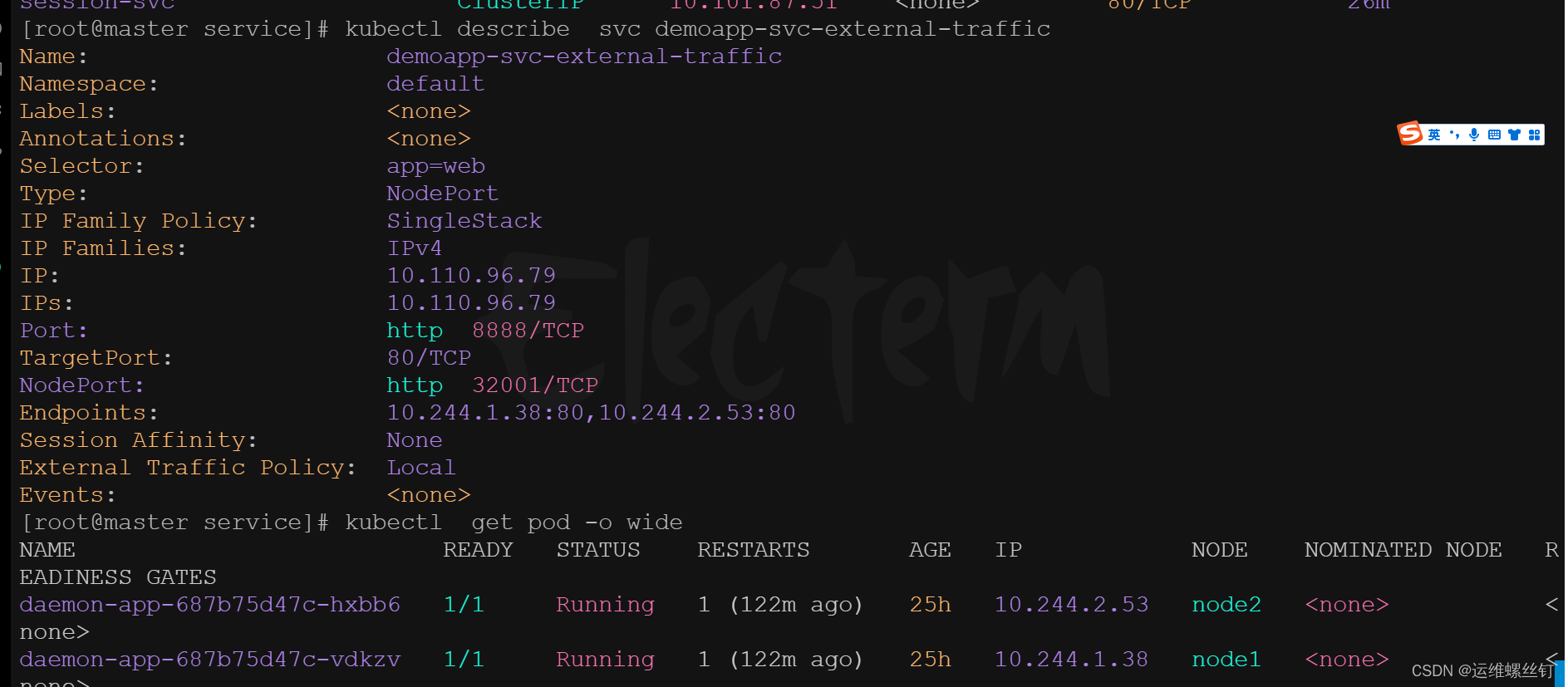


不管怎么刷新,只会在指定的node进行返回
3、internalTrafficPolicy
本地流量策略:当本地Pod对Service发起访问时,是将流量路由到本地节点上的Pod,还是路由到集群范围的Pod:
- Cluster(默认):将Pod的请求路由到集群范围的所有Pod节点具有良好的整体负载均衡。
- Local:将请求路由到与发起方处于相同节点的端点,这种机制有助于节省开销,提升效率。但当请求指向的节点本地不存在目标Service相关的Pod对象时直接丢弃该报文。
注意:在一个Service上,当externalTrafficPolicy已设置为 Local时,internalTrafficPolicy则无法使用。 换句话说在一个集群的不同 Service 上可以同时使用这两个特性,但在一个Service 上不行
3.1 Cluster模式
apiVersion: v1
kind: Service
metadata:
name: demoapp-svc-internal-traffic
spec:
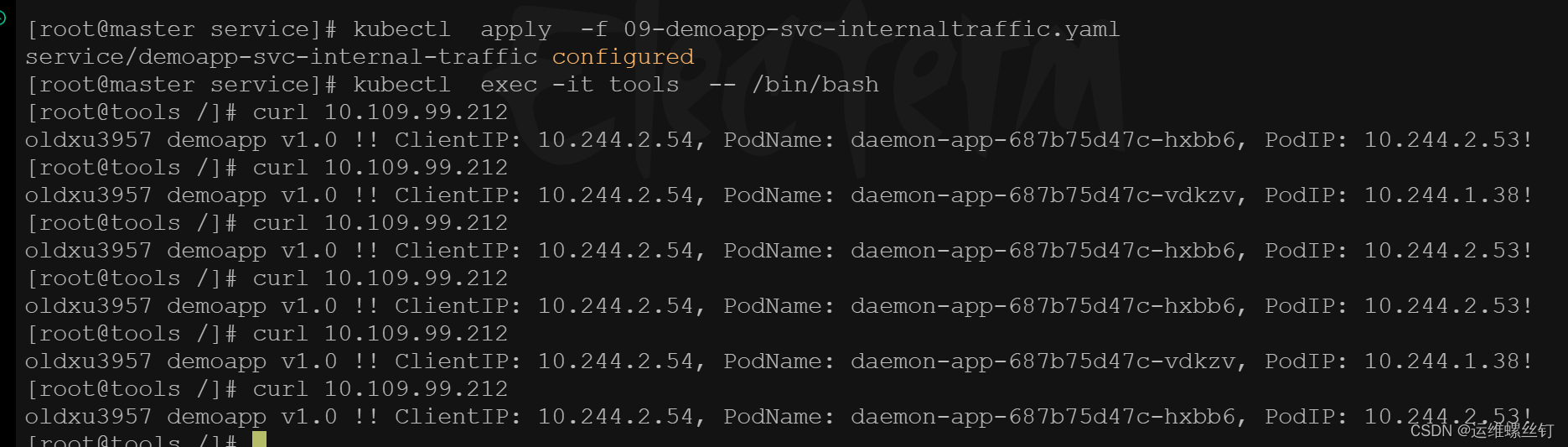
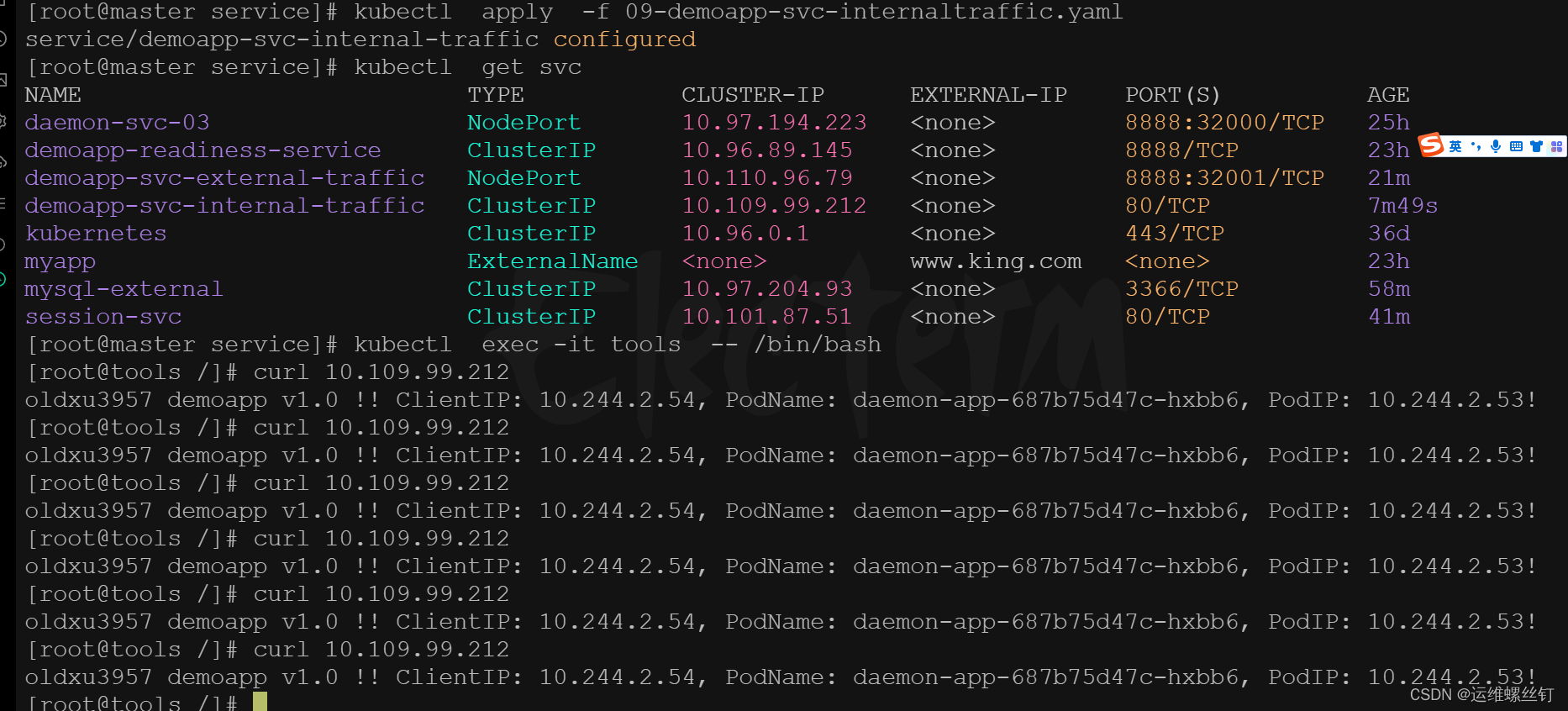
internalTrafficPolicy: Cluster # 有两种模式Cluster和Local,当externalTrafficPolicy已设置为 Local时,internalTrafficPolicy则无法使用
selector:
app: web
ports:
- name: http
port: 80 # Service的端口,后期所有的用户通过该端口进行访问
targetPort: 80 # Pod的端口
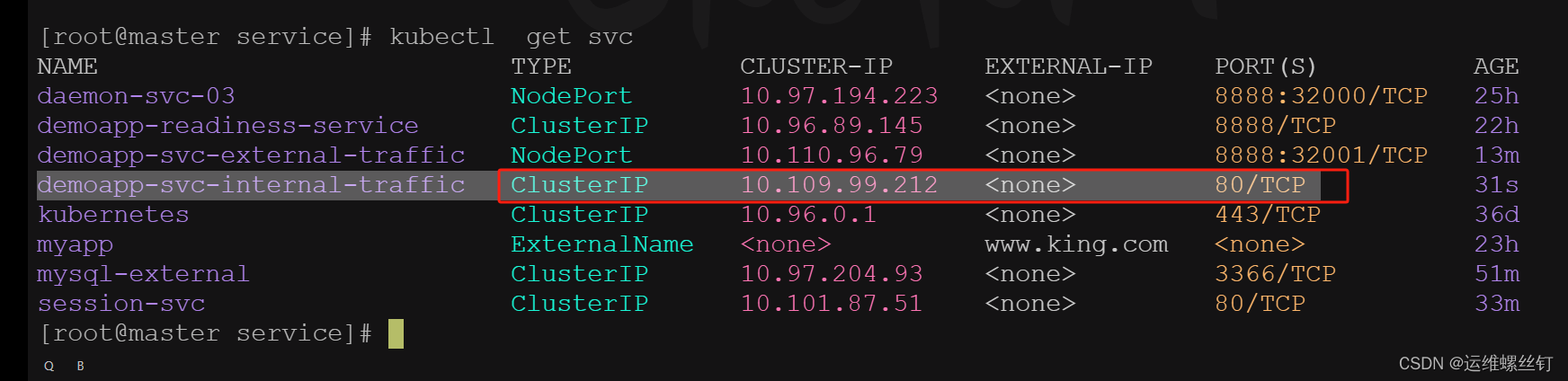
## 使用tools镜像进行测试
kubectl exec -it tools -- /bin/bash
3.2 Local模式
apiVersion: v1
kind: Service
metadata:
name: demoapp-svc-internal-traffic
spec:
internalTrafficPolicy: Local # 有两种模式Cluster和Local,当externalTrafficPolicy已设置为 Local时,internalTrafficPolicy则无法使用
selector:
app: web
ports:
- name: http
port: 80 # Service的端口,后期所有的用户通过该端口进行访问
targetPort: 80 # Pod的端口
4、publishNotReadyAddresses
publishNotReadyAddresses:表示Pod就绪探针探测失败,也不会将失败的PodIP加入notReadyAddress列表中
4.1、检查当前Service对应的后端列表;
apiVersion: v1
kind: Service
metadata:
name: demoapp-readiness-service
spec:
publishNotReadyAddresses: true
selector:
role: web-readiness
ports:
- protocol: TCP
port: 8888
targetPort: 80
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: demoapp2
spec:
replicas: 4
selector:
matchLabels:
role: web-readiness
template:
metadata:
labels:
role: web-readiness
spec:
containers:
- name: demoapp2
image: oldxu3957/demoapp:v1.0
readinessProbe: # 就绪探针
httpGet:
path: '/readyz'
port: 80
initialDelaySeconds: 15 # 初次检测延时时长
periodSeconds: 10 # 检测周期
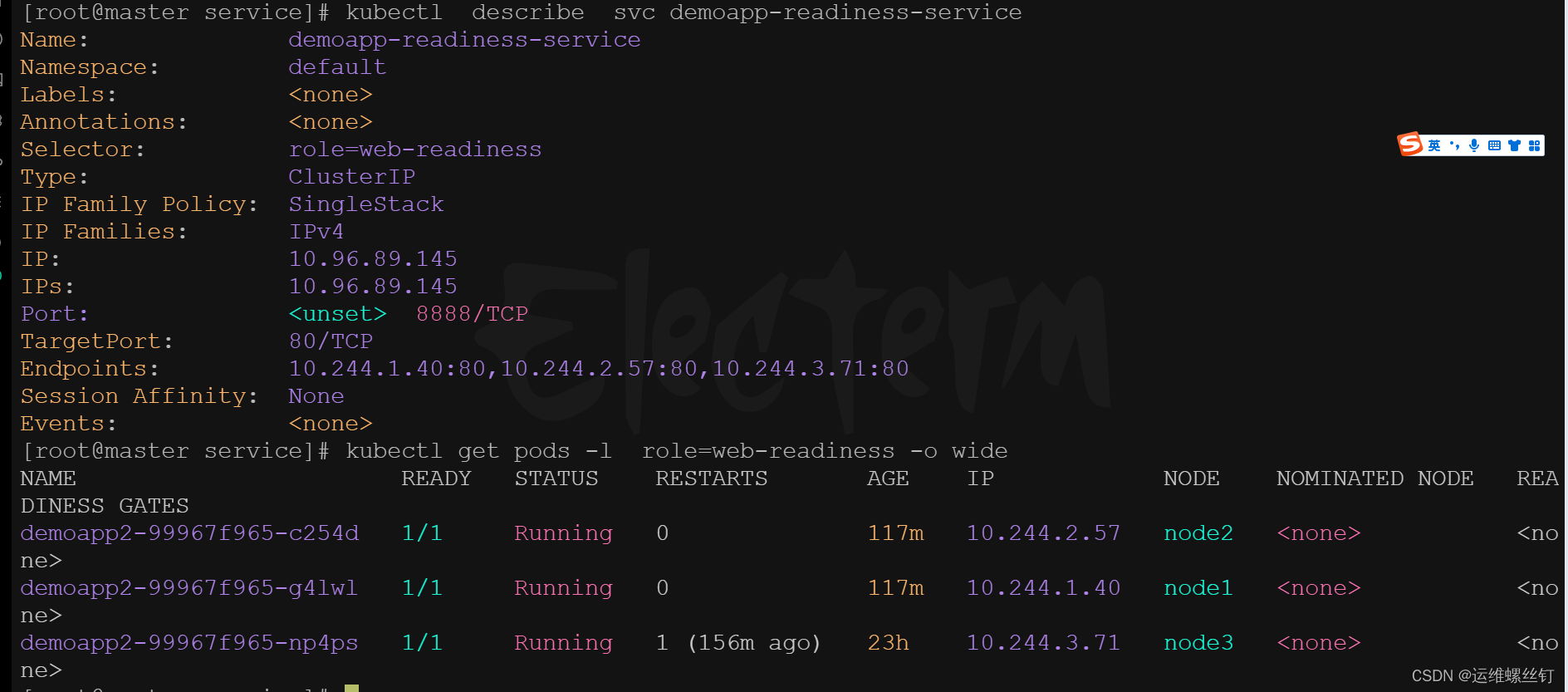
# 查看svc详情
kubectl describe svc demoapp-readiness-service
# 按照标签进行查看pod
kubectl get pod --show-labels
kubectl get pods -l role=web-readiness -o wide
4.2、将其中的某个Pod设定为不就绪,看看是否会将该PodIP加入到NotReadAddress字段中
apiVersion: v1
kind: Service
metadata:
name: demoapp-readiness-service
spec:
publishNotReadyAddresses: true ## 添加该字段
selector:
role: web-readiness
ports:
- protocol: TCP
port: 8888
targetPort: 80
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: demoapp2
spec:
replicas: 2
selector:
matchLabels:
role: web-readiness
template:
metadata:
labels:
role: web-readiness
spec:
containers:
- name: demoapp2
image: oldxu3957/demoapp:v1.0
readinessProbe: # 就绪探针
httpGet:
path: '/readyz'
port: 80
initialDelaySeconds: 15 # 初次检测延时时长
periodSeconds: 10 # 检测周期
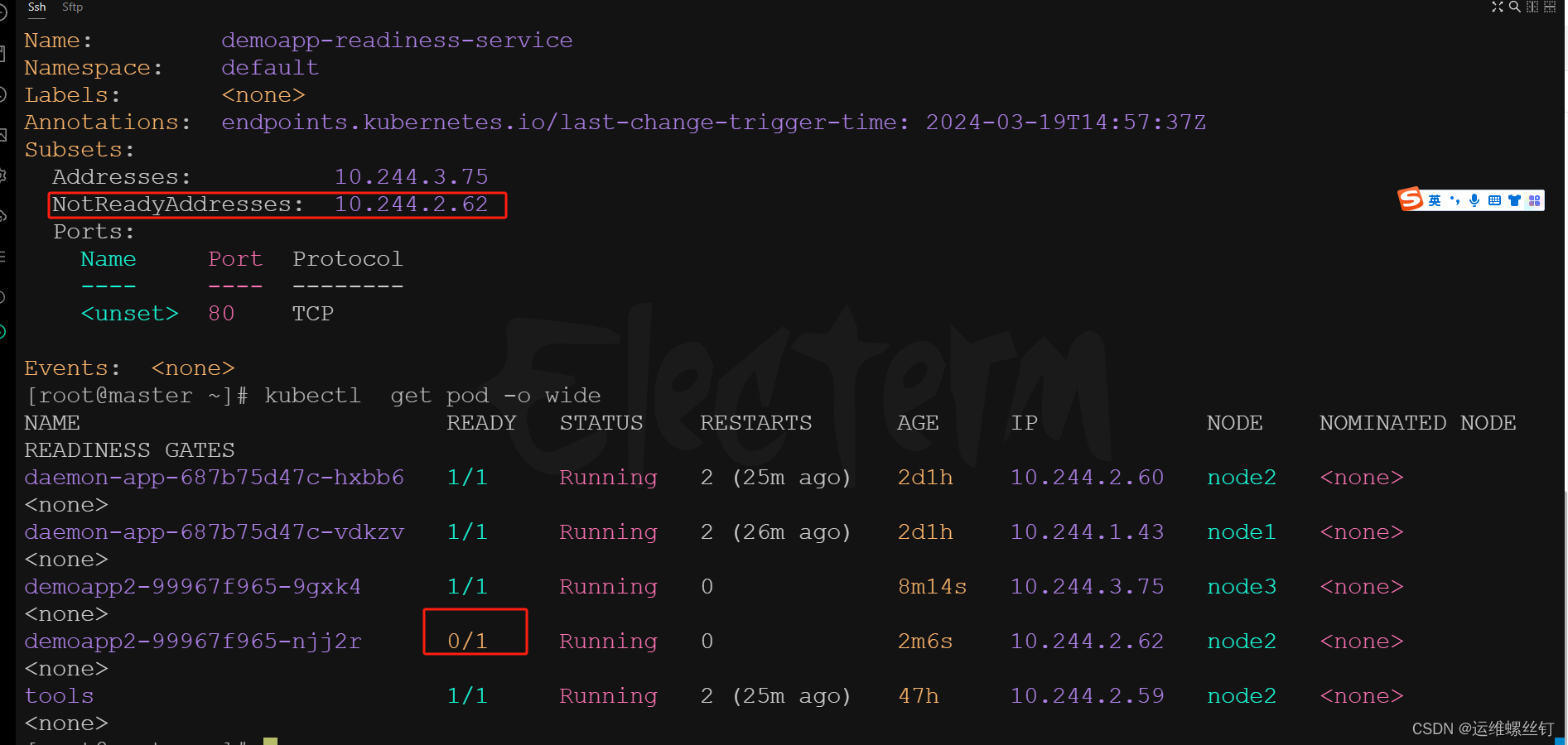
- 将pod设置成未就绪
curl -s -X POST -d 'readyz=err' 10.244.2.62/readyz
# 如果想将pod设置成就绪状态,只需要将pod进行删除重建就可以了
-
无论如何请求,只会请求只就绪的pod中
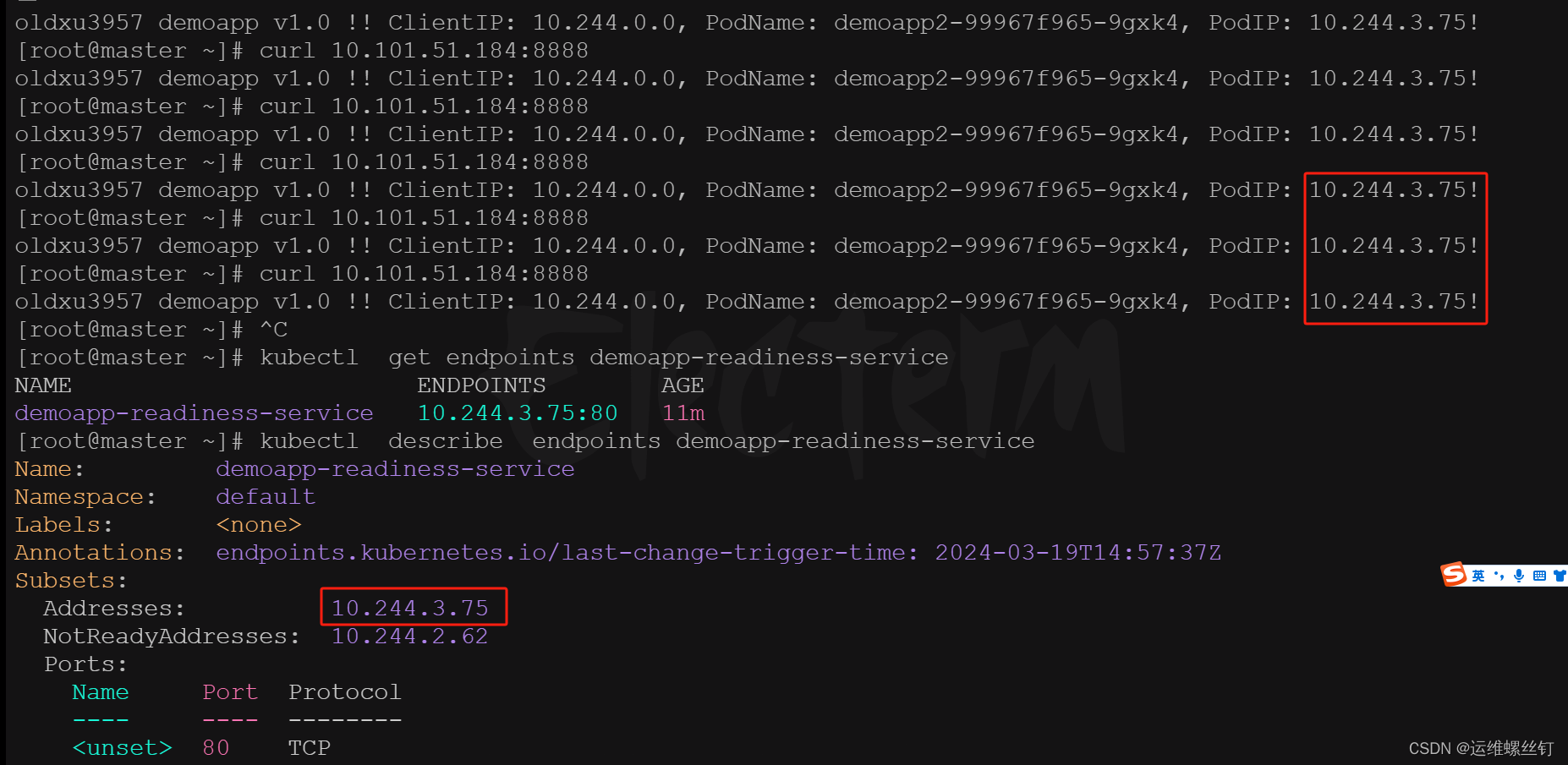
-
添加参数后的svc
spec:
'''
publishNotReadyAddresses: true
''''
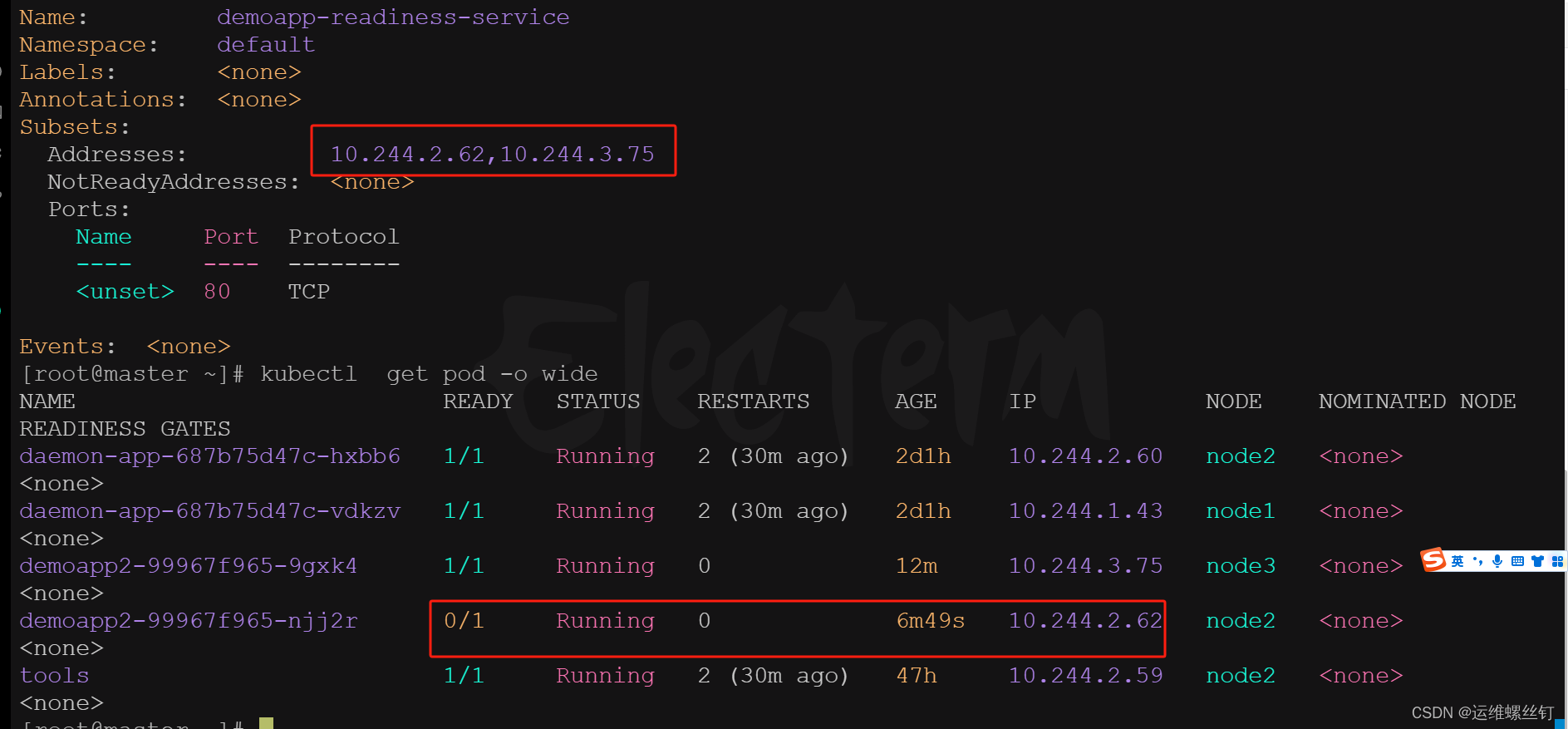
可以调用到未就绪的pod中
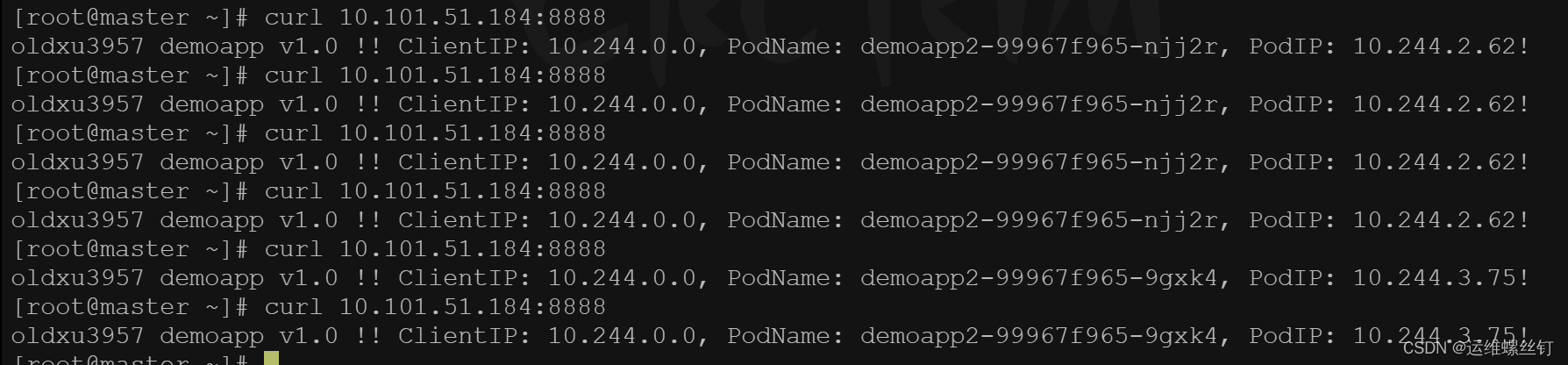
这种应用场景比较少
九、service的进阶-iptables和IPVS
1、service访问场景:
访问Service会出现如下4中情况:
- 1、Pod-A>Service >调度>Pod-B/Pod-C
- 2、Pod-A->Service >调度->Pod-A
- 3、Docker>Service>调度→>Pod-B/Pod-C
- 4、NodePort>Service>调度→>Pod-B/Pod-C
2、iptables规则
场景一,clusterIP规则
Pod-A>Service >调度>Pod-B/Pod-C
1、编写资源
apiVersion: apps/v1
kind: Deployment
metadata:
name: demoapp
spec:
replicas: 3
selector:
matchLabels:
app: web
template:
metadata:
labels:
app: web
spec:
containers:
- name: webservers
image: oldxu3957/demoapp:v1.0
imagePullPolicy: IfNotPresent
ports:
- containerPort: 80
---
apiVersion: v1
kind: Service
metadata:
name: demoapp-svc
spec:
type: ClusterIP
selector:
app: web
ports:
- port: 80
targetPort: 80

2、登陆pod,访问svc
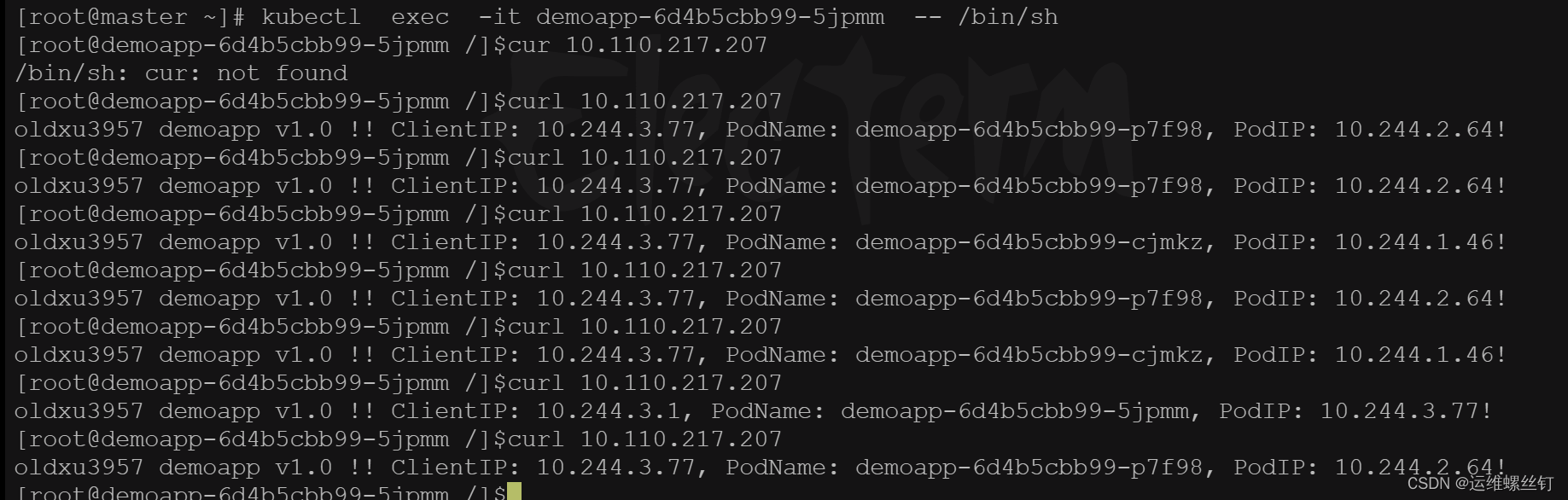
3、iptables规则查看
iptables的流程:
入站本机:PREROUTING -->INPUT
从本机流入: OUTPUT --》 POSTROUTING
经过节点: PREROUTING --》FORWRD --》POSTROUTING
整体流程:
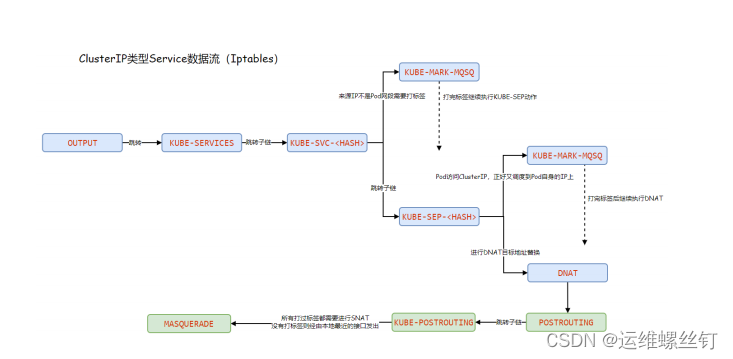
OUTPUT–>KUBE-SERVICES–>KUBE-SVC-–>KUBE-SEP------>POSTROUTING-----> KUBEPOSTROUTING ---->interface
第一步:所有从OUTPUT出去的数据包,都必须经过KUBE-SERVICES自定义链;
[root@node02 ~]# iptables -S OUTPUT
-P OUTPUT ACCEPT
-A OUTPUT -m conntrack --ctstate NEW -m comment --comment "kubernetes service portals" -j KUBE-SERVICES
-A OUTPUT -j KUBE-FIREWALL
-A OUTPUT -o virbr0 -p udp -m udp --dport 68 -j ACCEPT
第二步:分析KUBE-SERVICES
当发现请求的ServiceIP是 10.110.217.207的80端口时,则跳转KUBE-SVC-HASH这个自定义链上;
[root@node2 ~]# iptables -t nat -S KUBE-SERVICES | grep demoapp-svc
-A KUBE-SERVICES -d 10.110.217.207/32 -p tcp -m comment --comment "default/demoapp-svc cluster IP" -m tcp --dport 80 -j KUBE-SVC-EHL433DY3T7P3MZN
第三步:
第一条:创建自定义链;
第二条:如果来源不是POd的地址段,则将这个请求直接跳转到KUBE-MARK-MASQ这个自定义链上去; 然后给这个请求打上对应的标记 0x4000/0x4000
第三条到第五条:将请求通过调度算法调度到对应的自定义链上; --> 第一次请求第一条有1/3 第二次请求50% 第三次 100%
[root@node2 ~]# iptables -t nat -S KUBE-SVC-EHL433DY3T7P3MZN
-N KUBE-SVC-EHL433DY3T7P3MZN
-A KUBE-SVC-EHL433DY3T7P3MZN ! -s 10.244.0.0/16 -d 10.110.217.207/32 -p tcp -m comment --comment "default/demoapp-svc cluster IP" -m tcp --dport 80 -j KUBE-MARK-MASQ
### 通过轮休的方式进行调度到指定的地址上
-A KUBE-SVC-EHL433DY3T7P3MZN -m comment --comment "default/demoapp-svc" -m statistic --mode random --probability 0.33333333349 -j KUBE-SEP-OKCWPUIB7WHDSNLK
-A KUBE-SVC-EHL433DY3T7P3MZN -m comment --comment "default/demoapp-svc" -m statistic --mode random --probability 0.50000000000 -j KUBE-SEP-47KFJORAGBSAGTDM
-A KUBE-SVC-EHL433DY3T7P3MZN -m comment --comment "default/demoapp-svc" -j KUBE-SEP-GDD5ADYI2DAT4RQT
[root@node2 ~]# iptables -t nat -S KUBE-MARK-MASQ
-N KUBE-MARK-MASQ
-A KUBE-MARK-MASQ -j MARK --set-xmark 0x4000/0x4000 #请求打上对应的标记 0x4000/0x4000
第四步:
第一条:创建自定义链;
第二条:如果10.244.1.46 访问得是自己的Service,然后又被Service调度给自己本身,这个时候就将这个请求打上对应的标签 0x4000/0x4000
第三条:进行dnat操作,就是将请求Service的IP,替换为Service后端的Pod的IP地址;
[root@node2 ~]# iptables -t nat -S KUBE-SEP-OKCWPUIB7WHDSNLK
-N KUBE-SEP-OKCWPUIB7WHDSNLK
-A KUBE-SEP-OKCWPUIB7WHDSNLK -s 10.244.1.46/32 -m comment --comment "default/demoapp-svc" -j KUBE-MARK-MASQ
-A KUBE-SEP-OKCWPUIB7WHDSNLK -p tcp -m comment --comment "default/demoapp-svc" -m tcp -j DNAT --to-destination 10.244.1.46:80
[root@node2 ~]# iptables -t nat -S KUBE-SEP-47KFJORAGBSAGTDM
-N KUBE-SEP-47KFJORAGBSAGTDM
-A KUBE-SEP-47KFJORAGBSAGTDM -s 10.244.2.64/32 -m comment --comment "default/demoapp-svc" -j KUBE-MARK-MASQ
-A KUBE-SEP-47KFJORAGBSAGTDM -p tcp -m comment --comment "default/demoapp-svc" -m tcp -j DNAT --to-destination 10.244.2.64:80
[root@node2 ~]# iptables -t nat -S KUBE-SEP-GDD5ADYI2DAT4RQT
-N KUBE-SEP-GDD5ADYI2DAT4RQT
-A KUBE-SEP-GDD5ADYI2DAT4RQT -s 10.244.3.77/32 -m comment --comment "default/demoapp-svc" -j KUBE-MARK-MASQ
-A KUBE-SEP-GDD5ADYI2DAT4RQT -p tcp -m comment --comment "default/demoapp-svc" -m tcp -j DNAT --to-destination 10.244.3.77:80
第五步:
第一条:创建自定义链;
第二条:无条件调度到KUBE-POSTROUTING这个自定义链上;
第三条: docker相关的;忽略;
第四条:由于源地址是 192.168.122.0/16 目标 192.168.122.0/16,所以RETURN了;又回到了POSTROUTING链;看默认的规则是什么;ACEEPT; 数据包就会被送出;
[root@node2 ~]# iptables -t nat -S POSTROUTING
-P POSTROUTING ACCEPT
-A POSTROUTING -m comment --comment "kubernetes postrouting rules" -j KUBE-POSTROUTING
-A POSTROUTING -s 172.17.0.0/16 ! -o docker0 -j MASQUERADE
-A POSTROUTING -s 192.168.122.0/24 -d 224.0.0.0/24 -j RETURN
-A POSTROUTING -s 192.168.122.0/24 -d 255.255.255.255/32 -j RETURN
-A POSTROUTING -s 192.168.122.0/24 ! -d 192.168.122.0/24 -p tcp -j MASQUERADE --to-ports 1024-65535
-A POSTROUTING -s 192.168.122.0/24 ! -d 192.168.122.0/24 -p udp -j MASQUERADE --to-ports 1024-65535
-A POSTROUTING -s 192.168.122.0/24 ! -d 192.168.122.0/24 -j MASQUERADE
-A POSTROUTING -s 10.244.0.0/16 -d 10.244.0.0/16 -m comment --comment "flanneld masq" -j RETURN
-A POSTROUTING -s 10.244.0.0/16 ! -d 224.0.0.0/4 -m comment --comment "flanneld masq" -j MASQUERADE
-A POSTROUTING ! -s 10.244.0.0/16 -d 10.244.2.0/24 -m comment --comment "flanneld masq" -j RETURN
-A POSTROUTING ! -s 10.244.0.0/16 -d 10.244.0.0/16 -m comment --comment "flanneld masq" -j MASQUERADE
第六步:
第一条:创建自定义链;
第二条:如果这个请求没有对应的标记,那么RETURN返回到POSTROUTING链;
[root@node2 ~]# iptables -t nat -S KUBE-POSTROUTING
-N KUBE-POSTROUTING
-A KUBE-POSTROUTING -m mark ! --mark 0x4000/0x4000 -j RETURN
-A KUBE-POSTROUTING -j MARK --set-xmark 0x4000/0x0
-A KUBE-POSTROUTING -m comment --comment "kubernetes service traffic requiring SNAT" -j MASQUERADE

4、iptables 的clusterIP模式图解
5、iptables的NodePort模式
apiVersion: apps/v1
kind: Deployment
metadata:
name: demoapp
spec:
replicas: 3
selector:
matchLabels:
app: web
template:
metadata:
labels:
app: web
spec:
containers:
- name: webservers
image: oldxu3957/demoapp:v1.0
imagePullPolicy: IfNotPresent
ports:
- containerPort: 80
---
apiVersion: v1
kind: Service
metadata:
name: demoapp-svc
spec:
type: NodePort
selector:
app: web
ports:
- port: 80
targetPort: 80
nodePort: 32000
NodePort类型的service进行分析;Iptables规则:
PREROUTING -->FORWARD>POSTROUTING>interface
第一步:
所有经过PREROUTING链的请求,都会被拦截到KUBE-SERVICES自定义链上;
[root@node2 ~]# iptables -t nat -S PREROUTING
-P PREROUTING ACCEPT
-A PREROUTING -m comment --comment "kubernetes service portals" -j KUBE-SERVICES
-A PREROUTING -m addrtype --dst-type LOCAL -j DOCKER
第二步:
所有的规则都不会被匹配,但是会匹配最后一条规则,最后一条规则是跳转到KUBE-NODEPORTS这个自定义链中;
[root@node2 ~]# iptables -t nat -S KUBE-SERVICES
-N KUBE-SERVICES
-A KUBE-SERVICES -d 10.110.217.207/32 -p tcp -m comment --comment "default/demoapp-svc cluster IP" -m tcp --dport 80 -j KUBE-SVC-EHL433DY3T7P3MZN
-A KUBE-SERVICES -d 10.96.0.1/32 -p tcp -m comment --comment "default/kubernetes:https cluster IP" -m tcp --dport 443 -j KUBE-SVC-NPX46M4PTMTKRN6Y
-A KUBE-SERVICES -d 10.96.0.10/32 -p udp -m comment --comment "kube-system/kube-dns:dns cluster IP" -m udp --dport 53 -j KUBE-SVC-TCOU7JCQXEZGVUNU
-A KUBE-SERVICES -d 10.96.0.10/32 -p tcp -m comment --comment "kube-system/kube-dns:dns-tcp cluster IP" -m tcp --dport 53 -j KUBE-SVC-ERIFXISQEP7F7OF4
-A KUBE-SERVICES -d 10.96.0.10/32 -p tcp -m comment --comment "kube-system/kube-dns:metrics cluster IP" -m tcp --dport 9153 -j KUBE-SVC-JD5MR3NA4I4DYORP
-A KUBE-SERVICES -d 10.100.82.155/32 -p tcp -m comment --comment "kube-system/metrics-server:https cluster IP" -m tcp --dport 443 -j KUBE-SVC-Z4ANX4WAEWEBLCTM
-A KUBE-SERVICES -m comment --comment "kubernetes service nodeports; NOTE: this must be the last rule in this chain" -m addrtype --dst-type LOCAL -j KUBE-NODEPORTS
第三步:
如果请求的是节点的32000端口;那么则跳转到 KUBE-SVC-<HASH>
[root@node2 ~]# iptables -t nat -S KUBE-NODEPORTS
-N KUBE-NODEPORTS
-A KUBE-NODEPORTS -p tcp -m comment --comment "default/demoapp-svc" -m tcp --dport 32000 -j KUBE-SVC-EHL433DY3T7P3MZN
第四步:
如果来源不是Pod的地址端,但是请求的是Service的IP,ClusterIP,目标端口是80,那么则跳转KUBE-MARK-MASQ 这个自定义链进行打标记;
如果请求的是节点的32000端口,那么则跳转到KUBE-MARK-MASQ这个自定义链,进行打标记 (0x4000/0x4000)
[root@node2 ~]# iptables -t nat -S KUBE-SVC-EHL433DY3T7P3MZN
-N KUBE-SVC-EHL433DY3T7P3MZN
-A KUBE-SVC-EHL433DY3T7P3MZN ! -s 10.244.0.0/16 -d 10.110.217.207/32 -p tcp -m comment --comment "default/demoapp-svc cluster IP" -m tcp --dport 80 -j KUBE-MARK-MASQ
-A KUBE-SVC-EHL433DY3T7P3MZN -p tcp -m comment --comment "default/demoapp-svc" -m tcp --dport 32000 -j KUBE-MARK-MASQ
-A KUBE-SVC-EHL433DY3T7P3MZN -m comment --comment "default/demoapp-svc" -m statistic --mode random --probability 0.33333333349 -j KUBE-SEP-SI5EEDPDQ7NVQF2Y
-A KUBE-SVC-EHL433DY3T7P3MZN -m comment --comment "default/demoapp-svc" -m statistic --mode random --probability 0.50000000000 -j KUBE-SEP-O7GW75MMOH2ZK4J5
-A KUBE-SVC-EHL433DY3T7P3MZN -m comment --comment "default/demoapp-svc" -j KUBE-SEP-ZOJBNUN3LSLJECDO
[root@node2 ~]# iptables -t nat -S KUBE-MARK-MASQ
-N KUBE-MARK-MASQ
-A KUBE-MARK-MASQ -j MARK --set-xmark 0x4000/0x4000
第五步:
直接进行DNAT操作;
[root@node2 ~]# iptables -t nat -S KUBE-SEP-O7GW75MMOH2ZK4J5
-N KUBE-SEP-O7GW75MMOH2ZK4J5
-A KUBE-SEP-O7GW75MMOH2ZK4J5 -s 10.244.2.65/32 -m comment --comment "default/demoapp-svc" -j KUBE-MARK-MASQ
-A KUBE-SEP-O7GW75MMOH2ZK4J5 -p tcp -m comment --comment "default/demoapp-svc" -m tcp -j DNAT --to-destination 10.244.2.65:80
第六步:
所有流经FORWARD这个链中的报文,都必须先到KUBE-FORWARD自定义链中;
[root@node2 ~]# iptables -S FORWARD
-P FORWARD ACCEPT
-A FORWARD -m comment --comment "kubernetes forwarding rules" -j KUBE-FORWARD
第七步:
所有流经POSTROUTING这个链中的报文,都必须先到KUBE-POSTROUTING自定义链中;
[root@node2 ~]# iptables -t nat -S POSTROUTING
-P POSTROUTING ACCEPT
-A POSTROUTING -m comment --comment "kubernetes postrouting rules" -j KUBE-POSTROUTING
-A POSTROUTING -s 172.17.0.0/16 ! -o docker0 -j MASQUERADE
-A POSTROUTING -s 192.168.122.0/24 -d 224.0.0.0/24 -j RETURN
-A POSTROUTING -s 192.168.122.0/24 -d 255.255.255.255/32 -j RETURN
-A POSTROUTING -s 192.168.122.0/24 ! -d 192.168.122.0/24 -p tcp -j MASQUERADE --to-ports 1024-65535
-A POSTROUTING -s 192.168.122.0/24 ! -d 192.168.122.0/24 -p udp -j MASQUERADE --to-ports 1024-65535
-A POSTROUTING -s 192.168.122.0/24 ! -d 192.168.122.0/24 -j MASQUERADE
-A POSTROUTING -s 10.244.0.0/16 -d 10.244.0.0/16 -m comment --comment "flanneld masq" -j RETURN
-A POSTROUTING -s 10.244.0.0/16 ! -d 224.0.0.0/4 -m comment --comment "flanneld masq" -j MASQUERADE
-A POSTROUTING ! -s 10.244.0.0/16 -d 10.244.2.0/24 -m comment --comment "flanneld masq" -j RETURN
-A POSTROUTING ! -s 10.244.0.0/16 -d 10.244.0.0/16 -m comment --comment "flanneld masq" -j MASQUERADE
第八步:
[root@node2 ~]# iptables -t nat -S KUBE-POSTROUTING
-N KUBE-POSTROUTING
-A KUBE-POSTROUTING -m mark ! --mark 0x4000/0x4000 -j RETURN
-A KUBE-POSTROUTING -j MARK --set-xmark 0x4000/0x0
-A KUBE-POSTROUTING -m comment --comment "kubernetes service traffic requiring SNAT" -j MASQUERADE
十、IPVS模型分析
1、会在每个节点上创建一个名为kube-ipvs0的虚拟接口,并将集群所有Service对象的ClusterIP都配置在该接口:2、Kube-Proxy将每个Service生成一个虚拟服务器VirtualServer的定义;
注意:ipvs仅需要借助极少量的iptables规则完成源地址转换、源端口转换等;
1、设置集群为IPVS模式
1.1 修改ipvs模式
kubectl edit configmaps kube-proxy -n kube-system
ipvs:
excludeCIDRs: null
minSyncPeriod: 0s
scheduler: ""
strictARP: false
syncPeriod: 0s
tcpFinTimeout: 0s
tcpTimeout: 0s
udpTimeout: 0s
kind: KubeProxyConfiguration
metricsBindAddress: ""
mode: "ipvs" #指定ipvs规则
1.2、删除kube-proxy的pod,重启kube-proxy
kubectl delete pod $(kubectl get pod -n kube-system | grep proxy | awk '{print $1}') -n kube-system
kubectl delete pod $(kubectl get pod -l k8s-app=kube-proxy -n kube-system | awk 'NR>1 {print $1}') -n kube-system
# 只删除第2和第三个pod
kubectl delete pod $(kubectl get pod -l k8s-app=kube-proxy -n kube-system | awk 'NR==3 || NR==4 {print $1}') -n kube-system
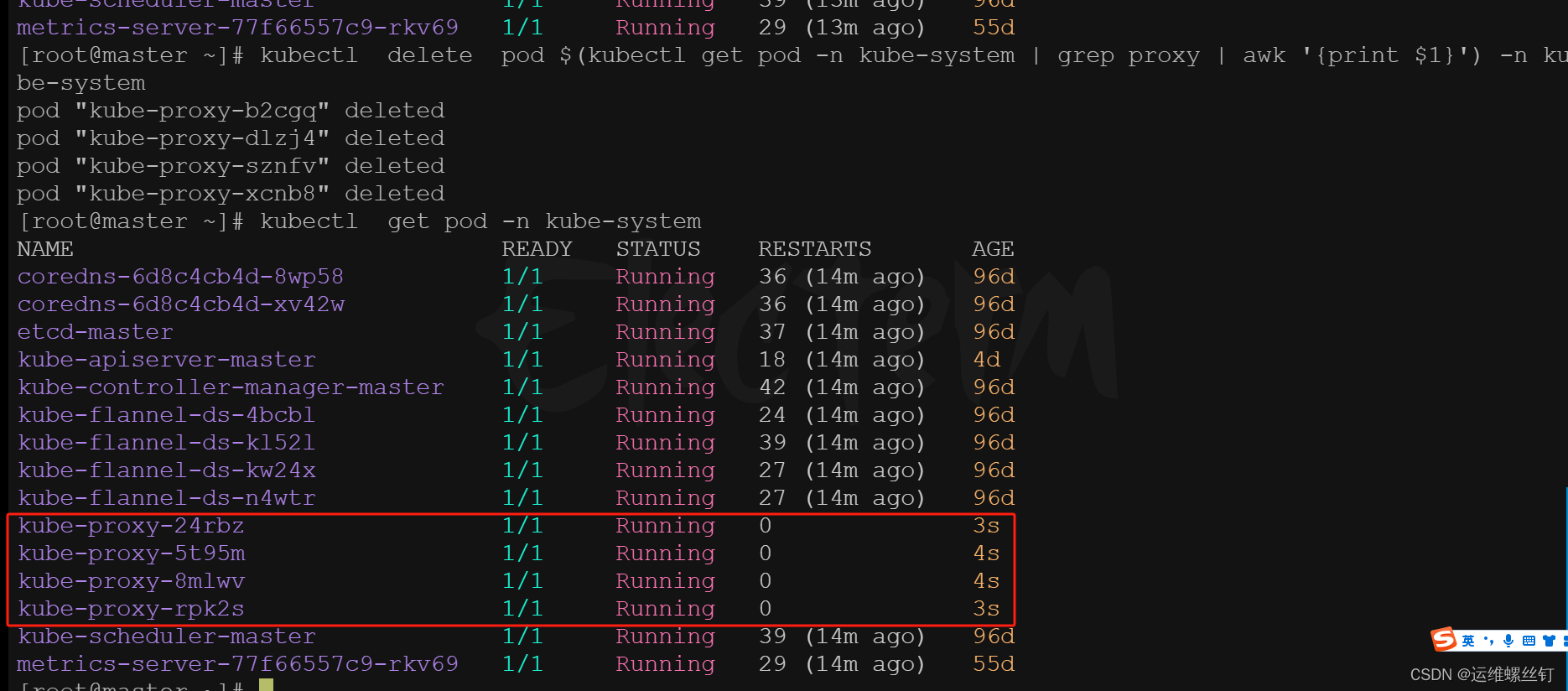
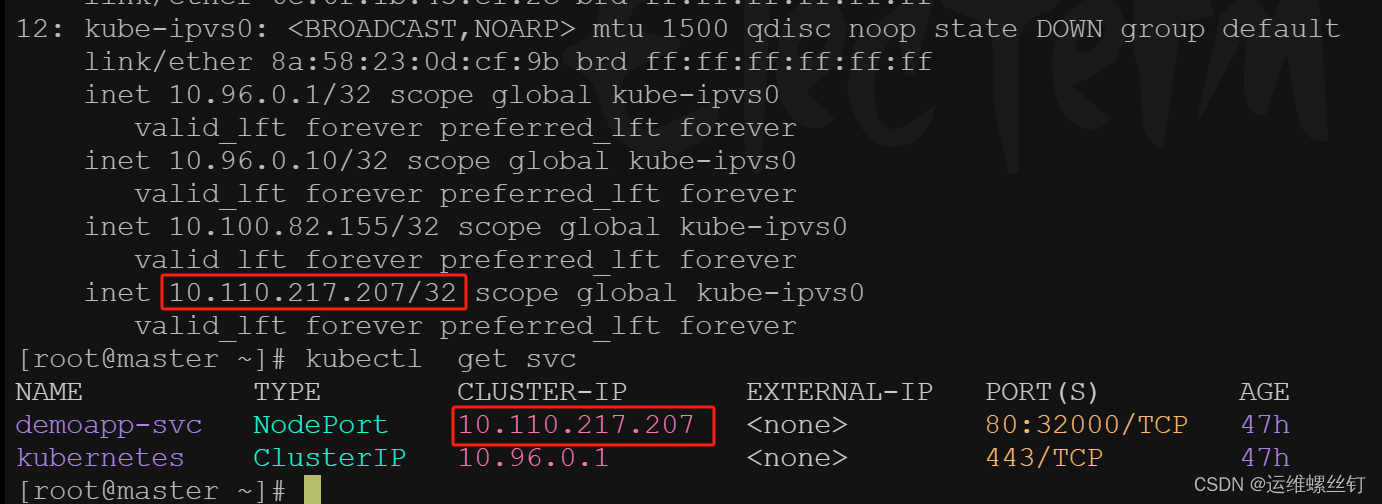
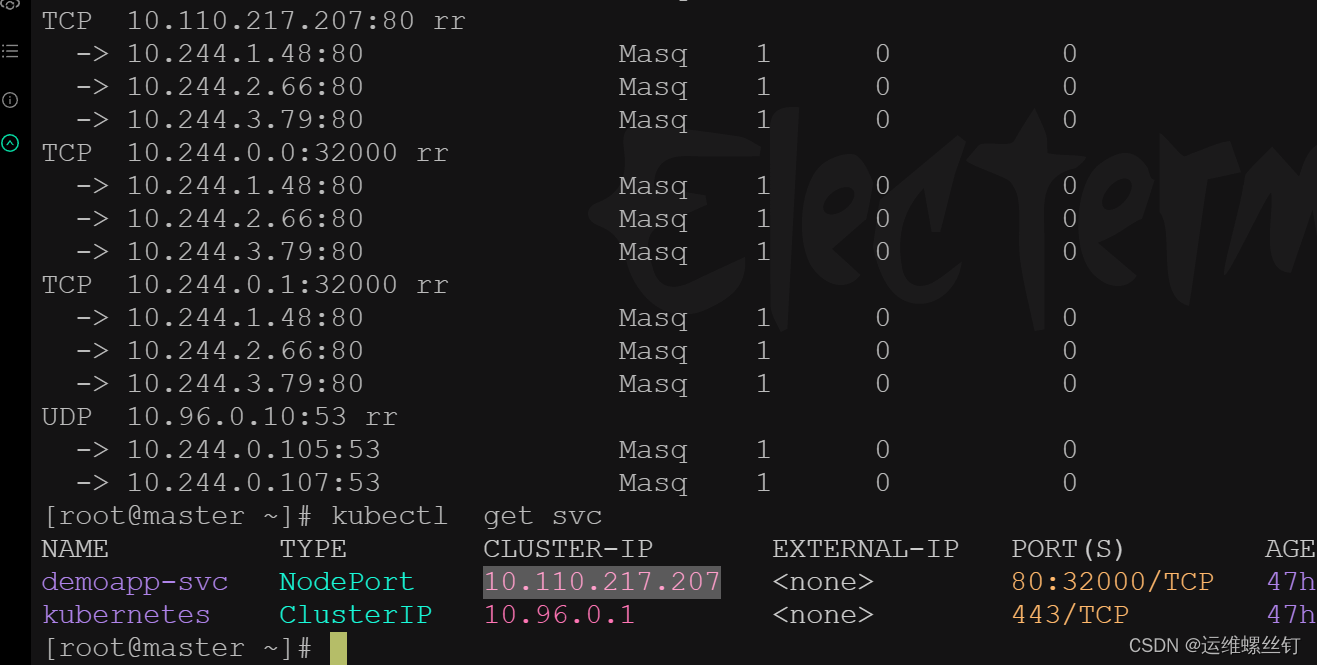
1.3 IPVS 规则查看
## 全部规则查看
ipvsadm -L -n
## IPVS的映射网卡查看
ip a s ## 查看网卡
kubect get svc ## 查看svc
如图所示,正式映射关系
十一、服务发现
当Pod需要访问Service时,通过Service提供的ClusterIP就可以实现了,但是有几个问题;
1、Service的IP不稳定,删除重建会发生变化;
2、ServiceIP难以记忆,如果能通过一个固定的名称访问就好了;
为了解决这样的问题,Kubernetes引入了环境变量和DNS两种方案来解决这样的问题;
1、环境变量方式:通过特定的名称将环境变量注入到Pod内部;
2、DNS方式:通过APIServer来监视Service变动,而后动态创建对应Service名称与ServiceIP的域名解析记录;
1、环境变量
每个 Pod 启动的时候,会通过环境变量的方式将Service的IP以及Port信息注入进去,这样 Pod 中的应用可以通过读取环境变量来获取对应Service服务的地址信息,这种方法使用起来相对简单,但是也存在一定的问题。就是Pod所依赖的Service必须优Pod启动,否则无法注入到环境变量中。
kubectl run tools --image=registry.cn-hangzhou.aliyuncs.com/mokeyking/k8s-oldxu:tools-latest

kubectl exec -it tools -- /bin/bash
env | grep -i demoapp_svc
ping ${DEMOAPP_SVC_SERVICE_HOST}

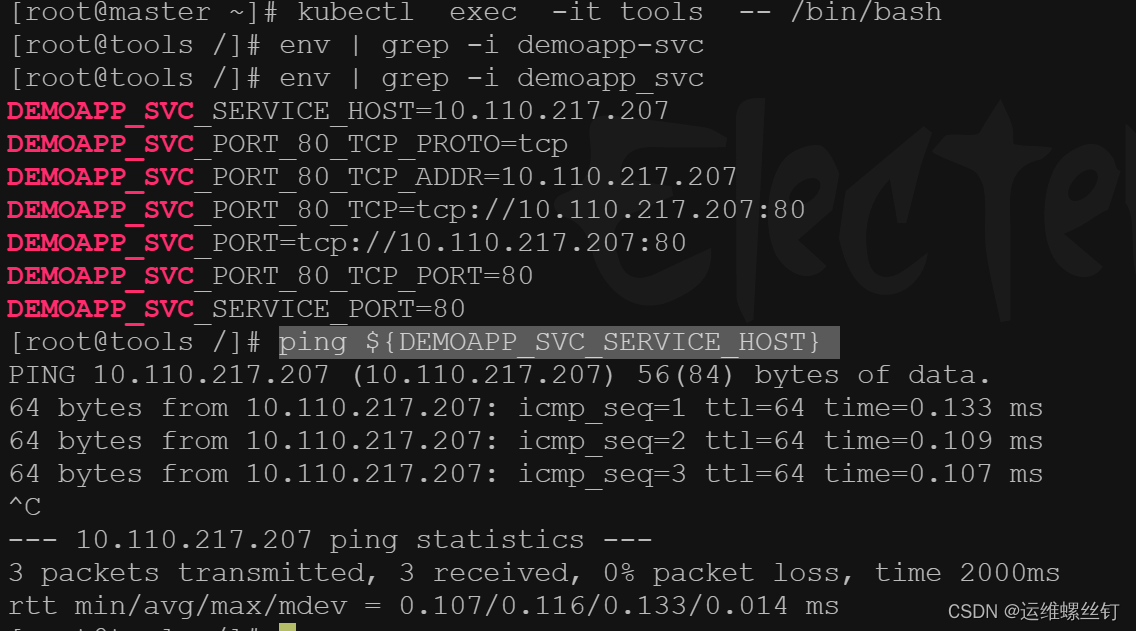
在创建一个svc。pod就无法获取到svc的环境变量
apiVersion: v1
kind: Service
metadata:
name: env-svc
spec:
selector:
app: web
ports:
- port: 80
targetPort: 80
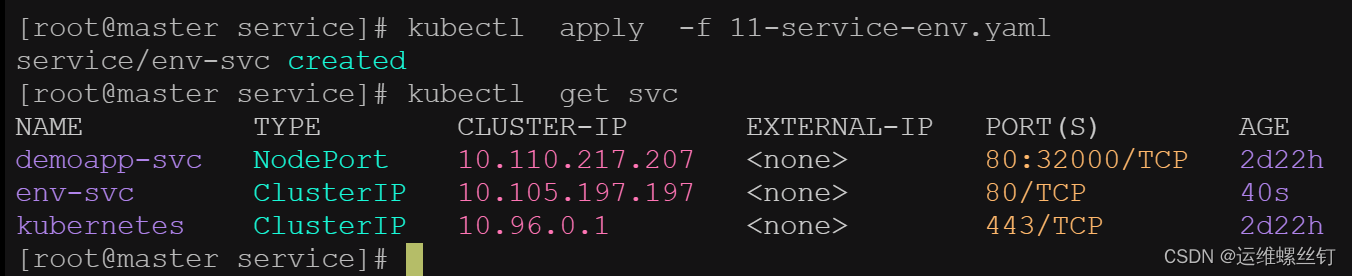
pod无法获取新创建的svc的环境变量信息
但是再新创建一个pod就会能或者svc的变量信息
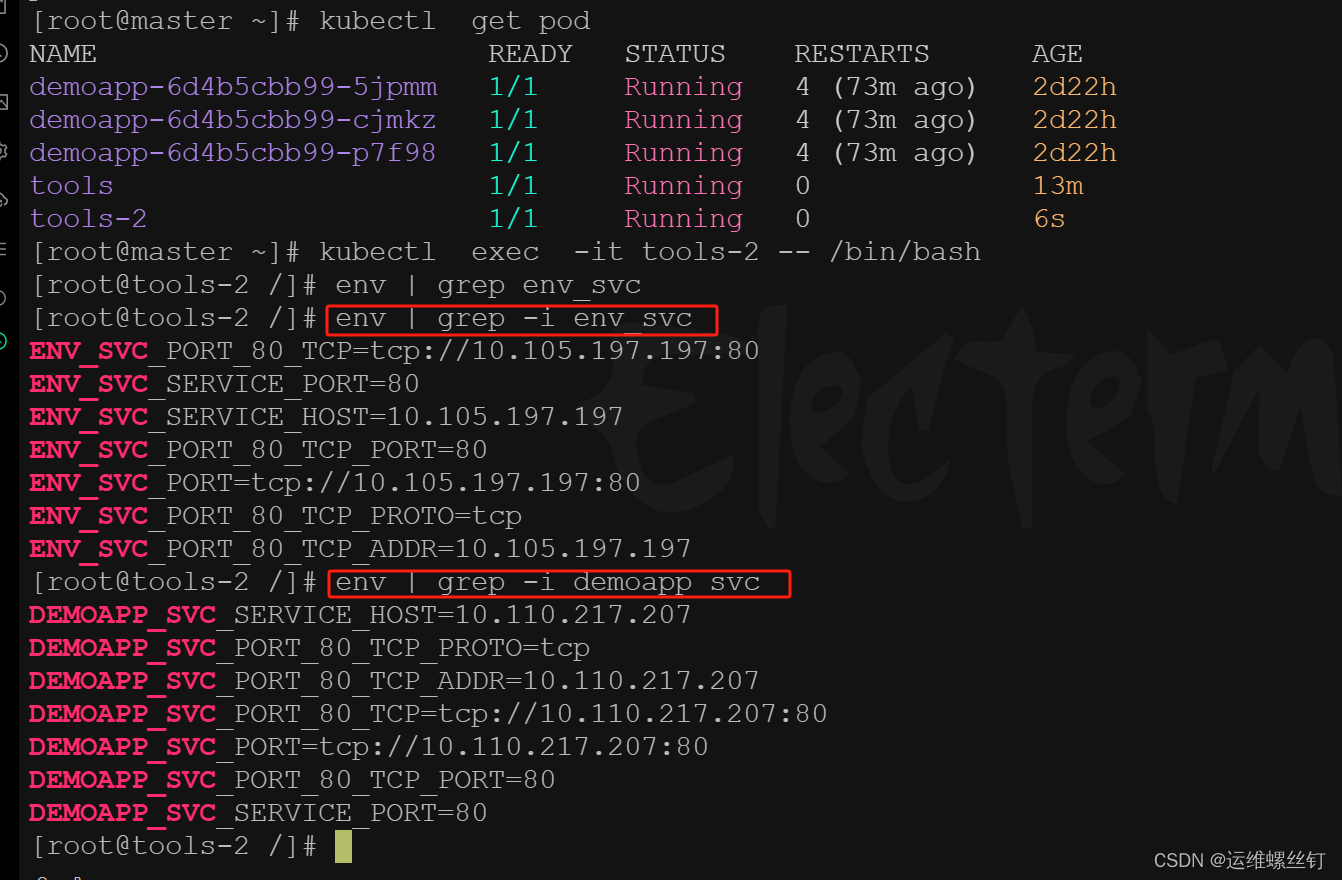
重新创建一个pod,能够或者两个svc的环境变量,这就是环境变量的作用
2、CoreDNS
在安装Kubernetes集群时,CoreDNS作为附加组件,用来为Pod提供DNS域名解析。CoreDNS监视 Kubernetes API 中的新Service,并为每个Service名称创建一组 DNS 记录。这样我们就可以通过固定的Service名称来转换出不固定的ServiceIP
了解CoreDNS的配置
[root@master service]# kubectl get configmap -n kube-system ## 查看所有的配置信息
NAME DATA AGE
coredns 1 97d
extension-apiserver-authentication 6 97d
kube-flannel-cfg 2 97d
kube-proxy 2 97d
kube-root-ca.crt 1 97d
kubeadm-config 1 97d
kubelet-config-1.23 1 97d
[root@master service]# kubectl get configmaps coredns -n kube-system -o yaml
apiVersion: v1
data:
Corefile: |
.:53 {
errors ## 错误记录
health { ## 监控检查
lameduck 5s
}
ready
kubernetes cluster.local in-addr.arpa ip6.arpa { ## 用于解析kubernetes集群内域名
pods insecure
fallthrough in-addr.arpa ip6.arpa
ttl 30
}
prometheus :9153 ## 监控端口
forward . /etc/resolv.conf { # 如果请求非Kubernetes域名,则由节点的resolv.conf中dns解析
max_concurrent 1000
}
cache 30 # 缓存所有内容
loop
reload # 支持热更新
loadbalance # 负载均衡,默认轮询
}
kind: ConfigMap
metadata:
creationTimestamp: "2023-12-15T16:08:05Z"
name: coredns
namespace: kube-system
resourceVersion: "233"
uid: 6fe29dab-17db-45f6-a7eb-70a08724337b
默认的域名解析配置
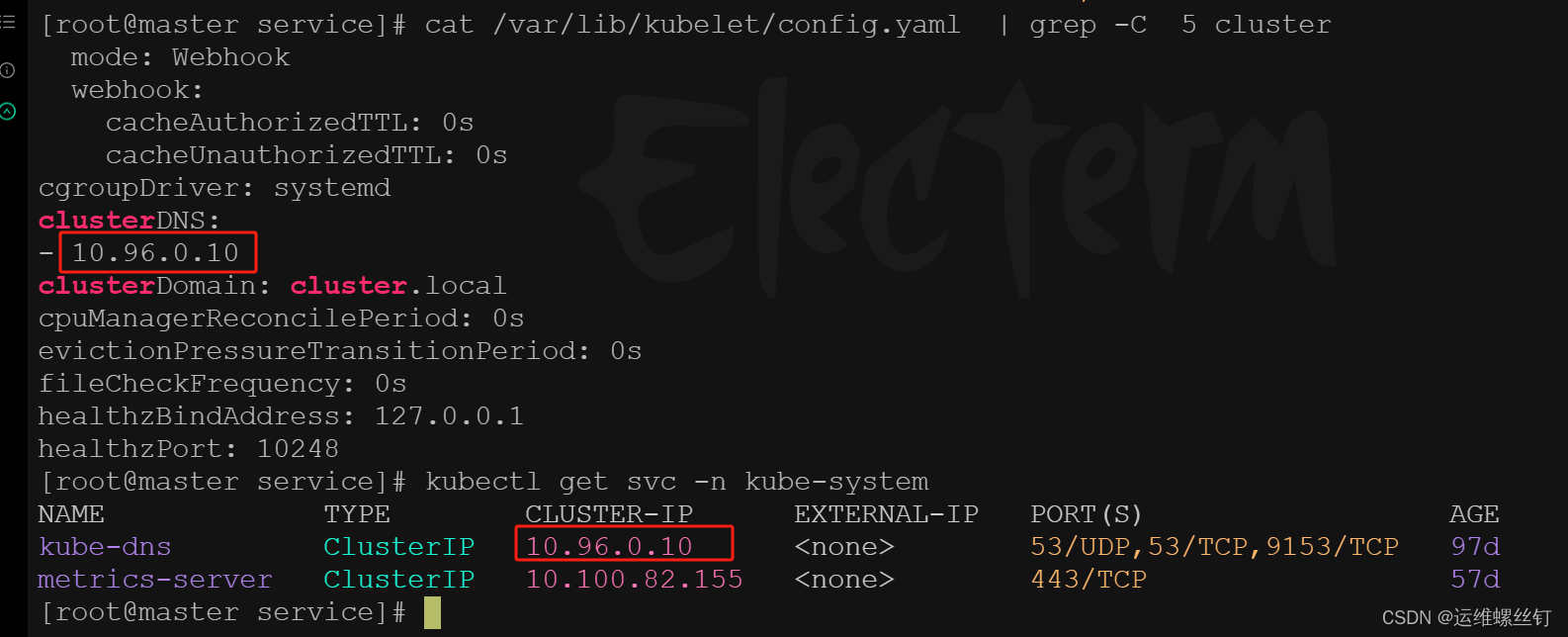


解析svc域名

总结:可以解析到对应的svcIP
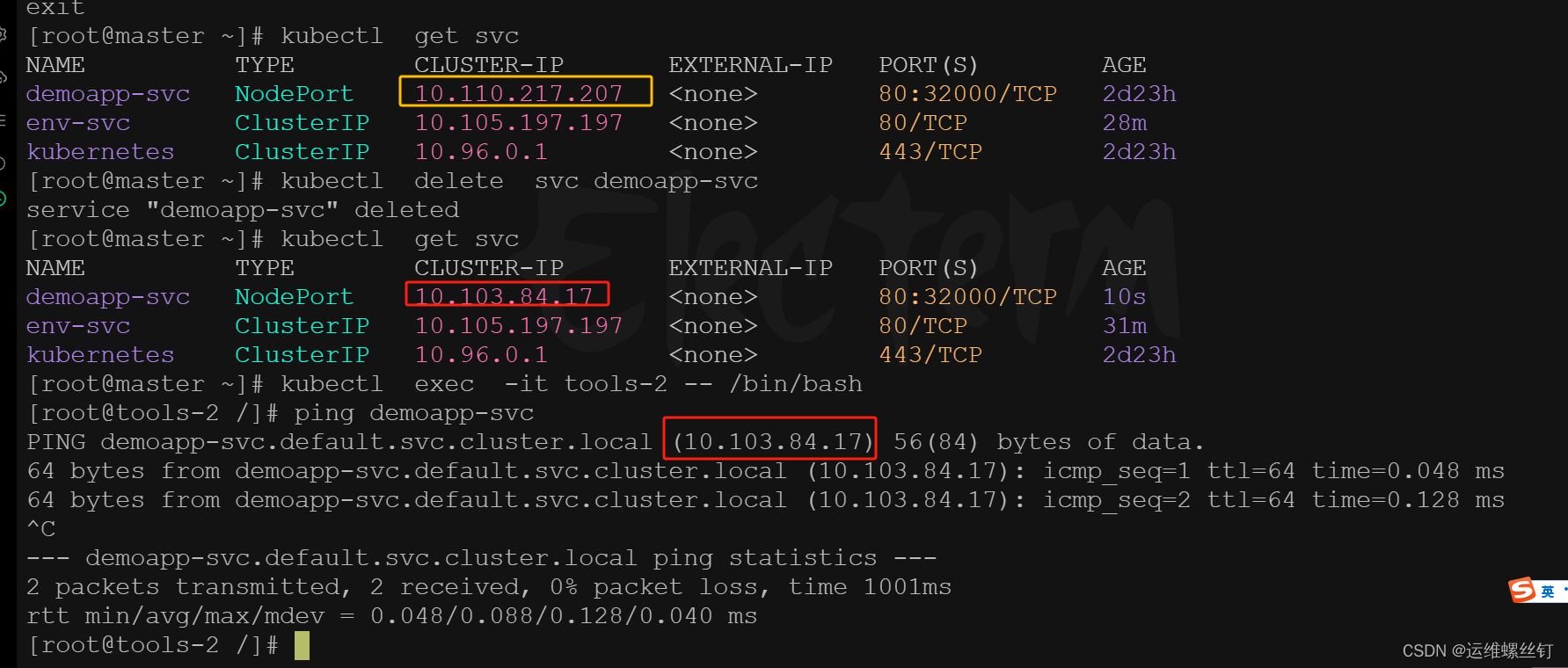
总结:删除svc时,svc的ip就会发生变化,但是重新对svc的域名进行解析,仍然能够解析到svc的ip。只要service的名称不发生变化,就可以正常解析,所有可以将这个注入到pod的中,就可以解析svc的配置。这个DNS是通过cordDNS进行转发解析的。

十二、CordDNS策略
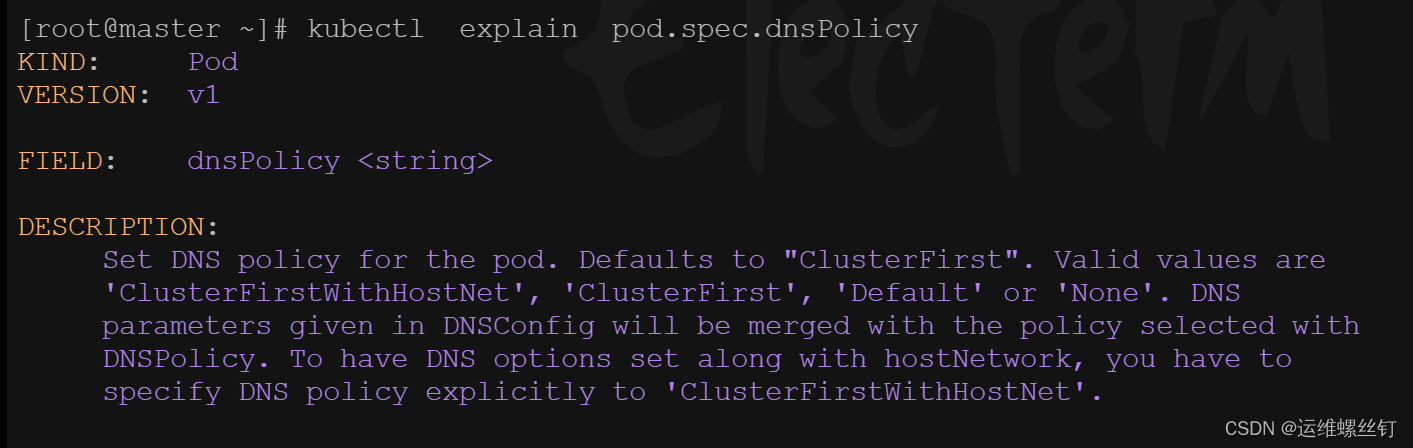
DNS策略可以单独对Pod进行设定,在创建Pod时可以为其指定DNS的策略,最终配置会落在Pod的/etc/resolv.conf文件中,可以通过pod.spec.dnsPolicy字段设置DNS的策略
1、ClusterFirst(默认DNS策略)
表示Pod内的DNS使用集群中配置的DNS服务,简单来说就是使用Kubernetes 中的 coredns 服务进行域名解析。如果解析不成功,会使用当前Pod所在的宿主机 DNS 进行解析。
apiVersion: v1
kind: Pod
metadata:
name: pod-example-1
spec:
dnsPolicy: ClusterFirst
containers:
- name: tools
image: registry.cn-hangzhou.aliyuncs.com/mokeyking/k8s-oldxu:tools-latest
ports:
- containerPort: 8899
查看pod的DNS的策略
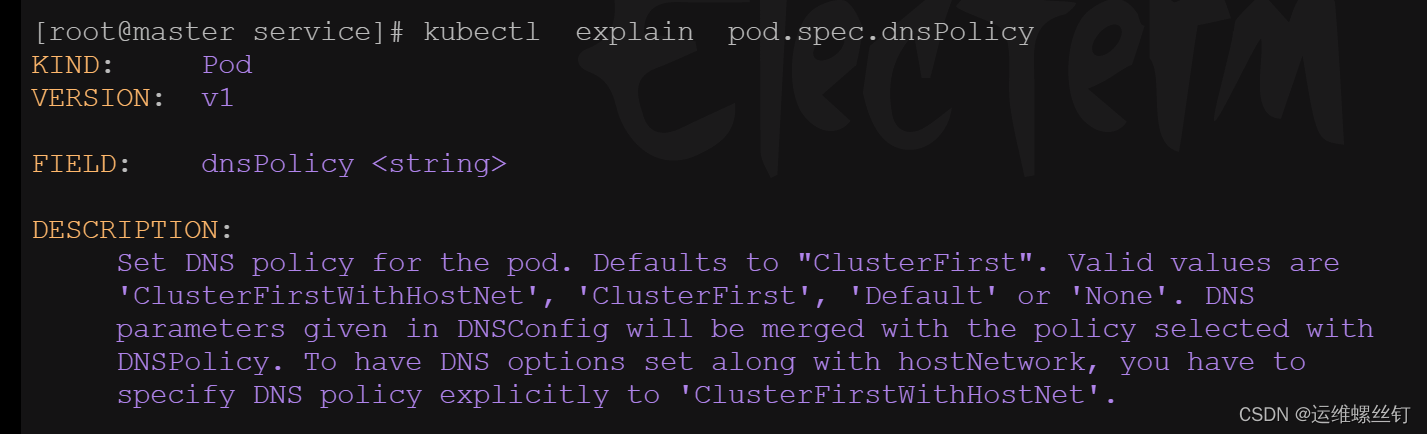
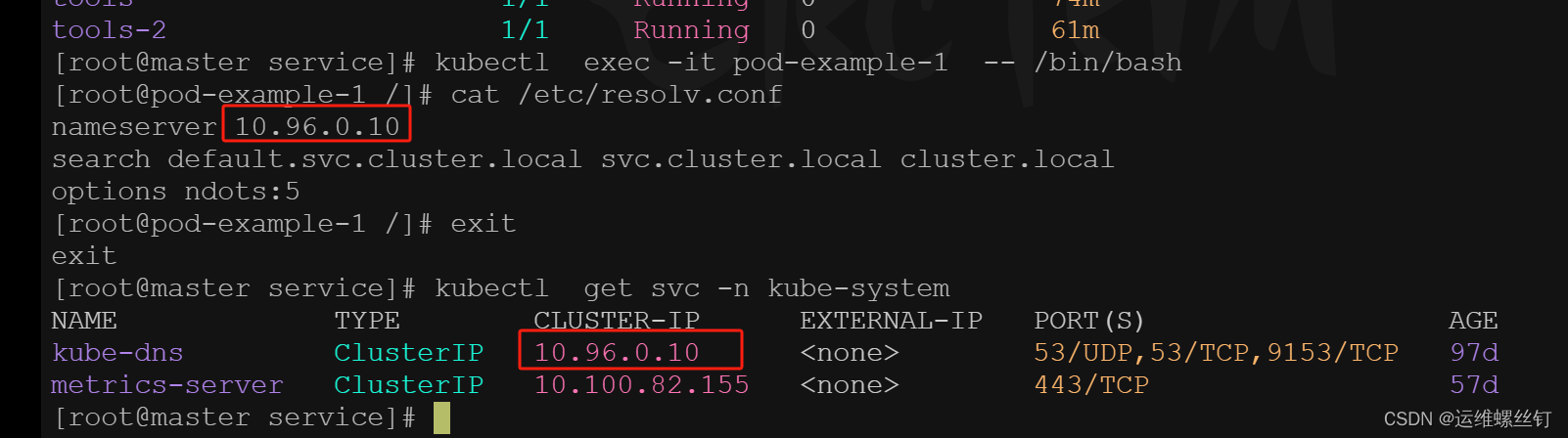
总结: 使用默认DNS解析
2、ClusterFirstWithHostNet
在某些场景下,我们的 Pod 是用 HostNetwork 模式启动的,一旦使用 HostNetwork 模式,那该Pod则会使用当前宿主机的/etc/resolv.conf来进行 DNS 查询,但如果任然想继续使用Kubernetes的DNS服务,那就将 dnsPolicy设置为ClusterFirstWithHostNet
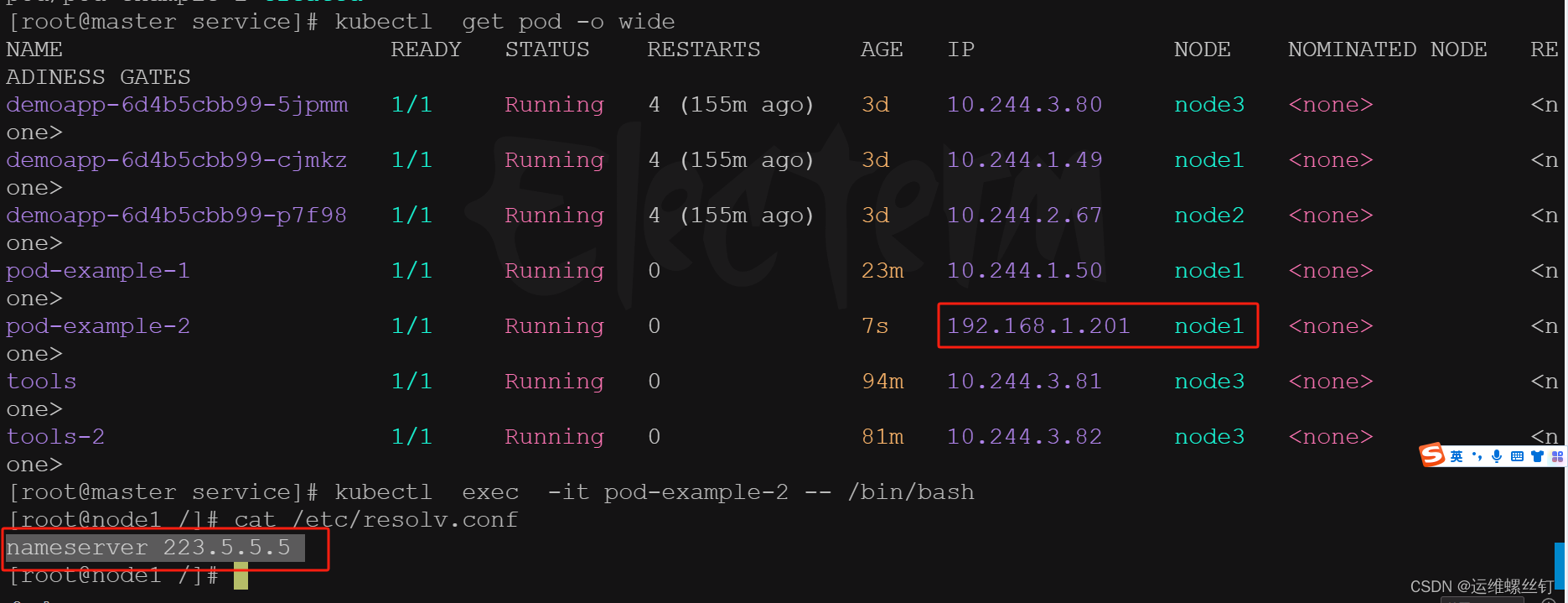
- 为了方便验证,将三个node的主机域名解析都缓存不一样的的
vim /etc/resolv.conf
### node1
nameserver 233.5.5.5
### node2
nameserver 233.6.6.6
### node3
nameserver 114.114.114.114
apiVersion: v1
kind: Pod
metadata:
name: pod-example-2
spec:
hostNetwork: true ## 与主机共享网络
dnsPolicy: ClusterFirst
containers:
- name: tools
image: registry.cn-hangzhou.aliyuncs.com/mokeyking/k8s-oldxu:tools-latest
imagePullPolicy: IfNotPresent
ports:
- containerPort: 8899
- 通过指定node标签,让pod创建到指定的node上
kubectl get node --show-labels
apiVersion: v1
kind: Pod
metadata:
name: pod-example-2
spec:
hostNetwork: true
dnsPolicy: ClusterFirst
containers:
- name: tools
image: registry.cn-hangzhou.aliyuncs.com/mokeyking/k8s-oldxu:tools-latest
imagePullPolicy: IfNotPresent
ports:
- containerPort: 8899
nodeSelector:
kubernetes.io/hostname: node2
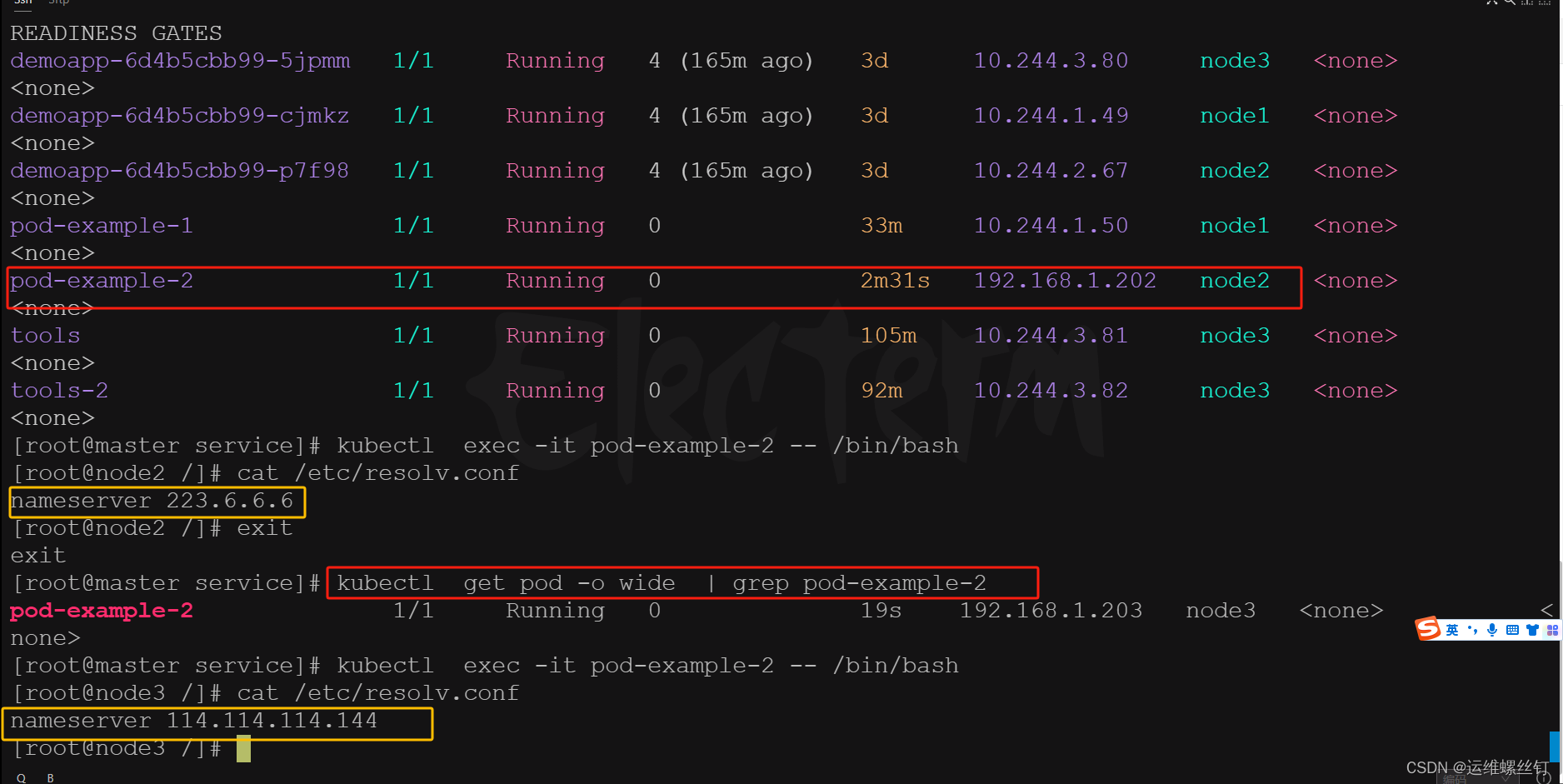
通过指定不的node便签进行创建pod,可以看到共享不同pod主机域名解析
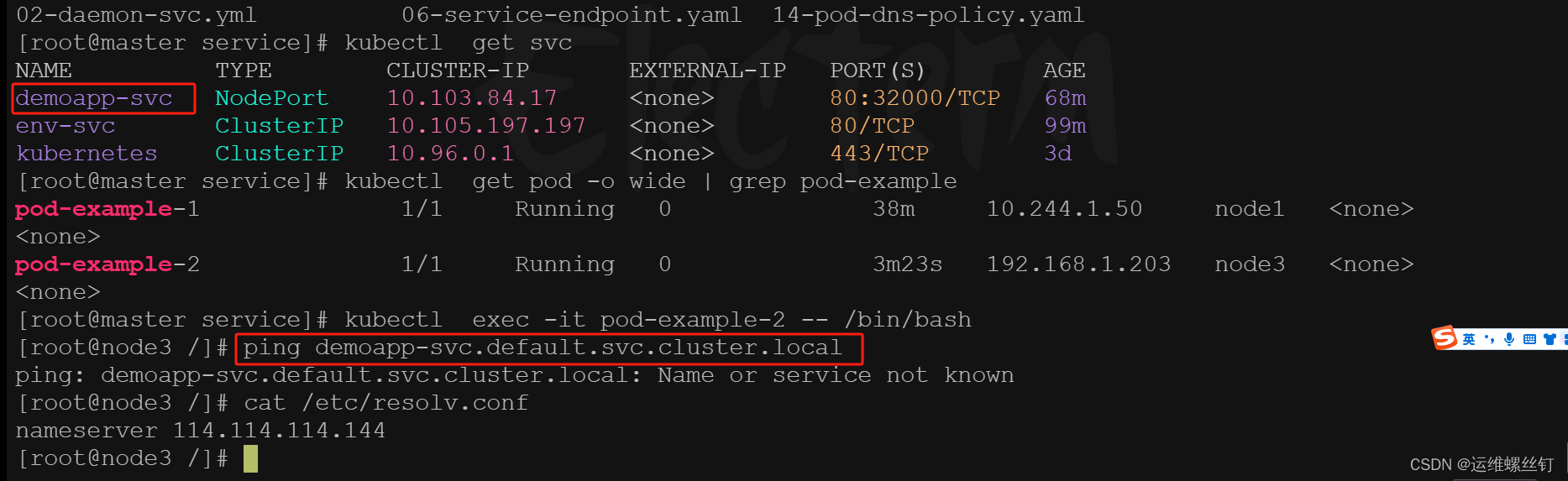 pod无法通过svc进行解析,可以dnsPolicy规则改为ClusterFirstWithHostNet
pod无法通过svc进行解析,可以dnsPolicy规则改为ClusterFirstWithHostNet
apiVersion: v1
kind: Pod
metadata:
name: pod-example-2
spec:
hostNetwork: true ## 共享主机网络
dnsPolicy: ClusterFirstWithHostNet ## 如果配置了首要配置kubernetes的域名解析
containers:
- name: tools
image: registry.cn-hangzhou.aliyuncs.com/mokeyking/k8s-oldxu:tools-latest
imagePullPolicy: IfNotPresent
ports:
- containerPort: 8899
nodeSelector:
kubernetes.io/hostname: node3
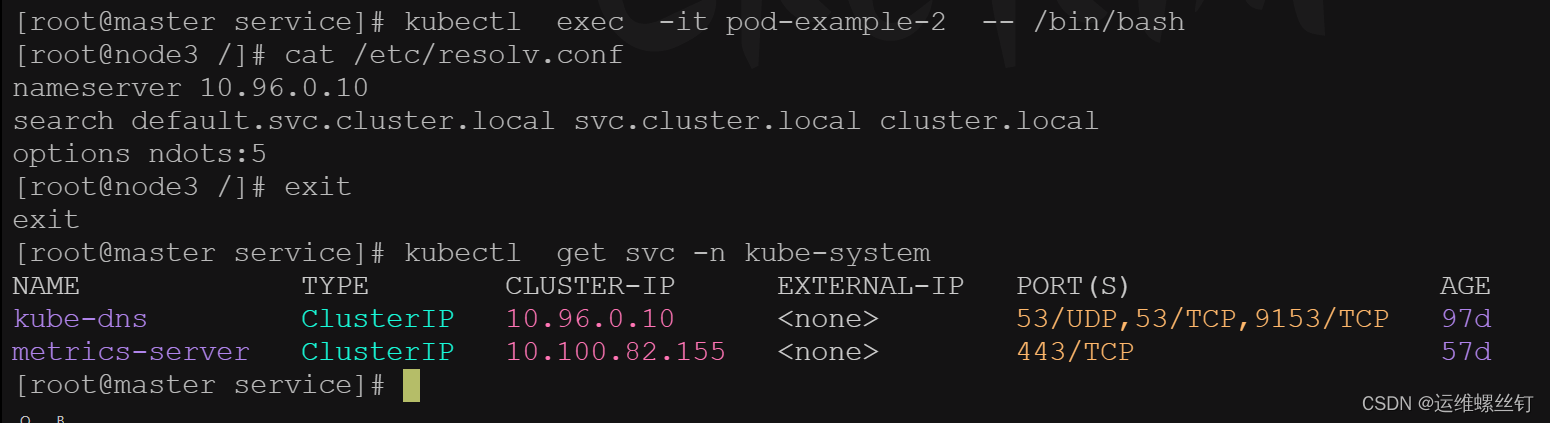
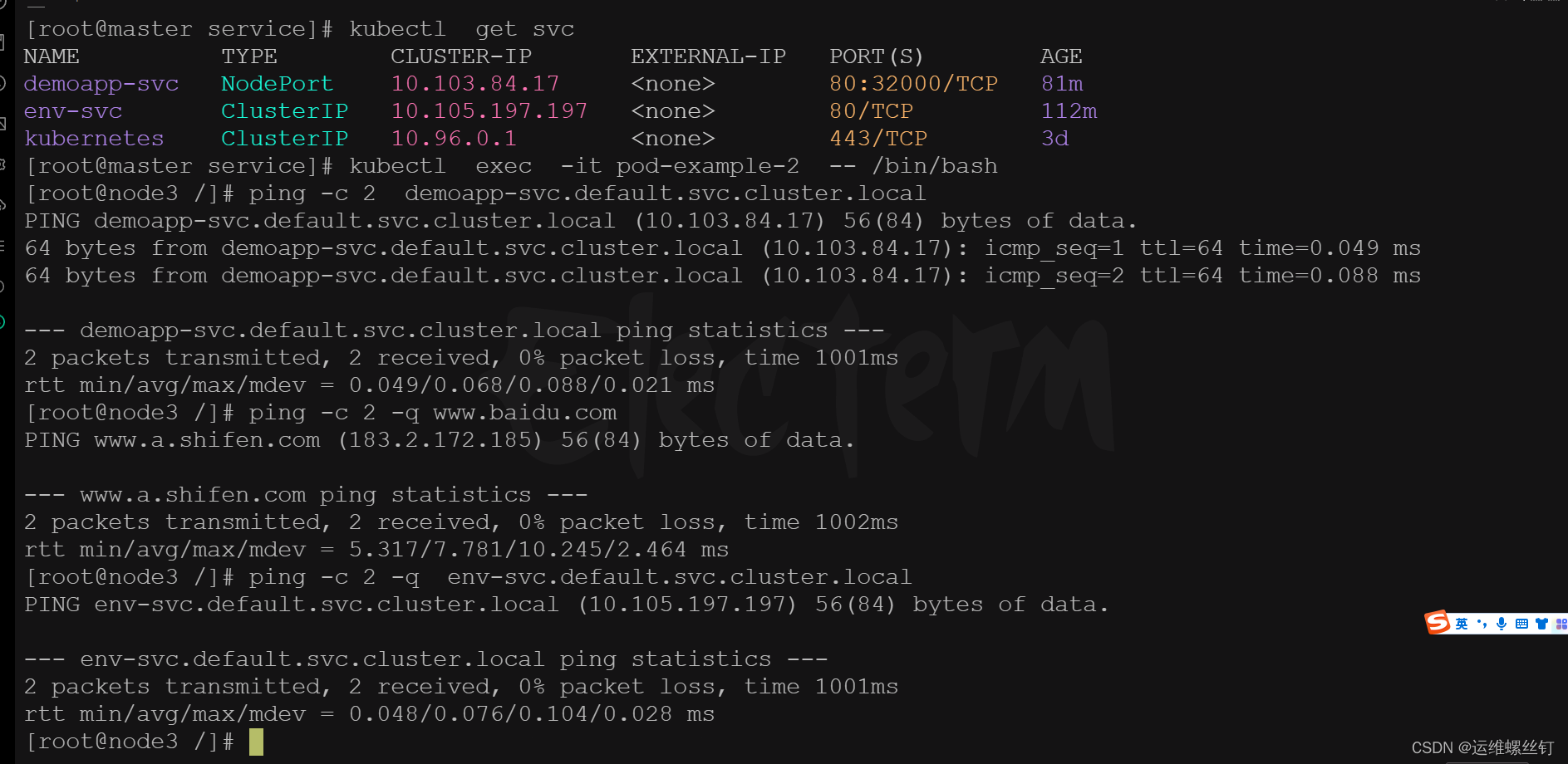
- 这个ClusterFirstWithHostNet策略也适用deployment

- 编写deployment的资源清单
apiVersion: apps/v1
kind: Deployment
metadata:
name: demoapp
spec:
replicas: 3
selector:
matchLabels:
app: web
template:
metadata:
labels:
app: web
spec:
hostNetwork: true
dnsPolicy: ClusterFirst
containers:
- name: webservers
image: oldxu3957/demoapp:v1.0
imagePullPolicy: IfNotPresent
ports:
- containerPort: 80
---
apiVersion: v1
kind: Service
metadata:
name: demoapp-svc
spec:
type: NodePort
selector:
app: web
ports:
- port: 80
targetPort: 80
nodePort: 32000

域名解析能解析到node3的主机 /etc/resolv.conf
3、default
默认使用宿主机的 /etc/resolv.conf但可以使用 kubelet 的 --resolv-conf=/etc/resolv.conf 来指定 DNS 解析文件地址。
- 使用默认主机的 /etc/resolv.conf
apiVersion: v1
kind: Pod
metadata:
name: pod-example-3
spec:
dnsPolicy: Default
containers:
- name: tools
image: registry.cn-hangzhou.aliyuncs.com/mokeyking/k8s-oldxu:tools-latest
ports:
- containerPort: 8899
nodeSelector:
kubernetes.io/hostname: node3
使用了node3的 /etc/resolv.conf 的默认主机名认证

- 使用node节点的指定路径的域名解析的文件,使用主机挂载方式
apiVersion: v1
kind: Pod
metadata:
name: pod-example-6
spec:
containers:
- name: tools
image: registry.cn-hangzhou.aliyuncs.com/mokeyking/k8s-oldxu:tools-latest
imagePullPolicy: IfNotPresent
volumeMounts:
- name: resolv-conf
mountPath: /etc/resolv.conf
readOnly: true
dnsPolicy: Default
dnsConfig:
options:
- name: ndots
value: "2"
volumes:
- name: resolv-conf
hostPath:
path: /root/resolv.conf
nodeSelector:
kubernetes.io/hostname: node3
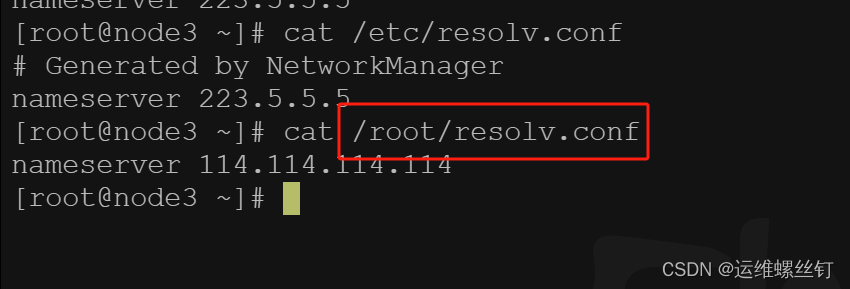
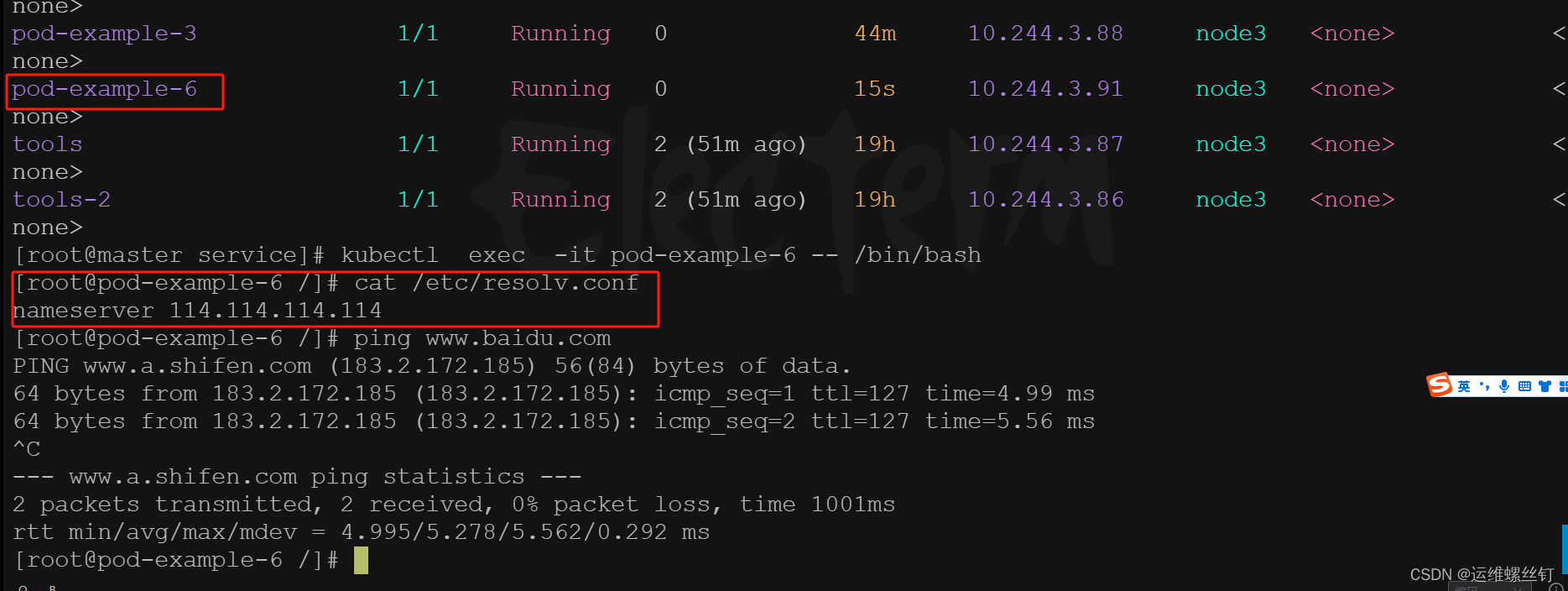
- 将域名添加到,并执行域名解析的ip,我特定的域名地址
apiVersion: v1
kind: Pod
metadata:
name: pod-example-4
spec:
containers:
- name: tools
image: registry.cn-hangzhou.aliyuncs.com/mokeyking/k8s-oldxu:tools-latest
dnsPolicy: Default
dnsConfig:
nameservers:
- 10.0.0.1
- 10.0.0.2
searches:
- /etc/resolv.conf
- otherdomain.svc.cluster.local
nodeSelector:
kubernetes.io/hostname: node2

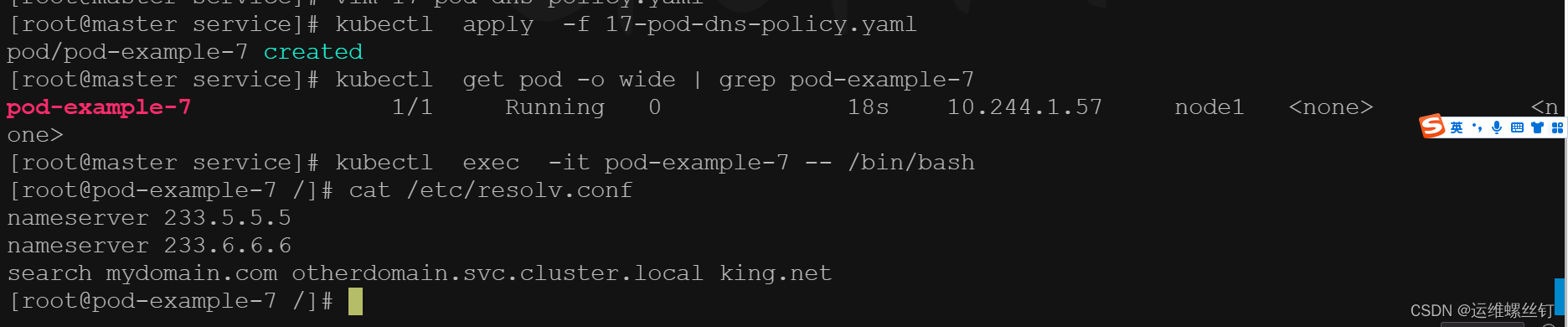
4、Node
空的DNS设置,这种方式一般用于自定义 DNS 配置的场景,往往需要和dnsConfig一起使用才可以达到自定义DNS的目的。
apiVersion: v1
kind: Pod
metadata:
name: pod-example-7
spec:
containers:
- name: tools
image: registry.cn-hangzhou.aliyuncs.com/mokeyking/k8s-oldxu:tools-latest
imagePullPolicy: IfNotPresent
dnsPolicy: None
dnsConfig:
nameservers:
- 233.5.5.5
- 233.6.6.6
searches:
- mydomain.com
- otherdomain.svc.cluster.local
- king.net
nodeSelector:
kubernetes.io/hostname: node1
十三、HeadLess Service
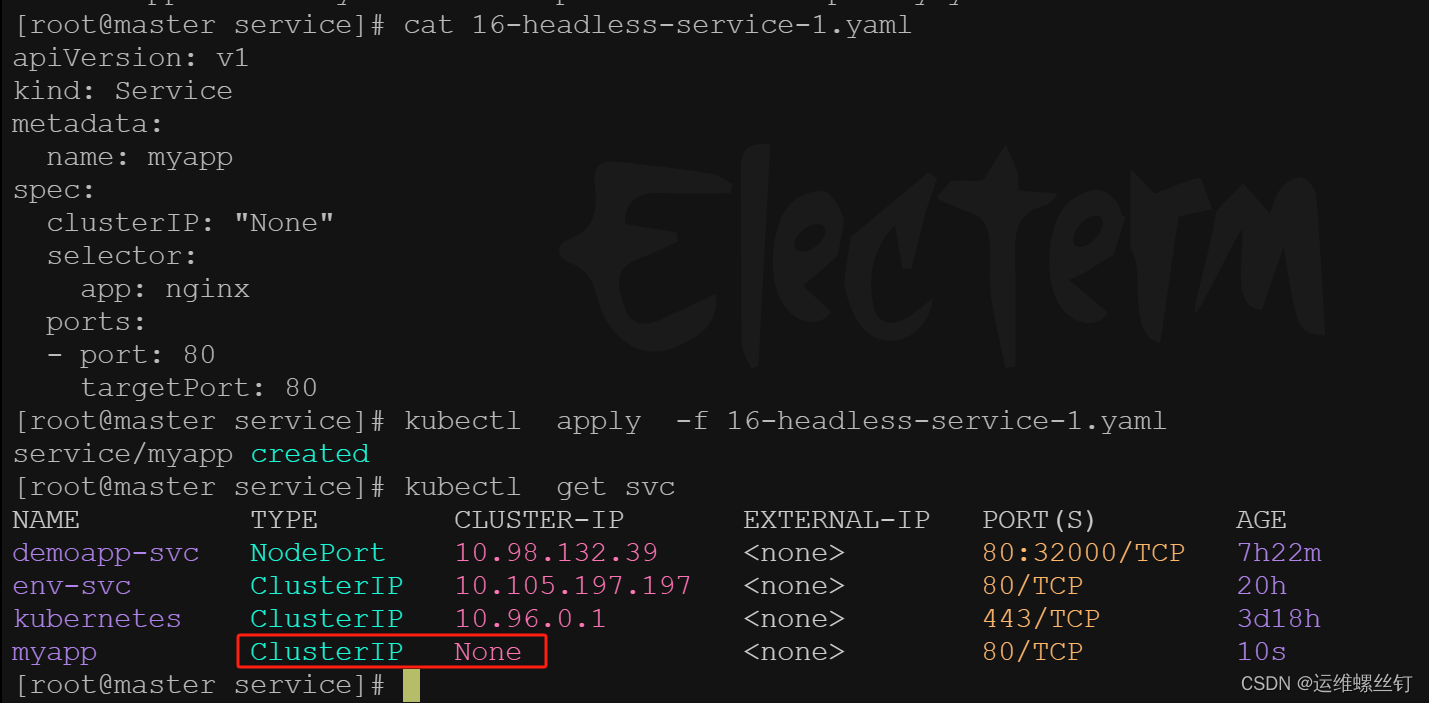
1、什么是HeadLess
HeadlessService也叫无头服务,就是创建的Service没有ClusterIP,而是为Service所匹配的每个Pod都创建一条DNS的解析记录,这样每个Pod都有一个唯一的DNS名称标识身份,访问的格式如下

2、HeadLess的作用
像 elasticsearch,mongodb,kafka 等分布式服务,在做集群初始化时,配置文件中要写上集群中所有节点的IP(或是域名)但Pod是没有固定IP的,所以配置文件里写DNS名称是最合适的。
那为什么不用Service,因为 Service 作为 Pod 前置的负载均衡一般是为一组相同的后端 Pod 提供访问入口,而且 Service的selector也没有办法区分同一组Pod的不同身份。
但是我们可以使用 Statefulset控制器,它在创建每个Pod的时候,能为每个 Pod 做一个编号,就是为了能区分这一组Pod的不同角色,各个节点的角色不会变得混乱,然后再创建 headless service 资源,集群内的节点通过Pod名称+序号.Service名称,来进行彼此间通信的只要序号不变,访问就不会出错。
当statefulSet.spec.serviceName 配置与headless service相同时,可以通过 {hostName}.fheadless service}.{namespace}.svc.cluster.local 解析出节点IP。hostName 由{statefulSet name}-{编号}组成。
{statefulSet name}-{编号}.{headless service}{namespace}.svc.cluster.local
# 放在当前es中,对应的DNS子域名分别是
es-0.elastic.default.svc.cluster.local
es-1.elastic.default.svc.cluster.local
es-2.elastic.default.svc.cluster.local
3、HeadLess示例
apiVersion: v1
kind: Service
metadata:
name: myapp
spec:
clusterIP: "None"
selector:
app: nginx
ports:
- port: 80
targetPort: 80
- 编写pod资源
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: web
spec:
serviceName: "myapp"
replicas: 2
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: xx
image: nginx:1.16
imagePullPolicy: IfNotPresent
ports:
- containerPort: 80

- 使用tools 进行验证测试
kubectl exec -it tools -- /bin/bash
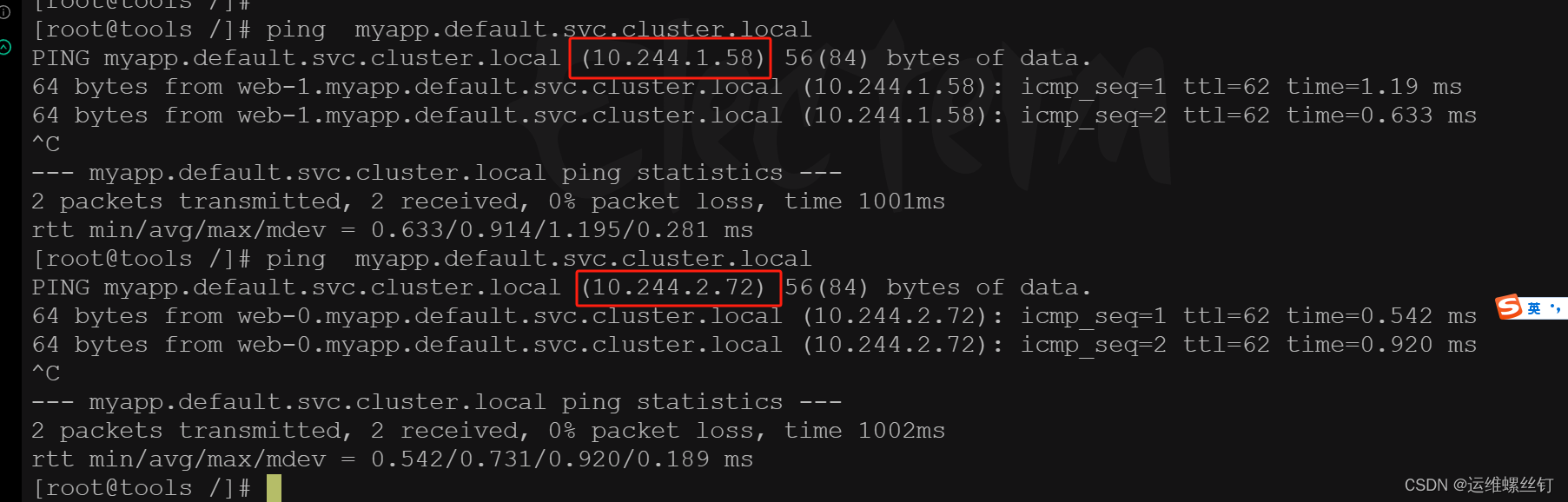
- ping myapp.default.svc.cluster.local 可以轮询到不同的pod上。

- ping web-1.myapp.default.svc.cluster.local 使用这个可以解析到指定的pod上
4、HeadLess测试
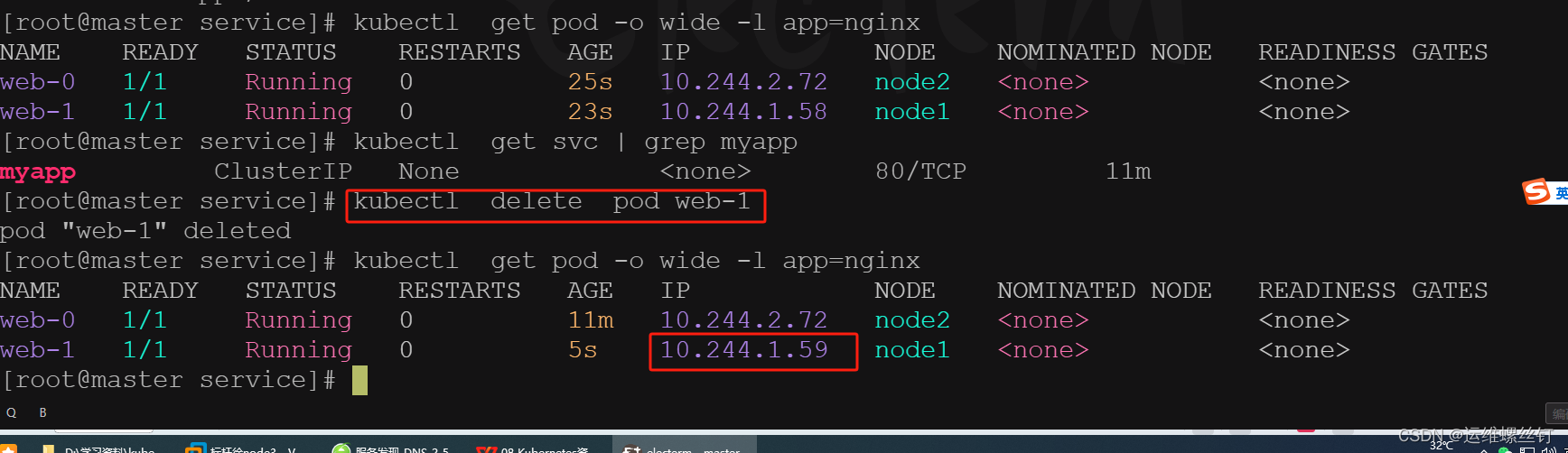

总结: 通过删除pod。依旧可以通过域名的方式进行解析
十四、guestBook案例实践
guestBook官网示例
guestBook的GitHub地址
1、场景描述
- 1、启动 Redis、领导 者(Leader)
- 2、启动两个 Redis 跟随者(Follower)
- 3、启动并公开 GuestBook 服务,数据写入Redis Leader节点数据读取统一写入Redis Slave节点
- 3.1 如果 GET HOSTS_FROM 设置为 env,则需要手动传递Redis Master、以及Slave的 Service名称;
REDIS LEADER SERVICE HOST # 传递Leader节点的Service名称或IP
REDIS FOLLOWER_SERVICE_HOST # 传递 Follower节点Service的名称或IP - 3.2 如果 GET HOSTS_FROM 设置为 dns,则站点会自动初始化两个变量,这就要求创建service时的名称得固定;
$host =‘redis-leader’;
$host =‘redis-follower’;
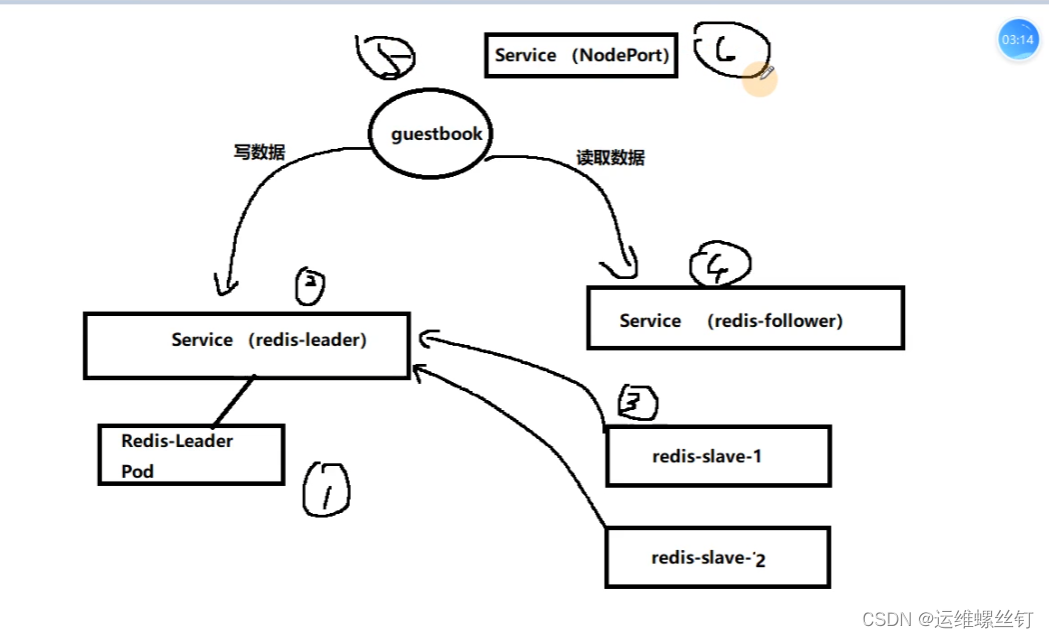
2、部署Redis-Leader
apiVersion: apps/v1
kind: Deployment
metadata:
name: redis-leader # Deployment Pod的名称
spec:
replicas: 1
selector:
matchLabels:
app: redis-master
template:
metadata:
labels:
app: redis-master
spec:
containers:
- name: redis-container
image: redis
ports:
- containerPort: 6379
---
apiVersion: v1
kind: Service
metadata:
name: redis-leader
spec:
type: ClusterIP
selector:
app: redis-master
ports:
- port: 6379
targetPort: 6379

3、部署redis-follower
apiVersion: apps/v1
kind: Deployment
metadata:
name: redis-follower
spec:
replicas: 2
selector:
matchLabels:
app: redis-slave
template:
metadata:
labels:
app: redis-slave
spec:
containers:
- name: redis-slave
image: redis
command: ["redis-server"]
args:
- --port 6379
- --slaveof redis-leader 6379
---
apiVersion: v1
kind: Service
metadata:
name: redis-follower
spec:
type: ClusterIP
selector:
app: redis-slave
ports:
- port: 6379
targetPort: 6379

4、部署guestbooks的deploy和service
apiVersion: apps/v1
kind: Deployment
metadata:
name: guestbooks
spec:
replicas: 3
selector:
matchLabels:
app: books
template:
metadata:
labels:
app: books
spec:
containers:
- name: books-container
image: oldxu3957/guestbook:v5
env:
- name: GET_HOSTS_FROM
value: "dns"
ports:
- containerPort: 80
---
apiVersion: v1
kind: Service
metadata:
name: guestbook-svc
spec:
type: NodePort
selector:
app: books
ports:
- protocol: TCP
port: 80
targetPort: 80
nodePort: 32003