知识库服务依赖该数据库,Embedding 形式个性化训练 ChatGPT,必不可少的就是向量数据库
因为 qdrant 向量数据库只支持 Docker 部署,所以需要先安装好 Docker 服务。
命令行安装
拉取镜像
docker pull qdrant/qdrant
运行服务
docker run -d -p 6333:6333 qdrant/qdrant
宝塔面板下安装
docker 管理器的镜像管理里,拉取 qdrant/qdrant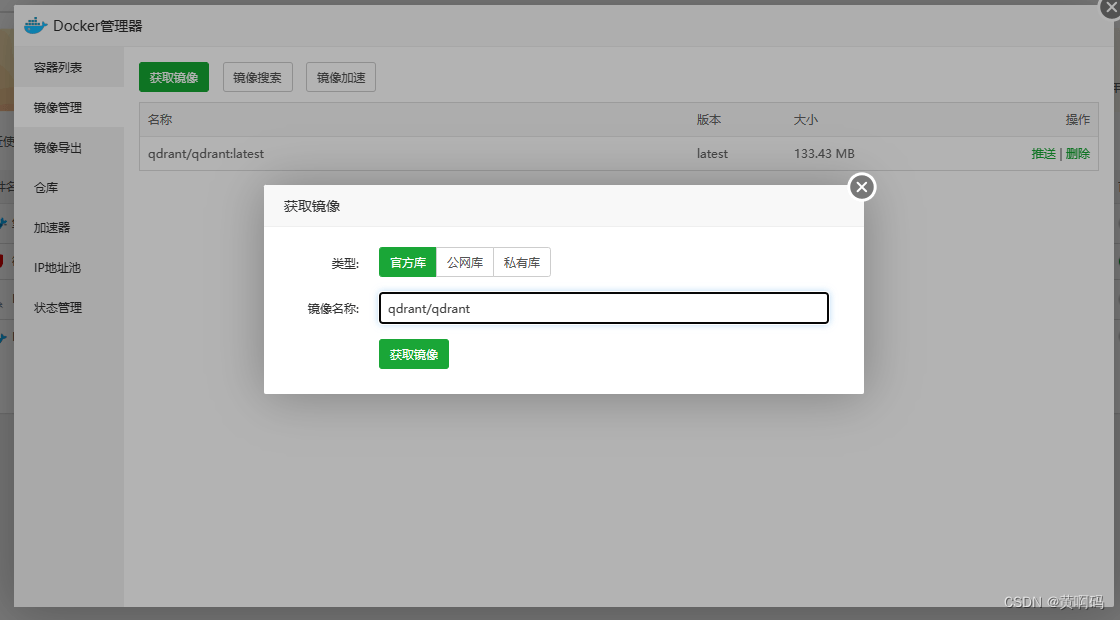
根据镜像创建容器,注意端口映射那里,填完以后一定要点那个 + 号,其他的是默认的
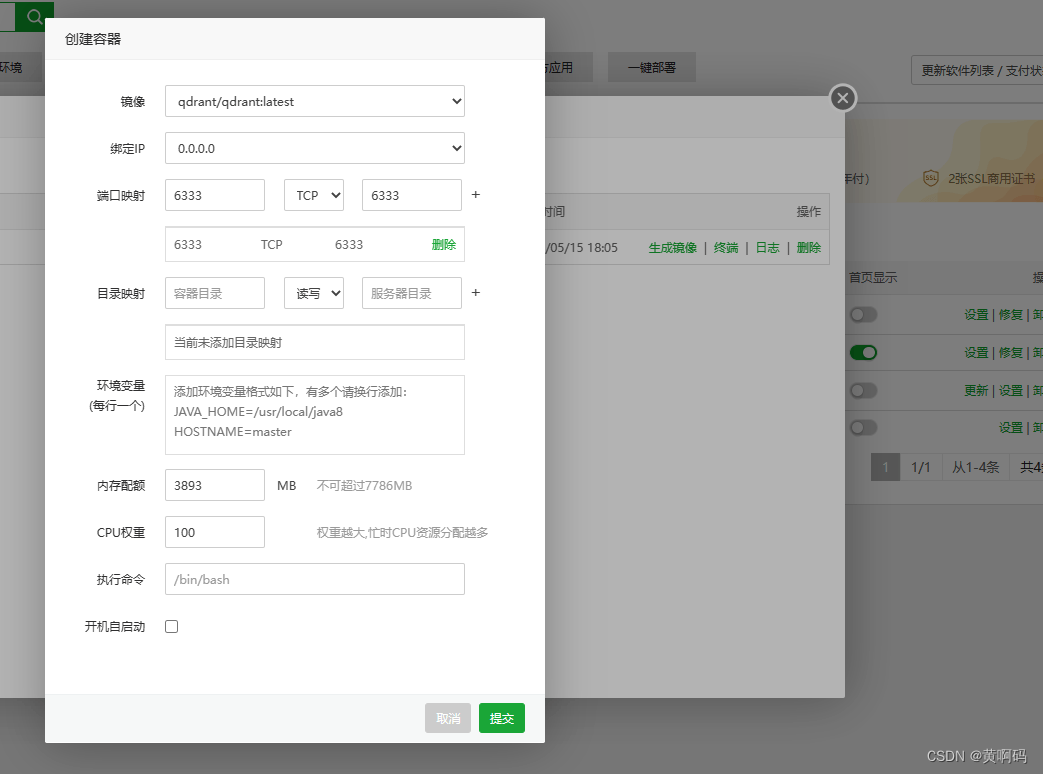
这样就能安装成功了。
向量数据库
但向量化数据存储到哪里呢?存到MySQL吗?答案显然是不现实的,存到MySQL你怎么做相似性查询,MySQL显然不太擅长做这件事情,想想都难。这时候就该向量数据库登场了
1、先建个collection
curl --location --request PUT 'http://your.domain.name/collections/[your collection name]' \
--header 'Content-Type: application/json' \
--data-raw '{
"vectors": {
"size": 1536,
"distance": "Dot"
}
}'注意:由于GPT的向量维度是惊人的1536个维度,所以在这里建collection的时候请填写size为1536,distance默认就是Dot。具体的collection名称在path上传就可以了。
数据库建好后,我们就可以在这个库里添加向量数据了,但向量数据从哪里来呢?前面说了,我们可以通过openai的API来拿到文档片段的向量数据。
2、文档片段向量化
curl --location --request POST 'https://your.domain.name/api/xxxx/embeddings?accessToken=xxxxxxx' \
--header 'Content-Type: application/json' \
--data-raw '{
"model": "text-embedding-ada-002",
"input": "文档片段内容"
}'返回值:
{
"model": "text-embedding-ada-002-v2",
"object": "list",
"data": [
{
"object": "embedding",
"embedding": [
-0.011098763,
0.0022886666,
0.0019187077,
-0.02824744,
-6.070769E-4,
0.019469986,
-0.014631506,
0.0020021298,
-0.015770398,
-0.019745642,
0.015494743,
...此处省略若干行(1536行实在太长)
-0.0138480645,
3.0421853E-4,
-0.004363337,
-0.0016793226,
0.0029088915,
-0.0062639094
],
"index": 0
}
],
"usage": {
"prompt_tokens": 6,
"completion_tokens": 0,
"total_tokens": 6
}
}这样我们就拿到了文档片段的向量化数据。
3、把向量数据存入向量库
继续回到Qdrant的API,下面这个API就负责添加数据,叫add points。
curl --location --request PUT 'https://your.domain.name/collections/[your_collection_name]/points?wait=true' \
--header 'Content-Type: application/json' \
--data-raw '{
"points": [
{"id": 1, "vector": [
-0.011098763,
0.0022886666,
0.0019187077,
-0.02824744,
-6.070769E-4,
0.019469986,
-0.014631506,
0.0020021298,
-0.015770398,
-0.019745642,
0.015494743,
...此处省略若干行(1536行实在太长)
-0.0138480645,
3.0421853E-4,
-0.004363337,
-0.0016793226,
0.0029088915,
-0.0062639094
],
"payload": {"doc_segment": "文档片段内容"}}
]
}'注意:points里边有三个关键字段,id、vector、payload。
id:唯一编号。相当于mysql的自增id。这个id要和你mysql里的文档片段表的id保持一致,方便后面反查到文档片段。
vector:向量数据。这里就是上面你拿到的向量数组。
payload:存储一些附加信息。这里我存了文档片段。
相似性检索
上面已经把一个个文档片段存入到Qdrant。现在我们就可以试试效果了。
1、向量化问题
我们现在把用户的提问进行向量化。同样用的是openai 的embedding API获得向量数组。这里同上就不赘述。
2、搜索
这一步是最关键的一步,前面做了那么多,就为了最后这一下搜索。我们使用Qdrant的search points API做相似性检索。
curl --location --request POST 'https://your.domain.name/qdrant/collections/[your_collection_name]/points/search' \
--header 'Content-Type: application/json' \
--data-raw '{
"vector": [
-0.009807939,
-0.036723405,
-0.0041218707,
-0.0159379,
-0.042078312,
...此处省略若干行(1536行实在太长)
-0.017488007,
-0.022744272,
0.0015791698,
-0.008109869,
0.002321635,
-6.385377E-4,
0.0057318667
],
"top": 1
}'注意:这里我们把上面拿到的问题的向量化数据传入到vector字段,top则传1,表示我们只要一个最相似的结果。
返回值:
{
"result": [
{
"id": 1,
"version": 0,
"score": 0.77804655,
"payload": null,
"vector": null
}
],
"status": "ok",
"time": 0.000159604
}注意:可以看出已经返回了最可能的答案,就是id为1的那个文档片段,另外可以发现分数为0.77804655,这里你不要计较这个分数的高低,分数都是相对的,总之你现在已经拿到了最可能的答案。
我们现在知道了最可能的答案就在id为1的文档片段里。是时候把这个文档片段反查出来了。怎么反查呢?其实前面提到了一点。那就是我们采用的是MySQL和向量库双写。MySQL负责管理文档关系,这是MySQL擅长的,Qdrant负责处理向量检索,这也是Qdrant擅长的。嗯,我们拿着这个id去MySQL表里反查文档片段内容。
MySQL管理文档关系
为了管理文档和通过向量化搜索后能拿到文档片段,我们需要在MySQL建两张表。
.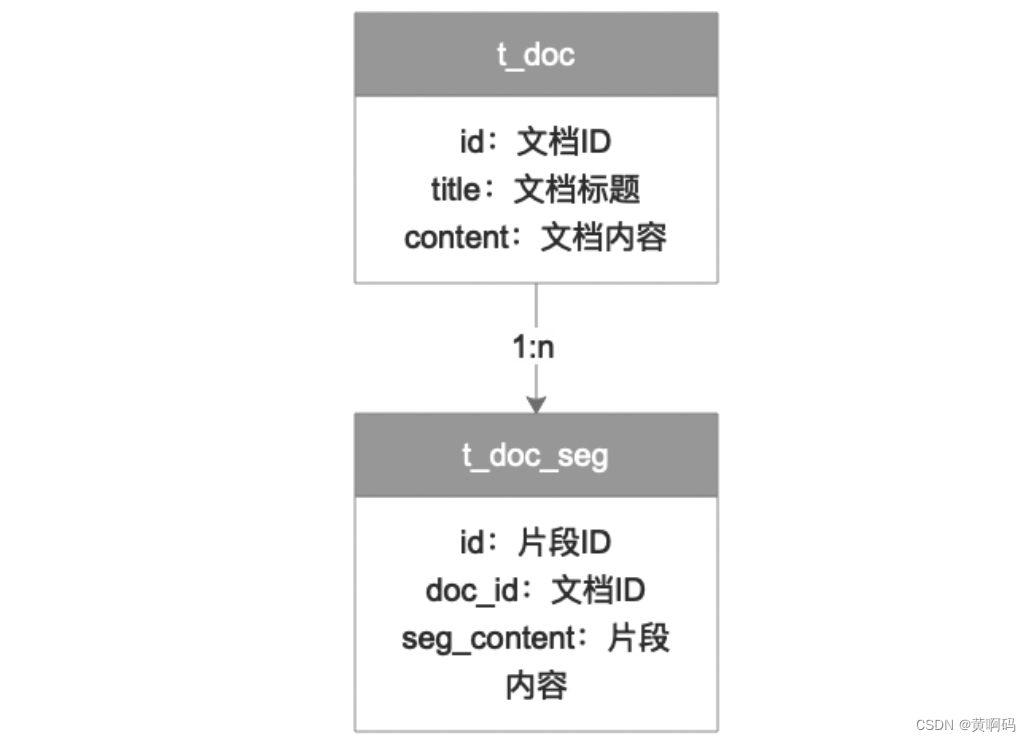
一张文档表、一张文档片段表,两者是一对多的关系。上面我们从向量库拿到的id就是文档片段的id,这样我们就可以反查到文档片段。
你也许在想我把片段拿到了,但依然不知道具体的答案啊。这时候就需要gpt的prompt出场了。
GPT Prompt最终总结和润色
我们拿到文档片段后,就可以构建下面这样一个prompt,这样就能得到最为准确的结果了
大体prompt的样子:
“{doc_seg},
请从提供的内容中找到最接近的答案(不知道就不回答):
{question}”