因为农机大部分时间是在田地工作,所以大多数农机轨迹样本存在数据分布不平衡的问题,既田地数据多,道路数据少。因为用于分类的大多数机器学习算法都是围绕每个类别的样本数量均相等的假设来设计的。这导致模型的预测性能较差,特别是针对样本较少类别的预测。针对这一情况,采用过采样加欠采样的方法对数据进行增强、扩充,得到平衡的数据集。
SafeLevelSMOTE
SafeLevelSMOTE 是一种改进的 Synthetic Minority Over-sampling Technique(SMOTE)算法,用于处理类不平衡问题。在传统的 SMOTE 算法中,生成的合成样本可能位于决策边界附近,导致模型学习到噪声数据。而 SafeLevelSMOTE 引入了 Safe-Level 概念,规定了生成合成样本的安全级别,从而确保生成的合成样本不会引入噪声,同时提高了生成样本的质量,可以更好地应对类不平衡导致的样本较少的情况下训练模型的问题。
class SafeLevelSMOTE(SMOTE):
def __init__(self, sampling_strategy='auto', k_neighbors=5, m_neighbors=10, n_jobs=1):
super(SafeLevelSMOTE, self).__init__(sampling_strategy=sampling_strategy, k_neighbors=k_neighbors,
n_jobs=n_jobs)
self.m_neighbors = m_neighbors
def _make_samples(self, X, y_dtype, y_type, nn_data, nn_num, k, step, **params):
nns = NearestNeighbors(n_neighbors=self.k_neighbors + 1, n_jobs=self.n_jobs)
nns.fit(nn_data)
knn = nns.kneighbors(nn_data, return_distance=False)[:, 1:]
safe_level = np.array([self._safe_level(i, knn) for i in range(nn_data.shape[0])])
safe_level = np.maximum(safe_level, 0.5)
return super(SafeLevelSMOTE, self)._make_samples(X, y_dtype, y_type, nn_data, nn_num, k, step, **params)
def _safe_level(self, i, knn):
return (1.0 / (1.0 + np.sum(knn[i] < self.m_neighbors)))
# 使用 SafeLevelSMOTE 进行过采样
safesmote = SafeLevelSMOTE(sampling_strategy='auto', k_neighbors=5, m_neighbors=10)
X_resampled, y_resampled = safesmote.fit_resample(X_train, y_train)NearMiss
NearMiss-1 是针对处理类不平衡数据集的一种欠采样方法。在 NearMiss-1 中,算法会选择离少数类样本最近的多数类样本进行移除,来达到平衡数据集的目的。NearMiss-1 通过选择离少数类样本最近的多数类样本进行移除, 可以有效地减少数据集的规模,避免过拟合,并提高对少数类的捕捉能力。
from imblearn.under_sampling import NearMiss
undersample = NearMiss(version=1, n_neighbors=3)
X_NearMiss, y_NearMiss= undersample.fit_resample(X_resampled, y_resampled)先进行过采样,然后进行欠采样,可以有效的提高少目标的数量,达到平衡数据集的作用。
原始图像: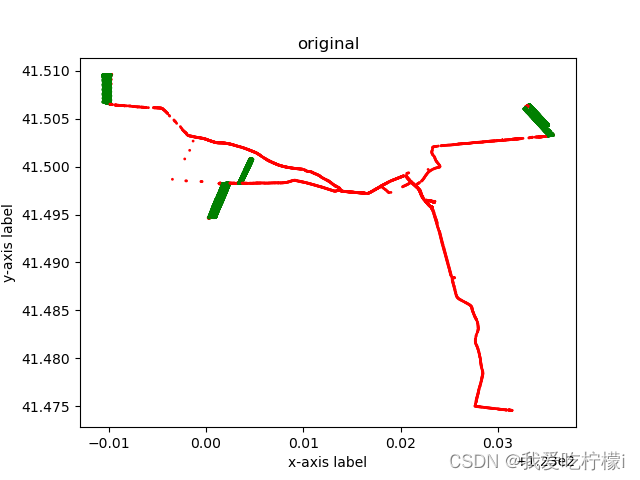
原始数据 = Counter({1: 19450, 0: 3131})过采样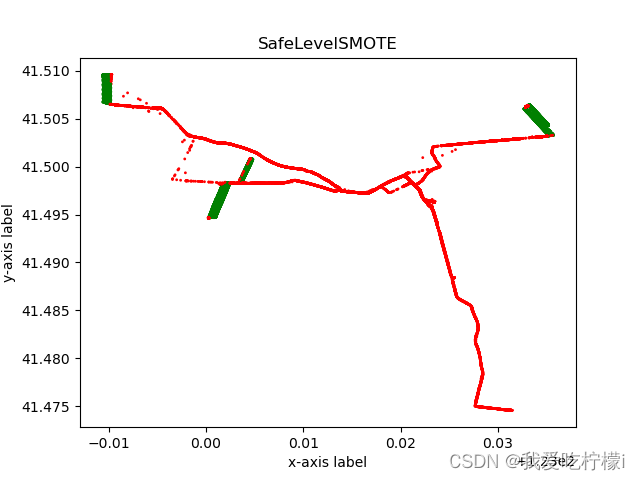
最终效果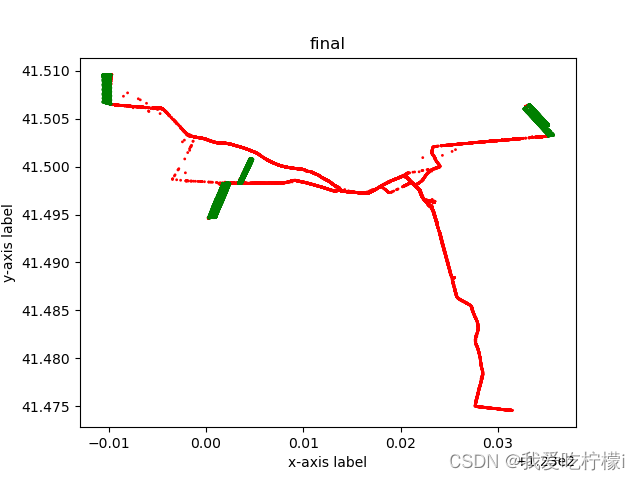
处理完的数据 = Counter({0: 19450, 1: 19450})处理完的数据,效果还可以。
完整代码
# -*- coding: utf-8 -*-
import numpy as np
from imblearn.over_sampling import BorderlineSMOTE, ADASYN, SMOTE
import pandas as pd
from imblearn.under_sampling import NearMiss
from matplotlib import pyplot as plt
from sklearn.neighbors import NearestNeighbors
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from collections import Counter
from datetime import datetime
import os
# 原始数据文件夹路径
input_folder = r'D:\GAN-316\1-60csv'
# 目标文件夹路径
output_folder = r'D:\GAN-316\111111111111111111111111111111111111111111111111111'
# 检查目标文件夹是否存在,如果不存在则创建
if not os.path.exists(output_folder):
os.makedirs(output_folder)
print(f"目标文件夹 {output_folder} 不存在,已创建")
# 遍历原始数据文件夹中的所有文件
for file_name in os.listdir(input_folder):
if file_name.endswith('.csv'):
file_path = os.path.join(input_folder, file_name)
# 加载数据
data = pd.read_csv(file_path,encoding='gbk')
data['time'] = pd.to_datetime(data['time'])
data['time_seconds'] = (data['time'] - datetime(1970, 1, 1)).dt.total_seconds()
# 2. 数据预处理
# 假设特征列为 '经度', '纬度', '速度', '方向',目标列为 '标签'
# X = data[['经度', '纬度', '速度', '方向', 'time_seconds']]
# if '标记' in data.columns:
# y = data['标记']
# elif '标签' in data.columns:
# y = data['标签']
# else:
# print("未找到标记列或标签列")
X = data[['longitude', 'latitude', 'speed', 'dir','time_seconds']]
y = data['tags']
X_train = X
y_train = y
y_counts = Counter(y)
print("原始数据 = ", y_counts)
print("min(y_counts) = ", min(y_counts))
if len(y_counts) == 1:
print(f"文件 {file_name} 中只包含一个类别,跳过处理")
continue
if min(y_counts.values()) < 20:
continue
#原始数据可视化
xx = data['longitude']
yy = data['latitude']
# 根据标签设置颜色
colors = ['green' if label == 1 else 'red' for label in y]
# 创建散点图
plt.scatter(xx, yy, c=colors, s=1)
plt.xlabel('x-axis label')
plt.ylabel('y-axis label')
plt.title('original')
plt.show()
class SafeLevelSMOTE(SMOTE):
def __init__(self, sampling_strategy='auto', k_neighbors=5, m_neighbors=10, n_jobs=1):
super(SafeLevelSMOTE, self).__init__(sampling_strategy=sampling_strategy, k_neighbors=k_neighbors,
n_jobs=n_jobs)
self.m_neighbors = m_neighbors
def _make_samples(self, X, y_dtype, y_type, nn_data, nn_num, k, step, **params):
nns = NearestNeighbors(n_neighbors=self.k_neighbors + 1, n_jobs=self.n_jobs)
nns.fit(nn_data)
knn = nns.kneighbors(nn_data, return_distance=False)[:, 1:]
safe_level = np.array([self._safe_level(i, knn) for i in range(nn_data.shape[0])])
safe_level = np.maximum(safe_level, 0.5)
return super(SafeLevelSMOTE, self)._make_samples(X, y_dtype, y_type, nn_data, nn_num, k, step, **params)
def _safe_level(self, i, knn):
return (1.0 / (1.0 + np.sum(knn[i] < self.m_neighbors)))
# 使用 SafeLevelSMOTE 进行过采样
safesmote = SafeLevelSMOTE(sampling_strategy='auto', k_neighbors=5, m_neighbors=10)
X_resampled, y_resampled = safesmote.fit_resample(X_train, y_train)
xxx = X_resampled['longitude']
yyy = X_resampled['latitude']
# 根据标签设置颜色
colors = ['green' if label == 1 else 'red' for label in y_resampled]
# 创建散点图
plt.scatter(xxx, yyy, c=colors, s=1)
plt.xlabel('x-axis label')
plt.ylabel('y-axis label')
plt.title('SafeLevelSMOTE')
plt.show()
# 使用 NearMiss 进行欠采样
undersample = NearMiss(version=1, n_neighbors=3)
X_NearMiss, y_NearMiss= undersample.fit_resample(X_resampled, y_resampled)
# #如果X_NearMiss的列名为[经度,纬度,速度,方向,时间] 就把他改为 ['longitude', 'latitude', 'speed', 'dir','time_seconds']
# original_column_names = ['经度', '纬度', '速度', '方向' ]
# new_column_names = ['longitude', 'latitude', 'speed', 'dir']
# #检查原始列名是否与指定的列名相匹配,然后进行重命名
# if all(elem in X_NearMiss.columns for elem in original_column_names):
# X_NearMiss.rename(columns=dict(zip(original_column_names, new_column_names)), inplace=True)
# print("列名已成功更改。")
# else:
# print("原始列名与指定列名不匹配,无法进行重命名。")
# 将时间秒数转换为 DateTime 格式并赋值给新的 'time' 列
X_NearMiss['time'] = pd.to_datetime(datetime(1970, 1, 1) + pd.to_timedelta(X_NearMiss['time_seconds'], unit='s'))
X_NearMiss['time'] = X_NearMiss['time'].dt.floor('S')
# 删除原始的 'time_seconds' 列
X_NearMiss.drop(['time_seconds'], axis=1, inplace=True)
df_labels = pd.DataFrame({'tags': y_NearMiss})
# 重置特征数据和标签数据的索引
X_NearMiss.reset_index(drop=True, inplace=True)
df_labels.reset_index(drop=True, inplace=True)
# 转换之后可视化
x = X_NearMiss['longitude']
y = X_NearMiss['latitude']
# 根据标签设置颜色
colors = ['green' if label == 1 else 'red' for label in y_NearMiss]
# 创建散点图
plt.scatter(x, y, c=colors, s=1)
plt.xlabel('x-axis label')
plt.ylabel('y-axis label')
plt.title("final")
plt.show()
# 合并特征和标签数据
data_combined = pd.concat([X_NearMiss, df_labels], axis=1)
print("Combined Data:")
print(data_combined)
# 6.统计 y_train_resampled 中每个元素的数量
y_train_resampled_counts = Counter(y_NearMiss)
print("处理完的数据 = ", y_train_resampled_counts)
output_file_path = os.path.join(output_folder, f'processed_{file_name}')
data_combined.to_csv(output_file_path, index=False,encoding='gbk')
print(f'文件 {file_name} 处理完毕,并保存到 {output_file_path}')
print('所有文件处理完成!')
# x = X_NearMiss['longitude']
# y = X_NearMiss['latitude']
#
# # 根据标签设置颜色
# colors = ['green' if label == 1 else 'red' for label in y_NearMiss]
#
# # 创建散点图
# plt.scatter(x, y, c=colors, s=1)
# plt.xlabel('x-axis label')
# plt.ylabel('y-axis label')
# plt.title(123)
# plt.show()
![[数据结构]堆](https://img-blog.csdnimg.cn/direct/e8ae4653849d4d6caa7457a0d9908358.png)