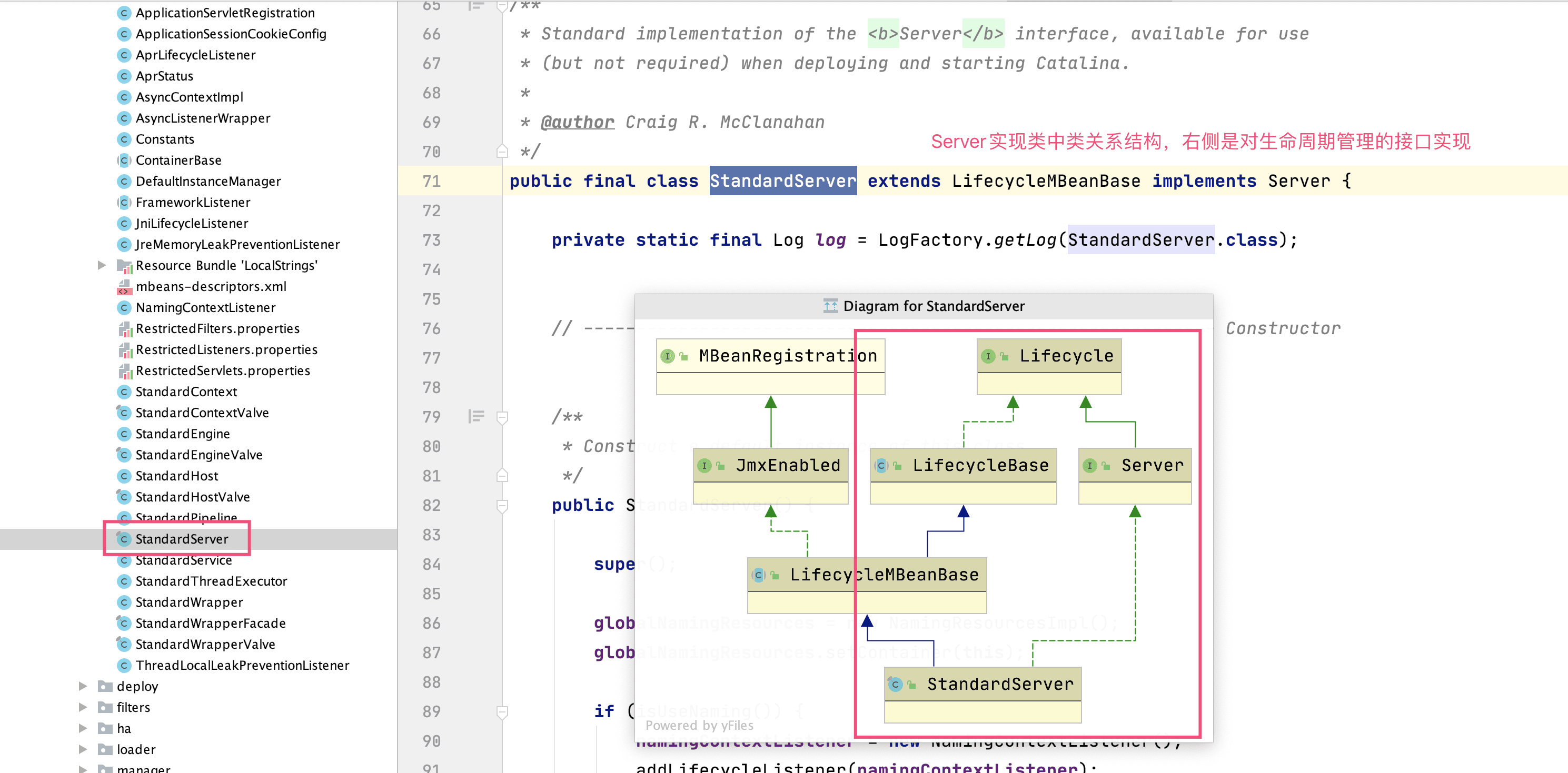
目录
- 1、正则表达式概述
- 2、re模块
- 3、匹配单个字符
- 4、匹配多个字符
- 5、匹配开头和结尾
- 6、匹配分组
- 7、总结
1、正则表达式概述
在实际开发过程中经常会需要查找某些复杂字符串的格式
正则表达式:记录文本规则的代码
正则表达式特点:
- 语法令人头疼,可读性差
- 通用性强,能够适用于很多编程语言
2、re模块
流程:导入re模块,match匹配数据,group提取数据
#导入re模块
import re
#match匹配数据
result = match(正则表达式,要匹配的字符串)
#group提取数据
result.group()
import re
result = re.match("it","itsma")
info = result.group() #如果没有匹配到,会报错
print(info) #输出it
3、匹配单个字符
. —匹配任意一个字符(除了\n)
\d —匹配数字0-9
\D —匹配非数字
\s — 匹配空白,空格,tab键
\S ----匹配非空白
\w ----匹配特殊字符,即a-z,A-Z,_,汉字
\W ----匹配非特殊字符
import re
result = re.match("it","itsma")
if result:
info = result.group() #如果没有匹配到,会报错
print(info) #输出it
else:
print('没有匹配到')
result = re.match("it","itsma\t")#\t是指tab键
4、匹配多个字符
- —匹配前一个字符出现0次或者无限次,可有可无
- ----匹配前一个字符出现1次或者无限次
? ----匹配前一个字符出现1次或者0次
{m} ----匹配前一个字符出现m次
{m,n} ----匹配前一个字符出现m次到n次之间的次数
5、匹配开头和结尾
^ 字符串—匹配字符串开头
字符串$ —匹配字符串结尾
[^指定字符] —取反,指定字符串以完的其他
6、匹配分组
| ----匹配左右任意一个表达式
(ab) —括号中的是一个分组
\num —引用分组num匹配到字符串
(?P)—分组起别名
(?P=name)引用别名为name分组匹配到的字符串
需求:

需求1:
import re
fruit = ['apple','banana','orange','pear'] #匹配apple和pear
for value in fruit:
result = re.match("apple|pear",value)
if result:
info = result.group() #如果没有匹配到,会报错
print("这是我想吃的水果",info) #输出it
else:
print('这个不是我想吃的水果',value)
需求2:
import re
result = re.match("[a-zA-Z0-9]{4,20}@(163|126|qq)\.com","1345ab@qq.com")
print(result)
if result:
info = result.group()
print(info) #输出it
else:
print('没匹配到')
需求3:
默认group(0)代表的是匹配的所有数据, 1:第一组的带括号的数据,2:第二组带括号的数据,
import re
result = re.match("(qq):([1-9]\d{4,11})","qq:123456")
print(result)
if result:
info = result.group()
print(info) #输出qq:123456
type1 = result.group(1)
print(type1) #输出qq
num = result.group(2)
print(num) #输出123456
else:
print('没匹配到')
需求4:
\num —引用分组num匹配到字符串,用之前要括号起来
import re
#result = re.match("<[a-zA-Z4-9]{4}>.*</[a-zA-Z4-9]{4}>","<html>hh</html>")
result = re.match("<([a-zA-Z1-6]{4})>.*</\\1>","<html>hh</html>")
print(result)
if result:
info = result.group()
print(info)
else:
print('没匹配到')
需求5:
\num —引用分组num匹配到字符串,用之前要括号起来\2
import re
result = re.match("<([a-zA-Z1-6]{4})><([a-zA-Z1-6]{2})>.*</\\2></\\1>","<html><h1>www.itcast.cn</h1></html>")
print(result)
if result:
info = result.group()
print(info)
else:
print('没匹配到')
需求6:
(?P)—分组起别名
(?P=name)引用别名为name分组匹配到的字符串
import re
result = re.match("<(?P<name1>[a-zA-Z1-6]{4})><(?P<name2>[a-zA-Z1-6]{2})>.*</(?P=name2)></(?P=name1)>","<html><h1>www.itcast.cn</h1></html>")
print(result)
if result:
info = result.group()
print(info)
else:
print('没匹配到')
7、总结
限定符
a? —o次或者1次a
a* ----0次或者多次a
a+ ----1次以上的a
a{6} ----6次出现a
a{2,6} ----6次或者2次出现a
a{2,} ----2次及以上出现a
(ab)+ ----1次以上的ab
(ab)|(cd) — ab或者cd
元字符
\d ----数字字符
\D —非数字字符
\w —单词字符(英文、数字、下划线)
\W —非单词字符
\s —空白字符(换行符、tab)
\S —非空白字符
. —任意字符
\bword\b —\b标注字符的边界
^ — 行首
& — 行尾
<.+> —贪婪匹配
<.+?> — 懒惰匹配