SegFormer 项目排坑记录
- 任务
- 记录
- 创建conda环境
- 准备数据库和预训练参数
- 程序配置修改
- 测试
- 可视化
- 训练
任务
需要复现SegFormer分割项目,似乎还有点麻烦,参考这几个进行复现,记录下过程:
SegFormer
mmsegmentation
CSDN博客
知乎博客
记录
创建conda环境
SegFormer的readme说:
For install and data preparation, please refer to the guidelines in MMSegmentation v0.13.0.
看来要先按照mmsegmentation创建环境。
按照mmsegmentation的readme执行:
conda create -n SEGFORMER python=3.7 -y
conda activate SEGFORMER
pip3 install empy==3.3.4 rospkg pyyaml catkin_pkg
mmsegmentation要求装torch1.6.0,配套cuda10.1.这可不行,我3070显卡只能用11.0以上的cuda。查看pytorch官网,没有torch1.6.0配套11cuda的。但我发现知乎那个博客他用的是Pytorch 1.10.0,这个查一下就有cuda11了。CSDN那个用的torch1.7.0,配合cuda11。我决定用1.7.0的:
conda install pytorch==1.7.0 torchvision==0.8.0 torchaudio==0.7.0 cudatoolkit=11.0 -c pytorch -y
pip3 install mmcv-full -f https://download.openmmlab.com/mmcv/dist/cu110/torch1.7.0/index.html
你要问我为啥选这个版本?因为官网的建议是这样的:mmcv。当并不是full版本,我觉得还是用full版本保险。CSDN上那个是full版本,但不是2.0的,而且那个命令我跑不通。然后我发现官网的whl可以找到:whl,于是我就修改了官网的指令。
有个报错,但小问题:
ERROR: pip's dependency resolver does not currently take into account all the packages that are installed. This behaviour is the source of the following dependency conflicts.
torch 1.7.0 requires dataclasses, which is not installed.
torch 1.7.0 requires future, which is not installed.
执行:
pip3 install dataclasses future
最后我装上的是1.7.2的:
Successfully installed addict-2.4.0 importlib-metadata-6.7.0 mmcv-full-1.7.2 opencv-python-4.9.0.80 packaging-24.0 platformdirs-4.0.0 tomli-2.0.1 typing-extensions-4.7.1 yapf-0.40.2 zipp-3.15.0
然后MMSegmentation这边好像没有要安装的了。除了git之后进行
pip install -e .
我觉得SegFormer的仓库应该包含了MMSegmentation,所以我打算开始git:
git clone https://github.com/NVlabs/SegFormer.git
cd SegFormer/
pip3 install -e .
然后看SegFormer的readme要安装:
pip install torchvision==0.8.2
pip install timm==0.3.2
pip install mmcv-full==1.2.7
pip install opencv-python==4.5.1.48
cd SegFormer && pip install -e . --user
但好多我已经有了,检查下:
pip3 show torchvision timm mmcv-full opencv-python
结果:
WARNING: Package(s) not found: timm
Name: torchvision
Version: 0.8.0
Summary: image and video datasets and models for torch deep learning
Home-page: https://github.com/pytorch/vision
Author: PyTorch Core Team
Author-email: soumith@pytorch.org
License: BSD
Location: /home/lcy-magic/anaconda3/envs/SEGFORMER/lib/python3.7/site-packages
Requires: numpy, pillow, torch
Required-by:
---
Name: mmcv-full
Version: 1.7.2
Summary: OpenMMLab Computer Vision Foundation
Home-page: https://github.com/open-mmlab/mmcv
Author: MMCV Contributors
Author-email: openmmlab@gmail.com
License:
Location: /home/lcy-magic/anaconda3/envs/SEGFORMER/lib/python3.7/site-packages
Requires: addict, numpy, opencv-python, packaging, Pillow, pyyaml, yapf
Required-by:
---
Name: opencv-python
Version: 4.9.0.80
Summary: Wrapper package for OpenCV python bindings.
Home-page: https://github.com/opencv/opencv-python
Author:
Author-email:
License: Apache 2.0
Location: /home/lcy-magic/anaconda3/envs/SEGFORMER/lib/python3.7/site-packages
Requires: numpy
Required-by: mmcv-full
也就是我只用安装timm就行了,其他版本不对先不管了:
pip3 install timm==0.3.2
好像项目里还有个requirements,也装了吧:
pip3 install -r requirements.txt
conda环境至此应该搞好了,要准备数据库了。
准备数据库和预训练参数
因为ADE20K的官网一直没给我发账号验证邮件,我就从这里下数据集了数据集
然后我在SegFormer根目录新建了data文件夹,把东西解压在那里了,结构为:

从readme给的ondrive上下载segformer.b5.640x640.ade.160k.pth预训练参数文件(本来都想下载的,但校园网这个速度太慢了,先只下一个吧),然后放到根目录下创建pretrained文件夹,放到这里。
最后在根目录下新建一个Checkpoints文件夹用来存放训练过程中的文件。
数据集和预训练参数的准备就到这里。
程序配置修改
- 我感觉我不用改ade.py,因为我就用的这个数据集。
- 修改mmseg/models/decode_heads/segformer_head.py;因为我单卡训练,所以把59行SyncBN 修改为 BN:
# norm_cfg=dict(type='SyncBN', requires_grad=True)
norm_cfg=dict(type='BN', requires_grad=True)
- 关于数据集的位置:configs/base/datasets/ade20k.py和local_configs/segformer/B5/segformer.b5.640x640.ade.160k.py中的data_root和data中的路径都和我的一致,我也不改了(B5应该是效果最好的,640还是1024我也不知道,先选个640吧),其他还有好几个要根据数据集修改的地方,因为我用的就是ADE20数据集,所以也都不修改,不赘述了。
测试
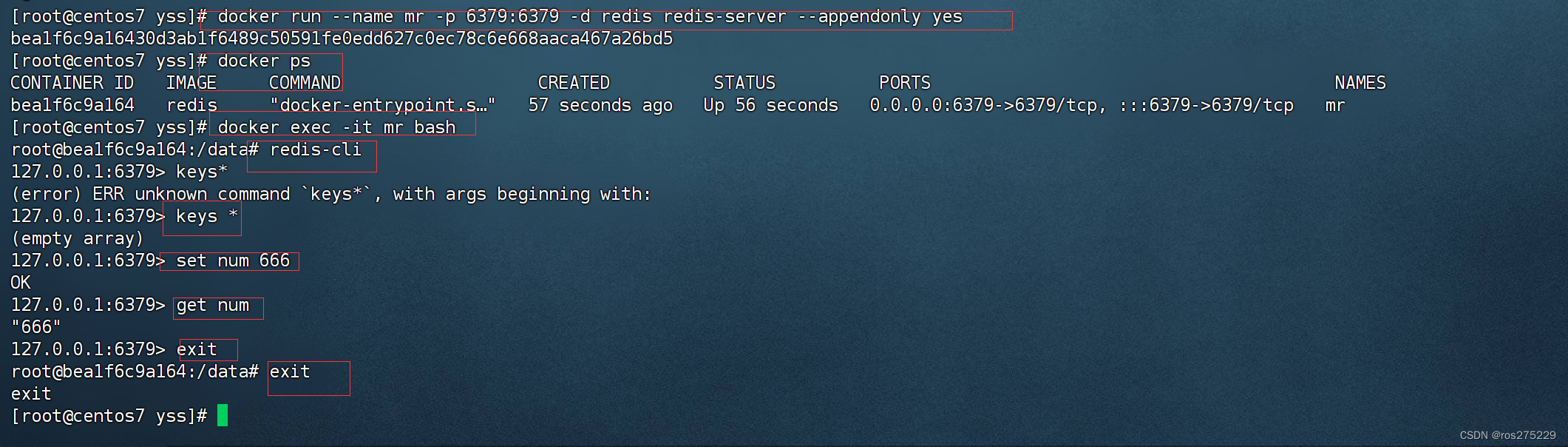
根目录下运行:
python tools/test.py local_configs/segformer/B5/segformer.b5.640x640.ade.160k.py pretrained/segformer.b5.640x640.ade.160k.pth
报错:
home/lcy-magic/anaconda3/envs/SEGFORMER/lib/python3.7/site-packages/mmcv/__init__.py:21: UserWarning: On January 1, 2023, MMCV will release v2.0.0, in which it will remove components related to the training process and add a data transformation module. In addition, it will rename the package names mmcv to mmcv-lite and mmcv-full to mmcv. See https://github.com/open-mmlab/mmcv/blob/master/docs/en/compatibility.md for more details.
'On January 1, 2023, MMCV will release v2.0.0, in which it will remove '
Traceback (most recent call last):
File "tools/test.py", line 10, in <module>
from mmseg.apis import multi_gpu_test, single_gpu_test
File "/home/lcy-magic/Segment_TEST/SegFormer/mmseg/__init__.py", line 27, in <module>
f'MMCV=={mmcv.__version__} is used but incompatible. ' \
AssertionError: MMCV==1.7.2 is used but incompatible. Please install mmcv>=[1, 1, 4], <=[1, 3, 0].
按照参考博客的说法,我把mmseg/init.py中的最大版本改了:
# MMCV_MAX = '1.3.0'
MMCV_MAX = '1.8.0'
再次运行又报错:
ModuleNotFoundError: No module named 'IPython'
于是安装:
pip3 install ipython
再次运行(太长了,截一部分):
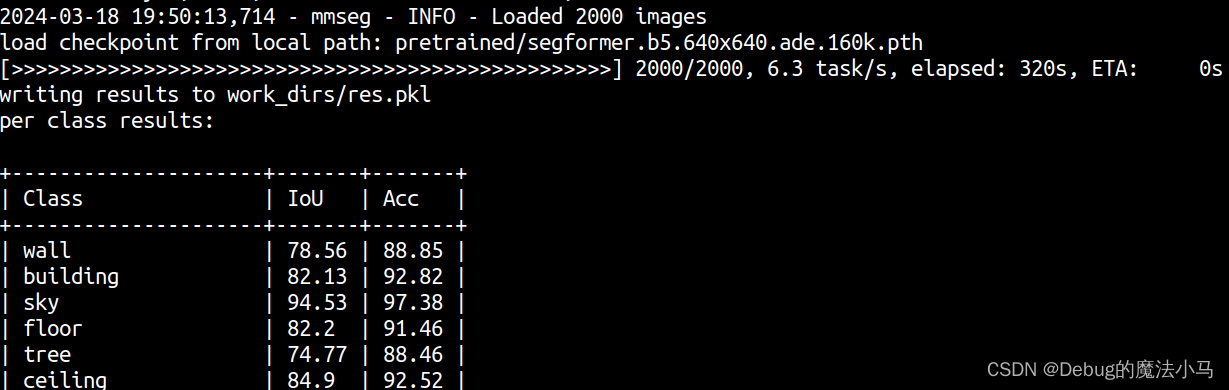
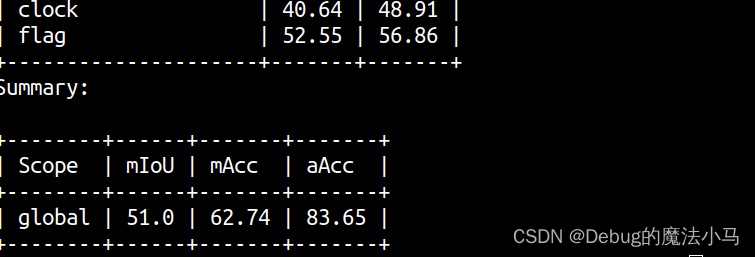
可视化
运行:
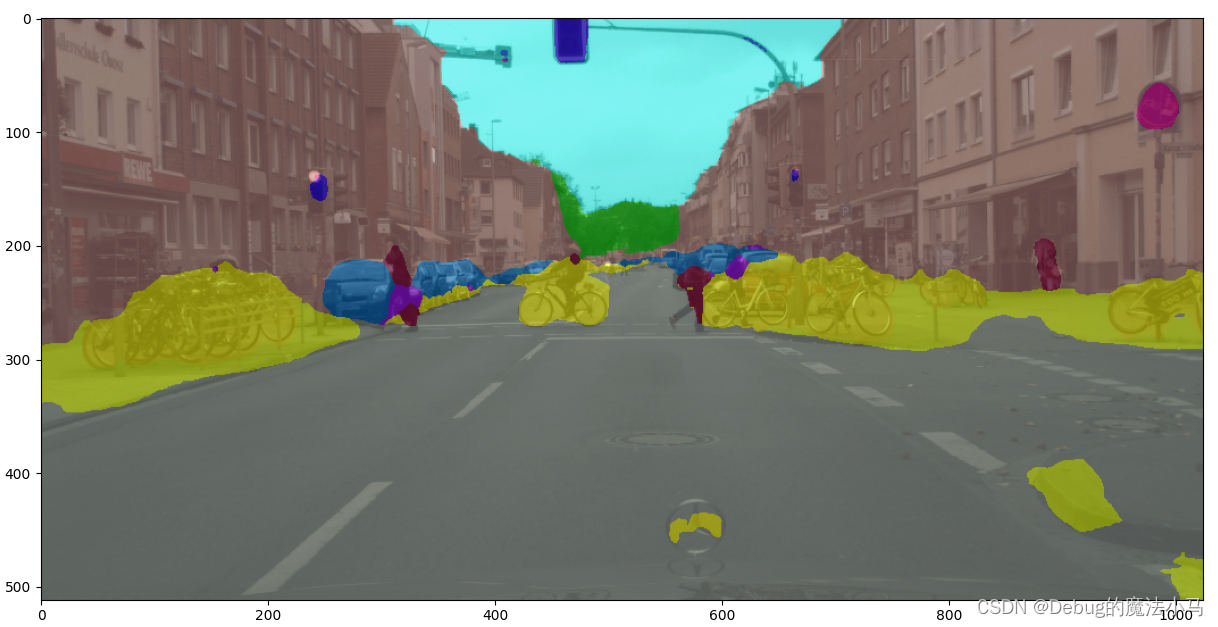
python demo/image_demo.py demo/demo.png local_configs/segformer/B5/segformer.b5.640x640.ade.160k.py pretrained/segformer.b5.640x640.ade.160k.pth --device cuda:0 --palette ade
效果有点拉胯哈哈:

可能因为是640的,正好我的b0下载好了,我试试b0:
python demo/image_demo.py demo/demo.png local_configs/segformer/B0/segformer.b0.512x512.ade.160k.py pretrained/segformer.b0.512x512.ade.160k.pth --device cuda:0 --palette ade
稍微好了点:
训练
把readme中的预训练权重文件下载到pretrained文件夹,我只下载了mit_b1.pth。
主目录下运行:
python tools/train.py local_configs/segformer/B1/segformer.b1.512x512.ade.160k.py
成功!但没完全成功:
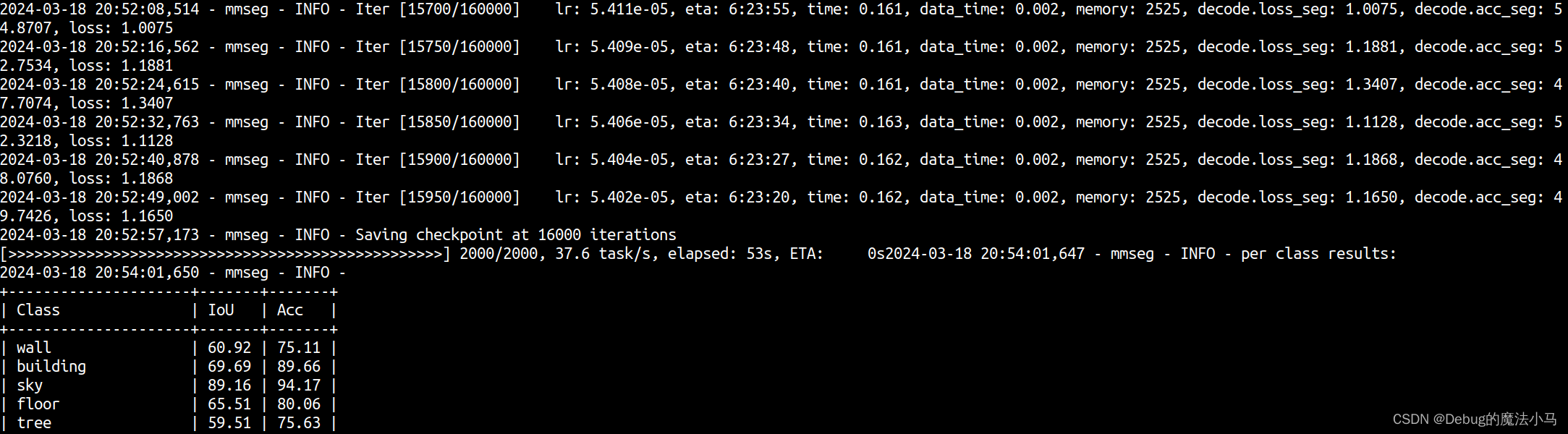
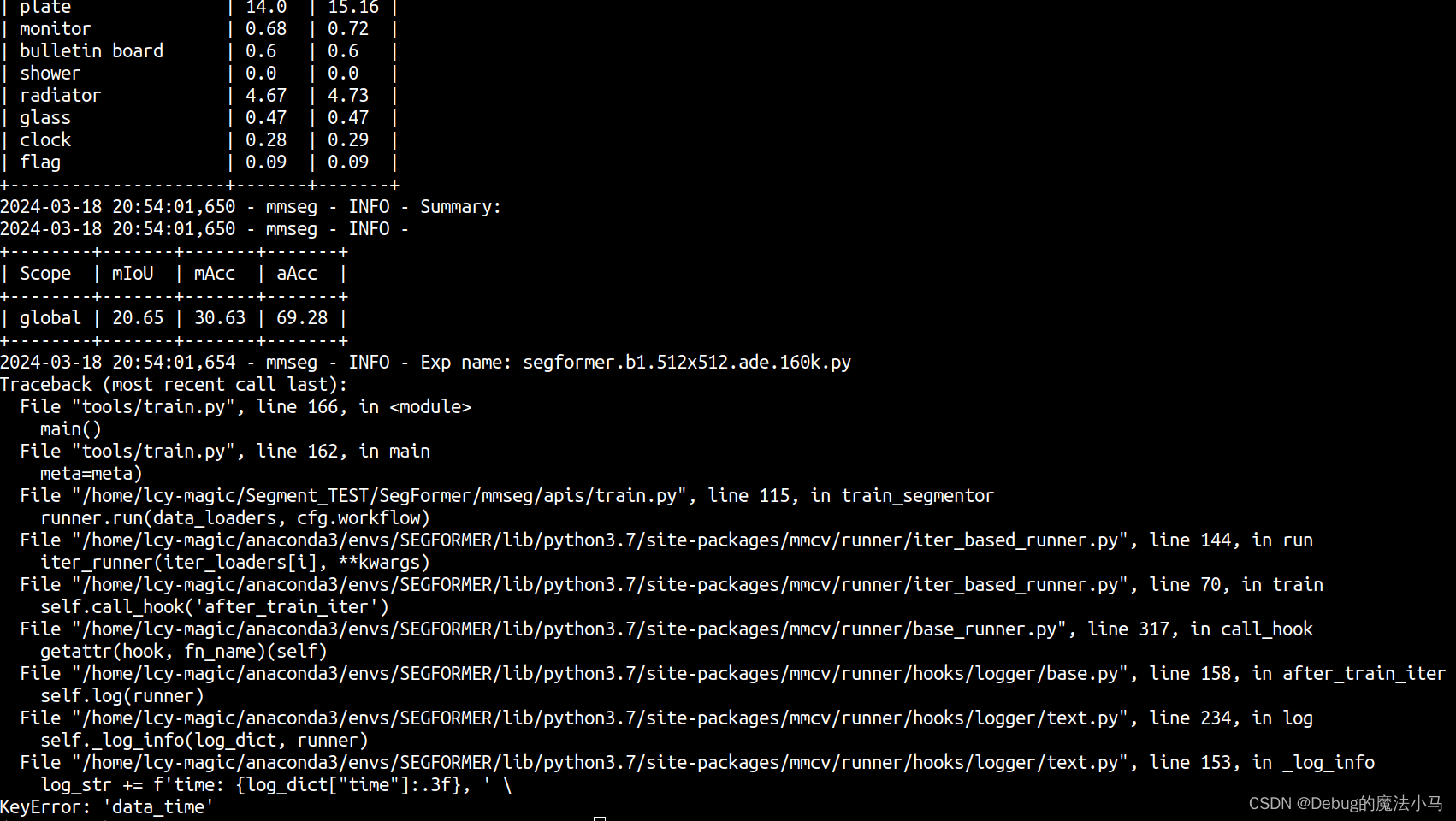
按照参考博客的方法。
在我的conda路径下的文件/home/lcy-magic/anaconda3/envs/SEGFORMER/lib/python3.7/site-packages/mmcv/runner/hooks/logger/text.py中添加:
import time
再把整个时间打印部分修改为:
if 'time' in log_dict.keys():
self.time_sec_tot += (log_dict['time'] * self.interval)
# time_sec_avg = self.time_sec_tot / (
# runner.iter - self.start_iter + 1)
# eta_sec = time_sec_avg * (runner.max_iters - runner.iter - 1)
# eta_str = str(datetime.timedelta(seconds=int(eta_sec)))
# log_str += f'eta: {eta_str}, '
# log_str += f'time: {log_dict["time"]:.3f}, ' \
# f'data_time: {log_dict["data_time"]:.3f}, '
log_dict["data_time"] = datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')
log_str += f'time: {log_dict["time"]}, 'f'data_time: {log_dict["data_time"]}, '
搞定!