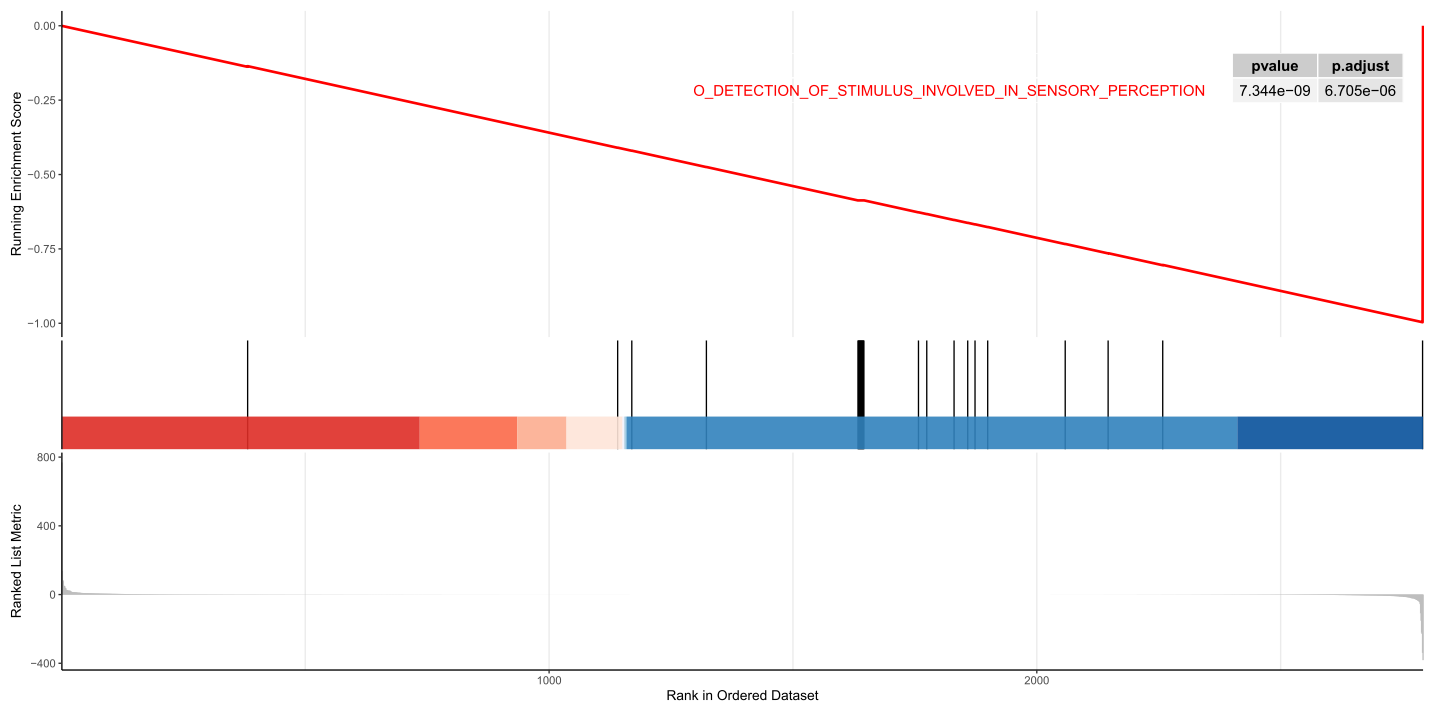
背景需求:
前文从原来的“新模版”文件夹里提取了周计划主要内容和教案内容。
【办公类-22-10】周计划系列(5-2)“周计划-02源文件docx读取5天“ (2024年调整版本)-CSDN博客文章浏览阅读1.1k次,点赞29次,收藏22次。【办公类-22-10】周计划系列(5-2)“周计划-02源文件docx读取5天“ (2024年调整版本)https://blog.csdn.net/reasonsummer/article/details/136308050
本篇是在第一遍提取基本信息基础上,对EXCEL内容进行补充,生成19份DOCX,然后再次再19份docx里面修改内容,让文字撑满格子。
虽然再次提取修改过内容的19份docx内容,到excel内,再次生成新的19份内容,
这样循环往复,逐步让每一份周计划内容变得完善。
一、提取原素材周计划docx中的所有信息(2023年、教案内容等),
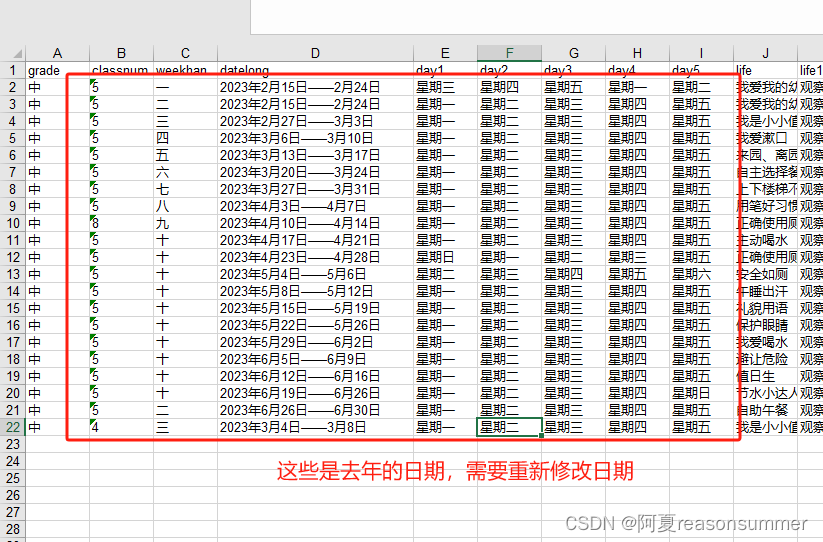
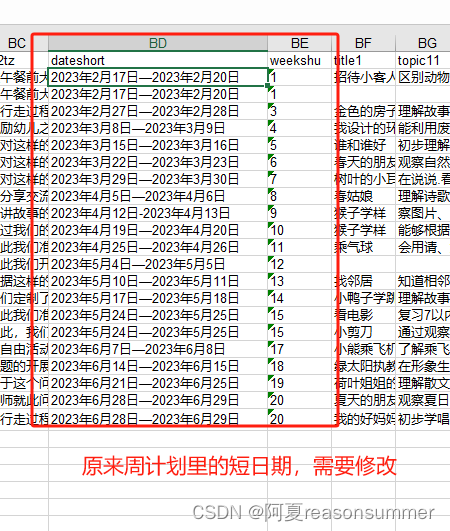

二、将其中的班级、周期、周次、班主任等信息替换成2024年的信息
把提取出来的“仅导出部分”,复制一份,改成“修改补充版”(主要修改基本信息(班级、日期、周次、班主任)
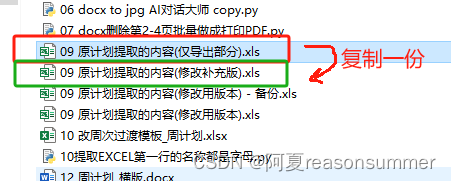
以下是手动修改信息:

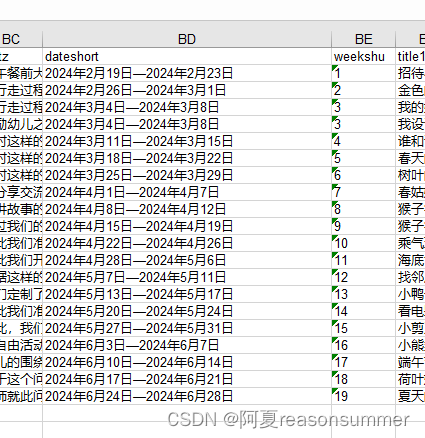

修改一份“改过日期、班级、班主任名字”的EXCEl模板

三、读取“修改补充版”的内容,生成19份Word
代码展示——把添加过新日期、班主任名字的EXCEL,通过Word模板,生成19份新的周计划docx
# 一、导入相关模块,设定excel所在文件夹和生成word保存的文件夹
from docxtpl import DocxTemplate
import pandas as pd
import os
# path=r'D:\\test\\02办公类\\90周计划4份\\01 信息窗'+'\\'
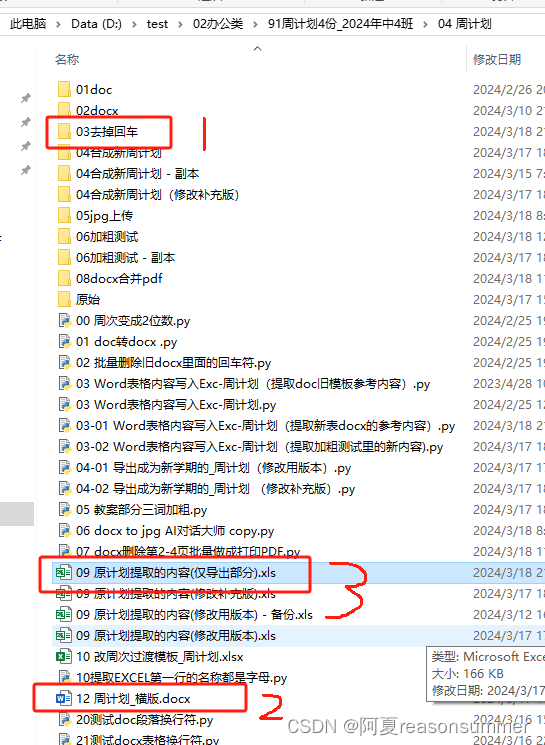
path = r"D:\test\02办公类\91周计划4份_2024年中4班\04 周计划"
print(path)
file_path=path+r'\04合成新周计划(修改补充版)'
print(file_path)
# 二、遍历excel,逐个生成word(WeeklyPlan.docx.docx是前面的模板)
try:
os.mkdir(file_path)
except:
pass
# tpl = DocxTemplate(path+r'\12 周计划_横版.docx')
WeeklyPlan = pd.read_excel(path+r'\09 原计划提取的内容(修改补充版).xls')
# WeeklyPlan = pd.read_excel(path+r'\09 原计划提取的内容(仅导出部分).xls')
grade = WeeklyPlan["grade"].str.rstrip()
classnum =WeeklyPlan["classnum"] # 没有str.rstrip()是数字格式
weekhan =WeeklyPlan["weekhan"].str.rstrip() # str.rstrip()都是文字格式
# day=WeeklyPlan["day"].str.rstrip()
# sc =WeeklyPlan["sc"].str.rstrip()
datelong =WeeklyPlan["datelong"].str.rstrip()
day1 = WeeklyPlan["day1"].str.rstrip()
day2 = WeeklyPlan["day3"].str.rstrip()
day3 = WeeklyPlan["day3"].str.rstrip()
day4 = WeeklyPlan["day4"].str.rstrip()
day5 = WeeklyPlan["day5"].str.rstrip()
life = WeeklyPlan["life"].str.rstrip()
life1 = WeeklyPlan["life1"].str.rstrip()
life2 = WeeklyPlan["life2"].str.rstrip()
sportcon1 = WeeklyPlan["sportcon1"].str.rstrip()
sportcon2 = WeeklyPlan["sportcon2"].str.rstrip()
sportcon3 = WeeklyPlan["sportcon3"].str.rstrip()
sportcon4 = WeeklyPlan["sportcon4"].str.rstrip()
sportcon5 = WeeklyPlan["sportcon5"].str.rstrip()
sport1 = WeeklyPlan["sport1"].str.rstrip()
sport2 = WeeklyPlan["sport2"].str.rstrip()
sport3 = WeeklyPlan["sport3"].str.rstrip()
sport4 = WeeklyPlan["sport4"].str.rstrip()
sport5 = WeeklyPlan["sport5"].str.rstrip()
sportzd1 = WeeklyPlan["sportzd1"].str.rstrip()
sportzd2 = WeeklyPlan["sportzd2"].str.rstrip()
sportzd3 = WeeklyPlan["sportzd3"].str.rstrip()
game1 = WeeklyPlan["game1"].str.rstrip()
game2 = WeeklyPlan["game2"].str.rstrip()
game3 = WeeklyPlan["game3"].str.rstrip()
game4 = WeeklyPlan["game4"].str.rstrip()
game5 = WeeklyPlan["game5"].str.rstrip()
gamezd1 = WeeklyPlan["gamezd1"].str.rstrip()
gamezd2 = WeeklyPlan["gamezd2"].str.rstrip()
theme= WeeklyPlan["theme"].str.rstrip()
theme1= WeeklyPlan["theme1"].str.rstrip()
theme2= WeeklyPlan["theme2"].str.rstrip()
gbstudy = WeeklyPlan["gbstudy"].str.rstrip()
art = WeeklyPlan["art"].str.rstrip()
gbstudy1 = WeeklyPlan["gbstudy1"].str.rstrip()
gbstudy2 = WeeklyPlan["gbstudy2"].str.rstrip()
gbstudy3 = WeeklyPlan["gbstudy3"].str.rstrip()
jtstudy1 = WeeklyPlan["jtstudy1"].str.rstrip()
jtstudy2 = WeeklyPlan["jtstudy2"].str.rstrip()
jtstudy3 = WeeklyPlan["jtstudy3"].str.rstrip()
jtstudy4 = WeeklyPlan["jtstudy4"].str.rstrip()
jtstudy5 = WeeklyPlan["jtstudy5"].str.rstrip()
gy1 = WeeklyPlan["gy1"].str.rstrip()
gy2 = WeeklyPlan["gy2"].str.rstrip()
fk1 = WeeklyPlan["fk1"].str.rstrip()
pj11 = WeeklyPlan["pj11"].str.rstrip()
fk1nr = WeeklyPlan["fk1nr"].str.rstrip()
fk1tz = WeeklyPlan["fk1tz"].str.rstrip()
fk2 = WeeklyPlan["fk2"].str.rstrip()
pj21= WeeklyPlan["pj21"].str.rstrip()
fk2nr = WeeklyPlan["fk2nr"].str.rstrip()
fk2tz = WeeklyPlan["fk2tz"].str.rstrip()
dateshort=WeeklyPlan["dateshort"].str.rstrip()
weekshu=WeeklyPlan["weekshu"]# 没有str.rstrip()是数字格式
title1 = WeeklyPlan["title1"].str.rstrip()
topic11 = WeeklyPlan["topic11"].str.rstrip()
topic12 = WeeklyPlan["topic12"].str.rstrip()
jy1 = WeeklyPlan["jy1"].str.rstrip()
cl1 = WeeklyPlan["cl1"].str.rstrip()
j1gc= WeeklyPlan["j1gc"].str.rstrip()
title2 = WeeklyPlan["title2"].str.rstrip()
topic21 = WeeklyPlan["topic21"].str.rstrip()
topic22 = WeeklyPlan["topic22"].str.rstrip()
jy2 = WeeklyPlan["jy2"].str.rstrip()
cl2 = WeeklyPlan["cl2"].str.rstrip()
j2gc= WeeklyPlan["j2gc"].str.rstrip()
title3 = WeeklyPlan["title3"].str.rstrip()
topic31 = WeeklyPlan["topic31"].str.rstrip()
topic32 = WeeklyPlan["topic32"].str.rstrip()
jy3 = WeeklyPlan["jy3"].str.rstrip()
cl3 = WeeklyPlan["cl3"].str.rstrip()
j3gc= WeeklyPlan["j3gc"].str.rstrip()
title4 = WeeklyPlan["title4"].str.rstrip()
topic41 = WeeklyPlan["topic41"].str.rstrip()
topic42 = WeeklyPlan["topic42"].str.rstrip()
jy4 = WeeklyPlan["jy4"].str.rstrip()
cl4 = WeeklyPlan["cl4"].str.rstrip()
j4gc= WeeklyPlan["j4gc"].str.rstrip()
title5 = WeeklyPlan["title5"].str.rstrip()
topic51 = WeeklyPlan["topic51"].str.rstrip()
topic52 = WeeklyPlan["topic52"].str.rstrip()
jy5 = WeeklyPlan["jy5"].str.rstrip()
cl5 = WeeklyPlan["cl5"].str.rstrip()
j5gc= WeeklyPlan["j5gc"].str.rstrip()
fs1 = WeeklyPlan["fs1"].str.rstrip()
fs11= WeeklyPlan["fs11"].str.rstrip()
fs2= WeeklyPlan["fs2"].str.rstrip()
fs21= WeeklyPlan["fs21"].str.rstrip()
T1 = WeeklyPlan["T1"].str.rstrip()
T2 = WeeklyPlan["T2"].str.rstrip()
T3 = WeeklyPlan["T3"].str.rstrip()
T4 = WeeklyPlan["T4"].str.rstrip()
T5 = WeeklyPlan["T5"].str.rstrip()
# 遍历excel行,逐个生成
num = WeeklyPlan.shape[0]
print(num)
for i in range(num):
context = {
"grade": grade[i],
"classnum": classnum[i],
"weekhan": weekhan[i],
# "day": day[i],
# "sc": sc[i],
"datelong": datelong[i],
"day1": day1[i],
"day2": day2[i],
"day3": day3[i],
"day4": day4[i],
"day5": day5[i],
"life": life[i],
"life1": life1[i],
"life2": life2[i],
"sportcon1": sportcon1[i],
"sportcon2": sportcon2[i],
"sportcon3": sportcon3[i],
"sportcon4": sportcon4[i],
"sportcon5": sportcon5[i],
"weekshu": weekshu[i],
"sport1": sport1[i],
"sport2": sport2[i],
"sport3": sport3[i],
"sport4": sport4[i],
"sport5": sport5[i],
"sportzd1": sportzd1[i],
"sportzd2": sportzd2[i],
"sportzd3": sportzd3[i],
"game1": game1[i],
"game2": game2[i],
"game3": game3[i],
"game4": game4[i],
"game5": game5[i],
"gamezd1": gamezd1[i],
"gamezd2": gamezd2[i],
"theme": theme[i],
"theme1": theme1[i],
"theme2": theme2[i],
"gbstudy": gbstudy[i],
"art": art[i],
"gbstudy1": gbstudy1[i],
"gbstudy2": gbstudy2[i],
"gbstudy3": gbstudy3[i],
"jtstudy1": jtstudy1[i],
"jtstudy2": jtstudy2[i],
"jtstudy3": jtstudy3[i],
"jtstudy4": jtstudy4[i],
"jtstudy5": jtstudy5[i],
"gy1": gy1[i],
"gy2": gy2[i],
"fk1": fk1[i],
"pj11": pj11[i],
"fk1nr": fk1nr[i],
"fk1tz": fk1tz[i],
"fk2": fk2[i],
"pj21": pj21[i],
"fk2nr": fk2nr[i],
"fk2tz":fk2tz[i],
"dateshort": dateshort[i],
"weekshu": weekshu[i],
"title1":title1[i],
"topic11":topic11[i],
"topic12":topic12[i],
"jy1":jy1[i],
"cl1":cl1[i],
"j1gc": j1gc[i],
"title2":title2[i],
"topic21":topic21[i],
"topic22":topic22[i],
"jy2":jy2[i],
"cl2":cl2[i],
"j2gc": j2gc[i],
"title3":title3[i],
"topic31":topic31[i],
"topic32":topic32[i],
"jy3":jy3[i],
"cl3":cl3[i],
"j3gc": j3gc[i],
"title4":title4[i],
"topic41":topic41[i],
"topic42":topic42[i],
"jy4":jy4[i],
"cl4":cl4[i] ,
"j4gc": j4gc[i],
"title5":title5[i],
"topic51":topic51[i],
"topic52":topic52[i],
"jy5":jy5[i],
"cl5":cl5[i] ,
"j5gc": j5gc[i],
"fs1": fs1[i],
"fs11": fs11[i],
"fs2": fs2[i],
"fs21": fs21[i] ,
"T1": T1[i],
"T2": T2[i],
"T3": T3[i],
"T4": T4[i],
"T5": T5[i],
}
tpl = DocxTemplate(path+r'\12 周计划_横版.docx')
tpl.render(context)
tpl.save(file_path+r"\{} 第{}周 周计划 {}({})({}{}班下学期).docx".format('%02d'%weekshu[i],str(weekhan[i]),theme[i],datelong[i],grade[i],classnum[i]))生成了19份改过日期的新周计划,先调整第一页“周计划横版”上的内容
随机打开第8周,

1、家园共育的内容需要修改
2、右侧反思部分内容太少
修改过程:在第8周.docx里面直接修改。

将19周的第一页“横版周计划”内的家园共育和反思与调整“都修改一遍。
代码展示——设置教案里面的“重点提问”“小结”“过渡语”这几个词语”加粗
【办公类-22-13】周计划系列(5-4)“周计划-04 周计划表格内“小结”加粗 (2024年调整版本)-CSDN博客文章浏览阅读934次,点赞25次,收藏10次。【办公类-22-13】周计划系列(5-4)“周计划-04 周计划表格内“小结”加粗 (2024年调整版本)https://blog.csdn.net/reasonsummer/article/details/136706722
'''
docx教案的表格里的“重点提问”“过渡语”“小结”加粗
(使用【办公类-22-05】周计划系列(5)-Word关键词加粗(把所有“小结”“提问”的文字设置 的代码)
作者:VBA-守候、阿夏补充
时间:2024年3月14日
'''
import os
from docx import Document
from docx.enum.text import WD_BREAK
from docx.oxml.ns import nsdecls
from docx.oxml import OxmlElement
from docx.oxml.ns import qn
# 文件夹路
path=r'D:\test\02办公类\91周计划4份_2024年中4班\04 周计划'
from win32com.client.gencache import EnsureDispatch
from win32com.client import constants # 导入枚举常数模块
old_word=['提问','小结','重点重点','过渡语']
new_word=['重点提问','小结','重点','过渡语']
print('-----第1步:把《04合成新周计划》里的资料复制到《06加粗测试)》-----')
#coding=utf-8
import os
import shutil
# old_path = path+r'\04合成新周计划' # 要复制的文件所在目录
old_path = path+r'\04合成新周计划(修改补充版)' # 要复制的文件所在目录
new_path = path+r'\06加粗测试' #新路径
def FindFile(path):
for ipath in os.listdir(path):
fulldir = os.path.join(path, ipath) # 拼接成绝对路径
print(fulldir) #打印相关后缀的文件路径及名称
if os.path.isfile(fulldir): # 文件,匹配->打印
shutil.copy(fulldir,new_path)
if os.path.isdir(fulldir): # 目录,递归
FindFile(fulldir)
FindFile(old_path)
print('-----第2步:提取word路径-----')
from docx import Document
import os
pathall=[]
path =new_path
for file_name in os.listdir(path):
print(path+'\\'+file_name)
pathall.append(path+'\\'+file_name)
print(pathall)
print(len(pathall))# 19
print('------第3步:每一份word替换----')
#————————————————
# 版权声明:本文为CSDN博主「VBA-守候」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
# 原文链接:https://blog.csdn.net/qq_64613735/article/details/125552847
# 部分参数修改
for h in range(len(pathall)): # 20份
path=pathall[h]
wdApp = EnsureDispatch("Word.Application")
# aDoc = wdApp.ActiveDocument # aDoc为当前文件
# wdApp.Visible = False # 程序设置为不可见
aDoc = wdApp.Documents.Open(path) # 打开已经存在的文件
i = 0
# 文档里有多个几个表格
for ta in aDoc.Tables: # 遍历表格,如果无需遍历,直接将ta指定为某个表格即可,如这样指定为第一个表格:ta = aDoc.Tables(1)
# f为每个表格区域查找
f = ta.Range.Find
# 查找框参数
f.ClearFormatting() # 清除原有格式
f.Forward = True # 向前查找
f.Format = True # 查找格式
f.Wrap = constants.wdFindStop # 查找完成即停止
f.MatchWildcards = True # 使用通配符,根据需要设置
# f.Text = '[!^13^l::]{1,}[::]' # 查找的内容 冒号前面的 [!^13^l::] 1代表z只要替换一次,[::]代表冒号。冒号前面包括冒号需要改成加粗
# f.Text = '[{}]{2,}'.format(old_word) # 查找的内容 2代表2个字小结,如果1 ,就会吧“小”开头的字全部替换为小结加粗,,提问会变成两次重点提问.但是这种写法无法用format,
for w in range(len(old_word)):
f.Text = '{}'.format(old_word[w]) # 旧内容重点提问
# 替换框参数
f.Replacement.ClearFormatting() # 清除原有格式
# f.Replacement.Text = '^&' # 替换框内容
f.Replacement.Text = '{}'.format(new_word[w]) # 替换框内容
f.Replacement.Font.Bold = True # 替换文本设置为加粗
f.Execute(Replace=constants.wdReplaceAll) # 执行,查找全部
i += 1
aDoc.SaveAs() # 保存并关闭文件,根据需要设置
aDoc.Close() # 保存并关闭文件,根据需要设置
print(f'完成,共替换了{i}个表格')