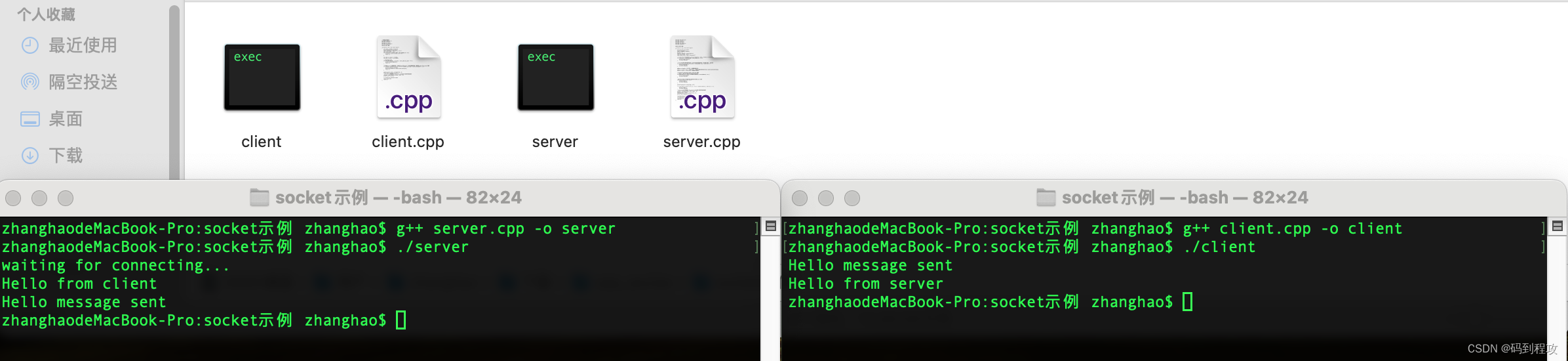
本文整理自阿里云实时计算团队 Apache Flink Committer 和 PMC Member 任庆盛在 FFA 2023 核心技术专场(二)中的分享,内容主要分为以下四部分:
- Source API
- Sink API
- 将 Connecter 集成至 Table /SQL API
- Catalog API
在正式介绍这些 API 的细节之前,要把这些 API 以它们的分层列了出来,下面一层 API 是 DataStream ,针对 Java 开发一般都是基于 DataStream API 直接开发的。再往上一层就是 Table 和 SQL API ,Connector API 分层也是类似的,如果是想实现一个 Connector 的话其实是一个自底向上的过程。首先需要实现 DataStream 层上的 Source 还有 Sink API ,这个是不可或缺的。在实现了 Source、Sink 之后我们为了支持 Table 、Catalog ,需要在其上针对于 Table 层对于 Connector 提供的 API 来进行再次的开发。那接下来的介绍也会按照这个顺序,从底向上来介绍每一层 API 的基本的逻辑以及开发时需要注意的一些问题。

一、Source API

Source API 已经引入很多版本,从 1.12 开始我们有了 Source API 的第一个版本,到 Flink 1.14 开始逐渐达到一个稳定的状态,并标记成 Public。如果了解 Flink 的时间较长,我们之前还有 InputFormat 和 SourceFunction。请大家注意这些 API 在 2.0 都会被弃用掉,如果需要开发一个新的 Connector ,请关注最新的 Source API 。
从整体的设计来看,Source API 使用了主从的结构,和 Flink 的集群结构是类似的,它分为了两个部分,第一部分就是 SplitEnumerator ,它相当于整个 Source 的大脑,从名字上来看它的主要功能就是枚举、分片。
分片是 Source 对外部系统的部分抽象,比如 Kafka 一个分片就是一个 Topic 里的 Partition。如果是一个文件系统的 Source ,那一个 Split 就是一个文件或者是一个文件夹。SplitEnumerator 的工作就是在外部系统当中发现这些分片并把它做成任务分配给最终真正进行干活的,我们称为 SourceReader 。SplitEnumerator 是作业级别的,也就是每个作业或者说每个 Source 是只有一个的, SourceReader 是 Subtask 级别的,整个 Source 的并发是多少,那我们 SourceReader 的实例就有多少。SourceReader 和 Enumerator之间是通过 JM 和 TM 的 RPC 进行通信的,我们在这之上也封装了一些事件能够让 Enumerator 和 Reader 之间进行沟通,我们称之为 Source Event,这样能够更好地协调 Enumerator 和 Reader 之间的任务分配和全局管理的工作。

为了进一步简化用户对 Source 的开发过程,正如上图所示,我们提供 SourceReaderBase 的基类,SourceReader 是一个相当于比较底层的接口,为了简化开发难度,我们也提供了一个 SourceReaderBase ,它进一步把 Source 和外部系统之间的沟通部分和与 Flink 进行协作的部分做了一个拆分,这样做的好处是 Source 开发者能够更加关注和外部系统之间的交互,而不需要过多关注和 Flink 之间的 Checkpoint 处理、会不会影响 Flink 主线程的工作等问题。在 SourceReaderBase 的设计之下,我们又抽出了一个名为 SplitReader 的 API,它才是真正的从外部系统中拉取数据,根据 Enumerator 分配的分片到外部系统中读取数据的部分。数据在读取来之后,SplitReader 会把它放到 SourceReaderBase 中间的一个 Element 队列,实际上就是做了和外部系统以及和 Flink 之间的隔离。在 Flink 这一侧,我们真正运转的是 Flink Task 的主线程,这是一个没有 Box 的模型,它会不断地从中间拉取数据,然后把数据经过 RecordEmitter 的处理后发送到下游。RecordEmitter 的工作主要就是用来做反序列化,将外部系统当中的数据格式转换成下游当中的一些数据格式。

在开发 Source 的时候需要注意的问题有哪些,这个是我在检查 Source 的实现和管理当中总结出来的。第一点是开发的时候一定要注意把和外部系统交互的部分以及和 Flink 交互的部分区分开,比如刚刚讲的 SourceReaderBase 为什么中间要插一个队列,这样就是尽量把和外部系统交互的部分和与 Flink 之间交互的部分区分开。之所以这样做是因为 Flink 的主线程是一个 mailbox 模型 ,包括 Checkpoint 和一些控制信息的传递都是通过这个 mailbox 的线程来做的。如果是我们用它去和外部系统做 IO 的话,这样有可能会对下游算子以及整个 Task 的运行产生一些影响,包括 Checkpoint 的运行有可能也会受到一定程度的影响,所以在开发的时候一定要注意把做 IO 的线程和 Flink 的线程区分开。
第二点是我们 Source 当中提供了很多工具或者说方法,比如 SplitEnumeratorContext 里面有一个 callAsync 方法,很多人在开发 Enumerator 时没有注意到它,自己去起一个线程池或者去起一个线程,很费劲地去处理各个线程之间的协调问题。那通过这个 callAsync 我们已经提供了一个能够给外部系统做 IO 的一个线程的,叫 worker thread。大家就可以直接利用这个工具,我们会在 Flink 里面把一些线程之间的隔离问题处理好。尽量能去复用 SourceReaderBase 和 SplitReader 的时候就尽量去复用它,这样能够大大降低我们的开发难度,总的来说就是尽量自己少造轮子,可以复用现有的轮子。

在近几个版本中我们对 Source 的功能做了增强,首先就是 Hybrid Source ,它有一种典型的用户场景,一些线上用户需要首先去读取 HDFS 或者其他文件系统存储里面的一些存量数据,在读取完已有的存量数据之后进行切换,比如切到 Kafka 或者其他的消息队列来读在线数据,那实际上是需要一个在不同 Source 之间进行切换的能力。Hybrid Source 就是在现有 Source 的基础上,封装这么一层,提供了这样一个多 Source 之间按序切换的能力。两个 Source 之间是有切换顺序的,当一个 Source 比如 FileEnumerator 执行完工作之后,会产生一个 Switch context ,也就是说我会把当前的进度或状态的信息通过这个 SwitchContext 提供给接下来要运行的 Source 。比如说刚提到的场景里面,FileEnumerator 就要告诉 Kafka 的 Enumerator 我现在读到哪, Kafka Enumerator 会根据当前在 Switchcontext 里面提供的位点信息或者说时间信息来正确地启动 Kafka Source 的读取,平滑地迁移到存量阶段或者在线数据的读取当中。从这个架构图中我们也可以观察到,实际上 Hybrid Source 就是对我们现有的 Enumerator 还有 Reader 进行了二次封装,并提供了这样一个工具类来帮助它们进行切换。

第二个在 Source 上面我们支持的功能就是 Watermark Alignment。
先说一下这个问题的背景,不管大家的作业当中有一个 Source 还是多个 Source ,经常会遇到的情况是不同 Source 之间读取的进度差异会很大,比方如果是 Kafka, Source 中的某一个 Partition 因为网络或者其他原因,它的进度远远落后于其他的 Partition。或者有两个 Source ,它们之间因为读取不同的外部系统导致产生不同的进度,这样就会导致一些下游的算子比如说我需要做一些 Join、我需要做 Aggregate,就需要等待所有并发的 Watermark 都前进到同一个位置之后才能够出发计算,只要有一个拖了后腿,那其他人的数据都要在状态里面等,这样就会导致后面某些需要用到的算子状态会越来越大,这实际上就是读取进度的不同所导致的。
针对这个问题,我们提出了这样一个 Watermark Alignment 的机制,在实现的时候,如果是同一个 Source 相对会简单一点,可以直接在这个 Source 的 Coordinator 、或者说是 Enumerator 里面就把这个事情做了。如果跨 Source 之间要实现这个能力,我们是在中间引入了一个叫 CoordinatorStore 的一个组件。它能够让不同的 Source 之间来交换一些信息,在这里面我们需要交换的就是 Watermark 信息, Source Operator 这边会周期性的给自己的 Coordinator 汇报当前处理的进度怎么样,然后 Source Coordinator 会周期性的检查当前进度的最小值,如果发现某些 Operator 读的太快了,有落在后面的并发或者说落在后面的 Source ,会让它先等一等,降低一下读取速度,等大家都追齐之后再往前读。这就是 Watermark Alignment 实现的一个细节。
二 、Sink API
介绍完 Source 之后,我们再为大家介绍一下 Sink API 。Sink API 也是经过了很多版本的迭代,最开始我们有 OutputFormat 和 SinkFunction,同样还要提醒大家这两个 API 在 2.0 里面是被废弃了的。在引入 Sink 之后我们也因为某些需求没法满足,所以推出了两个版本:Sink V1 、Sink V2 ,在这里主要介绍 Sink V2。Sink API 本身的设计相对来讲没有那么复杂,它不涉及到主从结构或者说不涉及到协调能力,Sink 本身只是一个工厂类,是来构建整个 Sink 的拓扑或者说各个组件的。其中最核心的组件就是 SinkWriter ,因为 Sink 本身需要往外写数据,所以不管是什么 Sink ,SinkWriter 一定是必不可少的,它的功能就是把上游的数据进行序列化,然后对应的写出到外部系统。如果说 Sink想要实现 Exactly-once 或者说第二阶段提交的能力,那在此基础上需要提供一个可选的 SinkCommitter 的组件。它们两个之间协调的方式就是在每个 Checkpoint 的时候,SinkWriter 会生成一个叫 Committable 的特殊的消息。
一般来讲数据库可能就是一个 Transaction,当 Checkpoint 触发的时候会产生这样一个 Committable,留给下面的 SinkCommitter,当所有的并发的 Checkpoint 都完成之后,我们会通过 SinkCommitter 将 Committable 提交到外部系统当中去,从而实现这样一个第二阶段提交的过程。有了这两个组件之后我们还是发现有一些需求很难满足,比如说像 Iceberg、Hive 这些 Sink ,它可能会涉及到 Checkpoint 之后再做一些小文件合并等额外的逻辑。为了更大程度地丰富 Sink 可以适用的场景,我们在此基础上又提供了三个部分,分别是 PreWrite 、 PreCommit 、PostCommit。实际上就是允许 Sink 的开发者在 SinkWriter 和 Committer 之间可以插入任意的拓扑逻辑。我可以在在里面串联很多的Operator也好或者说我可以给它们设计不同的并发,从而实现我 Sink 里面的特殊功能。但其实对于绝大多数的 Sink 来讲,这些功能可能用到的机会很少,但是如果你发现我们现有的 Writer和Committer 没有办法满足需求的时候,那就可以直接考虑用这三个自定义组件来实现自己的逻辑。

类似于刚刚介绍的 SourceReaderBase, 为了简化 Sink 的开发,我们提供 Async Sink 的基类,它提供的能力是对一些通用的、异步输出数据逻辑,通过这些场景来提供一个基本的抽象。在这里面涉及的概念比如 ElementConverter 会将我们上游的数据转换成能够对外部系统进行的真正的请求。Async Sink 本身会提供攒批的能力,用户可以通过设置攒批的条件比如当数据达到一定的大小,然后攒批的时间是多少之后,然后将这一批请求的批量提交到外部系统当中去。同样这里面也提供了内置的异常重试逻辑,如果是某次提交失败了,那么在下一次提交的时候再一次尝试把这些数据进行重试提交。基于这些逻辑我们可以看到实际上它只是实现了一个 at-least-once 语义的。但实际上我们生产当中,绝大部分的 Sink 都是 at-least-once ,因为实现一个 Exactly-once 的成本会很大,有一些 Sink 会觉得费了半天劲实现一个 Exactly-once 的 Sink 但是真正应用的人很少,那不如退而求其次,能够把 at-least-once 语义做到极致就可以了。如果你的 Sink 只需要实现 at-least-once 语义,不妨尝试 Async Sink ,能够大大降低大家的开发难度。
三、集成至 Table / SQL API
介绍完下面两层之后,我们再来说一下怎么把 Source Sink 集成至 Table / SQL API 上面去。
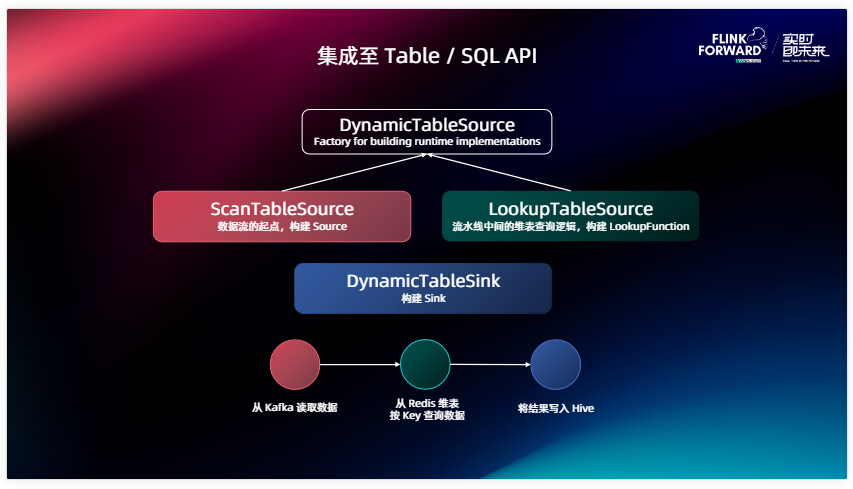
Table SQL API 对于 connector 提供的接口主要是一个层次关系, Source 最基础的接口叫做 DynamicTableSource,它下面有两种集成:ScanTableSource 和 LookupTableSource 。Scan 顾名思义就是对原表的扫描, Lookup 就是我们常说的对维表的典查的逻辑。这里我列了一个样例的kafka,那 ScanTableSource 可能就是我从 Kafka 中读取数据,再读取完之后通过 Redis 维表提供的LookupTableSource 去 Redis 上面进行点查,最终会写到 Sink 当中。比如说我们是 Hive ,会把这个结果通过这个 Sink 对应的接口叫做 DynamicTableSource 来写到外部系统当中去。实际上这三个接口都是对 Source 和 Sink 或者说我们下面会介绍的 LookupFunction 的一个工厂或者说是一个构造器,那真正在下面干活的,就是我们刚刚说的 DataStream API 、Source 和 Sink 。

那么我们先看 ScanTableSource 的接口长什么样。很简单也很好理解,它有两个方法,第一个叫 getChangelogMode,因为我们Flink Source整体是支持三种数据类型的,比如说像 INSERT / UPDATE / DELETE ,如果你的 Source 是一个三种能力都支持的 Source ,比如说我是一个满 MySQL CDC Source ,我能够读取原表里的插入、更新和删除等等,我就需要在 ChangelogMode 里面指定我是支持三个能力的。如果你是一个消息队列的 Source ,比如说 Kafka ,那它就只支持一种 INSERT ,那这里面返回一个支持 INSERT 就可以了。这个方法会被 Planner 拿去用来对一些下游算子的校验等等,包括你的一些逻辑,整体写出来之后看 INSERT / UPDATE / DELETE 下游的算子能不能接受。
第二个方法就是我们怎么真正去从 Table 构建出来 Source 在底层运行的 Source API 的构造器,从 Context 里面我们是可以拿到用户在 Source 在 CREATE TABLE 语句里面的所有配置的。我会根据这些配置,创建出对应的 Source Provider ,把最终运行在里面的 Source 构建出来。

再介绍一下 LookupTableSource ,这个刚刚说是实现了点查的逻辑,但是在 DataStream API 我们没有提供统一的抽象的接口,就是能够提供这样一个典查的能力,那么在这里面我们在 Table 阶段用的是叫 LookupFunction 。
它有两个版本,一个是 LookupFunction ,一个是 AsyncLookupFunction ,分别对应的是同步的实现和异步的实现。我们在 1.16 版本里面也为维表提供了一些辅助的能力,比如说维表的 Cache 能够快速地帮你构建出来一个 LookupFunction 这样一些工具类,这样大家在实现维表的时候也可以去考虑使用它。LookupTableSource 的接口比 Source 的还要简单,它不需要提供 ChangelogMode,因为它的工作就是接一条数据然后将对应的字段到外部系统查一下就可以了。唯一提供的就是 LookupRuntimeProvider 怎么根据用户的的配置来构建出来在 Runtime 当中使用的 LookupFunction 。

然后是 Sink ,Sink 和 Source 相似,两个接口我是不是支持写出 INSERT / UPDATE / DELETE ,给 Planner 做校验,下面就是我们怎么根据用户的配置构建出来 Sink ,这个跟 Source 基本上是完全对称的。

除此之外我们有一些 Source 是支持高级辅助能力的,比如说我可以提供给 Planner 这个信息, Planner 可以把 Projection Pushdown 到这个 Source 里面,把 Filter Pushdown 到另一个 Source 里面,我们在这里面统一地去定义了一些接口比如说 Supports 后面是能力的名字。比如说我们有一个很厉害的 Table Source ,那它是支持 FilterPushdown 和 ProjectionPushdown 的。很简单,我们只需要在这个类上面去实现这两个接口就可以了,根据这些接口里面提供的方法来提供对应的信息,比如怎么把真正的 Pushdown 推到 Source 里面。大家可以在代码里面查看这些所有支持的能力,选择自己能够支持的然后进行对应的实现。
四、Catalog API
在介绍完 Table 层后就是最后一部分 Catalog API 。

在这里我举个简单的例子,写过 SQL 的人都知道,很头疼的一件事就是去写 CREATE TABLE ,我们需要给每一个字段去定义它的类型和名字,比如说我在读取它的上游表,这个表里面定义的字段上百个,这是非常常见的情况,需要一一把它映射到 Flink 的数据类型里面,然后把它罗列在列定义里。除此之外,我们还需要为 Table 写 With 参数,指定 Connector ,配置这个 Connector。某些 Connector 的配置非常复杂,比如说连接一个开启了 SSL 的 Kafka 集群,可能需要写很多的参数才可以把这个 Table 创建出来,这就是我们遇到的第一个问题:CREATE TABLE 语句太冗长了。
第二个问题是配置问题很难复用,比如说我今天为这个集群配置了这个表,写了一堆参数,明天我还需要用这个集群,另一个表又写了一遍参数,这个感觉就很冗余。另外还有一个问题就是刚刚提到的我要给每个字段处理它对应的类型映射,这个也很麻烦。
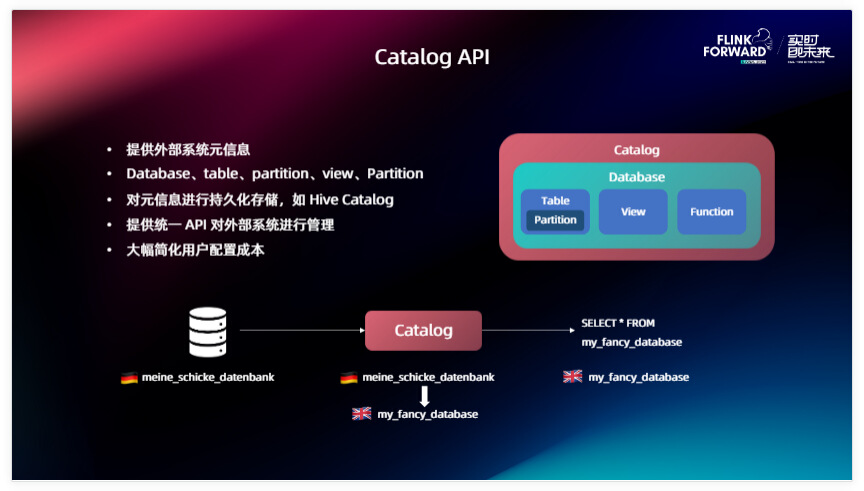
Catalog 的诞生就是为了解决这个问题。Catalog 实际上是一个能够提供外部系统原信息的一个组件,我们在 Catalog 这个 API 里面是提供了一个统一的抽象,和 Flink、Source里面的概念相对应。比如说像 Database 、 Table 、 Partition 、 View 、Function 提供这些统一的抽象概念,我们在开发 Catalog 的时候只需要把外部系统对应的概念和它们进行一一映射就可以了。这个也不是必须的,比如说我外部系统没有 Partition 、Function 这些的话就可以不实现它。Catalog 的其他能力还有能够对原信息进行一个持久化的存储,对于 Hive 的话我们可以对接到 Hive 的 Catalog 里面,把一些表的信息存储到里面进行一个持久化,方便后面进行复用。
除此之外 Catalog 提供了一个统一的 API 能够对外部系统进行一个统一的管理。当我们提供了 catalog 之后就可以大幅简化用户的配置成本。举个例子,外部系统各种各样,可能有各种各样的数据库类型,它们对自己管理数据库的概念又不一样,可能有的有 Schema、有的没有 Schema,有的叫 Database 、有的叫 Namespace,经过我们统一的 Catalog API 的这层翻译之后,能够把它们对应的概念一一映射到 Flink 里面的概念当中,用户在使用的时候接触到的就只有一种概念,我们在 Flink 里面定义的这些顶层逻辑,直接通过 Catalog 里面选择这个表就可以把这个表的数据拉出来了。

在这里举个例子,大家可能对 MySQL 这些数据库可能都比较好映射,它里面有 Database 、 Table 。那不典型的也不是这种结构化存储的比如说 kafka ,它能不能支持 Catalog 呢?当然是可以的。在这里面我们把一个 Kafka Catalog 映射到一个 Kafka 集群上面,一个 Table 对 kafka 来说就是一个 Topic ,在这里面 kafka 可能没有那么多层级的概念,可能没有一个 Database,那我就不映射 Database,给一个默认的就可以了,在实现 Kafka Cluster 的时候可以让用户配置这个 Topic 里面读取的数据类型。在这里面我举个例子,Kafka 里面存储的是一个 JSON 类型,那 Catalog 本身就可以对每一种字段的类型根据它 JOSN 的内容进行一个推导,把每一条数据映射到表里面的每一个行,这样就完成了对 Kafka 统一的抽象,对终端用户来讲如果使用这个 Kafka catalog ,就没有必要反复去配置这个 Kafka 集群的一些信息,想要哪一个 Topic 的数据,一个 SELECT 语句就可以直接拿出来,这样能够大大降低用户的使用门槛。

有了 Catalog 之后,基于 Catalog 可以做一些更丰富的事情,比如血缘信息管理。在 1.18 和 1.19(还未发布)两个版本当中 Flink 也会对血缘信息做一些支持。现在已经实现的部分 FLIP-294、Catalog Modification Listener ,也就是我们可以在 Catalog 上面注册一个监听器,如果 Catalog 有任何的变更,比如说加表、删表,这些信息都会通过 Listener 汇报到对应的外部组件里面。在血缘信息管理当中,它汇报的对象就是一个 MetadataPlatform ,比如说像 Atlas、Datahub 这些原信息管理系统,相对应的如果有建表我会在原信息管理平台上面创建对应的数据节点,删表之后会将其进行移除。
在未来 1.19 版本里面我们预计要实现的就是这个对作业血缘的监听,刚刚我们通过对 Katalog 的监听是对 MetadataPlatform 的一些数据节点进行一个创建,怎么把点之间的线连接起来呢?通过 FLIP-314 之间定义的一些接口它会对作业的启动、停止、暂停等基础的信息进行监听。如果一个作业启动之后,可以通过拿到它的 Source 和 Sink 把两个数据节点之间的线连接起来,这样就能够完整的获得这个 Flink 集群上面运行的数据血缘或者说节点之间的一个上下游逻辑,方便用户对自己的数据流向有更充分的管理。

再回到这个图,刚刚的介绍顺序是由底向上的,当大家想要实现自己的 Connector 时,首先需要考虑要接触到的一定是这个 Source 和 Sink ,它们是在 DataStream 层上面的实现,也是上面这些 API 的基石,想实现一个 Connector 一定要实现这两个接口。如果说 Connector 想支持 SQL、还有 Table 丰富的生态,我们需要在它的基础上实现 DynamicTableSource 和 DynamicTableSink , 它们可以理解成下面 Source 和 Sink 的构造器。如果想进一步简化用户使用 Connector 的成本,不要每次都写一堆很冗长的 Table ,我们对它进行一个复用,然后就可以去对接到 Catalog API 上面,把自己外部系统的一些概念抽象到 Flink 上面去,这样用户可以直接从你的外部系统 Catalog 里面 Select 数据出来, 不需要反复的去定义字段、定义配置等等,能够降低用户的使用门槛。提供了 Catalog 之后我们就能够天生的获得一些血缘管理或者说原信息管理的能力。