论文地址:https://arxiv.org/abs/1512.03385
摘要
重新定义了网络的学习方式
让网络直接学习输入信息与输出信息的差异(即残差)
比赛第一名
1 介绍
不同级别的特征可以通过网络堆叠的方式来进行丰富
梯度爆炸、梯度消失解决办法:
1.网络参数的初始标准化
2.网络中间层的标准化(BN)
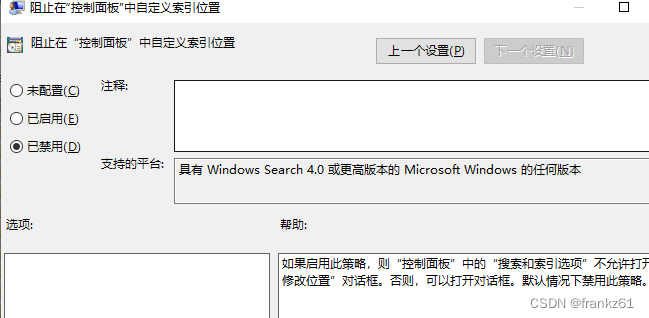
退化的解决办法:
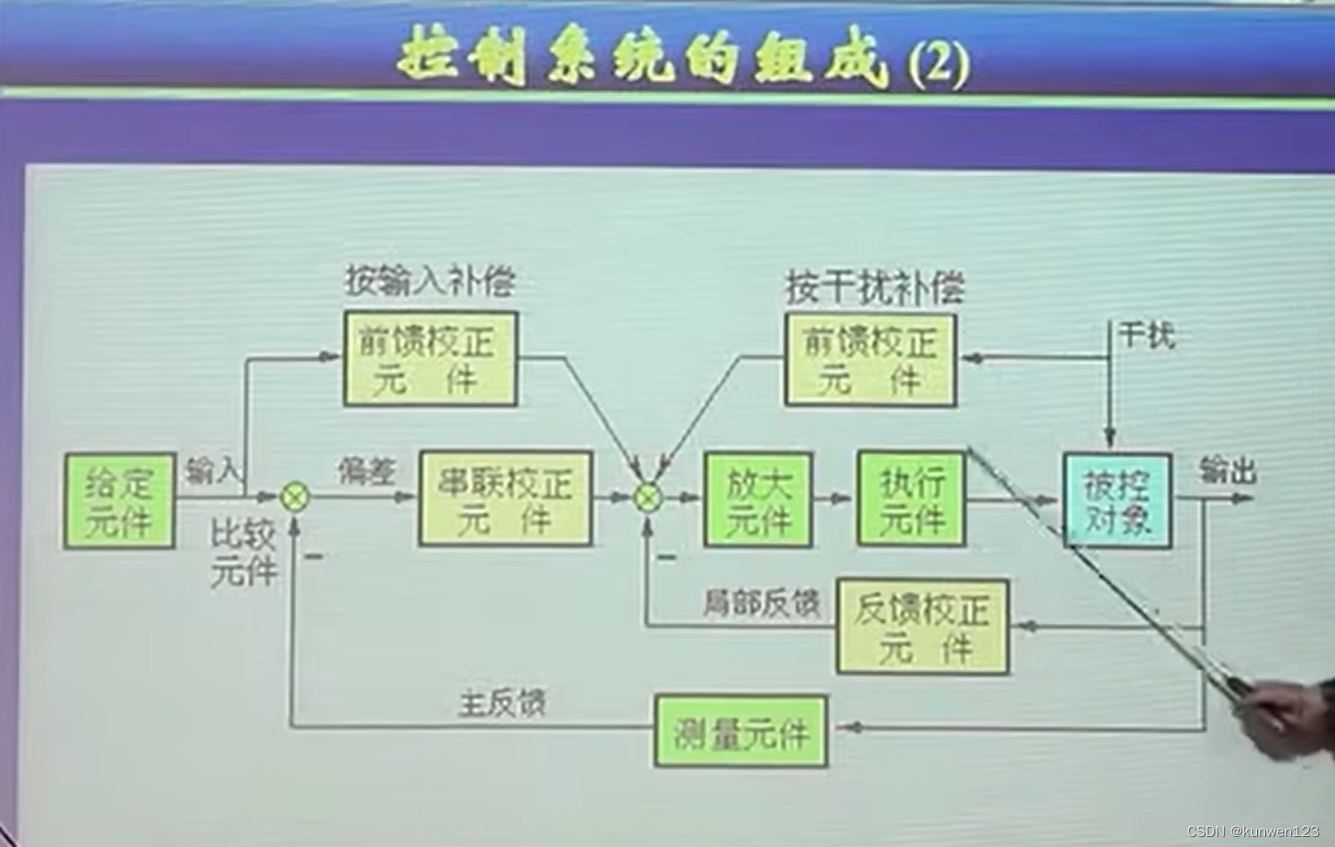
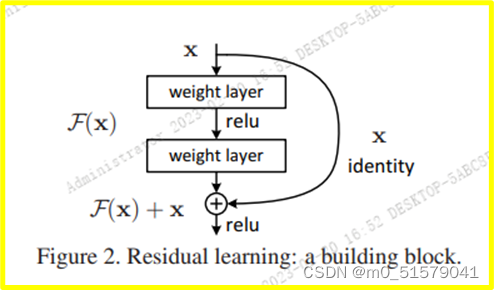
残差模块
shortcut可以跳过一层或者多次来进行实现恒等映射,且没有增加额外的参数,也没有增加计算的复杂度
ResNet复杂度比VGG-16要低
2 相关工作
residual representations:
shortcut connections:不带门功能
3 深度残差学习
3.1 残差学习
残差函数 F(x)=H(x)-x
很难将非线性的层训练成恒等映射
但是在残差的框架下,如果恒等映射是最优的结果,那么网络只需要让新增加的非线性层的权重变为0,即可达到拟合恒等映射的目的。
在实际的例子中,恒等映射或许不是最优的结果,但是却有助于解决训练退化的问题。(至少不会变差)
3.2 shortcut实现identity mapping
y=F(x,{Wi})+x
解决x和F(x)维度不一样的问题:
y=F(x,{Wi})+Ws*x (这种方法叫投影映射,会带来额外的参数和计算量)
3.3 网络结构
普通网络:
残差网络:
维度增加:
(A) 新增的维度用0代替(zero-padding)
(B) 线性投影(通过1x1卷积实现,会带来额外的参数和计算量)
尺寸不一致:
使用stridr=2的卷积来让他们统一。(下采样的一种,会带来额外的参数和计算量)
3.4 部署
在卷积和激活之间添加了BN(方差偏移)
SGD优化器
mini-batch size=256
learning rate=0.1( The learning rate starts from 0.1 and is divided by 10 when the error plateaus)
momentum=0.9
没有使用dropout(与BN不兼容)
4 实验
4.1 ImageNet分类
训练集:128万
验证集:5万
测试:10万
普通网络:
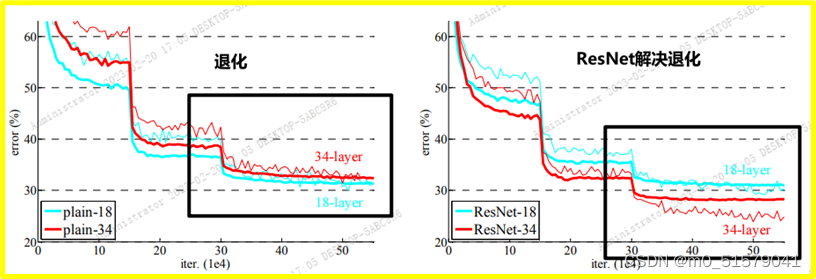
观测到训练退化的问题:
34层网络比18层网络有更高的训练误差
这种退化现象不太可能是由梯度消失引起的:
因为BN的使用,所以前向传播的过程中不会出现0方差的问题
因为BN的使用,反向传播的过程中所展示出现的梯度也是健康的
猜测是由于更深的普通网络就是有指数级的更低的收敛速度。(有待验证)
残差网络:
18层 34层
对应增加的维度,使用0进行填充(方案A),所以相对于普通网络,没有增加新的参数
发现:32层残差网络展示了相当低的训练误差,并且可以泛化到验证集
说明:残差网络结构可以解决退化问题
恒等映射VS投影映射:
投影映射并不能在本质上解决退化的问题,而且引入了新的参数。所以为了减少内存使用,时间的复杂度和模型的大小,选择主要使用恒等映射(parameter-free),维度增加时,使用0进行填充。
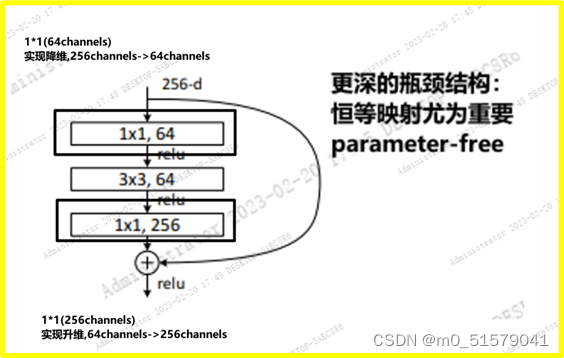
更深的瓶颈结构:
无参数的恒等映射对应瓶颈结构来说尤其重要,轻量化。
50层残差结构:
101层和152层残差结构:
和其他先进的方法比:
4.2 CIFAR-10数据集测试和分析
层响应分析
开发大于1000层的网络
4.3 在PASCAL和MS coco上的目标检测
在其他的识别任务上也有很好的泛化能力。
比赛第一名