在人工智能的世界里,多模态学习不断地展现出其重要性。这个领域的迅速发展不仅促进了不同类型数据之间的深度融合,还为机器理解世界提供了更加丰富和细腻的视角。随着科技的不断演进,人工智能模型已经开始渐渐具备处理和理解从文本、图像,到声音乃至视频等多种类型数据的能力。 —— AI Dreams, APlayBoy Teams!
博客首发地址:一文搞懂多模态:BeiT-3之前的14个多模态+4个周边原理解读 - 知乎
在这篇博客中,我们将共同回顾2022年之前出现的一系列具有里程碑意义的大型多模态模型。从BERT到BeiT-3,每个模型都在多模态学习的发展历程中扮演了不可或缺的角色,它们的每一次迭代都是技术发展的重要一步。
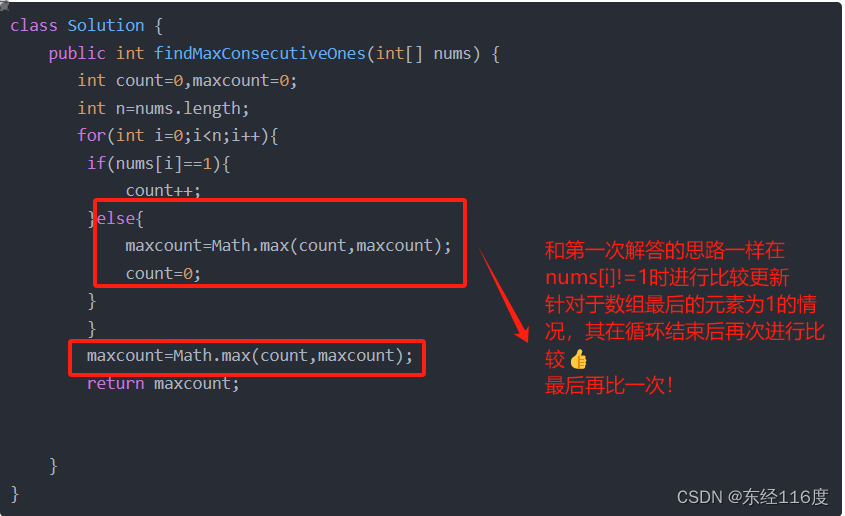
我们首先通过表格形式概述涉及到模型的一些基本信息,然后用一幅关系图片来初步认识这些模型之间的关系及其演进轨迹,这样将为我们在深入探讨这些模型的细节之前,构建一个清晰的理解框架。
在文章的后续部分,我们将详细探究每个模型的基本信息、框架、核心特点以及一些简单的应用,揭示它们如何独立地推动多模态学习领域的发展。无论你是一名深耕AI领域的研究者,还是对最新技术动态保持着浓厚兴趣的读者,这场深入浅出的串讲都将为你敞开通往多模态学习世界的大门。
模型列表
以下是一些主要的多模态模型,包括它们的简称、组织、发布时间、依赖技术和简介。
| 简称 | 组织 | 时间 | 依赖 | 简介 |
|---|---|---|---|---|
| Bert | 2018 | Transformer架构 | 文本无监督模型 | |
| UNITER | Baidu | 2019 | Bert | 视觉端使用检测框做多模态学习 |
| OSCAR | Microsoft | 2020 | Bert | 视觉端使用检测框做多模态学习 |
| ViT | 2020 | Bert | 有监督视觉模型 | |
| Beit | Microsoft | 2021 | Bert和ViT | 利用dVAE把连续的特征变成离散的token, 对mask掉的token做预测 |
| MAE | 2021 | ViT | 带掩码的视觉自编码模型 | |
| CLIP | OpenAI | 2021 | Bert和ViT | 文本和图像做对比学习 |
| ViLT | NAVER AI Lab | 2021 | OSCAR和UNITER | 把目标检测从视觉端拿掉,增加模态融合的权重 |
| ALBeF | Salesforce | 2021 | ViLT和CLIP | 多模态融合之前对齐模态特征 |
| VLMo | Microsoft | 2021 | ViLT和ALBeF | 提出混合模态专家结构,不同模态权重共享,分阶段训练 |
| SimVLM | 2021 | ViT | 原始结构中直接包含encoder、decoder、单模态、多模态 | |
| BeiTV2 | Microsoft | 2022 | Beit | 优化了Beit中视觉标志的生成结构 |
| VL-BeiT | Microsoft | 2022 | Bert和Beit | 单模态和多模态结构共享,对数据进行masked预测 |
| FLIP | Meta | 2022 | MAE | 带掩码图像和文本的对比学习 |
| CoCa | 2022 | SimVLM和ALBeF | 文本端只用decode训练,提升训练效率 | |
| BLIP | 2022 | ALBeF和VLMo | 通过decoder生成字幕,字幕器和过滤器引清晰数据,文本decoder、encoder共享权重 | |
| BeiT-3 | Microsoft | 2022 | VLMo、VL-BeiT和BeitV2 | 所有技术的大一统 |
关系图

相关工作简
Transformer架构
Transformer 架构是自然语言处理(NLP)和机器学习领域的一项里程碑创新。自从 Google 在 2017 年的论文《Attention Is All You Need》中首次介绍以来,Transformer 已成为现在各种模型的核心,如 BERT、GPT 系列,以及接下来提到的所有工作。
Transformer 架构

完全基于“注意力机制”(attention mechanism),摒弃了以往依赖循环神经网络(RNN)和卷积神经网络(CNN)的设计,并基于之前的Attention工作实现。它的主要优势在于能够并行处理序列数据,从而显著提升效率,并能更好地处理长距离依赖问题。
Transformer 架构的强大表现力和高效率使其成为了自然语言处理(如机器翻译、文本摘要、问答系统)和近年来多模态学习(如图像文字融合、语音处理)等领域的首选模型。
关键组件
- 注意力机制(Attention Mechanism):自注意力(Self-Attention):允许模型在处理序列的每个元素时,同时考虑序列中的所有其他元素,从而捕获序列内部的复杂关系。多头注意力(Multi-Head Attention):通过并行地运行多个自注意力层,Transformer 能够在不同的位置捕捉序列的不同方面,增强模型的表达能力。
- 位置编码(Positional Encoding): 由于 Transformer 不使用循环层,因此需要另一种机制来理解序列中元素的顺序。位置编码通过添加一些关于元素位置的信息到输入嵌入中,使模型能够利用序列的顺序。
- 编码器(Encoder):由多个相同的层组成,每层都有多头注意力机制和简单的前馈神经网络。
- 解码器(Decoder):同样由多个层组成,但除了包含与编码器中相同的层外,还额外添加了一个多头注意力层来关注编码器的输出。
- 前馈神经网络(Feed-Forward Neural Networks): 在每个编码器和解码器层中,都包含一个简单的前馈神经网络,用于进一步处理数据。
- 规范化层(Normalization Layers): 每个多头注意力和前馈神经网络操作后都跟随一个规范化层,用于稳定训练过程。
工作原理
- 编码过程:输入序列被输入到编码器,每个编码器层通过自注意力机制学习输入数据的内部结构,并通过前馈网络进一步处理信息。
- 解码过程:解码器接收编码器的输出,并通过自注意力机制学习输出序列的内部结构。额外的注意力层使解码器能够关注到输入序列的相关部分。
- 输出生成:最后,解码器输出经过一个线性层和 softmax 层,以生成最终的输出序列。
Bert
BERT(Bidirectional Encoder Representations from Transformers)是一种在自然语言处理(NLP)领域的预训练模型。由 Google 在 2018 年推出,BERT 的核心创新是它的双向 Transformer 架构,它在处理文本任务时能够考虑到整个句子的上下文信息。
BERT 不仅在纯文本领域表现卓越,也在多模态学习中显示了其强大的潜力和灵活性。它通过提供高质量的文本表示,为多模态任务中的语言成分提供了坚实的基础,从而在诸如图像-文本融合、跨模态理解等领域取得了显著成果。
BERT 架构

BERT 主要由 Transformer 的编码器组成。与标准的 Transformer 不同,BERT 只使用编码器部分,并在这个基础上进行预训练和微调,以适应不同的下游任务。
关键特点
- 双向上下文理解:传统的语言模型通常只能从左到右或从右到左考虑上下文。BERT 的独特之处在于它同时从两个方向学习上下文,这意味着每个词语都是在整个句子的上下文中进行理解和编码的。
- 预训练(Pre-training):BERT 首先在大规模文本数据上进行预训练,学习语言的基本规律。这个阶段主要包括两种任务:掩码语言建模(Masked Language Modeling, MLM)和下一句预测(Next Sentence Prediction, NSP)。
- 微调(Fine-tuning):预训练完成后,BERT 可以通过少量标注数据对特定任务进行微调,以适应诸如情感分析、问答系统等不同的NLP任务。
- 高效的表示能力:BERT 的双向特性和深度网络结构赋予了其高效的文本表示能力,能够捕捉复杂的语言特性和微妙的语义差异。
应用
- 图像和文本融合:在处理包含文本和图像的任务时,如图像描述、视觉问答等,BERT 可以用来理解和处理文本部分。它与图像处理模型(如CNN)相结合,共同提供更丰富、更准确的多模态输入表示。
- 跨模态理解和检索:在跨模态理解和检索任务中,例如,在一组图像中找到与特定文本描述相匹配的图像,BERT 可以有效地处理文本查询,提升检索的准确性。
- 融合学习框架的基础:BERT 的成功启发了一系列多模态模型的发展,这些模型将 BERT 作为处理文本的组件之一,与处理图像、音频等其他模式的组件结合,形成更全面的多模态学习框架。
ViT
Vision Transformer(ViT)是一种应用于计算机视觉领域的模型,由 Google 在 2020 年提出。它是首个成功地将 Transformer 架构应用于图像处理的尝试,打破了此前卷积神经网络(CNN)在图像处理领域的主导地位。
ViT 的提出不仅在图像处理领域引发了一场变革,也为多模态学习提供了新的可能性。通过其在图像理解方面的强大能力,ViT 为多模态领域带来了新的视角和方法,加深了我们对不同模态数据之间关系的理解。
ViT 架构

ViT 摒弃了传统的卷积层,而是将图像分割成一系列小块(称为“patch”),并将它们线性嵌入到一个一维序列中,之后通过标准的 Transformer 架构对这些序列进行处理。
关键特点
- 图像分割为 Patch:ViT 首先将输入图像划分为固定大小的小块(例如16x16像素的patch)。这些小块被视为与NLP中的词语类似的基本单元。
- 线性嵌入和位置编码: 每个 patch 被线性嵌入到一个高维空间,并添加位置编码以保留其在原始图像中的相对位置信息。
- 标准 Transformer 编码器:这些嵌入的 patch 然后被送入一个标准的 Transformer 编码器中进行处理。这与 NLP 中处理词语序列的方式类似。
- 分类头:在编码器的最后,ViT 添加一个分类头,通常是一个简单的线性层,用于分类任务。
应用
- 与文本模型结合:ViT 可以与如 BERT 等文本处理模型结合,形成一个强大的多模态框架,用于处理同时包含图像和文本的任务,例如图像描述和视觉问答。
- 特征提取:在多模态任务中,ViT 可以作为一个有效的特征提取器,将图像转换为高质量的特征表示,这些特征随后可以与其他模态的特征(如文本、音频)结合,进行更深层次的分析和学习。
- 跨模态表示学习:ViT 的出现促进了跨模态表示学习的发展,即在单一框架内同时处理和学习多种不同模态的表示,进一步推动了多模态研究的深度和广度。
MAE
Masked Autoencoder (MAE) 是一种应用于计算机视觉领域的模型,由 Facebook 在 2021 年提出。MAE 是一种自监督学习方法,主要用于有效地训练大型视觉模型。它通过随机遮蔽输入图像的一部分,然后训练模型去重建这些被遮蔽的部分,从而学习到有意义的图像表示。
MAE 作为一种高效的自监督学习方法,在单模态图像处理领域表现出色,并且它的原理和方法也为多模态学习的发展提供了新的视角和思路。通过它的自监督学习机制,MAE 在无需大量标注数据的情况下,也能学习到深刻且有意义的特征表示。
MAE 架构

MAE 的核心思想是利用自编码器(autoencoder)架构,它包括两个主要部分:编码器(encoder)和解码器(decoder)。编码器用于处理输入图像的一部分,而解码器则负责重建整个图像。
关键特点
- 图像分割与遮蔽:输入图像首先被分割成小块(类似于 ViT 中的 patch)。然后,随机选择一些 patch(通常是大部分)进行遮蔽。
- 编码器处理未被遮蔽的 Patch:编码器只对未被遮蔽的 patch 进行处理。这种方式减少了模型需要处理的数据量,从而提高了训练效率。
- 解码器重建整个图像:解码器的任务是根据编码器的输出重建整个图像,包括被遮蔽的部分。这种重建过程迫使模型学习到有意义的图像特征和内在结构。
- 自监督学习:MAE 的训练过程是自监督的,意味着它不需要标注数据。模型通过预测被遮蔽 patch 的内容进行学习。
应用
- 特征表示的丰富性:MAE 强迫模型关注图像的细节和结构,这使得其学到的特征表示更为丰富和具有表现力。在多模态场景中,这种丰富的视觉特征可以与其他模态(如文本)的特征结合,提升整体模型的性能。
- 自监督学习在多模态中的应用:MAE 展示了如何通过自监督学习有效地训练大型模型。这种方法同样可以应用于多模态学习,特别是在缺乏大量标注数据的情况下。
- 多模态数据融合:MAE 的思路可以启发多模态领域的研究者探索类似的自监督方法来处理和融合不同模态的数据,从而提升跨模态理解和生成的能力。
模型详细介绍
UNITER
UNITER(Universal Image-Text Representation)是一种多模态模型,由 Baidu Research 在 2019 年提出。UNITER 专注于理解和融合图像和文本数据,以实现高效的多模态表示学习。它在多种图像-文本相关任务中表现出色,如图像描述、视觉问答和跨模态检索。
UNITER 通过其强大的跨模态表示学习能力,在多模态领域取得了显著成就。它不仅能够有效地处理和融合图像和文本信息,还能在各种复杂的多模态任务中表现出色,是多模态研究和应用的一个重要里程碑。
UNITER 架构

UNITER 结合了自然语言处理和计算机视觉的进展,采用类似于 BERT 的架构来处理跨模态数据。它通过联合训练图像和文本的方法,学习两种类型数据的统一表示。
关键特点
- 跨模态输入处理:UNITER 将图像信息(例如,对象检测的特征)和文本信息(词语的嵌入表示)作为输入,并在单个模型中进行处理。
- 自注意力机制:与 BERT 类似,UNITER 使用 Transformer 架构的自注意力机制,允许模型捕获图像和文本间复杂的关联和依赖关系。
- 多种预训练任务:NITER 采用多种预训练任务,包括掩码语言建模、图像区域特征预测和图像-文本匹配等,来增强跨模态理解。
- 高效的多模态融合:通过深层次的跨模态融合,UNITER 能够理解图像内容和文本描述之间的细微关系,提供丰富的多模态信息。
应用
- 图像描述与视觉问答:UNITER 可以生成与图像内容相关的描述性文本,或在视觉问答任务中理解和回答与图像相关的问题。
- 跨模态内容检索:它能够根据文本查询检索相关的图像,或者根据图像内容找到描述性的文本。
- 图像-文本融合分析:在进行情感分析或细粒度分类时,UNITER 能够有效融合视觉和语言信息,提供更全面的分析。
OSCAR
OSCAR(Object-Semantics Aligned Pre-training)是一种多模态模型,由 Microsoft Research 在 2020 年提出。OSCAR 的核心目标是有效融合图像和文本信息,特别强调在视觉-语言预训练中利用对象级别的语义信息。这一模型在多种图像-文本相关任务中表现优异,例如图像标注、视觉问答和跨模态检索。
OSCAR 通过引入对象级别的语义信息,显著提升了多模态学习的效果。它不仅能够更好地处理和融合图像和文本信息,还能在多种多模态任务中展现出色的性能,是多模态领域的一个重要进展。
OSCAR 架构

OSCAR 结合了最新的自然语言处理和计算机视觉技术,采用基于 Transformer 的架构来处理跨模态数据,并特别注重在预训练阶段融合图像的对象级语义信息。
关键特点
- 对象标签作为锚点:OSCAR 的一个创新之处在于使用检测到的图像对象标签作为额外的“锚点”,来提升图像和文本之间的语义对齐。
- 对象-语义对齐预训练:OSCAR 在预训练中引入对象标签,以及文本中的词语,通过对象-语义对齐的方式增强模型对跨模态内容的理解。
- Transformer架构:OSCAR 使用了类似于 BERT 的 Transformer 架构,这使得模型能够有效处理文本信息,并与图像特征进行融合。
- 多任务预训练策略:OSCAR 通过多种预训练任务,如掩码语言建模和对象标签预测,来增强其多模态表示的能力。
应用
- 图像标注和视觉问答:OSCAR 能够生成准确的图像描述,并在视觉问答任务中有效地回答与图像内容相关的问题。
- 跨模态检索:利用其强大的语义对齐能力,OSCAR 可以实现根据文本查询检索相关图像,或反向根据图像内容找到相应的文本描述。
- 图像-文本融合分析:OSCAR 在处理需要深度图像-文本融合的任务时表现优秀,如情绪分析或复杂场景的细粒度分类。
Beit
Bidirectional Encoder Representations from Image Transformers(BeiT)是一种在计算机视觉领域的模型,由 Microsoft Research 在 2021 年提出。BeiT 是将 BERT 的预训练方法应用于图像处理的尝试,它通过对图像中的像素进行遮蔽并训练模型预测这些被遮蔽像素的内容来学习有用的图像表示。
BeiT 通过引入 BERT 风格的预训练策略到图像领域,不仅在图像处理方面取得了显著成果,而且为多模态学习的发展提供了新的思路。它的成功表明,NLP 中的一些先进技术可以通过适当的调整和应用,同样在视觉甚至其他模态中发挥重要作用。
BeiT 架构

BeiT 创新地将 BERT 预训练策略引入图像处理领域。它使用类似于 BERT 的“掩码语言模型”(MLM)的策略,但是应用于图像的像素而非文本的单词。
关键特点
- 图像分割与遮蔽:BeiT 首先将输入图像分割成小块(patch),类似于 ViT。然后,随机遮蔽其中的一部分 patch。
- 离散变分自编码器(dVAE):BeiT 使用离散变分自编码器(dVAE)将图像的 patch 转换为一系列离散的 token。这一步骤类似于在 NLP 中将单词转换为词嵌入。
- 预测被遮蔽像素的内容:模型的训练目标是预测被遮蔽 patch 的原始内容。这一过程迫使模型学习到图像的内在结构和重要特征。
- 自监督预训练:BeiT 的预训练过程是自监督的,它不依赖于标注数据,而是通过重建任务来学习图像的特征。
应用
- 多模态特征学习:在多模态任务中(如图像-文本融合、视觉问答等),BeiT 提供的丰富和有效的图像表示可以与文本模型(如 BERT)相结合,提供更深层次的跨模态理解。
- 跨模态预训练策略:BeiT 展示了如何将预训练策略从一种模态(如文本)成功迁移到另一种模态(如图像),为多模态领域中类似的策略迁移提供了范例。
- 提高多模态模型的效率:通过自监督学习,BeiT 在不依赖大量标注数据的情况下学习有效的图像表示,这种方法可以用来提高多模态模型在处理大规模未标注数据时的效率。
CLIP
CLIP(Contrastive Language–Image Pretraining)是由 OpenAI 在 2021 年提出的一种创新的多模态模型。CLIP 的目标是理解广泛的视觉概念并与自然语言有效地关联起来。它通过大规模的图像和文本对进行训练,学会将图像和描述性文本联系起来。下面详细介绍 CLIP 的核心特点及其在多模态领域中的应用。
CLIP 通过其独特的对比学习方法和大规模预训练,在多模态领域实现了突破性的进展。它不仅能够理解广泛的视觉概念与自然语言之间的复杂关系,还展现出在零样本学习环境下的强大能力,这为未来的多模态研究和应用提供了新的可能性。
CLIP 架构

CLIP 采用一种对比学习(contrastive learning)的方法,分别使用两个神经网络处理图像和文本数据,然后训练这两个网络,以使相关联的图像和文本靠近彼此,而不相关的则远离。
关键特点
- 双网络结构:CLIP 包含两个主要组件:一个视觉模型(通常是一个卷积神经网络)用于处理图像,以及一个语言模型(通常是一个 Transformer)用于处理文本。
- 对比学习:CLIP 使用对比学习方法来训练模型,目的是最大化相关图像和文本之间的相似性,同时最小化不相关对之间的相似性。
- 大规模预训练:CLIP 在大规模的图像-文本对数据集上进行预训练,这使其能够学习到广泛的视觉概念和语言表示。
- 零样本学习能力:CLIP 能够在没有特定任务标注数据的情况下进行“零样本”学习,即直接对新任务进行推理,这得益于其广泛的预训练。
应用
- 图像分类和检索:CLIP 可以用于图像分类任务,特别是在零样本的场景中,以及根据文本描述检索相关联的图像。
- 跨模态理解:由于其强大的预训练,CLIP 能够理解复杂的视觉-语言关联,适用于解释性较强的任务,如图像标注和视觉问答。
- 数据集偏差校正:CLIP 显示出对数据集偏差具有较强的鲁棒性,能够在多样化的数据集上保持一致的性能。
ViLT
ViLT(Vision-and-Language Transformer)是一个多模态模型,由 NAVER AI Lab 在 2021 年提出。ViLT 旨在更高效地融合视觉和语言信息,特别是在减少对昂贵的图像特征提取器依赖的同时保持优异的性能。这使得 ViLT 在多种视觉-语言任务上表现出色,如图像标注、视觉问答和跨模态检索。
ViLT 通过简化多模态处理流程,并利用 Transformer 的强大能力,在多模态学习领域实现了显著的进步。它为高效融合视觉和语言信息提供了一种新的方法,特别适合于资源受限或需要快速处理的应用场景。
ViLT 架构

ViLT 是一种端到端的多模态模型,直接在图像 patch 和文本 token 上应用 Transformer 架构,避免了传统多模态方法中常见的复杂的图像预处理步骤。
关键特点
- 端到端的多模态处理:ViLT 能够直接在原始图像 patch 和文本 token 上进行处理,简化了多模态输入的处理流程。
- 减少对重型图像特征提取器的依赖:与依赖复杂卷积神经网络(CNN)提取图像特征的方法不同,ViLT 直接处理图像 patch,减少了计算成本和模型复杂性。
- Transformer 架构:ViLT 利用 Transformer 的强大能力来处理图像和文本信息,实现有效的跨模态融合。
- 强大的跨模态表示能力:通过端到端的学习方式,ViLT 能够捕捉图像和文本间复杂的关系,提供丰富的跨模态信息。
应用
- 图像标注与视觉问答:ViLT 可用于生成与图像内容相关的文本描述,或在视觉问答任务中有效回答与图像相关的问题。
- 跨模态内容检索: 利用其跨模态表示能力,ViLT 可以实现基于文本描述的图像检索,或根据图像内容找到相应的文本描述。
- 高效的多模态分析:由于其端到端的架构和减少对重型特征提取器的依赖,ViLT 在处理大规模多模态数据时更为高效。
ALBeF
ALBeF(Align before Fuse),由 Salesforce Research 提出,是一个多模态模型,专注于先对齐然后融合视觉和语言信息,以提升多模态任务的性能。ALBeF 的主要特点是在多模态融合之前,分别对视觉和语言信息进行高效的对齐,从而实现更精确和深入的跨模态理解。这种方法在多种视觉-语言任务上表现出色,如图像标注、视觉问答和跨模态检索。
ALBeF 通过其创新的对齐-融合策略,在多模态学习领域实现了显著的进步。它为深入理解和处理视觉和语言信息提供了一种高效且精确的方法,特别适用于复杂的跨模态任务。
ALBeF 架构

ALBeF 结合了视觉和语言的最新处理技术,采用了一个两阶段的框架:先对齐(Align)视觉和语言信息,然后融合(Fuse)这些信息以完成多模态任务。
关键特点
- 视觉-语言对齐:在融合阶段之前,ALBeF 首先对视觉(图像)和语言(文本)进行有效的对齐,确保两种模态之间达到较高的一致性和关联性。
- 高效的融合策略:经过对齐后,模型在融合视觉和语言信息时更加高效,能够更深入地理解和处理跨模态内容。
- 利用 Transformer 架构:ALBeF 借助强大的 Transformer 架构处理视觉和语言信息,有效地实现了跨模态表示的学习。
- 适用于多种多模态任务:通过先对齐后融合的策略,ALBeF 能够灵活地适应多种多模态任务,如图像描述生成、视觉问答等。
应用
- 图像描述与视觉问答:ALBeF 可以生成与图像内容密切相关的文本描述,并在视觉问答任务中根据图像内容提供准确的回答。
- 跨模态内容检索:利用其精准的视觉-语言对齐,ALBeF 能够高效地实现基于文本的图像检索或基于图像的文本检索。
- 多模态数据分析:在需要深入理解和分析图像与相关文本信息的场景中,ALBeF 表现出色,如在社交媒体分析或广告内容分析中。
VLMo
VLMo(Vision-Language Model with Masked Visual-Language Pre-training),由 Microsoft Research 提出,是一种多模态模型,专注于提升视觉-语言任务的处理效果。VLMo 的设计重点在于结合了视觉和语言信息的混合模态表示,通过融合两种模态的预训练来增强模型的跨模态理解和生成能力。这种方法在各类视觉-语言任务中表现优异,如图像描述、视觉问答和跨模态检索。
VLMo 通过混合模态的预训练方法,在多模态学习领域实现了显著的进步。它不仅在理解和处理视觉和语言信息方面表现出色,还在多种复杂的多模态任务中展现了强大的性能和灵活性。
VLMo 架构

VLMo 通过混合模态预训练,即同时处理视觉和语言数据,来学习强大的跨模态表示。它采用了 Transformer 架构作为基础,结合了视觉和语言信息的处理。
关键特点
- 混合模态预训练:VLMo 同时对视觉(图像)和语言(文本)信息进行预训练,这使得模型在处理跨模态任务时更为高效和准确。
- 共享的 Transformer 架构:VLMo 利用共享的 Transformer 架构处理图像和文本,促进视觉和语言表示的深度整合。
- 跨模态理解与生成能力:通过混合模态的预训练,VLMo 不仅能够理解跨模态内容,还能在需要时生成相关的图像或文本描述。
- 灵活适用于多种任务:VLMo 适用于各类视觉-语言任务,包括但不限于图像标注、视觉问答和跨模态检索。
应用
- 图像描述与视觉问答:VLMo 可以生成与图像内容密切相关的文本描述,或在视觉问答任务中提供准确的回答。
- 跨模态内容检索:利用其跨模态表示能力,VLMo 能够实现基于文本描述的图像检索,或基于图像内容的文本检索。
- 丰富的多模态内容生成:在需要生成图像描述或根据描述生成图像的任务中,VLMo 表现出卓越的能力。
SimVLM
SimVLM(Simplified Vision-Language Model)是由 Google 在 2021 年提出的一种先进的多模态模型,旨在简化视觉-语言融合的过程。SimVLM 的创新之处在于它的简化架构和直接的学习方式,能够同时处理图像和文本数据,并在多种多模态任务中表现出色。
SimVLM 通过其统一和简化的架构,在多模态领域展现出卓越的性能。它能够有效地融合视觉和语言信息,为多模态理解和生成提供了一种高效且直接的方法。SimVLM 的出现不仅推动了多模态学习的发展,也为未来的多模态研究提供了新的思路和方向。
SimVLM 架构

SimVLM 采用统一的模型架构,同时处理视觉和语言输入,目标是建立一个能够统一处理和理解多种类型数据的模型。
关键特点
- 统一的处理框架:不需要像传统的多模态模型那样,分别为视觉和语言信息设计独立的处理模块。它通过统一的架构同时处理这两种类型的数据。
- 端到端的学习方式:通过端到端的方式直接学习视觉和语言数据的融合,减少了传统多模态学习中常见的预处理和特征抽取步骤。
- 强大的跨模态理解能力:在理解跨模态内容方面表现出色,能够同时理解图像内容和相关联的文本信息。
- 高效的训练与推理性能:由于其简化的架构,在训练和推理时更加高效,特别是在处理大规模多模态数据时。
应用
- 图像和文本的直接融合:SimVLM 能够在一个统一的框架内直接处理和融合图像和文本数据,适用于图像描述、视觉问答等任务。
- 跨模态内容生成与理解:它不仅能够理解跨模态内容,还能生成相关联的图像和文本,例如自动生成图像描述。
- 多模态知识蒸馏和迁移学习:SimVLM 的统一架构适合于多模态知识蒸馏和迁移学习,可以将在特定任务上学到的知识应用到其他多模态任务中。
BeitV2
$\quad$ BeitV2,作为 Microsoft Research 提出的 BeiT 模型的升级版本,进一步提升了图像处理和多模态学习的性能。BeitV2 在原始 Beit 模型的基础上,通过优化图像表示和训练策略,提供了更有效的特征学习能力。
$\quad$ BeitV2 作为 Beit 模型的改进版,在图像处理能力和多模态学习方面都展现出显著的进步。它的优化不仅体现在更精细的图像表示上,也在于其更高效的训练和更强大的多模态融合能力,使其成为处理复杂多模态任务的有力工具。
BeitV2 架构

BeitV2 在 Beit 的基础上,引入了新的组件和技术,以更有效地处理图像数据,并提高模型的表示能力。
关键特点
- 改进的图像编码:BeitV2 对图像的编码方式进行了优化,提升了模型处理图像的能力。这包括更有效的图像分割和编码方法,使得模型能够更好地捕捉图像的细节和结构。
- 优化的训练策略:BeitV2 引入了改进的训练策略,例如更有效的遮蔽机制和预测任务,这些策略进一步强化了模型对图像内在特征的学习。
- 更深层次的特征提取:通过引入更深层次的网络结构和优化的注意力机制,BeitV2 能够提取更丰富和复杂的图像特征。
- 高效的处理能力:相较于原始的 Beit,BeitV2 在处理图像时更为高效,能够更快地对大规模数据集进行训练,同时保持或提高模型的性能。
应用
- 跨模态特征表示:在多模态任务(如图像-文本融合)中,BeitV2 提供的高质量图像表示可以与其他模态(如文本)的表示相结合,提升整体模型的理解和预测能力。
- 更精确的多模态融合: BeitV2 的深层次特征提取能力有助于在多模态任务中实现更精确和细腻的模态间融合,这对于处理复杂的跨模态场景尤为重要。
- 多模态数据处理的效率提升:BeitV2 在保持高性能的同时提高了训练效率,这使得在处理大型多模态数据集时更为高效,尤其在资源受限的情况下尤为重要。
VL-BeiT
VL-BeiT(Vision and Language Beit)是由 Microsoft Research 提出的一种创新的多模态模型,旨在融合视觉和语言信息。它基于 BeiT 模型的框架,将视觉和文本处理相结合,用于处理包含图像和文本数据的多模态任务。
VL-BeiT 通过将视觉和语言处理紧密结合,为多模态学习领域带来了新的视角和方法。它不仅能够有效地融合和理解跨模态信息,还能够在多种复杂的多模态任务中表现出色,是多模态领域的一个重要创新。
VL-BeiT 架构

VL-BeiT 是一个统一的多模态框架,旨在同时处理和理解图像及相关的文本信息。它基于 BeiT 架构的思想,将图像和文本信息融合在一个共享的模型中。
关键特点
- 结合视觉和语言处理:VL-BeiT 同时对视觉(图像)和语言(文本)信息进行处理,实现了在一个统一模型中对两种模态的有效融合。
- 多模态预训练任务:类似于 BeiT,VL-BeiT 使用掩码策略来预训练模型,但它将这种策略扩展到了文本和图像的联合处理上,强化了模型对多模态内容的理解。
- 共享的 Transformer 架构:VL-BeiT 利用 Transformer 架构来处理多模态数据,其中包括图像的 patch 和文本的 token,以实现高效的特征学习和融合。
- 跨模态理解和生成能力:VL-BeiT 不仅能理解图像和文本的联合内容,还能生成相关的文本描述或图像内容,展现出强大的跨模态能力。
应用
- 图像描述和视觉问答:VL-BeiT 可以用于生成图像的描述性文本或在视觉问答任务中理解和回答与图像相关的问题。
- 多模态知识抽取和理解:它能够理解和抽取多模态内容中的关键信息,如从图像-文本对中学习知识点。
- 跨模态内容生成:VL-BeiT 还可以用于跨模态内容生成任务,如根据文本描述生成相应的图像。
FLiP
FLiP,由 Meta 在 2022 年提出,是一种创新的多模态预训练方法,专注于通过遮蔽技术来扩展语言和图像的预训练。该方法在视觉和语言任务的处理上实现了优化和提升,尤其是在大规模数据集上的应用。
FLiP 架构

FLiP 采用了一种结合了语言和图像的多模态预训练框架,通过在图像和文本上同时使用遮蔽策略进行预训练。
关键特点
- 融合语言和图像预训练: FLiP 的核心在于结合了语言和图像数据的预训练,以提升模型在理解视觉-语言交互方面的能力。
- 遮蔽技术: 通过对文本和图像同时实施遮蔽策略,FLiP 在预训练阶段学习恢复被遮蔽的信息,加深对语言和视觉内容的理解。
- 适应性强的预训练策略: FLiP 的预训练过程通过适应不同类型的数据(即文本和图像)来提高模型的灵活性和效率。
应用
- 视觉-语言融合任务: 包括图像描述生成、视觉问答(VQA)、视觉推理等任务,FLiP 通过加强跨模态理解来提升这些任务的性能。
- 跨模态内容理解: FLiP 能够深入理解图像内容与关联文本之间的复杂关系,提升如跨模态检索和分类任务的效果。
- 数据丰富性和模型泛化: 通过在大规模多样化的数据集上进行预训练,FLiP 提升了多模态模型对不同类型和样式的视觉和语言数据的泛化能力。
CoCa
CoCa(Contrastive Captioners)是一种由 Google 在 2022 年提出的先进多模态模型,专注于通过对比学习方法和生成任务来改善视觉和文本的联合理解。CoCa 的设计核心是结合了对比学习和生成模型的优势,以提高对图像内容和相关文本的理解能力。这种方法在图像描述、视觉问答以及其他多模态任务中表现出色。
CoCa 通过结合对比学习和生成式任务,在多模态学习领域实现了显著的进展。它不仅提升了模型在理解和处理视觉和语言信息方面的能力,而且在多种复杂的多模态任务中展现出了强大的性能。
CoCa 架构

CoCa 采用了对比学习和生成式学习的结合方式,使用一个统一的 Transformer 模型同时处理图像和文本信息,并通过对比学习来优化其跨模态理解能力。
关键特点
- 结合对比学习和生成任务:CoCa 的核心创新是将对比学习和生成任务结合起来,既利用对比学习的方式优化模型的特征提取能力,又通过生成任务增强模型的表达能力。
- 强化跨模态理解:CoCa 设计用于深入理解图像内容及其与文本描述之间的复杂关系,这对于解决复杂的多模态任务至关重要。
- Transformer 架构:与其他先进的多模态模型类似,CoCa 也利用了 Transformer 的强大处理能力来高效处理图像和文本数据。
- 文本端的解码器训练:CoCa 在文本端采用解码器训练方法,以提高在图像-文本生成任务中的性能和效率。
应用
- 图像描述生成:CoCa 能够根据图像内容生成准确且丰富的文本描述,适用于自动图像标注和内容创作。
- 视觉问答:在视觉问答任务中,CoCa 能够理解图像内容并根据此生成相关问题的回答。
- 跨模态内容理解与生成:CoCa 不仅能够理解图像和文本的联合内容,还可以用于生成与特定文本描述相符的图像内容。
BLIP
$\quad$ BLIP(Bootstrapped Language Image Pretraining)是一种由 Facebook 在 2022 年提出的创新多模态模型,旨在通过引入引导学习(bootstrapping)的概念来改善视觉和语言任务的处理效果。BLIP 的核心创新在于其能够利用引导学习来提升跨模态理解,尤其是在图像和文本的联合表示上。这种方法在图像标注、视觉问答以及其他多模态任务中展现出了优异的性能。
$\quad$ BLIP 通过引入引导学习机制和混合模态预训练,在多模态学习领域实现了显著的进步。它不仅提高了模型在理解和处理视觉和语言信息方面的能力,而且在多种复杂的多模态任务中表现出了卓越的性能和灵活性。
BLIP 架构

BLIP 利用了混合模态预训练的概念,结合了引导学习策略,以增强模型对视觉和语言信息的理解。它采用了 Transformer 架构来有效地处理图像和文本数据,并通过引导学习进一步优化模型的跨模态能力。
关键特点
- 引导学习机制:BLIP 引入了引导学习机制,通过这种方式使得模型能够更好地学习和理解图像和文本之间的关系。
- 混合模态预训练:BLIP 对视觉(图像)和语言(文本)信息同时进行预训练,使得模型在处理跨模态任务时更加准确和高效。
- 强化的跨模态表示:利用混合模态预训练和引导学习,BLIP 能够提供更丰富和精准的跨模态表示。
- 适用于多种多模态任务:BLIP 适用于多种视觉-语言任务,包括图像描述生成、视觉问答和跨模态检索等。
应用
- 图像描述生成和视觉问答:BLIP 可以根据图像内容生成准确的文本描述,并能有效地回答与图像内容相关的问题。
- 跨模态内容检索:通过其强化的跨模态表示能力,BLIP 能够实现基于文本描述的图像检索或基于图像内容的文本检索。
- 高效的多模态分析:在需要深度理解和分析图像与相关文本信息的任务中,BLIP 表现出色,如在社交媒体内容分析或广告内容创作中。
Beit-3
BeitV3(BEIT Pretraining for All Vision and Vision-Language Tasks),作为一种通用多模态基础模型,代表了语言、视觉和多模态预训练的大融合趋势。它在多种视觉和视觉-语言任务上实现了最先进的迁移性能。
BeitV3 通过其多向 Transformer 架构和创新的预训练方法,在多模态学习中实现了显著的进步。它不仅在视觉任务上展现出强大的性能,也在视觉-语言任务中表现出色,表明了这种融合视觉和语言预训练方法的巨大潜力和应用广度。BeitV3 的成功预示着多模态模型在处理更复杂、更细粒度跨模态任务中的巨大潜力。
BeitV3 架构

采用多向 Transformer,这种结构包括一个共享的自注意力模块,以及用于不同模态的模块化前馈网络(即模态专家)。这样的设计既考虑了模态特定编码,又使得不同模态间的深度融合成为可能。
关键特点
- 多向 Transformer(Multiway Transformers)架构: 用于通用建模的多向 Transformer 提供模块化架构,允许深度融合和模态特定编码。
- 统一的预训练任务: 在图像(称为 Imglish)、文本和图像-文本对上进行遮蔽“语言”建模,实现统一方式处理。
- 模型规模扩展: BeitV3 扩展到数十亿参数规模,同时使用公开可获取的资源进行预训练,以便学术复现。
- 强大的跨模态表现: 在多项视觉和视觉-语言任务中展现出色的性能,如对象检测、语义分割、图像分类、视觉推理、视觉问答、图像字幕和跨模态检索。
- 遮蔽数据建模: 使用单一预训练任务,即遮蔽然后预测,来训练这个通用多模态基础模型。
- 跨模态融合与专家网络: 每个多向 Transformer 块包含共享的自注意力模块和一组用于不同模态的前馈网络(即模态专家)。
应用
- 视觉任务: 包括图像分类、对象检测和语义分割等。BeitV3 能够理解和解析图像内容,表现出与专门的视觉模型(如 ViT、BeiT)相媲美的能力。
- 视觉-语言融合任务: 包括图像描述生成、视觉问答和视觉推理。这些任务要求模型理解图像内容并生成或回答相关的文本,BeitV3 可以像 CLIP 或 UNITER 那样处理这类任务。
- 跨模态检索与理解: 包括基于文本的图像检索或基于图像的文本检索,需要模型理解和关联两种不同模态的内容。BeitV3 能够有效地处理这些任务,类似于 OSCAR 或 VLMo 的能力。
- 自然语言处理任务: BeitV3 亦可适用于纯文本任务,例如文本分类、情感分析等,类似于 BERT 的应用范围。
- 多模态生成任务: 包括从文本描述生成图像或相关内容,以及图像字幕等任务。BeitV3 可以像 SimVLM 或 CoCa 那样处理这类任务。
- 大规模联合学习任务: 在需要多方数据融合的场景中,如 FLiP,BeitV3 也能通过其灵活的架构和强大的表示能力,有效地协调和处理跨源数据。
结束语
最后,在本次多模态的探索之旅的尾声,感谢每位朋友的陪伴,更新这个博客花费了多周的心血,如果对您有点帮助,就点个赞呗。您的点赞、关注是我持续分享的动力。我是APlayBoy,期待与您一起在AI的世界里不断成长!






![[Redis]——Redis持久化的两种方式RDB、AOF](https://img-blog.csdnimg.cn/direct/51366bf13f994f38badaface857e7d6c.png)