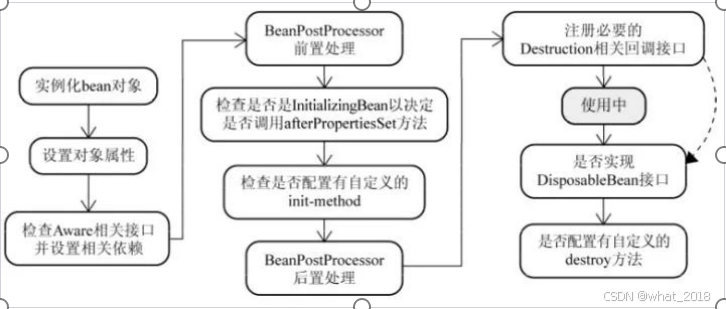
深度学习 Deep Learning 第16章 结构化概率模型
内容概要
本章深入探讨了结构化概率模型(Graphical Models,包含有向图和无向图模型)的概念及其在深度学习中的应用。结构化概率模型通过图结构描述随机变量之间的直接交互,从而简化概率分布的表示和学习。本章详细介绍了结构化概率模型的基本概念、挑战、模型结构、采样方法、推理和近似推理,以及深度学习中独特的结构化概率模型方法。
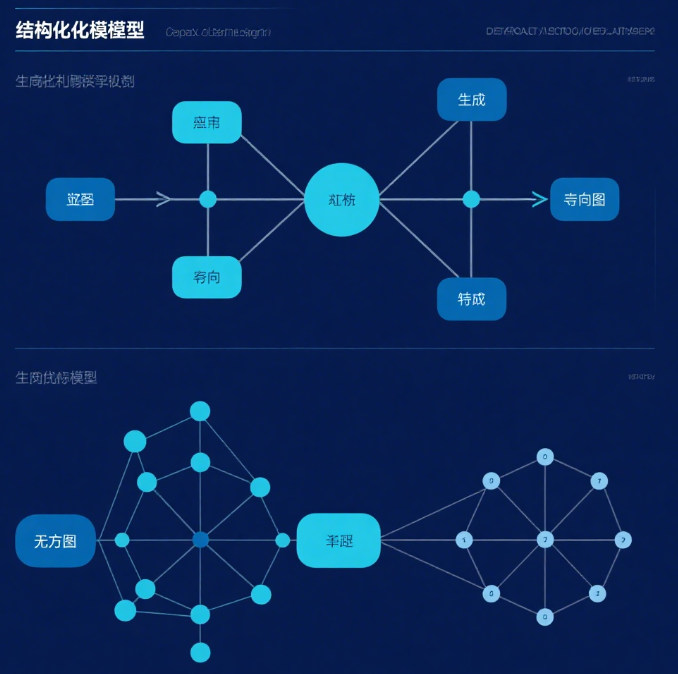
主要内容
-
无结构建模的挑战
- 高维数据的建模需要处理指数级的参数,导致内存、统计效率和运行时间的挑战。
- 通过结构化模型,可以显著减少参数数量,提高模型的可解释性和计算效率。
- 稀疏依赖假设:现实数据中变量多通过间接、局部依赖关联(如接力赛跑中选手时间的依赖链),图模型通过显式描述直接交互简化建模。
-
图模型的核心形式
- 有向模型(Directed Models,贝叶斯网络):使用有向无环图(DAG)描述变量之间的因果关系。每个节点表示一个随机变量,边表示直接交互。依赖拓扑排序定义条件概率分布,如接力赛中t0→t1→t2的因果链。参数数量从O(kn)降至O(km)(m为最大父节点数)。
- 无向模型(Undirected Models,马尔可夫网络):使用无向图描述变量之间的对称交互。每个节点表示一个随机变量,边表示直接交互。
- 能量模型(Energy-Based Models):通过能量函数定义概率分布,确保所有状态的概率非零。
- 分离与D-分离(Separation and D-Separation):用于确定变量之间的条件独立性。
-
采样方法
- 有向模型的祖先采样(Ancestral Sampling):通过拓扑排序依次采样。
- 无向模型的吉布斯采样(Gibbs Sampling):通过迭代更新每个变量的值。
-
推理与近似推理
- 精确推理:计算复杂度高,通常不可行。
- 近似推理:使用变分推断等方法近似真实分布。
-
深度学习中的结构化概率模型
- 分布式表示:深度学习模型通常使用大量潜在变量来捕捉复杂的非线性交互。
- 模型结构:深度模型通常具有多层潜在变量,连接方式密集。
- 高效计算:通过矩阵运算和卷积等高效实现,处理大规模数据。
- 容忍未知:深度学习模型允许使用无法精确计算的边际分布,通过近似方法进行训练和推理。
-
技术前沿方向
- 非参数化图模型:结合图神经网络(GNN)动态建模变量关系,替代固定结构假设。
- 跨模态统一表示:如何设计统一图结构融合文本、图像等多模态数据(如CLIP的跨模态对齐)?
- 量子计算赋能:利用量子采样加速配分函数计算,突破经典Gibbs采样的效率瓶颈。
总结
-
价值:
-
计算效率:图结构显式约束依赖,大幅减少参数规模,避免维度灾难。
-
灵活性:有向/无向模型互补,适应因果与非因果场景(如文本生成与图像去噪)。
-
深度适配:分布式表示与矩阵参数化契合深度学习的层次化特征学习需求。
-
-
局限性:
- 推断复杂度:无向模型配分函数Z难计算,依赖近似方法引入误差。
- 结构设计依赖:图拓扑需人工预设或复杂结构学习,可能遗漏关键依赖。
- 可解释性:隐变量语义不透明,难以直接关联现实概念(如RBM隐单元)。
精彩语录
-
中文:结构化概率模型通过图结构描述随机变量之间的直接交互,从而显著减少参数数量。
英文原文:Structured probabilistic models describe direct interactions between random variables using a graph, dramatically reducing the number of parameters.
解释:这句话强调了结构化概率模型通过图结构简化模型复杂度的核心优势。 -
中文:有向模型适合描述因果关系明确的场景,而无向模型适合描述交互方向不明确的场景。
英文原文:Directed models are suitable for scenarios with clear causal relationships, while undirected models are better for interactions without a clear direction.
解释:这句话说明了有向和无向模型在不同场景下的适用性。 -
中文:能量模型通过能量函数确保所有状态的概率非零,简化了学习过程。
英文原文:Energy-based models ensure all states have non-zero probabilities through an energy function, simplifying the learning process.
解释:这句话描述了能量模型如何通过能量函数保证概率分布的非零性。 -
中文:吉布斯采样通过迭代更新每个变量的值,适用于无向模型的采样。
英文原文:Gibbs sampling iteratively updates each variable’s value, making it suitable for sampling from undirected models.
解释:这句话介绍了吉布斯采样在无向模型中的应用。 -
中文:深度学习中的结构化概率模型通过分布式表示和密集连接,捕捉复杂的非线性交互。
英文原文:Structured probabilistic models in deep learning capture complex nonlinear interactions through distributed representations and dense connectivity.
解释:这句话总结了深度学习中结构化概率模型的独特优势。




![[MySQL初阶]MySQL表的操作](https://i-blog.csdnimg.cn/direct/51bd09dd8dcf4655879ec5cb86574970.png)





![NSSCTF [HGAME 2023 week1]simple_shellcode](https://i-blog.csdnimg.cn/img_convert/b687acfa6cb6039d3e83b906e2395971.png)


