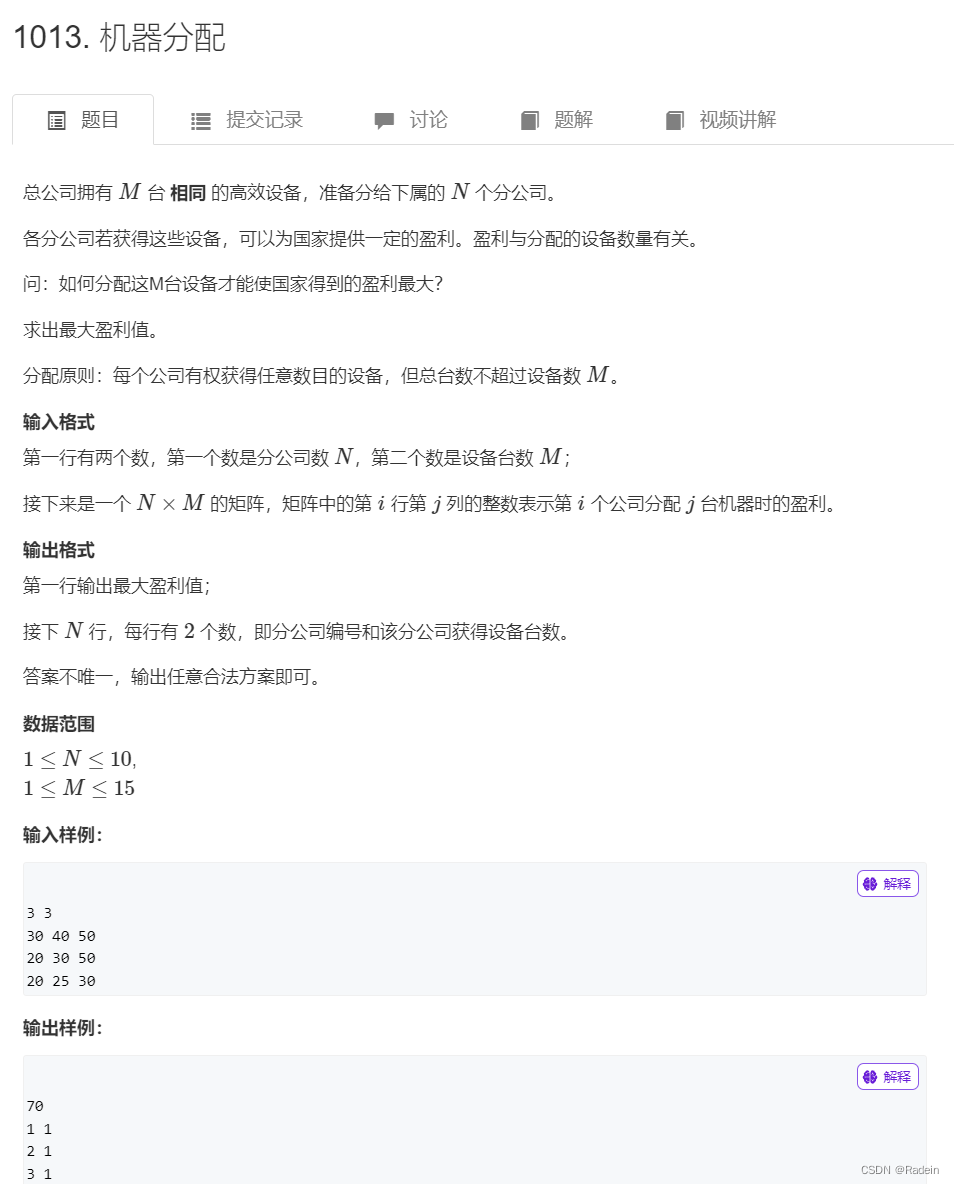
通过上一篇文章的学习:
【机器学习智能硬件开发全解】(二)—— 政安晨:嵌入式系统基本素养【处理器原理】![]() https://blog.csdn.net/snowdenkeke/article/details/136662796我们已经知道了CPU的设计流程和工作原理,紧接着一个新问题又出现了:我们编写的程序存储在哪里呢?CPU内部的结构其实很简单,除了ALU、控制单元、寄存器和少量Cache,根本没有多余的空间存放我们编写的代码,我们需要额外的存储器来存放我们编写的程序(指令序列)。
https://blog.csdn.net/snowdenkeke/article/details/136662796我们已经知道了CPU的设计流程和工作原理,紧接着一个新问题又出现了:我们编写的程序存储在哪里呢?CPU内部的结构其实很简单,除了ALU、控制单元、寄存器和少量Cache,根本没有多余的空间存放我们编写的代码,我们需要额外的存储器来存放我们编写的程序(指令序列)。
存储器按照存储类型可分为易失性存储器和非易失性存储器。
易失性存储器如SRAM、DDR SDRAM等,一般用作计算机的内部存储器,所以又被称为内存。这类存储器支持随机访问,CPU可以随机到它的任意地址去读写数据,访问非常方便,但缺点是断电后数据会立即消失,无法永久保存。
非易失性存储器一般用作计算机的外部存储器,也被称为外存,如磁盘、Flash等。这类存储器支持数据的永久保存,断电后数据也不会消失,但缺点是不支持随机访问,读写速度也不如内存。为了兼顾存储和效率,计算机系统一般会采用内存+外存的存储结构:程序指令保存在诸如磁盘、NAND Flash、SD卡等外部存储器中,当程序运行时,相应的程序会首先加载到内存,然后CPU从内存一条一条地取指令、翻译指令和运行指令。
计算机主要用来处理数据。我们编写的程序,除了指令,还有各种各样的数据。指令和数据都需要保存在存储器中,根据保存方式的不同,计算机可分为两种不同的架构:冯·诺依曼架构和哈弗架构。
政安晨的个人主页:政安晨
欢迎 👍点赞✍评论⭐收藏
收录专栏: 机器学习智能硬件开发全解
希望政安晨的博客能够对您有所裨益,如有不足之处,欢迎在评论区提出指正!

冯·诺依曼架构
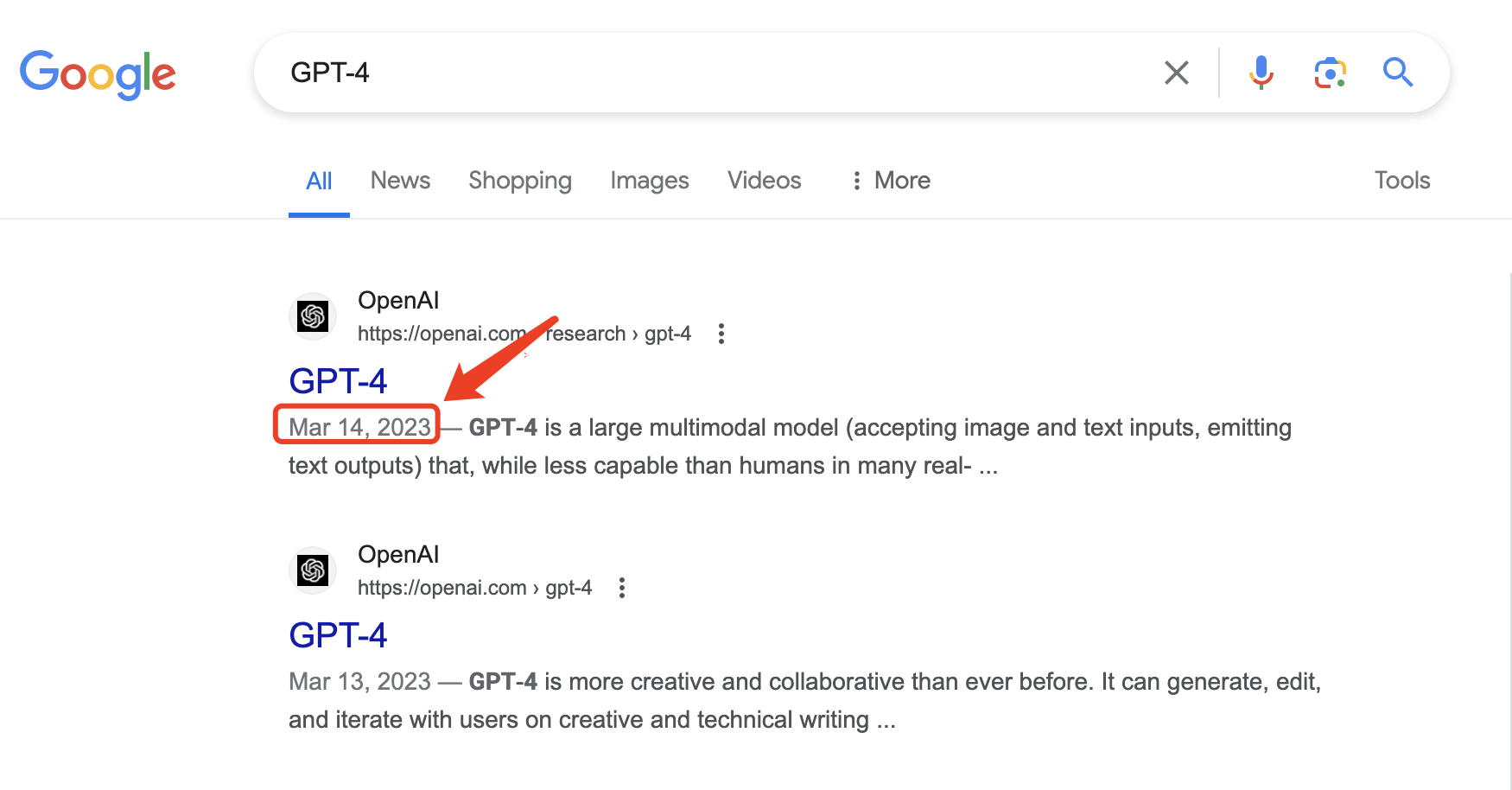
冯·诺依曼架构,也称为普林斯顿架构。采用冯·诺依曼架构的计算机,其特点是程序中的指令和数据混合存储,存储在同一块存储器上,如下图所示(冯·诺依曼架构):
在冯·诺依曼架构的计算机中,程序中的指令和数据同时存放在同一个存储器的不同物理地址上,一般我们会把指令和数据存放到外存储器中。
当程序运行时,再把这些指令和数据从外存储器加载到内存储器(内存储器支持随机访问并且访问速度快),冯·诺依曼架构的特点是结构简单,工程上容易实现,所以很多现代处理器都采用这种架构,如X86、ARM7、MIPS等。
哈弗架构
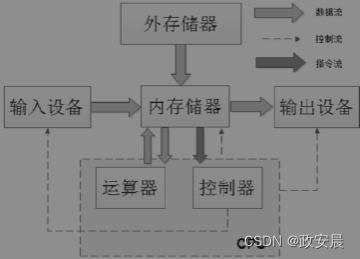
和冯·诺依曼架构相对的是哈弗架构,使用哈弗架构的计算机系统如下图所示(哈弗架构):
哈弗架构的特点是:指令和数据被分开独立存储,它们分别被存放到程序存储器和数据存储器。每个存储器都独立编址,独立访问,而且指令和数据可以在一个时钟周期内并行访问。使用哈弗架构的处理器运行效率更高,但缺点是CPU实现会更加复杂。8051系列的单片机采用的就是哈弗架构。
混合架构
随着处理器不断地更新换代,现在的CPU工作频率越来越高,很容易和内存RAM之间产生带宽问题:CPU的频率可以达到GHz级别,而对应的内存RAM也是达到GHZ级别了。CPU和RAM之间传输数据,要经过找地址、取数据、配置、等待、输出数据等多个时钟周期,内存带宽瓶颈会拖慢CPU的工作节奏,进而影响计算机系统的整体运行效率。为了减少内存瓶颈带来的影响,CPU引入了Cache机制:指令Cache和数据Cache,用来缓存数据和指令,提升计算机的运行效率。
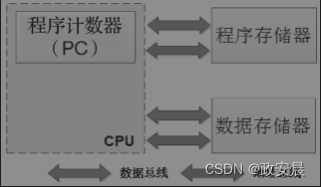
现代的ARM SoC芯片架构一般如下图所示,SoC芯片内部的Cache层采用哈弗架构,集成了指令Cache和数据Cache。
(混合架构)
当CPU到RAM中读数据时,内存RAM不是一次只传输要读取的指定字节,而是一次缓存一批数据到Cache中,等下次CPU再去取指令和数据时,可以先到这两个Cache中看看要读取的数据是不是已经缓存到这里了,如果没有缓存命中,再到内存中读取。当CPU写数据到内存RAM时,也可以先把数据暂时写到Cache里,然后等待时机将Cache中的数据刷新到内存中。
Cache缓存机制大大提高了CPU的访问效率,而SoC芯片外部则采用冯·诺依曼架构,工程实现简单。现代的计算机集合了这两种架构的优点,因此我们很难界定一款芯片到底是冯·诺依曼架构还是哈弗架构,我们就姑且称之为混合架构吧。
CPU性能提升:Cache机制
随着半导体工艺和芯片设计技术的发展,CPU的工作频率也越来越高,和CPU进行频繁数据交换的内存的运行速度却没有相应提升,于是两者之间就产生了带宽问题,进而影响计算机系统的整体性能。
CPU执行一条指令需要零点几纳秒,而RAM则需要30纳秒左右,读写一次RAM的时间,CPU都可以执行几百条指令了。为了不给CPU拖后腿,解决内存带宽瓶颈的方法一般有两个:
一是大幅提升内存RAM的工作频率,目前最新的内存条的工作频率可以飙到几GHz,但是和高端的CPU相比,还是存在一定差距的。
第二就是使用Cache缓存机制,有速度瓶颈的地方就有缓存,这种思想在计算机中随处可见。
Cache的工作原理
Cache在物理实现上其实就是静态随机访问存储器(Static Random Access Memory,SRAM),Cache的运行速度介于CPU和内存DRAM之间,是在CPU和内存之间插入的一组高速缓冲存储器,用来解决两者速度不匹配带来的瓶颈问题。
Cache的工作原理很简单,就是利用空间局部性和时间局部性原理,通过自有的存储空间,缓存一部分内存中的指令和数据,减少CPU访问内存的次数,从而提高系统的整体性能。
Cache的工作流程以下图为例(通过Cache缓存RAM中的数据):
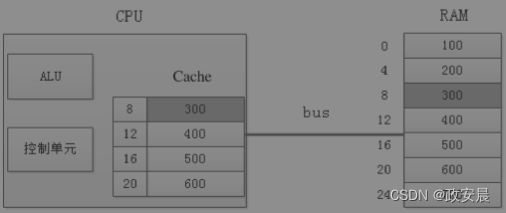
当CPU读取内存中地址为8的数据时,CPU会将内存中地址为8的一片数据缓存到Cache中。等下一次CPU读取内存地址为12的数据时,会首先到Cache中检查该地址是否在Cache中。如果在,就称为缓存命中(Cache Hit),CPU就直接从Cache中取数据;如果该地址不在Cache中,就称为缓存未命中(Cache Miss),CPU就重新转向内存读取数据,并重新缓存从该地址开始的一片数据到Cache中。
CPU写内存的工作流程和读类似:以下图为例(Cache的回写过程):
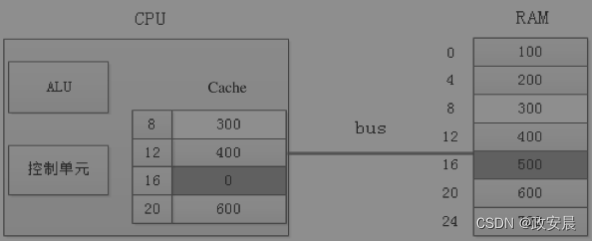
当CPU往地址为16的内存写入数据0时,并没有真正地写入RAM,而是暂时写到了Cache里。
此时Cache和内存RAM的数据就不一致了,缓存的每块空间里一般会有一个特殊的标记位,叫“Dirty Bit”,用来记录这种变化。当Cache需要刷新时,如Cache空间已满而CPU又需要缓存新的数据时,在清理缓存之前,会检查这些“Dirty Bit”标记的变化,并把这些变化的数据回写到RAM中,然后才腾出空间去缓存新的内存数据。
以上只是对Cache的工作原理做了简化分析,实际的Cache远比这复杂,如Cache里存储的内存地址,一般要经过地址映射,转换为更易存储和检索的形式。除此之外,现代的CPU为了进一步提高性能,大多采用多级Cache:一级Cache、二级Cache,甚至还有三级Cache。
一级Cache和二级Cache
CPU从Cache里读取数据,如果缓存命中,就不用再访问内存,效率大大提升;
如果缓存未命中,情况就不太乐观了:CPU不仅要重新到内存中取数据,还要缓存一片新的数据到Cache中,如果Cache已经满了,还要清理Cache,如果Cache中的数据有“Dirty Bit”,还要回写到内存中。
这一波操作可能需要几十甚至上百个指令,消耗上百个时钟周期的时间,严重影响了CPU的读写效率。为了减少这种情况发生,我们可以通过增大Cache的容量来提高缓存命中的概率,但随之带来的就是成本的上升。
在CPU内部,Cache和寄存器的电路比内存DRAM复杂了很多,会占用很大的芯片面积,如果大量使用,芯片发热量会急剧上升,所以在CPU内部寄存器一般也就几十个,靠近CPU的一级Cache也就几十千字节。既然无法继续增加一级Cache的容量,一个折中的办法就是在一级Cache和内存之间添加二级Cache,如下图所示。二级Cache的工作频率比一级Cache低,但是电路成本会降低,元器件的运行速度总是和电路成本成正比。
(CPU处理器中的多级Cache)

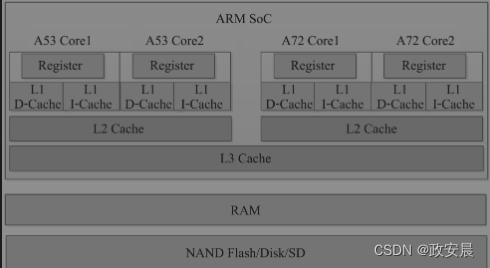
现在的CPU一般都是多核结构,一个CPU芯片内部会集成多个Core,每个Core都会有自己独立的L1 Cache,包括D-Cache和I-Cache。在X86架构的CPU中,一般每个Core也会有自己独立的L2 Cache,L3 Cache被所有的Core共享。而在ARM架构的CPU中,L2 Cache则被每簇(Cluster)的Core共享。ARM架构SoC芯片的存储结构如下图所示。
(ARM架构多核CPU的存储结构)
为什么有些处理器没有Cache
通过咱们前面文章的学习,我们已经知道Cache的作用主要是缓解CPU和内存之间的带宽瓶颈。Cache一般用在高性能处理器中,并不是所有的处理器都有Cache,如C51系列单片机、cortex-M0、cortex-M1、cortex-M2、cortex-M3、cortex-M4系列的ARM处理器都没有Cache。为什么这些处理器不使用Cache呢?
主要原因有三个:
一是这些处理器都是低功耗、低成本处理器,在CPU内集成Cache会增加芯片的面积和发热量,不仅功耗增加,芯片的成本也会增加不少。以Intel酷睿i7-3960X处理器为例,如下图所示,L3 Cache大约占了芯片面积的1/4,再加上每个Core内部集成的独立L1 Cache和L2 Cache,整个Cache面积差不多就占了芯片总面积的1/3。

二是这些处理器本来工作频率就不高(从几十兆赫到几百兆赫不等),和RAM之间不存在带宽问题,有些处理器甚至不需要外接RAM,直接使用片内SRAM就可满足面向控制领域的软件开发需求。
三是使用Cache无法保证实时性。当缓存未命中时,CPU从RAM中读取数据的时间是不确定的,这是嵌入式实时控制场景无法接受的。因此,在一些面向嵌入式工业控制、实时领域、超低功耗的处理器中,大家可以看到很多没有集成Cache的处理器。
不要觉得奇怪:适合自己的,才是最好的,不是所有的手机都叫苹果,不是所有的处理器都需要Cache。
CPU性能提升:流水线
流水线是工业社会化大生产背景下的产物。亚当·斯密在他的《国富论》中曾经描述这样一个场景:制作一枚回形针一般需要18个步骤,工厂里的工人平均每天也只能做100枚回形针。后来改进工艺,把制针流程分成18道工艺,然后让这10名工人平均每人负责1~2道工艺,最后这10名工人每天可以制造出48 000枚回形针,生产效率整整提高了几十倍。
在农业社会做一部机器,需要的是工匠、手艺人,就像故宫里修文物的那些匠人一样,是需要拜师学艺、慢慢摸索、逐步精进的。
如果我们拿智能硬件的生产做比喻,农业社会的模式是这样的:从电路焊接、手机组装、质检、贴膜、包装都是一个人,什么都要学。手艺人慢工出细活,但生产成本很高。
到了工业化社会就不一样了:大家分工合作,将做手机这个复杂手艺拆分为多个简单步骤,每个人负责一个步骤,多个步骤构成流水线。流水线上的每个工种经过练习和培训,都可以很快上手,每个人都做自己最擅长的,进而可以大大提高整个流水线的生产效率。
做一部手机,焊接电路、组装成品这一步流程一般需要8分钟,测试检验需要4分钟,贴膜包装成盒需要4分钟,总共需要16分钟。
如果有3个工人,每个人都单独去做手机,每16分钟可以生产3部手机。一个新员工从进厂开始,要培训学习三个月才能掌握所有的技能,才能上岗。如果引入生产流水线就不一样了,每个人只负责一个工序,如下图所示,小A只负责焊接电路、组装手机,小B只负责质检,小C只负责贴膜包装。
每个人进厂培训10天就可以快速上手了,流水线对工人的技能要求大大降低,而且随着时间的推移,每个人会对自己负责的工序越来越熟练。
每道工序需要的时间也会大大减少:
小A焊接电路越来越顺手,花费时间从原来的8分钟缩减为4分钟;
小B的质量检验练得炉火纯青,做完整个流程只需要2分钟;
小C的贴膜技术也越来越高了,从贴膜到包装2分钟完成。每16分钟,小A可以焊接4块电路板,整个流水线可以生产出4部手机,产能整整提升了33.33%!老板高兴,小A高兴,小B和小C高兴,因为每做2分钟,他们还可以休息2分钟,岂不乐哉。
(手机生产流水线)

看到这里可能有人抬杠了:你这么算是不对的,每道工序所用的时间都变为原来的一半,怎么可能做得到?其实要做到不难的,只要工序拆解得合理,容易上手,再加上足够时间的机械重复,很多人都可以做得到。
流水线工作原理
一条指令的执行一般要经过取指令、翻译指令、执行指令3个基本流程。CPU内部的电路分为不同的单元:取指单元、译码单元、执行单元等,指令的执行也是按照流水线工序一步一步执行的。如下图所示,我们假设每一个步骤的执行时间都是一个时钟周期,那么一条指令执行完需要3个时钟周期。
(ARM处理器的三级流水线)

CPU执行指令的3个时钟周期里,取指单元只在第一个时钟周期里工作,其余两个时钟周期都处于空闲状态,其他两个执行单元也是如此。这样做效率太低了,消费者无法接受,老板更无法接受。解决方法就是引入流水线,让流水线上的每一颗螺丝钉都马不停蹄地运转起来。
如下图所示(处理器指令的流水线执行过程):

引入流水线后,除了刚开始的第一个时钟周期大家可以偷懒,其余的时间都不能闲着:
从第二个时钟周期开始,当译码单元在翻译指令1时,取指单元也不能闲着,要接着去取指令2。
从第三个时钟周期开始,当执行单元执行指令1时,译码单元也不能闲着,要接着去翻译指令2,而取指单元要去取指令3。
从第四个时钟周期开始,每个电路单元都会进入满负荷工作状态,像富士康工厂里的流水线一样,源源不断地执行一条条指令。
引入流水线后,虽然每一条指令的执行流程和时间不变,还是需要3个时钟周期,但是从整条流水线的输出来看,差不多平均每个时钟周期就能执行一条指令。原来执行一条指令需要3个时钟周期,引入流水线后平均只需要1个时钟周期,CPU性能提升了不少。
流水线的本质其实就是拿空间换时间。将每条指令分解为多步执行,指令的每一小步都有独立的电路单元来执行,并让不同指令的各小步操作重叠,通过多条指令的并行执行,加快程序的整体运行效率。
CPU内部的流水线如此,工厂里的手机生产流水线也是如此,通过不断地往流水线增加人手来提高流水线的生产效率,也就是增加流水线的吞吐率。
超流水线技术
想知道什么是超流水线,让我们再回到工厂。
在手机生产流水线上,由于小A的工作效率不高,每焊接组装一步手机需要4分钟,导致流水线上生产一部手机也得需要4分钟。小A拖累了整条生产线的生产效率,老板很生气,后果很严重,小A没干到一个月就被老板炒掉了。接下来的几个月里,陆陆续续来了不少人,都想挑战一下这份工作,可惜干得还不如小A。老板招不到人,感觉又错怪了小A,于是决定升级生产线,并在加薪的承诺下重新召回了小A。
经过分析,老板找到了生产线的瓶颈:流水线上的每道工序都需要2分钟,只有小A这道工序需要4分钟,老板发现自己错怪了小A,这不是小A的原因,是因为这道工序太复杂。老板把这道工序拆解为两道工序:焊接电路和组装手机。
如下图所示(改进后的手机生产流水线):
焊接电路仍由小A负责,把电路板、显示屏、手机外壳组装成手机这道工序则由新员工小D负责。生产流水线经过优化后,小A焊接电路只需要2分钟,小D组装每部手机也只需要2分钟,生产每部手机的时间也由原来的4分钟缩减为2分钟。现在每16分钟可以生产8部手机,生产效率是原来的2倍!生产流水线的瓶颈解决了。

和手机生产流水线类似,优化CPU流水线也是提升CPU性能的有效手段。
流水线存在木桶短板效应,我们只需要找出CPU流水线中的性能瓶颈,即耗时最长的那道工序,对其再进行细分,拆解为更多的工序就可以了。每一道工序都称为流水线中的一级,流水线越深,每一道工序的执行时间就会变得越小,处理器的时钟周期就可以更短,CPU的工作频率就可以更高,进而可以提升CPU的性能,提高工作效率。
在手机生产流水线上,耗时最长的那道工序决定了整条流水线的吞吐率。
CPU内部的流水线也是如此,流水线中耗时最长的那道工序单元的执行时间(即时间延迟)决定了CPU流水线的性能。CPU流水线中的每一级电路单元一般都是由组合逻辑电路和寄存器组成的,组合逻辑电路用来执行本道工序的逻辑运算,寄存器用来保存运算输出结果,并作为下一道工序的输入。
流水线通过减少每一道工序的耗费时间来提升整条流水线的效率。
在CPU内部也是如此,CPU内部的数字电路是靠时钟驱动来工作的,既然每条指令的执行时钟周期数不变,即执行每条指令都需要3个时钟周期,但是我们可以通过缩短一个时钟周期的时间来提升效率,即减少每条指令所耗费的时间。
一个时钟周期的时间变短,CPU主频也就相应提升,影响时钟周期时间长短的一个关键的制约因素就是CPU内部每一个工序执行单元的耗费时间。虽说电信号在电路中的传播时间很快,可以接近光速,但是经过成千上万个晶体管,不停地信号翻转,还是会带来一定的时间延迟,这个时间延迟我们可以看作电路单元的执行时间。
以下图为例(流水线中每道工序的耗时):
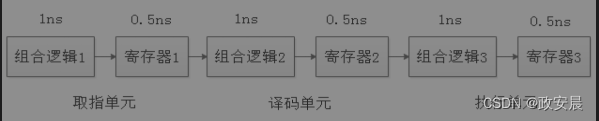
如果每个执行单元的时间延迟都是1+0.5=1.5ns,那么你的时钟周期至少也得2ns,否则电路就会工作异常。如果驱动CPU工作的时钟周期是2ns,那么CPU的主频就是500MHz。现在的CPU流水线深度可以做到10级以上,流水线的每一级时间延迟都可以做到皮秒级别,驱动CPU工作的时钟周期可以做到更短,可以把CPU的主频飙到5GHz以上。
我们把5级以上的流水线称为超流水线结构。
为了提升CPU主频,高性能的处理器一般都会采用这种超流水线结构。Intel的i7处理器有16级流水线,AMD的速龙64系列CPU有20级流水线,史上具有最长流水线的处理器是Intel的第三代奔腾四处理器,有31级流水线。
要想提升CPU的主频,本质在于减少流水线中每一级流水的执行时间,消除木桶短板效应。
解决方法有三个:
一是优化流水线中各级流水线的性能,受限于当前集成电路的设计水平,这一步最难;
二是依靠半导体制造工艺,工艺制程越先进,芯片面积就会越小,发热也就越小,就更容易提升主频;
三是不断地增加流水线深度,流水线越深,流水线中的各级时间延迟就可以做得越小,就更容易提高主频。
流水线是否越深越好呢?不一定。
流水线的本质是拿空间换时间,流水线越深,电路会越复杂,就需要更多的组合逻辑电路和寄存器,芯片面积也就越大,功耗也就随之上升了。用功耗增长换来性能提升,在PC机和服务器上还行,但对于很多靠电池供电的移动设备的处理器来说就无法接受了,CPU设计人员需要在性能和功耗之间做一个很好的平衡。
流水线越深,就越能提升性能吗?也不一定。
流水线是靠指令的并行来提升性能的,第一条指令还没有执行完,下面的第二条指令就开始取指、译码了。执行的程序指令如果是顺序结构的,没有中断或跳转,流水线确实可以提高执行效率。但是当程序指令中存在跳转、分支结构时,下面预取的指令可能就要全部丢掉了,需要到跳转的地方重新取指令执行。
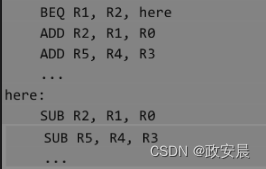
在上面的汇编程序中,BEQ是一个条件跳转指令,根据寄存器R1和R2的值是否相等,跳转到不同的地方执行。
正常情况下,当执行BEQ指令时,下面的ADD指令就已经被预取和译码了,如果程序没有跳转,则会接着继续往下执行。
但是当BEQ跳转到here标签处执行时,流水线中已经预取的ADD指令就无效了,要全部丢弃掉,然后重新到here标签处取SUB指令,流水线才能接着继续执行。
流水线越深,一旦预取指令失败,浪费和损失就会越严重,因为流水线中预取的几十条指令可能都要丢弃掉,此时流水线就发生了停顿,无法按照预期继续执行,这种情况我们一般称为流水线冒险(hazard)。
流水线冒险
引起流水线冒险的原因有很多种,根据类型不同,我们一般分为3种。
● 结构冒险:所需的硬件正在为前面的指令工作。
● 数据冒险:当前指令需要前面指令的运算数据才能执行。
● 控制冒险:需根据之前指令的执行结果决定下一步的行为。
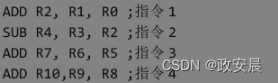
结构冒险很好理解,如果多条指令都用相同的硬件资源,如内存单元、寄存器等,就会发生冲突。如下面的汇编程序。:

上面这两条指令执行时都需要访问寄存器R1,但是这两条指令之间没有依赖关系,不需要数据的传送,仅仅在使用的硬件资源上发生了冲突,这种冲突我们就称为结构冒险。
解决结构冒险的方法很简单,我们直接对冲突的寄存器进行重命名就可以了。这种操作可以通过编译器静态实现,也可以通过硬件动态完成,如下图所示,我们在流水线中加入寄存器重命名单元就可以了。
(流水线中的重命名单元)

通过硬件电路对寄存器重命名后,代码就变成了下面的样子,将SUB指令中的R1寄存器重命名为R5,结构冒险解决。
![]()
数据冒险指当前指令的执行需要上一条指令的运算结构,上一条指令没有运行结束,当前指令就无法运行,只能暂停执行。如下面的程序代码:
![]()
第二条SUB指令,要等待第一条ADD指令运行结束,将运算结果写回寄存器R2后才能执行。
现在的经典CPU流水线一般分为5级:取指、译码、执行、访问内存、写回。
也就是说,指令执行结束后还要把运算结果写回寄存器,然后下一条指令才可以到这个寄存器取数据。要解决流水线的数据冒险,方法有很多,如使用“operand forwarding”技术,当ADD指令运行结束后,不再执行后面的回写寄存器操作,而是直接使用运算结果。
第二个解决方法是在ADD和SUB指令中间插入空指令,即pipeline bubble,暂缓SUB指令的执行,等ADD指令将运算结果写回寄存器R2后再执行就可以了。
如下图所示,为了防止数据冒险,我们在时钟周期2和时钟周期3内,添加了两个空指令,让流水线暂时停顿(stall),产生空泡(bubble)。
(在流水线中添加空指令)

在第5个时钟周期,ADD指令执行结束,并将运算结果写回寄存器R2之后,SUB指令才在第6个时钟周期继续执行。
通过这种填充空指令的方式,SUB指令虽然延缓了2个时钟周期执行,但总比把后面已经预取的几十条指令全部丢掉强,尤其是当流水线很深时,这种方式很划算,你值得拥有。
控制冒险也是如此,当我们执行BEQ这样的条件判断指令,无法确定接下来要执行什么,无法确定到哪里取指令时,也可以采取上图所示的解决方法,插入几个空指令,等BEQ执行结束后再去取指令就可以了。
分支预测
条件跳转引起的控制冒险虽然也可以通过在流水中插入空泡来避免,但是当流水线很深时,需要插入更多的空泡。以一个20级深度的流水线为例,如果一条指令需要上一条指令执行结束才去执行,则需要在这两条指令之间插入19个空泡,相当于流水线要暂停19个时钟周期,这是CPU无法接受的。
如下图所示,为了避免这种情况发生,现在的CPU流水线在取指和译码时,都要对跳转指令进行分析,预测可能执行的分支和路径,防止预取错误的分支路径指令给流水线带来停顿。
(在流水线中添加分支预测单元)

根据工作方式的不同,分支预测可分为静态预测和动态预测。
静态预测在程序编译时通过编译器进行分支预测,这种预测方式对于循环程序最有效,它可以根据你的循环边界反复取指令。而对于跳转分支,静态预测就比较简单粗暴了,一般都是默认不跳转,按照顺序执行。
我们在编写有跳转分支的程序时,要记得把大概率执行的代码分支放在前面,这样可以明显提高代码的执行效率。如下面的分支跳转代码,写得就不好。

执行上面的代码,不用纠结,99.99%的概率会跳转到else分支执行。
如果我们在一个20级流水线的处理器上运行这个程序,一旦预测失败,就会浪费很多时钟周期去冲刷前面预取错误的流水线,从而大大降低程序的运行效率。我们可以稍微优化一下,将大概率执行的分支放到前面,就可以大概率避免流水线冲刷和停顿。

动态预测则指在程序运行时进行预测。
不同的软件、不同的程序分支行为,我们可以采取不同的算法去提高预测的准确率,如我们可以根据程序的历史执行路径信息来预测本次跳转的行为,常见的动态预测方式有1-bit动态预测、n-bit动态预测、下一行预测、双模态预测、局部分支预测、全局分支预测、融合分支预测、循环预测等。随着大量新的应用软件的出现,为了应对新的程序逻辑行为,分支预测器也做得越来越复杂,占用的芯片面积也越来越大。
在CPU内部,除了Cache,就数分支预测器的电路版图最大。
分支预测技术是提高CPU性能的一项关键技术,其本质就是去除指令之间的相关性,让程序更高效运行。
一个CPU性能高不高,不仅在于你的流水线有多深、主频有多高、Cache有多大,还和分支预测技术息息相关。
一个分支预测器好不好,我们可以从两个方面来衡量:分支判断速度和预测准确率。
目前分支预测技术可以达到95%的预测准确率,然而技术进化之路永未停止,分支预测技术一直在随着计算机的发展不断更新迭代。
乱序执行
我们编写的代码指令序列按照顺序依次存储在RAM中。
当程序执行时,PC指针会自动到RAM中去取,然后CPU按照顺序一条一条地依次执行,这种执行方式称为顺序执行(in order)。
当这些指令前后有数据依赖关系时,就会产生数据冒险,我们可以通过在指令序列之间添加空指令,让流水线暂时停顿来避免流水线中预期的指令被冲刷掉。
除此之外,我们还可以通过乱序执行(out of order)来避免流水线冲突。
造成流水线冲突的根源在于指令之间存在相关性:前后指令之间要么产生数据冒险,要么产生结构冒险。我们可以通过重排指令的执行顺序,而不是被动地填充空指令来去掉这种依赖。
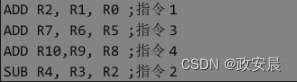
在上面的程序中,第二条SUB指令要使用第一条指令的运算结果,要等到第一条ADD指令运行结束后才能执行,于是就产生了数据冒险。我们可以通过在流水线中插入2个空指令来避免。

通过暂停流水线2个时钟周期,我们避免了流水线的冲突。
当指令序列中存在依赖关系的指令很多时,就需要在流水线中不停地插入空指令,造成流水线频繁地停顿,进而影响程序的运行效率。为了避免这种情况发生,我们可以将指令执行顺序重排,乱序执行。
因为指令3、指令4和指令1之间不存在相关性,因此我们可将它们放到前面执行。
等再次执行到指令2时,指令1已经执行结束,不存在数据冒险,此时我们就不需要在流水线中添加空指令了,CPU流水线满负载运行,效率提升。
支持乱序执行的CPU处理器,其内部一般都会有专门的乱序执行逻辑电路,该控制电路会对当前指令的执行序列进行分析,看能否提前执行。如整型计算、浮点型计算会使用不同的计算单元,同时执行这些指令并不会发生冲突。
CPU分析这些不相关的指令,并结合各电路单元的空闲状态综合判断,将能提前执行的指令进行重排,发送到相应的电路单元执行。
SIMD和NEON
一条指令一般由操作码和操作数构成,不同类型的指令,其操作数的数量可能不一样。
以加法指令为例,它有2个操作数:加数1和加数2。
当译码电路译码成功并开始执行ADD指令时,CPU的控制单元会首先到内存中取数据,将操作数送到算术逻辑单元中,取数据的方法有两种:
第一种是先取第一个操作数,然后访问内存读取第二个操作数,最后才能进行求和计算。这种数据操作类型一般称为单指令单数据(Single Instruction Single Data,SISD);
第二种方法是几个执行部件同时访问内存,一次性读取所有的操作数,这种数据操作类型称为单指令多数据(Single Instruction Multiple Data,SIMD)。
毫无疑问,SIMD通过单指令多数据运算,帮助CPU实现了数据并行访问,SIMD型的CPU执行效率更高。
随着多媒体技术的发展,计算机对图像、视频、音频等数据的处理需求大增,SIMD特别适合这种数据密集型计算:一条指令可以同时处理多个数据(音频或一帧图像数据)。为了满足这种需求,从1996年起,X86架构的处理器就开始不断地扩展这种SIMD指令集。
多媒体扩展(MultiMedia eXtensions,MMX)指令集是X86处理器为音视频、图像处理专门设计的57条SIMD多媒体指令集。
MMX将64位寄存器当作2个32位或8个8位寄存器来用,用来处理整型计算。这些寄存器并不是为MMX单独设计的,而是借用浮点运算的寄存器进行计算的,因此MMX指令和浮点运算不能同时工作。
SSE(Internet Streaming SIMD Extensions)指令集是Intel在奔腾三处理器中对MMX进行扩展的指令集。
SSE和MMX相比,不再占用浮点运算单元的寄存器,它有自己单独的128位寄存器,一次可处理128位数据。后来AVX(Advanced Vector Extensions)指令集将128位的寄存器扩展到256位,支持矢量计算,并全面兼容SSE及后续的扩展指令集系列SSE2/SSE3/SSE4。
短短几年后,AMD也不甘示弱,发布了3DNow!和SSE5指令集。3DNow!指令集基于Intel的MMX指令集进行扩展,不仅支持并行整型计算、并行浮点型计算,还可以混合操作整型和浮点型计算,不需要上下文来回切换,执行效率更高。
FMA(Fused-Multiply-Add)指令集,基于AVX指令集进行扩展,融合了加法和乘法,又称为积和熔加计算,可通过单一指令执行多次重复计算,简化了程序,比AVX更加高效,以适应绘图、渲染、立体音效等一些更复杂的多媒体运算。现在无论是Intel还是AMD,新版的CPU微架构都开始支持FMA指令集。
随着音乐播放、拍照、直播、小视频等多媒体需求在移动设备上的爆发,ARM架构的处理器也开始慢慢支持和扩展SIMD指令集。
如下图所示,NEON是适用于Cortex-A和Cortex-R52系列处理器的一种128位的SIMD扩展指令集。
(ARM处理器中的SIMD指令执行单元)

早期的浮点运算已不能满足需求,ARM从ARM V7指令集开始引入NEON多媒体SMID指令,通过向量化运算,更好地支持音视频编解码、计算机视觉AR/VR、游戏渲染、机器学习、深度学习等需要大量复杂计算的新应用场景。
单发射和多发射
SIMD指令可以用一条指令来处理多个数据,其实就是通过数据并行来提高执行效率的。
为应对日益复杂的多媒体计算需求,X86和ARM处理器都分别扩展了SIMD指令集,这些扩展的SIMD指令和其他指令一样,在流水线上也是串行执行的。
流水线通过前面的各种优化手段来提高吞吐率,其实就是通过提升处理器主频来提高运行效率。CPU的主频提升了,但处理器在每个时钟周期能执行的指令个数仍是不变的:每个时钟周期只能从存储器取一条指令,每个时钟周期也只能执行一条指令,这种处理器一般叫作单发射处理器。
多发射处理器在一个时钟周期内可以执行多条指令。处理器内部一般有多个执行单元,如算术逻辑单元(ALU)、乘法器、浮点运算单元(FPU)等,每个时钟周期内仅有一个执行单元在工作,其他执行单元都闲着,甜豆浆咸豆浆,喝一碗倒一碗,这是多么的浪费啊!双发射处理器可以在一个时钟周期内同时分发(dispatch)多条指令到不同的执行单元运行,让CPU同时执行不同的计算(加法、乘法、浮点运算等),从而达到指令级的并行。一个双发射处理器每个时钟周期理论上最多可执行2条指令,一个四发射处理器每个时钟周期理论上最多可以执行4条指令。
双发处理器的流水线如下图所示:

根据实现方式的不同,多发射处理器又可分为静态发射和动态发射。
静态发射指在编译阶段将可以并行执行的指令打包,合并到一个64位的长指令中。
在打包过程中,若找不到可以并行的指令配对,则用空指令NOP补充。这种实现方式称为超长指令集架构(Very Long Instruction Word,VLIW)。如下面的汇编指令,带有||的指令表示这两条指令要在一个时钟周期里同时执行。
![]()
VLIW实现简单,不需要额外的硬件,通过编译器在编译阶段就可以完成指令的并行。
早期的汇编语言不支持指令的并行化执行声明,随着处理器不断地迭代更新,为了保证指令集的兼容性,现在的处理器,如X86、ARM等都采用SuperScalar结构。采用SuperScalar结构的处理器又叫超标量处理器,如下图所示:
(超标量处理器的动态发射)
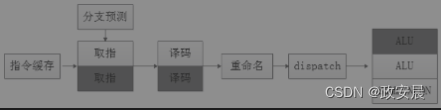
这种处理器在多发射的实现过程中会增加额外的取指单元、译码单元、逻辑控制单元等硬件电路。在指令运行时,将串行的指令序列转换为并行的指令序列,分发到不同的执行单元去执行,通过指令的动态并行化来提升CPU的性能。
大家不要把乱序执行和SuperScalar弄混淆了,两者不是一回事。
乱序执行是串行执行指令,只不过调整了指令的执行顺序而已,而SuperScalar则是并行执行多条指令。
两者在一个处理器中是可以共存的:一个处理器可以是双发射、顺序执行的,也可以是双发射、乱序执行的;可以是单发射、乱序执行的,当然也可以是单发射、顺序执行的。超标量处理器通过增加电路逻辑将指令并行化来提升性能,其代价是增大了芯片的面积和功耗。不同的处理器,根据自己的市场定位,可以灵活搭配合适的架构:是追求低功耗,还是追求高性能,还是追求性能和功耗的相对平衡,总能做出一道适合你的菜。
VLIW和SuperScalar分别从编译器和硬件上实现了指令的并行化,各有各的优势和局限性:
VLIW虽然实现简单,但由于兼容性问题,不支持目前主流的X86、ARM处理器;
而采用SuperScalar结构的处理器,完全依赖流水线硬件去动态识别可并行执行的指令,并分发到对应的执行单元执行,不仅大大增加了硬件电路的复杂性,而且也存在极限。
学者和工业界一致认为,同时执行8条指令将是SuperScalar结构的极限。
现在新架构的处理器没有指令集兼容的历史包袱,一般会采用显式并行指令计算(Explicitly Parallel Instruction Computing,EPIC)的指令集结构。EPIC结合了VLIW和SuperScalar的优点,允许处理器根据编译器的调度并行执行指令而不增加硬件的复杂性。
EPIC的实现原理也很简单,就是在指令中使用3个比特位来表示相邻的两条指令有没有相关性、当前指令要不要等上一条指令运行结束后才能执行。程序在运行时,流水线根据指令中的这些信息可以很轻松地实现指令的并行化和分发工作。
EPIC大大简化了CPU硬件逻辑电路的设计,1997年,Intel和HP联合开发的纯64位的安腾(Itanium)处理器就采用了EPIC结构。
多核CPU
半导体工艺和架构是提升CPU性能的双驾马车。
CPU的发展史,其实就是处理器架构和半导体工艺交互升级、协同演进的发展史。
半导体工艺采用更先进的制程,晶体管尺寸变小了,芯片面积降低了,CPU的主频就可以做得更高;
在相同的工艺制程下,通过不断优化CPU架构,从Cache、流水线、乱序执行、SIMD、多发射、指令预测等方面不断更新迭代,就可以设计出比别家公司性能更高、功耗更低的处理器。
单核处理器的瓶颈
在相同的半导体工艺制程下,芯片的面积越大,芯片的良品率就越低,芯片的成本就会越高,功耗也会越大。
美国加利福尼亚州有家名叫Cerebras的创业公司发布了一款专为人工智能打造、号称史上最大的AI芯片,这款名为Wafer Scale Engine(WSE)的芯片由1.2万亿个晶体管构成,采用台积电16nm工艺,芯片面积比一个iPad还大,功耗15 000W,比6台电磁炉的总功率还大。如果把这款处理器用在你的手机上,“充电5小时,通话2分钟”,绝对不是梦想。现在处理器的发展趋势就是在提升性能的情况下,功耗越做越低,这样的产品在市场上才有竞争力。
而在相同的工艺下,提升芯片性能和减少功耗之间往往又是冲突的。
以Cache为例,我们可以通过增加L1、L2、L3级Cache的容量来增加Cache的命中率,提高CPU的性能,但芯片的面积和功耗也会随之增加。流水线同样如此,我们可以通过增加流水线级数、减少每一级流水的时间延迟,来提高处理器的主频,但随之而来的就是芯片电路的复杂性增加。鱼与熊掌不可兼得,很多厂家在发布自己的处理器时,都会根据产品的市场定位在性能、成本和功耗之间反复做平衡,或者干脆发布一系列低、中、高端产品:要么追求高性能,要么追求低功耗,要么追求能效比。
单核时代的玩法玩得差不多了,就要换种新玩法,才能让消费者有欲望和动力扔掉旧机器,刷着花呗白条更新换代。于是,一个更加缤纷多彩的多核大战时代来临了。
片上多核互连技术
现代的计算机,无论是PC、手机还是服务器,一般都是多个任务同时运行,单核CPU的性能再强劲,其实也是在串行执行这几个任务,多个任务轮流占用CPU运行。只要任务切换得足够快,就可以以假乱真,让用户觉得多个程序在同时运行。
多核处理器则可以让多个任务真正地同时执行。在单核处理器通过指令级并行性能提升空间有限的情况下,通过多核在任务级做到真正并行,可以进一步提升CPU的整体性能。
单核处理器芯片内部除了集成CPU的各个基本电路单元,还集成了各级Cache。当在一个芯片内部集成多个核(Core)时,各个Core之间怎么连接呢?Cache是每个Core独享,还是共享?不同架构的处理器,甚至相同架构不同版本的处理器,其连接方式都不一样。
早期的计算机比较简单,CPU和内存、I/O模块直接相连,这种连接也称为星型连接。星型连接通信效率最高,但是浪费的资源也多。举一个简单的例子,如邮局,如下图左侧部分所示:
(星型连接与总线型连接)
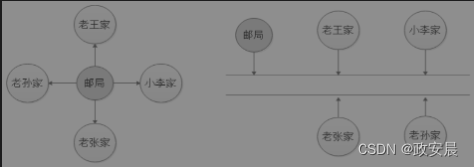
计算机的CPU和其他模块,如果像邮局一样采用星型连接,通信效率确实高效,快递员到每家都有专门的道路,永不堵车。
但星型连接成本高、可扩展性差:
如果老王家的小王结婚盖了新房,则还需要专门修一条新公路,从邮局通到小王家;
小李家拆迁了,乔迁新居,原来的公路就浪费了,还得继续修公路通到新家。为了解决这种缺陷,如上图图右侧部分所示,总线型连接就产生了:各家共享公路资源,邮局对他们各家进行编址管理。总线型连接可以随意增加或减少连接模块,兼容性和扩展性都大大增强。
在单核处理器时代,总线型连接是最理想和最经济的,但是到了多核时代就未必如此了。
总线型连接也有缺陷,在某一个时刻只允许一对设备进行通信,如下图所示,当多个Core同时想占用总线与外部设备通信时,就会产生竞争,进而影响通信效率。
(多核CPU的总线型连接)
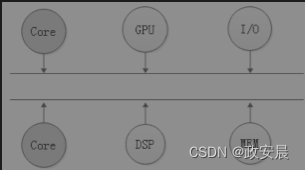
一个解决方法是使用线性阵列,分段使用总线,就像高速公路上的不同收费点一样,多个处理器可以分段使用总线资源进行通信,如IBM的Cell处理器。另一个解决方法是使用交叉开关(Crossbar),如下图左侧部分所示(交叉开关型连接):
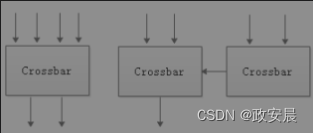
交叉开关像路由器一样有多个端口,多个Core可以通过交叉开关的端口互连,并行通信。
相互通信的各对节点都是独立的,互不干扰。交叉开关可以提高通信效率,但其自身也会占用芯片面积,功耗很大,尤其当连接设备很多,交叉开关的端口很多时,芯片面积和功耗会急剧上升。为了缓解这一矛盾,我们可以使用层次化交叉开关(如上图右侧部分所示),通过层次化交叉开关可以在局部构建一个节点的集群,然后在上一层将每个局部的集群看成一个节点,再通过合适的方式进行连接。
层次化交叉开关利用网络通信的局部特征,缓解了单个开关在连接的节点上升时产生的性能下降,在性能、芯片面积和功耗之间达到一个平衡。交叉开关两两互连,处理器的多个Core之间通过开关可以相互独立通信,效率很高(如下图左侧部分所示)。
(交叉开关型结构与Ring Bus结构)
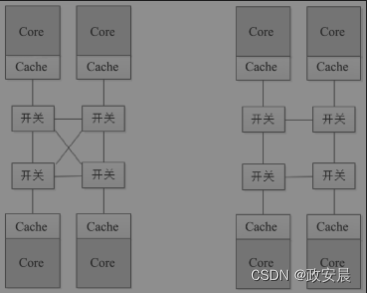
但随之而来的问题是,随着连接节点增多,交叉开关的互连逻辑也越来越复杂,功耗和占用的芯片面积也越来越大,所以这种连接结构一般适用于四核以下的CPU。四核以上的CPU可以采用Ring Bus结构(如上图右侧部分所示):将总线和交叉开关结合起来,连成一个环状,相邻的两个Core通信效率最高,远离的两个Core之间可以通过开关路由通信。Intel的八核处理器一般都是采用这种结构的。
Ring Bus结构结合了总线型连接和开关型连接两者的优点,在成本功耗和通信效率之间达到一个平衡,但是也有局限性,当这个环上连接的Core很多时,通信延迟又会带来效率下降。面向服务器的处理器一般都是16核以上的,这种众核结构如果再使用以上连接方式则都会有局限性,影响多核整体性能的发挥。
面向众核处理器领域,目前比较流行的一种片上互连技术叫作片上网络(Net On Chip,NoC)。现在比较常用的二维Mesh网络如下图所示(二维Mesh网络):
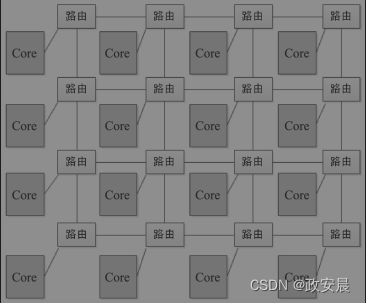
当处理器的Core很多时,我们不再使用总线型连接,而是使用网络节点的方式连接。
每个节点包括计算单元、通信单元及其附属电路。
计算和通信实现了分离,每一个节点中的处理单元可以是一个Core,也可以是一个小规模的SoC。
Core与Core之间的通信基于通信协议进行,数据包在网络中按照设定的路由算法传输,通过网络通信的分布化来避免总线的竞争。
当2D Mesh网络连接的Core很多时,距离较远的两个Core,因为经过太多的路由,通信延迟也会对处理器整体性能产生一定影响。将网络路径中每一条线的首尾路由节点相连,就变成了二维的Ring Bus结构,即Torus网络,可以进一步减少路由路径较远时带来的通信延迟。
NoC根据连接的节点类型,可分为同构和异构两种类型:
同构指网络上连接的节点处理器类型都是一样的,如都是CPU的Core;
而异构则指网络上可以连接不同类型的处理单元,如GPU、DSP、NPU、TPU等。
随着人工智能、大数据、物联网等技术的发展,我们需要在同一个处理器中集成不同类型的运算单元,如CPU、GPU、NPU等。如何更方便地连接它们,如何让它们更高效地协同工作,如何避免“一核有难,八核围观”的尴尬局面,如何提升处理器的整体性能,成为目前NoC领域研究的热点。
big.LITTLE结构
多个Core集成到一个处理器上,当CPU负载很大时,多个Core一起上阵确实可以提高工作效率,但是当工作任务不是很多时,如只开一个QQ,然后八个核一起跑,只有一个Core在工作,其他Core也开始跟着空转打酱油,随之带来的就是功耗的上升。
为了避免这种情况,ARM推出了big.LITTLE架构,也就是大小核架构:一个处理器内部集成的有高性能的Core,也有低功耗的Core。当CPU工作负载很重时,启动高性能的Core工作;当CPU很闲时,则切换到低功耗的Core上工作。根据不同的应用场景和工作负载,CPU分配不同的Core工作,可以在性能和功耗之间达到一个平衡。
ARM处理器针对多核采取了分层设计,如下图所示:
(ARM处理器的big.LITTLE架构)
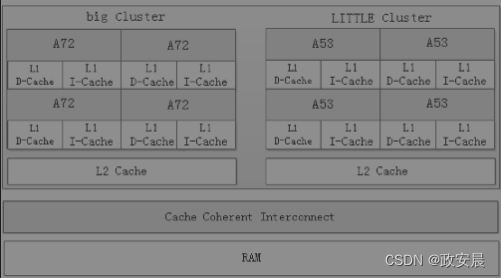
将所有的高性能核放到一个簇(Cluster)里,构成一个big Cluster,将多个低功耗核放到另一个Cluster里,构成LITTLE Cluster。
处理器中的每个Core都有自己独立的数据Cache和指令Cache,每个Cluster共享L2 Cache。为了保证多个Core运行时Cache和RAM中的数据相同,两个Cluster之间通过缓存一致性接口相连,不仅保证多个Core之间的高效通信,还通过检测电路,保证了多个Cache之间、Cache和RAM之间的数据一致性,避免程序运行出错。
操作系统运行时,可以根据CPU的负载情况灵活地在两个Cluster之间来回切换。
为了更好地在性能和功耗之间达到平衡,我们甚至可以进行更精细的调度:
当CPU负载较轻时,使用小核;
当CPU负载一般时,大核和小核混合使用;
只有当CPU负载较高时,才全部使用大核工作。
随着ARM的大小核设计技术越来越成熟,在软件上的优化越来越得心应手,越来越多的厂家开始使用这项技术去设计自己的处理器,大小核设计目前已经成为ARM多核处理器的标配。
超线程技术
在多核处理器设计中,还有一种技术叫超线程技术(Hyper-Threading,HT),目前主要应用在Intel、AMD的X86多核处理器上。大家买计算机时,经常会看到4核8线程、6核12线程的说明,带有这些字眼的处理器一般都采用了超线程技术。
什么是超线程技术呢?
网上有个例子讲得很形象,这里就拿来跟大家分享一下:
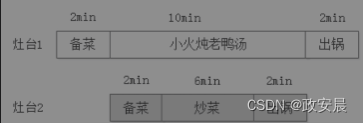
假如你是一个餐馆的老板,雇了一个厨师烧菜,顾客点了两道菜:老鸭汤和宫保鸡丁。厨师接单后,开始做起来。如图2-50所示,老鸭汤从备菜到出锅需要14min,宫保鸡丁从备菜到出锅需要10min,两道菜总共需要24min。
为了提高上菜速度,老板有两个方法:
一是再雇一个厨师,每个厨师同时各做一道菜;
二是在厨房里再增加一个灶台,让厨师分别在两个灶台上同时做这两道菜。只要老板智商没问题,肯定会选第二种,因为老板发现厨师在煲汤的十分钟里一直闲着没事干,顾客早就等得不耐烦了,厨师却在那里刷抖音。
再雇一个厨师的成本太高,如下图所示,再添一个灶台,就可以让厨师一直忙,既节省了人力成本,又可以将做两道菜的时间缩减到14min。

如果把厨师看作CPU,则选择第一种方案就是双核处理器,选择第二种方案是单核双线程处理器。超线程技术通过增加一定的控制逻辑电路,使用特殊指令可以将一个物理处理器当两个逻辑处理器使用,每个逻辑处理器都可以分配一个线程运行,从而最大限度地提升CPU的资源利用率。超线程技术在CPU内部的实现原理也很简单,我们以学校旁边打印店里的打印机为例,如下图所示:
当打印店的生意很火爆时,老板一般会多购买几台打印设备(计算机+打印机)。
如果每台计算机配一台打印机,成本会很高,而且打印机也不是一直在用,大部分时间都在闲着,因为大部分时间都花费在文档的输入、修改和设计上了。为了充分利用打印机资源,节省成本,老板可以只买一台打印机,然后将两台计算机通过虚拟打印机设置都连接到这台打印机上。如果把打印机看作CPU的Core,那么这种共享打印机的设置其实就是超线程技术。
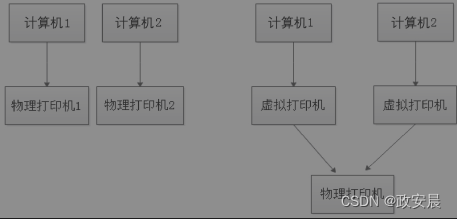
超线程技术的实现原理和打印机类似:如下图所示:
(CPU的超线程技术)
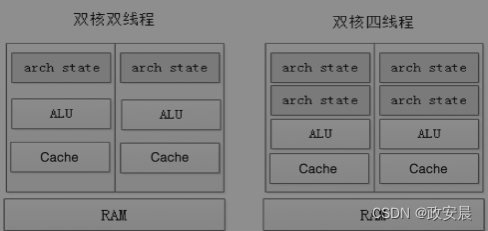
在CPU内部很多资源其实也是可以共享的,如ALU、FPU、Cache、总线等,也有很多资源是每个线程独有的,如寄存器状态、堆栈等。我们通过增加一些控制逻辑电路,保存各个线程的状态,共享ALU、Cache等共享资源,就可以在一个物理Core上实现两个逻辑Core,操作系统可以给每个逻辑Core都分配1个线程运行。
这里需要注意的是,在同一个物理Core上的两个线程并不是同时运行的,因为每个线程都需要使用物理Core上的共享资源(如ALU、Cache等)。
但是两个线程之间可以互相协助运行,一般处理器上的两个线程上下文切换需要20 000个时钟周期,而超线程处理器上的两个线程切换只需要一个时钟周期就可以了,上下文切换的时间开销大大减少。
超线程技术其实就是“欺骗”操作系统,让操作系统认为它有更多的Core,给它分配更多的任务执行,通过减少CPU的空闲时间来提高CPU的利用率。因为线程在两个逻辑处理器上并不是真正的并行,所以也不可能带来2倍的性能提升,但是通过增加5%左右的芯片面积换来CPU 15%~30%的性能提升,还是很划算的。
超线程技术的使用也离不开硬件和软件层面的支持。首先主板和BIOS要支持超线程技术,操作系统也需要对超线程技术有专门的优化。Windows操作系统从Windows XP以后开始支持超线程技术,GNU/Linux操作系统则从Linux-2.6以后开始支持超线程技术。除此之外,应用层面也需要支持超线程技术,如NPTL库等。
并不是所有的场合都适合使用超线程技术,你可以根据自己的实际需求选择开启或关闭超线程。
在高并发的服务器场合下,使用超线程技术确实可以提升性能,但在一些对单核性能要求比较高的场合,如大型游戏,开启超线程反而会增加系统开销,影响性能。
在Intel和AMD的处理器产品系列中,你会发现并不是所有的处理器都使用了超线程技术,甚至某代处理器全部放弃使用,而最新的Intel 10代处理器则又卷土重来,全面开启超线程。
CPU这件事咱们就告一段落了。