强化学习算法
(一)动态规划方法——策略迭代算法(PI)和值迭代算法(VI)
(二)Model-Free类方法——蒙特卡洛算法(MC)和时序差分算法(TD)
(三)基于动作值的算法——Sarsa算法与Q-Learning算法
(四)深度强化学习时代的到来——DQN算法
(五)最主流的算法框架——Actor-Critic算法框架
(六)应用最广泛的算法——PPO算法
(七)更高级的算法——DDPG算法与TD3算法
(八)待续
文章目录
- 强化学习算法
- 前言
- 一、REINFORCE算法
- 1. 核心原理
- 2. 代码实现
- 二、Actor-Critic算法框架
- 1. AC算法的核心思想
- 2.AC算法代码实现
前言
在以往学习的算法中,我们均围绕状态价值或动作价值间接优化策略,本章开始我们将学习一类新的算法——策略梯度算法,这种算法通过直接优化策略函数得到最优策略。该类算法更强调实用性是,不需要认识每个状态的价值,直接得到最优策略。在本章我们将从最基本的策略梯度算法REINFORCE开始介绍,然后介绍现今强化学习领域最流行的算法框架Actor-Critic算法框架。
一、REINFORCE算法
1. 核心原理
我们从最原始的策略梯度算法——REINFORCE算法开始学习,REINFORCE算法接优化策略函数(Policy),而不是像DQN那样先学值函数再推导策略。
假设你训练一只小狗做动作(坐下、握手):
- DQN方式:先告诉它每个动作的“潜在奖励”,再让它选奖励最高的动作。
- 策略梯度:直接告诉它“某个动作做得很好,以后要多做”,通过试错直接调整动作概率。
下面我们通过推导的形式得到REINFORCE算法的核心公式:
策略梯度定理的核心目标是通过梯度上升优化策略参数
θ
θ
θ,最大化期望回报
J
(
θ
)
=
E
[
∑
t
=
0
∞
γ
t
r
t
]
J(\theta )=\mathbb{E}[ {\textstyle \sum_{t=0}^{\infty }}γ^t r_t]
J(θ)=E[∑t=0∞γtrt]。
将
J
(
θ
)
J(\theta )
J(θ)写成如下形式
J
(
θ
)
=
∫
P
(
τ
;
θ
)
R
(
τ
)
d
τ
J(\theta )=\int P(\tau;\theta)R(\tau)d\tau
J(θ)=∫P(τ;θ)R(τ)dτ其中,积分符号表示连续环境下对所有可能的取值进行加权平均。
P
(
τ
;
θ
)
P(\tau;\theta)
P(τ;θ)为生成某条轨迹的概率,可以将其拆解为
P
(
τ
;
θ
)
=
∏
t
=
0
T
π
(
a
t
∣
s
t
;
θ
)
⋅
P
(
s
t
+
1
∣
s
t
,
a
t
)
P(\tau;\theta)={\textstyle \prod_{t=0}^{T}}\pi(a_t|s_t;\theta)\cdot P(s_{t+1}|s_t,a_t)
P(τ;θ)=∏t=0Tπ(at∣st;θ)⋅P(st+1∣st,at),也就是策略与状态转移矩阵的概率乘积。
R
(
τ
)
R(\tau)
R(τ)表示该条轨迹获得的奖励值之和。我们以上述形式做为目标函数,并对其求导得到
∇
θ
J
(
θ
)
=
∫
∇
θ
P
(
τ
;
θ
)
R
(
τ
)
d
τ
\nabla _\theta J(\theta )=\int \nabla _\theta P(\tau;\theta)R(\tau)d\tau
∇θJ(θ)=∫∇θP(τ;θ)R(τ)dτ这里我们再对
∇
θ
P
(
τ
;
θ
)
\nabla _\theta P(\tau;\theta)
∇θP(τ;θ)利用对数微分技巧,得到
∇
θ
ln
P
(
τ
;
θ
)
=
∇
θ
P
(
τ
;
θ
)
P
(
τ
;
θ
)
\nabla _\theta \ln P(\tau;\theta)=\frac{\nabla _\theta P(\tau;\theta)}{P(\tau;\theta)}
∇θlnP(τ;θ)=P(τ;θ)∇θP(τ;θ)因此,
∇
θ
P
(
τ
;
θ
)
=
∇
θ
ln
P
(
τ
;
θ
)
⋅
P
(
τ
;
θ
)
\nabla _\theta P(\tau;\theta)=\nabla _\theta \ln P(\tau;\theta) \cdot P(\tau;\theta)
∇θP(τ;θ)=∇θlnP(τ;θ)⋅P(τ;θ),代入原式得到
∇
θ
J
(
θ
)
=
∫
∇
θ
ln
P
(
τ
;
θ
)
R
(
τ
)
d
τ
\nabla _\theta J(\theta )=\int \nabla _\theta \ln P(\tau;\theta) R(\tau)d\tau
∇θJ(θ)=∫∇θlnP(τ;θ)R(τ)dτ而
P
(
τ
;
θ
)
=
∏
t
=
0
T
π
(
a
t
∣
s
t
;
θ
)
⋅
P
(
s
t
+
1
∣
s
t
,
a
t
)
P(\tau;\theta)={\textstyle \prod_{t=0}^{T}}\pi(a_t|s_t;\theta)\cdot P(s_{t+1}|s_t,a_t)
P(τ;θ)=∏t=0Tπ(at∣st;θ)⋅P(st+1∣st,at),去掉其中与
θ
\theta
θ无关的项得到下式
∇
θ
J
(
θ
)
=
E
[
R
(
τ
)
∑
t
=
0
T
∇
θ
ln
π
(
a
t
∣
s
t
;
θ
)
]
\nabla _\theta J(\theta )=\mathbb{E}[R(\tau)\sum_{t=0}^{T} \nabla _\theta \ln\pi(a_t|s_t;\theta)]
∇θJ(θ)=E[R(τ)t=0∑T∇θlnπ(at∣st;θ)]不同的策略梯度算法对上述梯度的计算方式不同,REINFORCE算法通过采样 N 条轨迹来近似期望值:
∇
θ
J
(
θ
)
≈
1
N
∑
i
=
1
N
[
R
(
τ
i
)
∑
t
=
0
T
∇
θ
ln
π
(
a
i
,
t
∣
s
i
,
t
;
θ
)
]
\nabla _\theta J(\theta )\approx\frac{1}N{}\sum_{i=1}^N[R(\tau_i)\sum_{t=0}^{T} \nabla _\theta \ln\pi(a_{i,t}|s_{i,t};\theta)]
∇θJ(θ)≈N1i=1∑N[R(τi)t=0∑T∇θlnπ(ai,t∣si,t;θ)]因此,REINFORCE算法每个轮次的梯度上升公式可以表示为:
θ
←
θ
+
α
⋅
γ
t
G
t
⋅
∇
θ
log
π
(
a
t
∣
s
t
;
θ
)
\theta ←\theta+α\cdotγ^tG_t\cdot\nabla _\theta\log\pi(a_t|s_t;\theta)
θ←θ+α⋅γtGt⋅∇θlogπ(at∣st;θ)
这里的 G t G_t Gt就是AC算法中Actor网络更新的核心要点了, G t G_t Gt可以变成多种形式,若换为TD Error
就成了经典AC算法的Actor更新公式;若换为 A t = Q t − A t A_t=Q_t-A_t At=Qt−At,则是以优势函数为基础的A2C算法。
2. 代码实现
REINFPRCE算法的实现如下
import gym
import numpy as np
import matplotlib.pyplot as plt
import torch
import torch.nn as nn
import torch.optim as optim
from collections import deque
import random
# 设置支持中文的字体
plt.rcParams['font.sans-serif'] = [
'SimHei', # 中易黑体 (Windows)
'Microsoft YaHei', # 微软雅黑 (Windows)
'WenQuanYi Zen Hei', # 文泉驿正黑 (Linux)
'Arial Unicode MS' # macOS
]
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题
# 超参数设置
GAMMA = 0.99 # 折扣因子
LR = 0.001 # 学习率
HIDDEN_SIZE = 128 # 网络隐藏层大小
reward_list = []
# 定义设备(自动检测GPU可用性)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 定义策略网络结构
class PolicyNetwork(nn.Module):
def __init__(self, state_dim, action_dim):
super(PolicyNetwork, self).__init__()
self.fc = nn.Sequential(
nn.Linear(state_dim, HIDDEN_SIZE),
nn.ReLU(),
nn.Linear(HIDDEN_SIZE, action_dim),
nn.Softmax(dim=-1) # 输出动作概率
)
def forward(self, x):
return self.fc(x)
# REINFORCE智能体
class REINFORCEAgent:
def __init__(self, state_dim, action_dim):
self.action_dim = action_dim
# 策略网络
self.policy_net = PolicyNetwork(state_dim, action_dim).to(device)
self.optimizer = optim.Adam(self.policy_net.parameters(), lr=LR)
# 存储回合数据的缓冲区
self.states = []
self.actions = []
self.rewards = []
def choose_action(self, state):
""" 根据策略网络采样动作 """
state_tensor = torch.FloatTensor(state).to(device)
probs = self.policy_net(state_tensor)
action_dist = torch.distributions.Categorical(probs)
action = action_dist.sample().item()
return action
def store_transition(self, state, action, reward):
""" 存储回合数据 """
self.states.append(state)
self.actions.append(action)
self.rewards.append(reward)
def update_model(self):
""" 使用完整回合数据更新策略 """
# 计算每个时间步的折扣回报
returns = []
G = 0
for r in reversed(self.rewards):
G = r + GAMMA * G
returns.insert(0, G)
# 转换为张量
states = torch.FloatTensor(np.array(self.states)).to(device)
actions = torch.LongTensor(self.actions).to(device)
returns = torch.FloatTensor(returns).to(device)
# 归一化回报(减少方差)
returns = (returns - returns.mean()) / (returns.std() + 1e-9)
# 计算策略梯度
probs = self.policy_net(states)
# 计算log π(a_t|s_t;θ)
log_probs = torch.log(probs.gather(1, actions.unsqueeze(1)))
loss = -(log_probs.squeeze() * returns).mean()
# 梯度下降
self.optimizer.zero_grad()
loss.backward()
self.optimizer.step()
# 清空回合数据
self.states = []
self.actions = []
self.rewards = []
# 训练流程
def train_reinforce(env_name, episodes):
env = gym.make(env_name)
state_dim = env.observation_space.shape[0]
action_dim = env.action_space.n
agent = REINFORCEAgent(state_dim, action_dim)
for episode in range(episodes):
state = env.reset()[0]
episode_reward = 0
done = False
while not done:
# 1. 选择并执行动作
action = agent.choose_action(state)
next_state, reward, terminated, truncated, _ = env.step(action)
done = terminated or truncated
# 2. 存储转移数据
agent.store_transition(state, action, reward)
state = next_state
episode_reward += reward
# 3. 使用完整回合数据更新策略
agent.update_model()
# 记录训练进度
reward_list.append(episode_reward)
if (episode + 1) % 10 == 0:
print(f"Episode: {episode + 1}, Reward: {episode_reward}")
env.close()
if __name__ == "__main__":
env_name = "CartPole-v1"
episodes = 2000
train_reinforce(env_name, episodes)
np.save(f"result/REINFORCE_rewards.npy", np.array(reward_list))
plt.plot(range(episodes), reward_list)
plt.xlabel('迭代次数')
plt.ylabel('每代的总奖励值')
plt.title('REINFORCE的训练过程')
plt.grid(True)
plt.show()
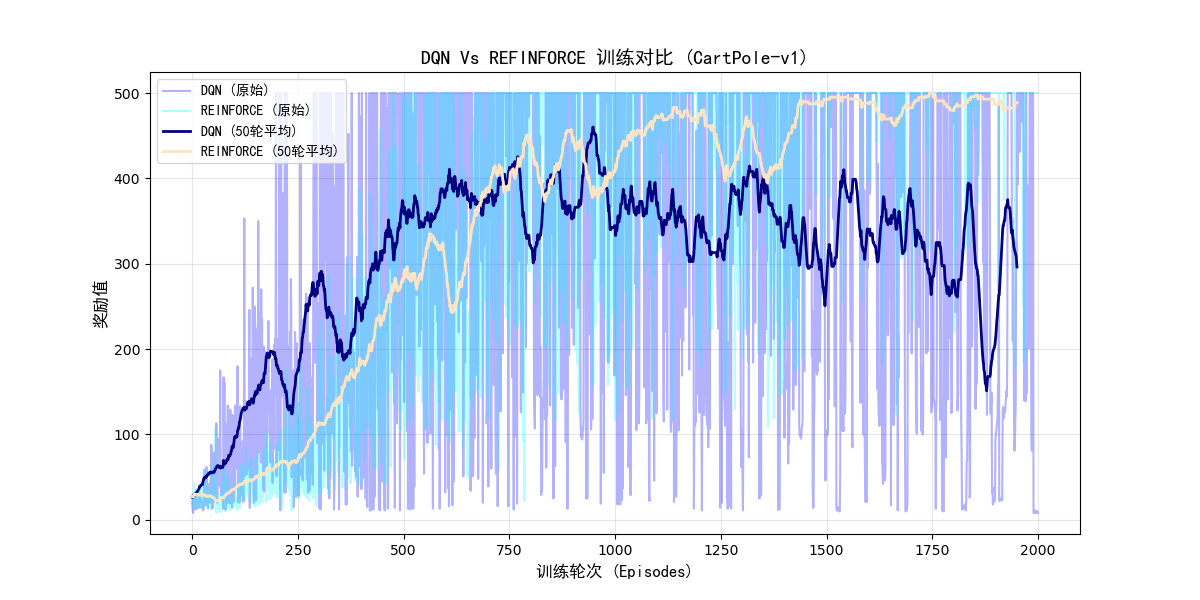
算法对比绘图代码
import numpy as np
import matplotlib.pyplot as plt
# 加载数据(注意路径与图中一致)
dqn_rewards = np.load("dqn_rewards.npy")
REFINORCE_rewards = np.load("REINFORCE_rewards.npy")
plt.figure(figsize=(12, 6))
# 绘制原始曲线
plt.plot(dqn_rewards, alpha=0.3, color='blue', label='DQN (原始)')
plt.plot(REFINORCE_rewards, alpha=0.3, color='cyan', label='REINFORCE (原始)')
# 绘制滚动平均曲线(窗口大小=50)
window_size = 50
plt.plot(np.convolve(dqn_rewards, np.ones(window_size)/window_size, mode='valid'),
linewidth=2, color='navy', label='DQN (50轮平均)')
plt.plot(np.convolve(REFINORCE_rewards, np.ones(window_size)/window_size, mode='valid'),
# 图表标注
plt.xlabel('训练轮次 (Episodes)', fontsize=12, fontfamily='SimHei')
plt.ylabel('奖励值', fontsize=12, fontfamily='SimHei')
plt.title('DQN Vs REFINFORCE 训练对比 (CartPole-v1)', fontsize=14, fontfamily='SimHei')
plt.legend(loc='upper left', prop={'family': 'SimHei'})
plt.grid(True, alpha=0.3)
# 保存图片(解决原图未保存的问题)
# plt.savefig('comparison.png', dpi=300, bbox_inches='tight')
plt.show()
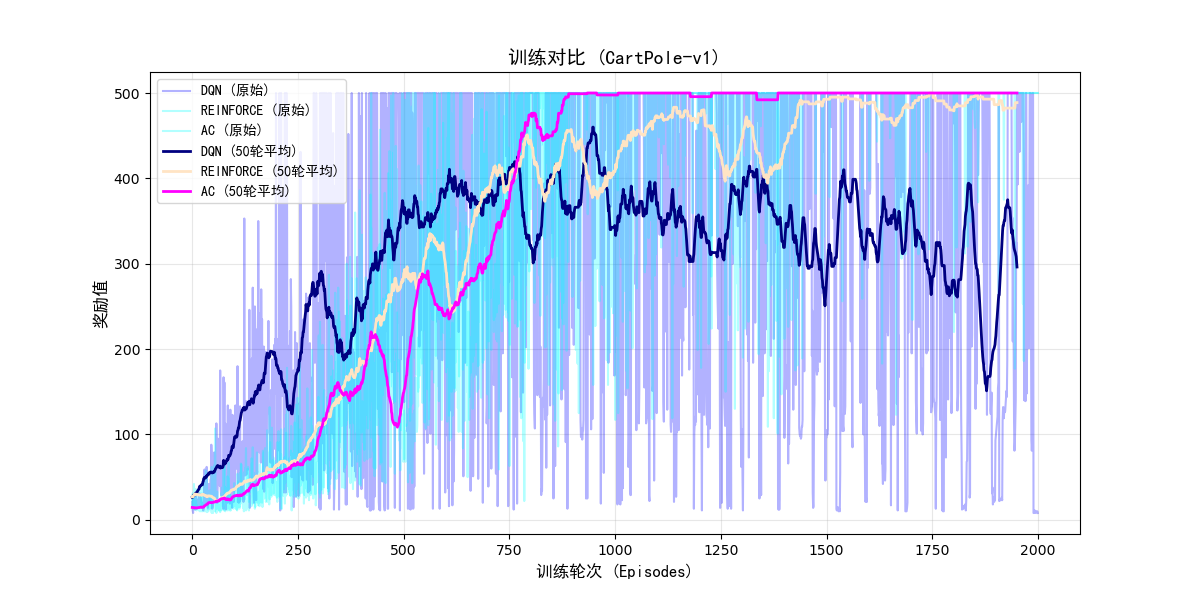
算法运行结果及对比:
二、Actor-Critic算法框架
1. AC算法的核心思想
Actor-Critic(演员-评论家)算法框架当前强化学习算法中最流行的算法框架,这种算法框架融合了值函数近似与策略梯度两种算法的核心思想,后续的PPO、SAC、DDPG等算法均是在此框架下提出的。这里我们首先介绍一下最经典的AC算法核心思想。
Actor-Critic算法结合了策略梯度(Actor)和值函数近似(Critic)其中:
- Actor:策略网络 π ( a ∣ s ; θ ) π(a∣s;θ) π(a∣s;θ),负责生成动作。
- Critic:价值网络 V ( s ; ϕ ) V(s;ϕ) V(s;ϕ)(或 Q ( s , a ; ϕ ) Q(s,a;ϕ) Q(s,a;ϕ)),评估状态或动作的价值,提供策略优化的方向引导。
Actor根据Critic的评估结果调整策略;Critic通过环境反馈优化价值估计。
下面介绍他们的核心更新公式。
-
Critic的更新(值函数估计)
经典AC算法中的 Critic网络通过最小化时序差分误差(TD Error)优化函数,我们可以把Critic网络看成一个执行TD算法的网络,其更新公式可以表示为:
ϕ ← ϕ − α ϕ ⋅ ∇ ϕ ( r t + γ V ( s t + 1 ; ϕ ) − V ( s t ; ϕ ) ) 2 \phi ←\phi -α_\phi \cdot \nabla_\phi(r_t+γV(s_{t+1};\phi)-V(s_t;\phi))^2 ϕ←ϕ−αϕ⋅∇ϕ(rt+γV(st+1;ϕ)−V(st;ϕ))2 -
Actor的更新(策略梯度)
Actor利用Critic提供的优势函数,通过梯度上升优化策略:
θ ← θ + A ( s t , a t ) ⋅ ∇ θ log π ( a t ∣ s t ; θ ) \theta ← \theta+A(s_t,a_t)\cdot\nabla_\theta\log\pi(a_t|s_t;\theta) θ←θ+A(st,at)⋅∇θlogπ(at∣st;θ)其中,优势函数 A ( s t , a t ) A(s_t,a_t) A(st,at)可以是TD形式,也可以是Q值形式。即 A ( s t , a t ) = r t + γ V ( s t + 1 ) − V ( s t ) A(s_t,a_t)=r_t+γV(s_{t+1})-V(s_t) A(st,at)=rt+γV(st+1)−V(st)或 A ( s t , a t ) = Q ( s t , a t ) − V ( s t ) A(s_t,a_t)=Q(s_t,a_t)-V(s_t) A(st,at)=Q(st,at)−V(st),前者为AC算法,后者为A2C算法。
2.AC算法代码实现
import gym
import numpy as np
import matplotlib.pyplot as plt
import torch
import torch.nn as nn
import torch.optim as optim
from collections import deque
import random
# 设置支持中文的字体
plt.rcParams['font.sans-serif'] = [
'SimHei', # 中易黑体 (Windows)
'Microsoft YaHei', # 微软雅黑 (Windows)
'WenQuanYi Zen Hei', # 文泉驿正黑 (Linux)
'Arial Unicode MS' # macOS
]
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题
# 超参数设置
GAMMA = 0.99 # 折扣因子
LR_ACTOR = 0.001 # Actor网络学习率
LR_CRITIC = 0.01 # Critic网络学习率
HIDDEN_SIZE = 128 # 网络隐藏层大小
reward_list = []
# 定义设备(自动检测GPU可用性)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 定义策略网络结构(Actor)
class Actor(nn.Module):
def __init__(self, state_dim, action_dim):
super(Actor, self).__init__()
self.fc = nn.Sequential(
nn.Linear(state_dim, HIDDEN_SIZE),
nn.ReLU(),
nn.Linear(HIDDEN_SIZE, action_dim),
nn.Softmax(dim=-1) # 输出动作概率
)
def forward(self, x):
return self.fc(x)
# 定义价值网络结构(Critic)
class Critic(nn.Module):
def __init__(self, state_dim):
super(Critic, self).__init__()
self.fc = nn.Sequential(
nn.Linear(state_dim, HIDDEN_SIZE),
nn.ReLU(),
nn.Linear(HIDDEN_SIZE, 1) # 输出状态价值
)
def forward(self, x):
return self.fc(x)
# Actor-Critic智能体
class ACAgent:
def __init__(self, state_dim, action_dim):
self.action_dim = action_dim
# 创建Actor和Critic网络
self.actor = Actor(state_dim, action_dim).to(device)
self.critic = Critic(state_dim).to(device)
# 优化器
self.actor_optimizer = optim.Adam(self.actor.parameters(), lr=LR_ACTOR)
self.critic_optimizer = optim.Adam(self.critic.parameters(), lr=LR_CRITIC)
# 存储回合数据的缓冲区
self.states = []
self.actions = []
self.rewards = []
self.next_states = []
self.dones = []
def choose_action(self, state):
""" 根据策略网络采样动作 """
state_tensor = torch.FloatTensor(state).to(device)
probs = self.actor(state_tensor)
action_dist = torch.distributions.Categorical(probs)
action = action_dist.sample().item()
return action
def store_transition(self, state, action, reward, next_state, done):
""" 存储转移数据(需要记录下一状态和终止标志) """
self.states.append(state)
self.actions.append(action)
self.rewards.append(reward)
self.next_states.append(next_state)
self.dones.append(done)
def update_model(self):
""" 使用完整回合数据更新网络 """
# 转换为张量
states = torch.FloatTensor(np.array(self.states)).to(device)
actions = torch.LongTensor(self.actions).to(device)
rewards = torch.FloatTensor(self.rewards).to(device)
next_states = torch.FloatTensor(np.array(self.next_states)).to(device)
dones = torch.BoolTensor(self.dones).to(device)
# ----------------- Critic更新 -----------------
# 计算当前状态价值 V(s)
current_v = self.critic(states).squeeze()
# 计算目标价值 V_target = r + γ * V(s')
with torch.no_grad():
next_v = self.critic(next_states).squeeze()
next_v[dones] = 0.0 # 终止状态无后续价值
v_target = rewards + GAMMA * next_v
# 计算Critic损失(均方误差)
critic_loss = nn.MSELoss()(current_v, v_target)
# 梯度下降
self.critic_optimizer.zero_grad()
critic_loss.backward()
self.critic_optimizer.step()
# ----------------- Actor更新 -----------------
# 重新计算当前状态价值 V(s)(使用更新后的Critic)
with torch.no_grad():
current_v = self.critic(states).squeeze()
next_v = self.critic(next_states).squeeze()
next_v[dones] = 0.0
td_errors = rewards + GAMMA * next_v - current_v
# 计算策略梯度
probs = self.actor(states)
log_probs = torch.log(probs.gather(1, actions.unsqueeze(1)))
actor_loss = -(log_probs.squeeze() * td_errors).mean()
# 梯度上升
self.actor_optimizer.zero_grad()
actor_loss.backward()
self.actor_optimizer.step()
# 清空回合数据
self.states = []
self.actions = []
self.rewards = []
self.next_states = []
self.dones = []
# 训练流程
def train_ac(env_name, episodes):
env = gym.make(env_name)
state_dim = env.observation_space.shape[0]
action_dim = env.action_space.n
agent = ACAgent(state_dim, action_dim)
for episode in range(episodes):
state = env.reset()[0]
episode_reward = 0
done = False
while not done:
# 1. 选择并执行动作
action = agent.choose_action(state)
next_state, reward, terminated, truncated, _ = env.step(action)
done = terminated or truncated
# 2. 存储转移数据
agent.store_transition(state, action, reward, next_state, done)
state = next_state
episode_reward += reward
# 3. 使用完整回合数据更新网络
agent.update_model()
# 记录训练进度
reward_list.append(episode_reward)
if (episode + 1) % 10 == 0:
print(f"Episode: {episode + 1}, Reward: {episode_reward}")
env.close()
if __name__ == "__main__":
env_name = "CartPole-v1"
episodes = 2000
train_ac(env_name, episodes)
np.save(f"result/AC2_rewards.npy", np.array(reward_list))
plt.plot(range(episodes), reward_list)
plt.xlabel('迭代次数')
plt.ylabel('每代的总奖励值')
plt.title('Actor-Critic的训练过程')
plt.grid(True)
plt.show()
绘图代码:
import numpy as np
import matplotlib.pyplot as plt
# 加载数据(注意路径与图中一致)
dqn_rewards = np.load("dqn_rewards.npy")
REFINORCE_rewards = np.load("REINFORCE_rewards.npy")
AC_rewards = np.load("AC2_rewards.npy")
plt.figure(figsize=(12, 6))
# 绘制原始曲线
plt.plot(dqn_rewards, alpha=0.3, color='blue', label='DQN (原始)')
plt.plot(REFINORCE_rewards, alpha=0.3, color='cyan', label='REINFORCE (原始)')
plt.plot(AC_rewards, alpha=0.3, color='cyan', label='AC (原始)')
# 绘制滚动平均曲线(窗口大小=50)
window_size = 50
plt.plot(np.convolve(dqn_rewards, np.ones(window_size)/window_size, mode='valid'),
linewidth=2, color='navy', label='DQN (50轮平均)')
plt.plot(np.convolve(REFINORCE_rewards, np.ones(window_size)/window_size, mode='valid'),
linewidth=2, color='bisque', label='REINFORCE (50轮平均)')
plt.plot(np.convolve(AC_rewards, np.ones(window_size)/window_size, mode='valid'),
linewidth=2, color='magenta', label='AC (50轮平均)')
# 图表标注
plt.xlabel('训练轮次 (Episodes)', fontsize=12, fontfamily='SimHei')
plt.ylabel('奖励值', fontsize=12, fontfamily='SimHei')
plt.title('训练对比 (CartPole-v1)', fontsize=14, fontfamily='SimHei')
plt.legend(loc='upper left', prop={'family': 'SimHei'})
plt.grid(True, alpha=0.3)
# 保存图片(解决原图未保存的问题)
# plt.savefig('comparison.png', dpi=300, bbox_inches='tight')
plt.show()
结果对比图: