本文目录
- 一、项目基本信息
- 二、分析当前项目情况
- 1、使用 webpack-bundle-analyzer 插件
- 2、使用 speed-measure-webpack-plugin 插件
- 三、解决构建问题
- 1、caniuse-lite 提示的问题
- 2、 warning 问题
- 四、打包速度优化
- 1、修改source map
- 2、处理 loader
- 五、webpack性能优化
- 1、使用Tree Shaking
- 2、配置Gzip压缩
- 3、配置devtool
- 4、适用 uglifyjs-webpack-plugin 压缩js
- 5、chunks 分割
一、项目基本信息
本次要进行webpack优化的项目是vue2开发的,基本信息如下:


vue.config.js配置如下:
module.exports = {
productionSourceMap: false,
chainWebpack: config => {
config.plugin('html').tap(args => {
args[0].chunksSortMode = 'none';
return args;
});
},
devServer: {
disableHostCheck: true,
before: function(app) {
app.get('/api/version', function(req, res) {
res.json({
data: 'V1.0.0',
message: '',
status: 0,
});
});
},
proxy: {
'/api': {
target: 'http://localhost:8080/',
changeOrigin: true,
autoRewrite: true,
pathRewrite: {
'^/api/': '/',
},
},
},
},
};
可以发现,这个项目基本没有做任何的优化。
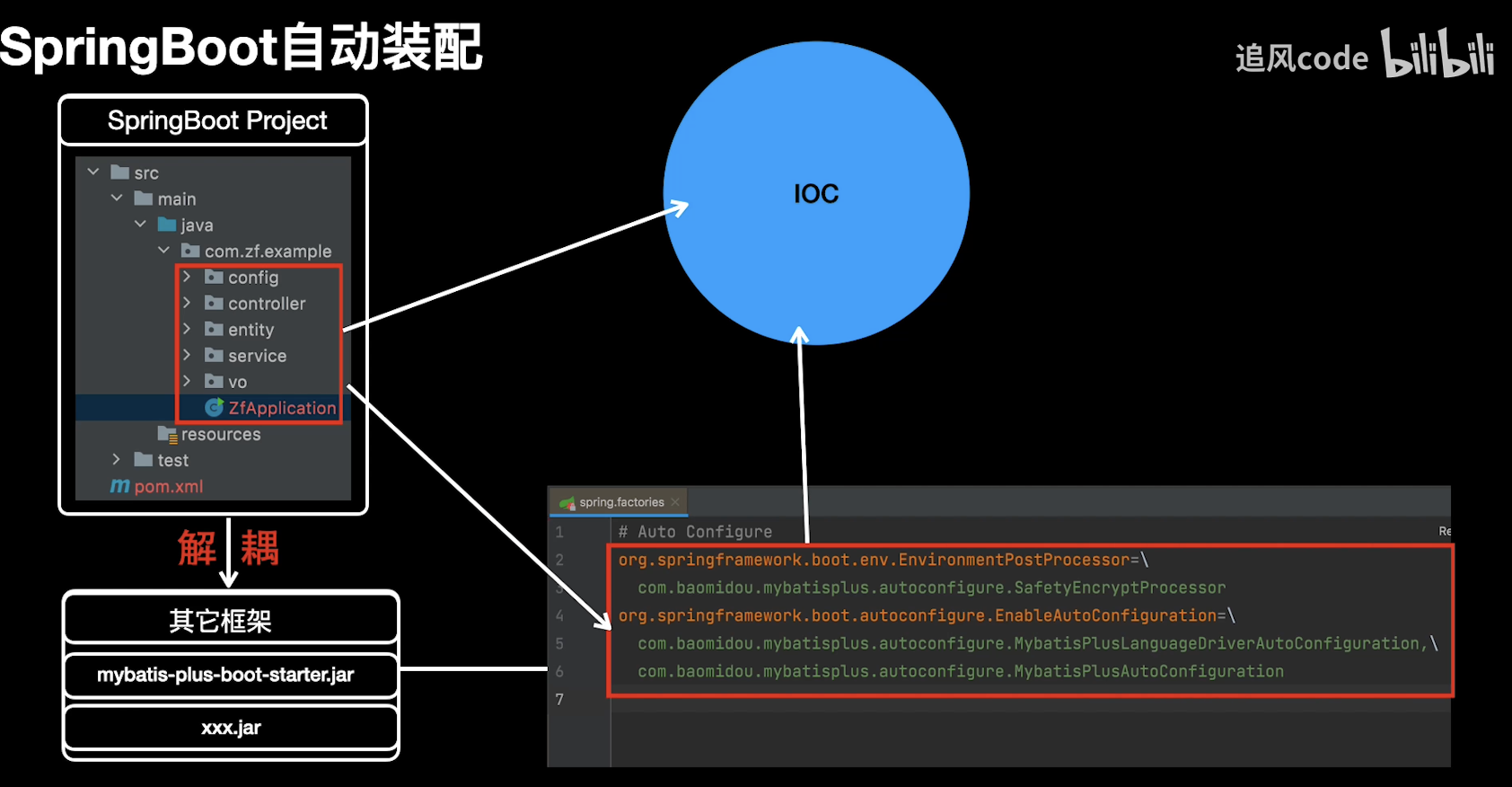
二、分析当前项目情况
1、使用 webpack-bundle-analyzer 插件
该插件主要是分析项目各个模块的大小。
- 安装:
npm i webpack-bundle-analyzer -D - 使用:
// vue.config.js
const BundleAnalyzerPlugin = require('webpack-bundle-analyzer').BundleAnalyzerPlugin;
module.exports = {
productionSourceMap: false,
// webpack相关配置:该对象将会被webpack-merge合并入最终的webpack配置
configureWebpack: config => {
config.plugins.push(new BundleAnalyzerPlugin());
},
}
-
执行:
npm run build --report
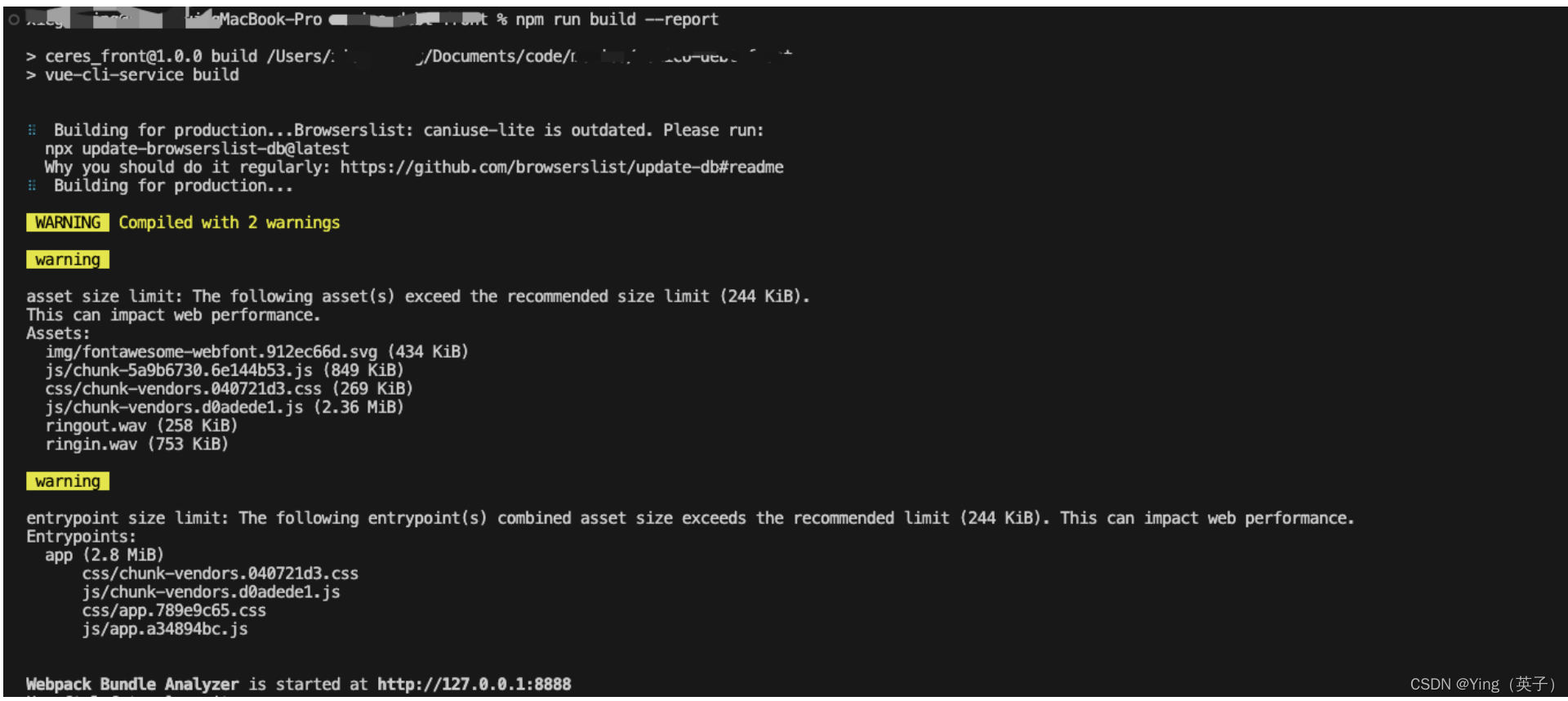

-
浏览器默认打开:http://127.0.0.1:8888/ 得到
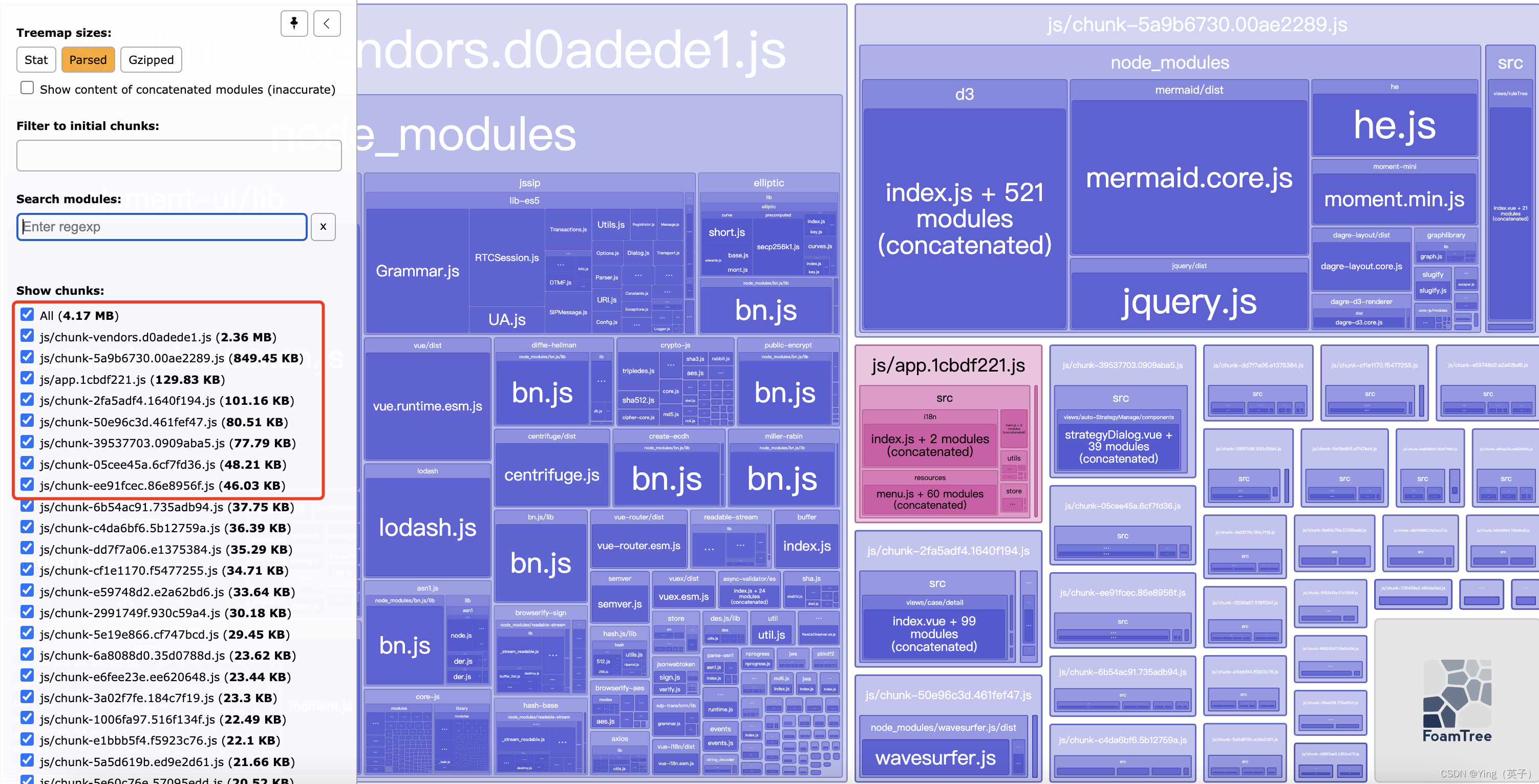
可以看到,不仅打包过程有warning,而且打包后最大的文件达竟然有4.17M! -
new BundleAnalyzerPlugin参数配置说明
new BundleAnalyzerPlugin({
analyzerMode:'server', // 可以是 server、static、json、disabled。在server模式下,分析器将启动HTTP服务器来显示软件包报告。在“静态”模式下,会生成带有报告的单个HTML文件。在disabled模式下,你可以使用这个插件来将generateStatsFile设置为true来生成Webpack Stats JSON文件。
analyzerHost: '127.0.0.1', // 将在“服务器”模式下使用的端口启动HTTP服务器
analyzerPort: 8888, // 端口号
reportFilename: 'report.html', // 路径捆绑,将在static模式下生成的报告文件。相对于捆绑输出目录
defaultSizes: 'parsed', // 默认显示在报告中的模块大小匹配方式。应该是stat,parsed或者gzip中的一个
openAnalyzer: false, // 在默认浏览器中是否自动打开报告,默认 true
generateStatsFile: false, // 如果为true,则Webpack Stats JSON文件将在bundle输出目录中生成
statsFilename: 'stats.json', // 相对于捆绑输出目录
statsOptions: null, //stats.toJson()方法的选项。例如,您可以使用source:false选项排除统计文件中模块的来源。在这里查看更多选项:https://github.com/webpack/webpack/blob/webpack-1/lib/Stats.js#L21
logLevel: 'info', // 日志级别,可以是info, warn, error, silent
excludeAssets:null, // 用于排除分析一些文件
})
2、使用 speed-measure-webpack-plugin 插件
通过这个插件分析 webpack 的总打包耗时以及每个 plugin 和 loader 的打包耗时,从而让我们对打包时间较长的部分进行针对性优化。
- 安装:
npm i speed-measure-webpack-plugin -D - 使用:
const SpeedMeasurePlugin = require('speed-measure-webpack-plugin');
module.exports = {
productionSourceMap: false,
// webpack相关配置:该对象将会被webpack-merge合并入最终的webpack配置
configureWebpack: config => {
config.plugins.push(new BundleAnalyzerPlugin());
config.plugins.push(new SpeedMeasurePlugin());
},
}
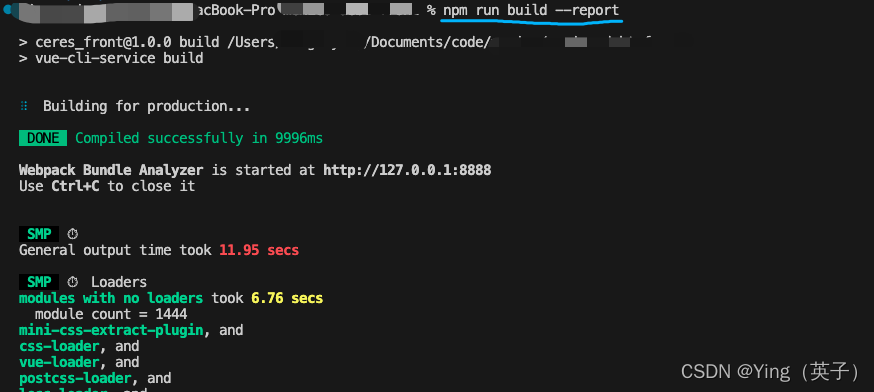
- 重新执行打包命令npm run build --report ,在控制台就能看到如下信息:
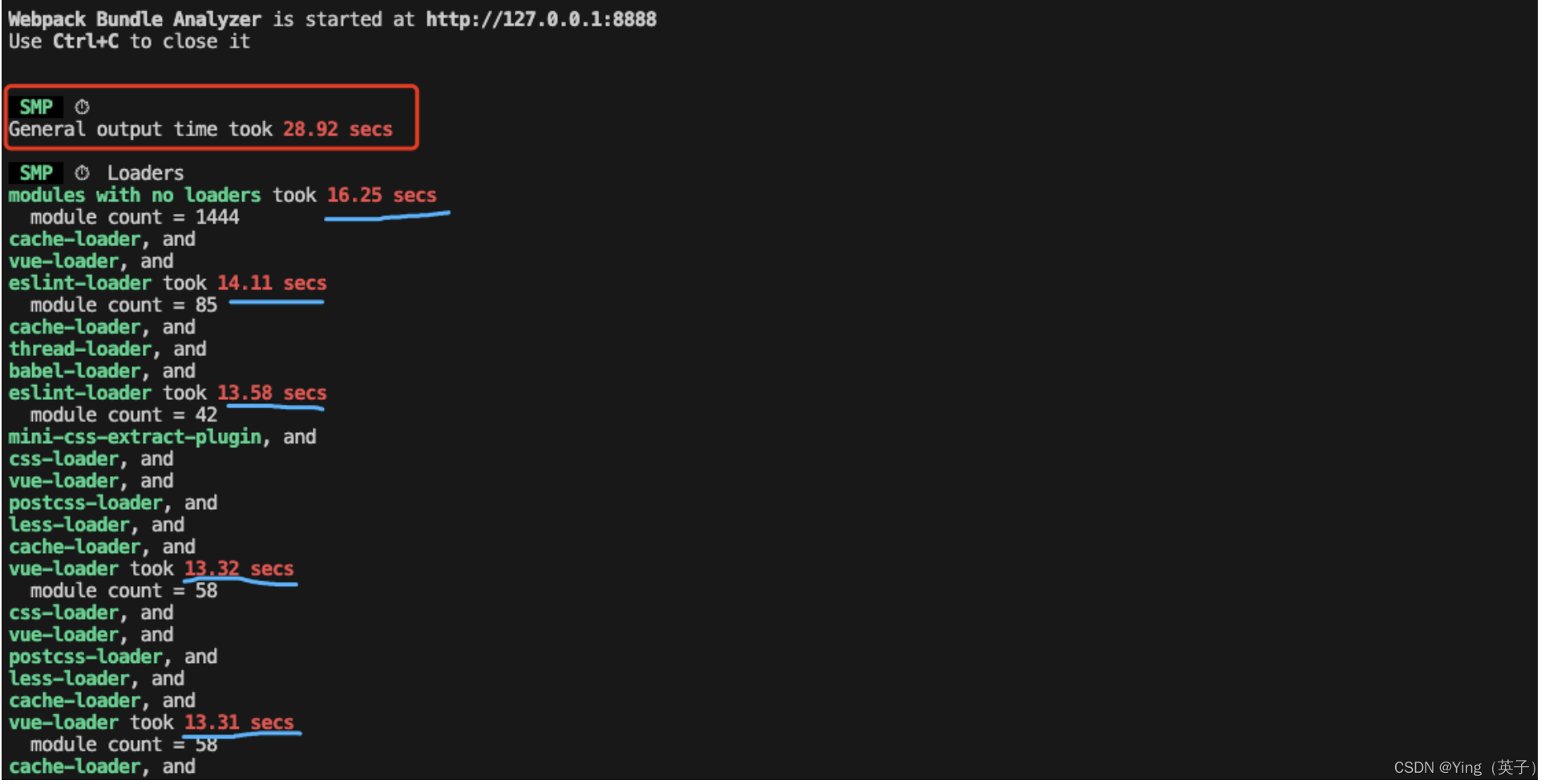 通过smp 日志可以看到,打包整体输出时间竟然需要将近29s!打包速度慢主要集中在
通过smp 日志可以看到,打包整体输出时间竟然需要将近29s!打包速度慢主要集中在eslint-loader、less-loader等一些loader中。
但总的来说,无论是项目打包的文件大小,还是打包时间,都是无法忍受的!
三、解决构建问题
1、caniuse-lite 提示的问题
在进行打包的时候,发现控制台很多提示:Building for production...Browserslist: caniuse-lite is outdated. Please run: npx update-browserslist-db@latest
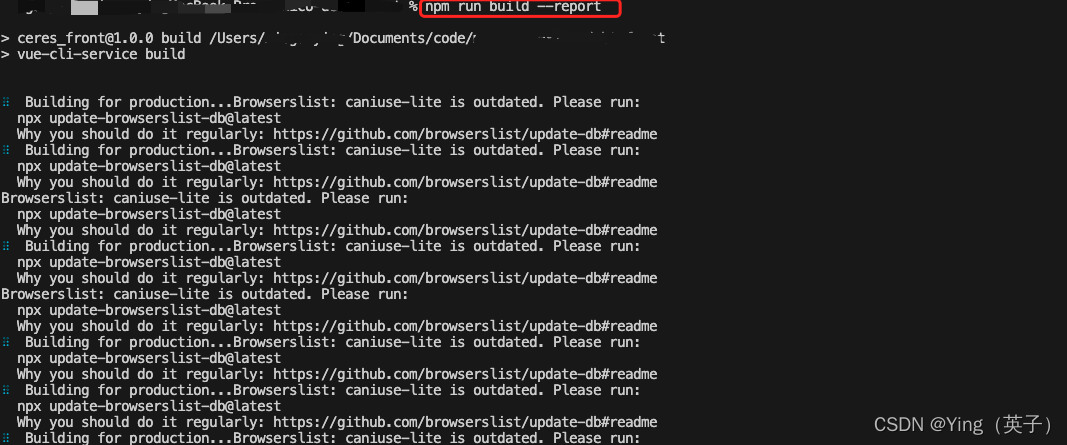
-
办法1:根据日志提示的信息,
caniuse lite过时了,直接按提示执行:npx update-browserslist-db@latest
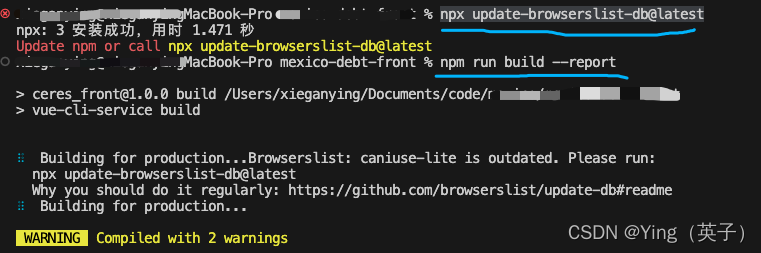
caniuse-lite is outdated仍然还有1个提示,说明其实问题并没有完全解决。 -
方法2:直接删了 node_modules/caniuse-lite 文件夹,然后重新安装:
npm i caniuse-lite -g

额。。。还是不能完全解决。 -
办法3:先删了
node_modules/caniuse-lite和node_modules/browserslist两个文件夹,然后执行:npm i caniuse-lite browserslist -D

然后执行打包命令,发现报错了!
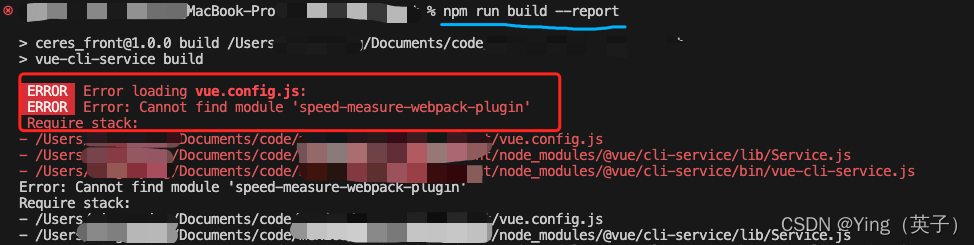
好吧,删除了caniuse-lite和browserslist导致了,之前安装的speed-measure-webpack-plugin插件有问题,原因可能是三者之间存在某种关联关系,反正解决办法就是先删除package.json中的:"speed-measure-webpack-plugin": "^1.5.0",然后重装speed-measure-webpack-plugin。
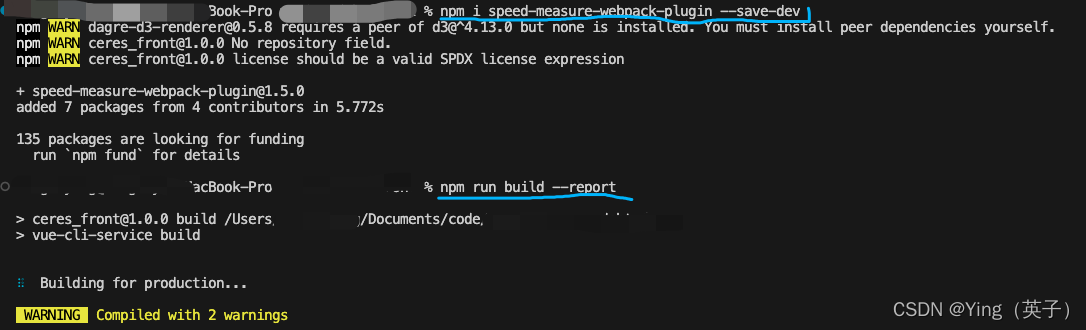
至此,终于把caniuse-lite过期的问题解决了。
2、 warning 问题
打包过程中,还发现有2个warning,必须给它解决了。
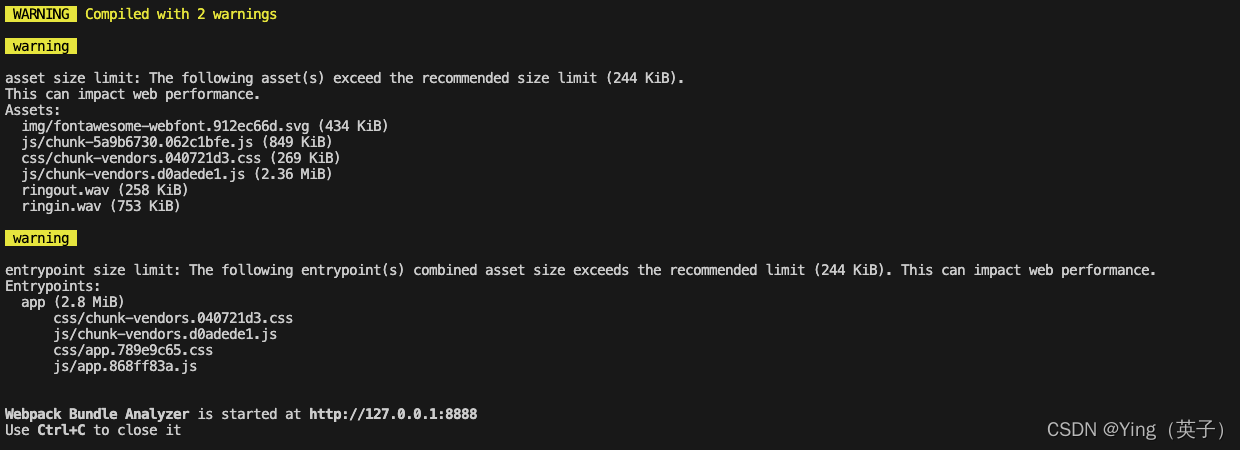
两个warning提示其实都差不多一个意思:就是文件过大的问题。
修改vue.config.js配置:
module.exports = {
productionSourceMap: false,
configureWebpack: config => {
config.plugins.push(new BundleAnalyzerPlugin());
config.plugins.push(new SpeedMeasurePlugin());
// 性能提示配置
config['performance'] = {
hints: false, // 简单粗暴,关闭webpack的性能提示
maxEntrypointSize: 512000, // 入口起点的最大体积,限制500kb
maxAssetSize: 512000, // 生成文件的最大体积
};
},
执行打包命令,然后就不会再有warning提示。
接下来就可以继续进行优化了。
四、打包速度优化
1、修改source map
执行打包命令后,会发现打包后每个js文件都有一个map文件。
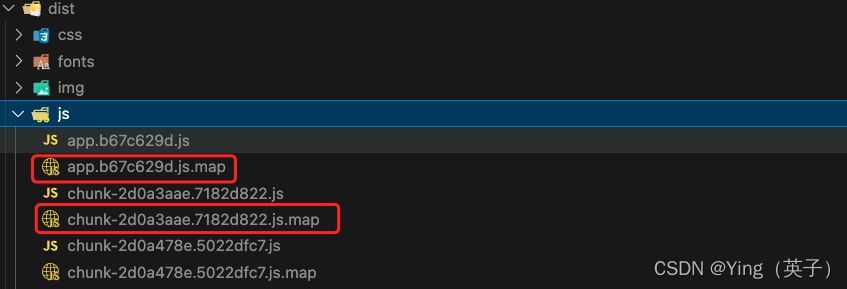
map文件的作用在于:项目打包后,代码都是经过压缩加密的,如果运行时报错,输出的错误信息无法准确得知是哪里的代码报错。有了map就可以像未加密的代码一样,准确的输出是哪一行哪一列有错,也就是说map文件相当于是查看源码的一个东西。
当然,这也会导致构建后的包体积会更大,所以,一般可以甚至,生产环境不用生成source map文件。
只需要vue.config.js里面配置:module.exports = { productionSourceMap: false }
生成map文件的包大小:

没有map文件的包大小:

2、处理 loader
在前面的速度分析中我们已经知道了打包速度主要耗费在 loader 的处理上。所以要想提升速度,就得针对性的解决各个loader。
// vue.config.js
module.exports = {
// 生产环境是否生成 sourceMap 文件
productionSourceMap: false,
configureWebpack: config => {
// 新增配置
config.module.rules.push(
{
test: /\.vue$/,
loader: 'vue-loader',
include: path.resolve('src'),
exclude: /node_modules/,
},
{
test: /\.js$/,
use: ['babel-loader'],
include: path.resolve('src'),
exclude: /node_modules/,
},
{
test: /\.less$/,
use: ['cache-loader'],
include: path.resolve('src'),
exclude: /node_modules/,
}
);
}
运行打包命令,速度喜人!
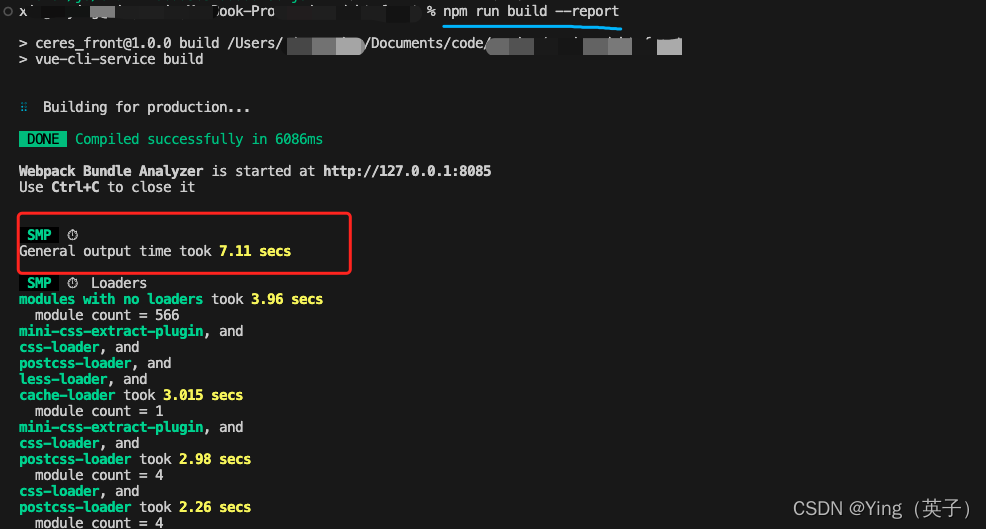
浏览器上,各个模块如下:

至此,其实本文的主要目的,提升webpack打包速度就算达成了,当然webpack还有很多可以优化的手段和措施。
此时完整的vue.config.js如下:
const BundleAnalyzerPlugin = require('webpack-bundle-analyzer').BundleAnalyzerPlugin;
const SpeedMeasurePlugin = require('speed-measure-webpack-plugin');
const path = require('path');
module.exports = {
// 生产环境是否生成 sourceMap 文件
productionSourceMap: false,
configureWebpack: config => {
// 性能配置
config.performance = {
hints: false, // 关闭性能提示
maxEntrypointSize: 512000, // 入口起点的最大体积,限制500kb
maxAssetSize: 512000, // 生成文件的最大体积
};
// 打包文件分析插件
config.plugins.push(
new BundleAnalyzerPlugin({
openAnalyzer: true,
analyzerPort: 8085,
}),
new SpeedMeasurePlugin() // 打包速度分析插件
);
// loader配置
config.module.rules.push(
{
test: /\.vue$/,
loader: 'vue-loader',
include: path.resolve('src'),
exclude: /node_modules/,
},
{
test: /\.js$/,
use: ['babel-loader'],
include: path.resolve('src'),
exclude: /node_modules/,
},
{
test: /\.less$/,
use: ['cache-loader'],
include: path.resolve('src'),
exclude: /node_modules/,
}
);
},
chainWebpack: config => {
config.plugin('html').tap(args => {
args[0].chunksSortMode = 'none';
return args;
});
},
devServer: {},
};
接下来的优化重点阐述方案和实施,数据就不做过多对比了。
五、webpack性能优化
1、使用Tree Shaking
webpack官方说明:https://www.webpackjs.com/guides/tree-shaking/
- 修改
vue.config.js
module.exports = {
// ...
configureWebpack: config => {
// ...
config.optimization = {
usedExports: true, // 设置 tree-shaking
// ...
}
}
}
- 修改
package.json:"sideEffects": true
true 所有文件都不会受到 tree shaking 的影响
false 所有文件都会受到 tree shaking 的影响
[] 数组内的文件不受 tree shaking 的影响,其他受 tree shaking 的影响,例:[“.css", ".vue”]
2、配置Gzip压缩
从 webpack-bundle-analyzer 的分析结果,可以看到如果对打包的文件进行压缩,差异十分巨大,所以首先考虑优化的手段就是文件压缩。
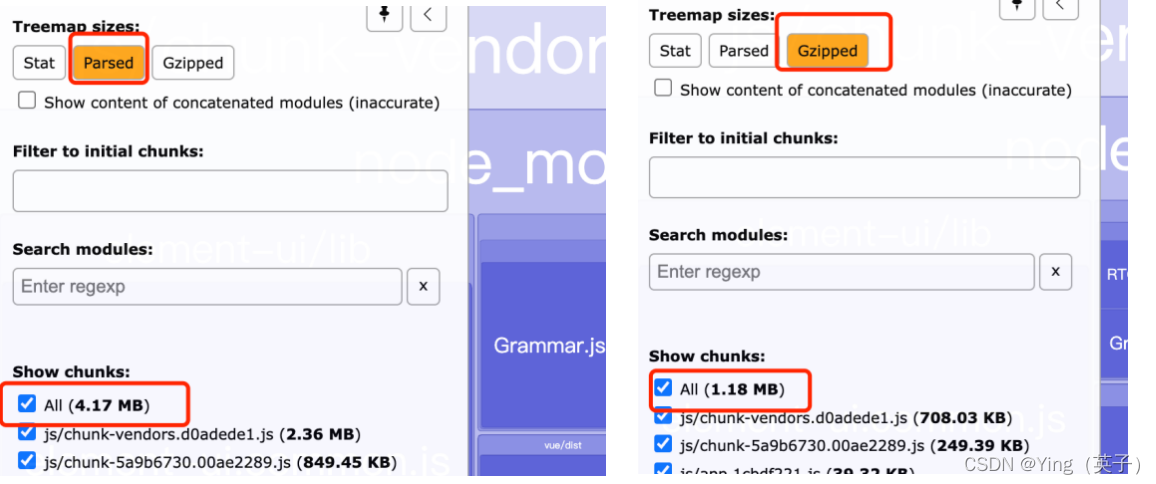
本文中将利用 compression-webpack-plugin 插件来实现Gzip压缩。
安装:npm i compression-webpack-plugin -D
适用:
const CompressionPlugin = require('compression-webpack-plugin');
module.exports = {
// ...
configureWebpack: config => {
// ...
config.plugins.push(new CompressionPlugin()); // 开启gzip压缩
}
}
配置说明:
// 只在生产环境配置Gzip压缩
if (process.env.NODE_ENV === 'production') {
new CompressionPlugin({
filename: '[path].gz[query]', // 使得多个.gz文件合并成一个文件,这种方式压缩后的文件少,建议使用,默认是:[path][base].gz
algorithm: 'gzip', // 默认压缩算法是gzip
test: /\.js$|\.css$|\.html$|\.ttf$|\.eot$|\.woff$/, // 使用正则给匹配到的文件做压缩,这里是给html、css、js以及字体(.ttf和.woff和.eot)做压缩
threshold: 10240, // 以字节为单位压缩超过此大小的文件,使用默认值10240吧
minRatio: 0.8, // 最小压缩比率,官方默认0.8
// 是否删除原有静态资源文件,即只保留压缩后的.gz文件,建议这个置为false,还保留源文件。以防假如出现访问.gz文件访问不到的时候,还可以访问源文件双重保障
deleteOriginalAssets: false
})
}
但是要进行Gzip压缩,同时必须要服务端支持,也就是在服务器上进行配置。,
比如:Nginx服务器可配置大概如下
server {
# ....
gzip on; # 开启gzip压缩
gzip_min_length 4k; # 小于4k的文件不会被压缩,大于4k的文件才会去压缩
gzip_buffers 16 8k; # 处理请求压缩的缓冲区数量和大小,比如8k为单位申请16倍内存空间;使用默认即可,不用修改
gzip_http_version 1.1; # 早期版本http不支持,指定默认兼容,不用修改
gzip_comp_level 2; # gzip 压缩级别,1-9,理论上数字越大压缩的越好,也越占用CPU时间。实际上超过2的再压缩,只能压缩一点点了,但是cpu确是有点浪费,因为2就够用了
# 压缩的文件类型MIME类型
gzip_types text/plain application/x-javascript application/javascript text/javascript text/css application/xml application/x-httpd-php image/jpeg image/gif image/png application/vnd.ms-fontobject font/x-woff font/ttf;
gzip_vary on; # 是否在http header中添加Vary: Accept-Encoding,一般情况下建议开启
}
参数详细说明:
gzip:是否开启gzip模块。gzip_disable:指定哪些不需要gzip压缩的浏览器(将和User-Agents进行匹配),(IE5.5和IE6 SP1使用msie6参数来禁止gzip压缩)。gzip_vary:增加响应头“Vary: Accept-Encoding”。gzip_proxied:Nginx做为反向代理的时候启用,off:关闭所有的代理结果数据压缩
expired:如果header中包含“Expires”头信息,启用压缩·
no-cache:如果header中包含“Cache-Control:no-cache”头信息,启用压缩
no-store:如果header中包含“Cache-Control:no-store”头信息,启用压缩
private:如果header中包含“Cache-Control:private”头信息,启用压缩
no_last_modified:如果header中包含“Last_Modified”头信息,启用压缩
no_etag:如果header中包含“ETag”头信息,启用压缩
auth:如果header中包含“Authorization”头信息,启用压缩
any:无条件压缩所有结果数据gzip_comp_level:设置gzip压缩等级,范围是1-9,等级越低,压缩速度越快,文件压缩比越小,反之速度越慢文件压缩比越大。gzip_buffers:设置用于处理请求压缩的缓冲区数量和大小。比如32 4K表示按照内存页(one memory page)大小以4K为单位(即一个系统中内存页为4K),申请32倍的内存空间。建议此项不设置,使用默认值。gzip_http_version:用于识别http协议的版本,早期的浏览器不支持gzip压缩,用户会看到乱码,所以为了支持前期版本加了此选项。默认在http/1.0的协议下不开启gzip压缩。gzip_types:设置需要压缩的MIME类型,如果不在设置类型范围内的请求不进行压缩。
由于本次只是前端优化,暂时没有服务端支持,所以Gzip压缩效果暂时没办法测试。
3、配置devtool
在上文其实介绍过source map了,但是只是建议对生产环境不需要map文件,实际上也可以在生产环境生成map文件,那么就可以参考以下配置和说明。
configureWebpack: config => {
// ...
if (process.env.NODE_ENV === 'production') {
// 生产环境
config['devtool'] = 'source-map'; // 整个source map作为一个单独的文件生成。为bundle添加了一个引用注释,以便开发工具知道在哪里可以找到它。
} else {
// 非生产环境
config['devtool'] = 'eval';
}
}
配置说明:
(开发环境的配置)
eval:每个模块都使用eval()执行,并且都有//@ sourceURL。此选项会非常快地构建。主要缺点是,由于会映射到转换后的代码,而不是映射到原始代码(没有从 loader 中获取 source map),所以不能正确的显示行数。eval-source-map:每个模块使用eval()执行,并且 source map 转换为 DataUrl 后添加到eval()中。初始化 source map 时比较慢,但是会在重新构建时提供比较快的速度,并且生成实际的文件。行数能够正确映射,因为会映射到原始代码中。它会生成用于开发环境的最佳品质的 source map。cheap-eval-source-map:类似eval-source-map,每个模块使用eval()执行。这是 “cheap(低开销)” 的 source map,因为它没有生成列映射(column mapping),只是映射行数。它会忽略源自 loader 的 source map,并且仅显示转译后的代码,就像evaldevtool。cheap-module-eval-source-map:类似cheap-eval-source-map,并且,在这种情况下,源自 loader 的 source map 会得到更好的处理结果。然而,loader source map 会被简化为每行一个映射(mapping)。
(生产环境的配置)
none:(省略devtool选项)不生成 source map。这是一个不错的选择。source-map:整个 source map 作为一个单独的文件生成。它为 bundle 添加了一个引用注释,以便开发工具知道在哪里可以找到它。hidden-source-map:与source-map相同,但不会为 bundle 添加引用注释。如果你只想 source map 映射那些源自错误报告的错误堆栈跟踪信息,但不想为浏览器开发工具暴露你的 source map,这个选项会很有用。nosources-source-map:创建的 source map 不包含sourcesContent(源代码内容)。它可以用来映射客户端上的堆栈跟踪,而无须暴露所有的源代码。你可以将 source map 文件部署到 web 服务器。
更多可查看官方:https://webpack.js.org/configuration/devtool/
4、适用 uglifyjs-webpack-plugin 压缩js
安装:npm install uglifyjs-webpack-plugin --save-dev
使用:
const UglifyJsPlugin = require('uglifyjs-webpack-plugin');
module.exports = {
config.plugins.push(
new UglifyJsPlugin({
uglifyOptions: {
compress: {
drop_debugger: true,
drop_console: true, // 生产环境自动删除console
},
warnings: false,
},
sourceMap: false,
parallel: true, // 使用多进程并行运行来提高构建速度。默认并发运行数:os.cpus().length - 1。
})
)
}
官方更多字段说明:https://www.npmjs.com/package/uglifyjs-webpack-plugin?activeTab=readme
5、chunks 分割
module.exports = {
configureWebpack: config => {
config.optimization = {
// 设置 tree-shaking
usedExports: true,
// 抽离公共的代码
splitChunks: {
chunks: 'all',
cacheGroups: {
common: {
name: 'common', // 指定chunks名称
minChunks: 1,
test: /[\\/]node_modules[\\/]vue[\\/]|[\\/]node_modules[\\/]vue-router[\\/]|[\\/]node_modules[\\/]vuex[\\/]|[\\/]node_modules[\\/]axios[\\/]/,
chunks: 'initial', // 仅限于最初依赖的第三方
priority: -1, // 优先级:数字越大优先级越高,默认值为0,自定义的一般是负数形式,决定cacheGroups中相同条件下每个组执行的优先顺序。
},
elementUI: {
name: 'elementUI',
minChunks: 1,
test: /[\\/]node_modules[\\/]_?element-ui[\\/]/,
chunks: 'initial',
priority: -2,
reuseExistingChunk: true,
enforce: true,
},
},
},
};
}
}
splitChunks字段说明:
chunks: "async", // 需要进行分割的chunks,可选值有:async,initial和all
minSize: 30000, // 新分离出的chunk必须大于等于minSize,默认为30000,约30kb。
minChunks: 1, // 一个模块至少应被minChunks个chunk所包含才能分割。默认为1。
maxAsyncRequests: 5, // 按需加载文件时,并行请求的最大数目。默认为5。
maxInitialRequests: 3, // 加载入口文件时,并行请求的最大数目。默认为3。
automaticNameDelimiter: '~', // 拆分出的chunk的名称连接符。默认为~。如chunk~vendors.js
name: true, // 设置chunk的文件名。默认为true。当为true时,splitChunks基于chunk和cacheGroups的key自动命名。
cacheGroups: {
// cacheGroups 下可以可以配置多个组,每个组根据test设置条件,符合test条件的模块,就分配到该组。
// 模块可以被多个组引用,但最终会根据priority来决定打包到哪个组中。
// 默认将所有来自 node_modules目录的模块打包至vendors组,将两个以上的chunk所共享的模块打包至default组。
vendors: {
test: /[\\/]node_modules[\\/]/,
priority: -10
},
default: {
minChunks: 2,
priority: -20,
reuseExistingChunk: true
}
}
webpack优化的措施还有使用CDN、使用缓存、设置预解析、优化图片/字体等等。
没有绝对的优化措施,只有适合的方案, 性能优化之路漫漫~