一、本文介绍
本文给大家带来的改进机制是由YOLO-Face提出能够改善物体遮挡检测的注意力机制SEAM,SEAM(Spatially Enhanced Attention Module)注意力网络模块旨在补偿被遮挡面部的响应损失,通过增强未遮挡面部的响应来实现这一目标,其希望通过学习遮挡面和未遮挡面之间的关系来改善遮挡情况下的损失从而达到改善物体遮挡检测的效果,本文将通过介绍其主要原理后,提供该机制的代码和修改教程,并附上运行的yaml文件和运行代码,小白也可轻松上手。。
欢迎大家订阅我的专栏一起学习YOLO!
专栏回顾:YOLOv5改进专栏——持续复现各种顶会内容——内含100+创新
目录
一、本文介绍
二、原理介绍
2.1 遮挡改进
2.2 SEAM模块
2.3 排斥损失
三、核心代码
四、添加教程
4.1 修改一
4.2 修改二
4.3 修改三
4.4 修改四
五、SEAM的yaml文件和运行记录
5.1 SEAM的yaml文件
5.2 MultiSEAM的yaml文件
5.3 训练过程截图
五、本文总结
二、原理介绍
2.1 遮挡改进
本文重点介绍遮挡改进,其主要体现在两个方面:注意力网络模块(SEAM)和排斥损失(Repulsion Loss)。
1. SEAM模块:SEAM(Spatially Enhanced Attention Module)注意力网络模块旨在补偿被遮挡面部的响应损失,通过增强未遮挡面部的响应来实现这一目标。SEAM模块通过深度可分离卷积和残差连接的组合来实现,其中深度可分离卷积按通道进行操作,虽然可以学习不同通道的重要性并减少参数量,但忽略了通道间的信息关系。为了弥补这一损失,不同深度卷积的输出通过点对点(1x1)卷积组合。然后使用两层全连接网络融合每个通道的信息,以增强所有通道之间的联系。这种模型希望通过学习遮挡面和未遮挡面之间的关系,来弥补遮挡情况下的损失。
2. 排斥损失(Repulsion Loss):一种设计来处理面部遮挡问题的损失函数。具体来说,排斥损失被分为两部分:RepGT和RepBox。RepGT的功能是使当前的边界框尽可能远离周围的真实边界框,而RepBox的目的是使预测框尽可能远离周围的预测框,从而减少它们之间的IOU,以避免某个预测框被NMS抑制,从而属于两个面部。
2.2 SEAM模块
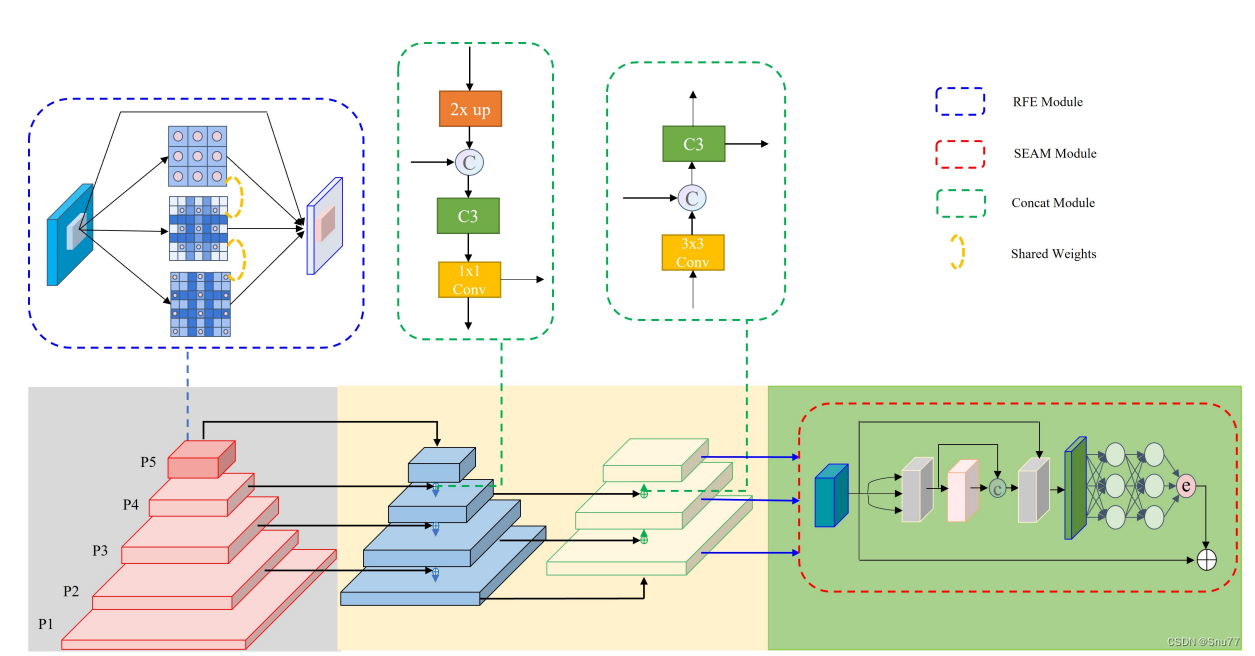
下图展示了SEAM(Separated and Enhancement Attention Module)的架构以及CSMM(Channel and Spatial Mixing Module)的结构。
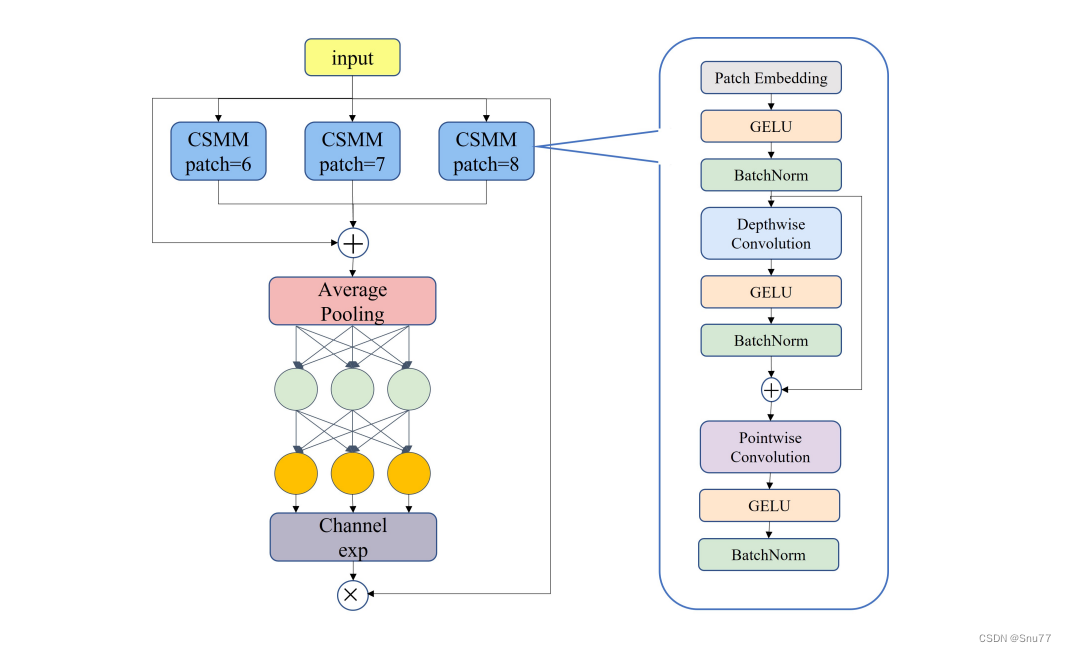
左侧是SEAM的整体架构,包括三个不同尺寸(patch-6、patch-7、patch-8)的CSMM模块。这些模块的输出进行平均池化,然后通过通道扩展(Channel exp)操作,最后相乘以提供增强的特征表示。右侧是CSMM模块的详细结构,它通过不同尺寸的patch来利用多尺度特征,并使用深度可分离卷积来学习空间维度和通道之间的相关性。模块包括了以下元素:
(a)Patch Embedding:对输入的patch进行嵌入。
(b)GELU:Gaussian Error Linear Unit,一种激活函数。
(c)BatchNorm:批量归一化,用于加速训练过程并提高性能。
(d)Depthwise Convolution:深度可分离卷积,对每个输入通道分别进行卷积操作。
(f)Pointwise Convolution:逐点卷积,其使用1x1的卷积核来融合深度可分离卷积的特征。
这种模块设计旨在通过对空间维度和通道的细致处理,从而增强网络对遮挡面部特征的注意力和捕捉能力。通过综合利用多尺度特征和深度可分离卷积,CSMM在保持计算效率的同时,提高了特征提取的精确度。这对于面部检测尤其重要,因为面部特征的大小、形状和遮挡程度可以在不同情况下大相径庭。通过SEAM和CSMM,YOLO-FaceV2提高了模型对复杂场景中各种面部特征的识别能力。
2.3 排斥损失
排斥损失(Repulsion Loss)是一种用于处理面部检测中遮挡问题的损失函数。在面部检测中,类内遮挡可能会导致一个面部包含另一个面部的特征,从而增加错误检测率。排斥损失能够有效地通过排斥效应来缓解这一问题。排斥损失被分为两个部分:RepGT和RepBox。
(a)RepGT损失:其功能是使当前边界框尽可能远离周围的真实边界框。这里的“周围真实边界框”指的是与除了要预测的边界框外的面部标签具有最大IoU的那个边界框。RepGT损失的计算方法如下:
其中,代表面部预测框,
是周围具有最大IoU的真实边界框。这里的IoG(Intersection over Ground truth)定义为
,且其值范围在0到1之间。
是一个连续可导的对数函数,
是一个在[0,1)范围内的平滑参数,用于调整排斥损失对异常值的敏感度。
(b)RepBox损失:其目的是使预测框尽可能远离周围的预测框,从而减少它们之间的IOU,以避免一个预测框因NMS(非最大抑制)而被压制,并归属于两个面部。预测框被分成多个组,不同组之间的预测框对应不同的面部标签。对于不同组之间的预测框和
,希望它们之间的重叠面积尽可能小。RepBox也使用SmoothLn作为优化函数。
排斥损失通过使边界框之间保持距离,减少预测框之间的重叠,从而提高面部检测在遮挡情况下的准确性。
三、核心代码
代码的使用方式看章节四!
import torch
import torch.nn as nn
__all__ = ['SEAM', 'MultiSEAM']
class Residual(nn.Module):
def __init__(self, fn):
super(Residual, self).__init__()
self.fn = fn
def forward(self, x):
return self.fn(x) + x
class SEAM(nn.Module):
def __init__(self, c1, c2, n, reduction=16):
super(SEAM, self).__init__()
if c1 != c2:
c2 = c1
self.DCovN = nn.Sequential(
# nn.Conv2d(c1, c2, kernel_size=3, stride=1, padding=1, groups=c1),
# nn.GELU(),
# nn.BatchNorm2d(c2),
*[nn.Sequential(
Residual(nn.Sequential(
nn.Conv2d(in_channels=c2, out_channels=c2, kernel_size=3, stride=1, padding=1, groups=c2),
nn.GELU(),
nn.BatchNorm2d(c2)
)),
nn.Conv2d(in_channels=c2, out_channels=c2, kernel_size=1, stride=1, padding=0, groups=1),
nn.GELU(),
nn.BatchNorm2d(c2)
) for i in range(n)]
)
self.avg_pool = torch.nn.AdaptiveAvgPool2d(1)
self.fc = nn.Sequential(
nn.Linear(c2, c2 // reduction, bias=False),
nn.ReLU(inplace=True),
nn.Linear(c2 // reduction, c2, bias=False),
nn.Sigmoid()
)
self._initialize_weights()
# self.initialize_layer(self.avg_pool)
self.initialize_layer(self.fc)
def forward(self, x):
b, c, _, _ = x.size()
y = self.DCovN(x)
y = self.avg_pool(y).view(b, c)
y = self.fc(y).view(b, c, 1, 1)
y = torch.exp(y)
return x * y.expand_as(x)
def _initialize_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.xavier_uniform_(m.weight, gain=1)
elif isinstance(m, nn.BatchNorm2d):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
def initialize_layer(self, layer):
if isinstance(layer, (nn.Conv2d, nn.Linear)):
torch.nn.init.normal_(layer.weight, mean=0., std=0.001)
if layer.bias is not None:
torch.nn.init.constant_(layer.bias, 0)
def DcovN(c1, c2, depth, kernel_size=3, patch_size=3):
dcovn = nn.Sequential(
nn.Conv2d(c1, c2, kernel_size=patch_size, stride=patch_size),
nn.SiLU(),
nn.BatchNorm2d(c2),
*[nn.Sequential(
Residual(nn.Sequential(
nn.Conv2d(in_channels=c2, out_channels=c2, kernel_size=kernel_size, stride=1, padding=1, groups=c2),
nn.SiLU(),
nn.BatchNorm2d(c2)
)),
nn.Conv2d(in_channels=c2, out_channels=c2, kernel_size=1, stride=1, padding=0, groups=1),
nn.SiLU(),
nn.BatchNorm2d(c2)
) for i in range(depth)]
)
return dcovn
class MultiSEAM(nn.Module):
def __init__(self, c1, c2, depth, kernel_size=3, patch_size=[3, 5, 7], reduction=16):
super(MultiSEAM, self).__init__()
if c1 != c2:
c2 = c1
self.DCovN0 = DcovN(c1, c2, depth, kernel_size=kernel_size, patch_size=patch_size[0])
self.DCovN1 = DcovN(c1, c2, depth, kernel_size=kernel_size, patch_size=patch_size[1])
self.DCovN2 = DcovN(c1, c2, depth, kernel_size=kernel_size, patch_size=patch_size[2])
self.avg_pool = torch.nn.AdaptiveAvgPool2d(1)
self.fc = nn.Sequential(
nn.Linear(c2, c2 // reduction, bias=False),
nn.ReLU(inplace=True),
nn.Linear(c2 // reduction, c2, bias=False),
nn.Sigmoid()
)
def forward(self, x):
b, c, _, _ = x.size()
y0 = self.DCovN0(x)
y1 = self.DCovN1(x)
y2 = self.DCovN2(x)
y0 = self.avg_pool(y0).view(b, c)
y1 = self.avg_pool(y1).view(b, c)
y2 = self.avg_pool(y2).view(b, c)
y4 = self.avg_pool(x).view(b, c)
y = (y0 + y1 + y2 + y4) / 4
y = self.fc(y).view(b, c, 1, 1)
y = torch.exp(y)
return x * y.expand_as(x)四、添加教程
4.1 修改一
第一还是建立文件,我们找到如下yolov5-master/models文件夹下建立一个目录名字呢就是'modules'文件夹(用群内的文件的话已经有了无需新建)!然后在其内部建立一个新的py文件将核心代码复制粘贴进去即可。
4.2 修改二
第二步我们在该目录下创建一个新的py文件名字为'__init__.py'(用群内的文件的话已经有了无需新建),然后在其内部导入我们的检测头如下图所示。
4.3 修改三
第三步我门中到如下文件'yolov5-master/models/yolo.py'进行导入和注册我们的模块(用群内的文件的话已经有了无需重新导入直接开始第四步即可)!
从今天开始以后的教程就都统一成这个样子了,因为我默认大家用了我群内的文件来进行修改!!

4.4 修改四
按照我的添加在parse_model里添加即可。
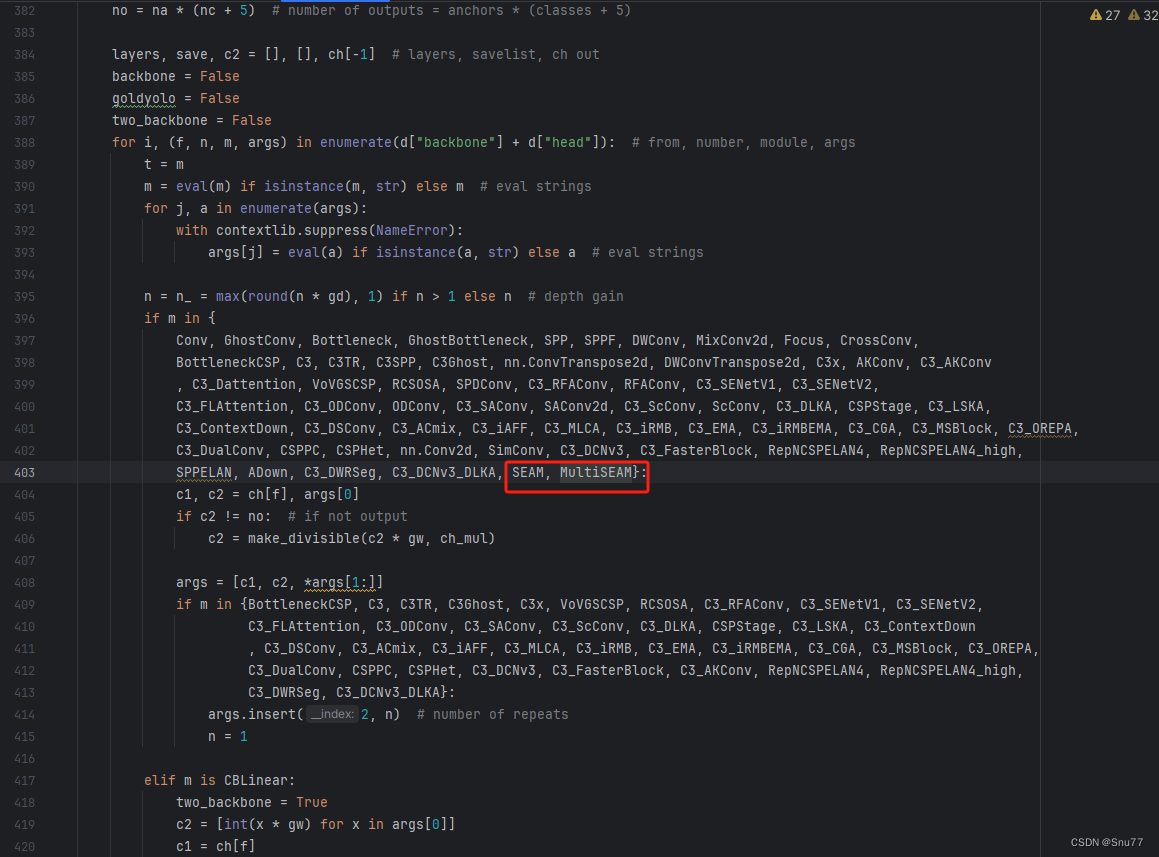
到此就修改完成了,大家可以复制下面的yaml文件运行。
五、SEAM的yaml文件和运行记录
5.1 SEAM的yaml文件
# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
# Parameters
nc: 80 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.25 # layer channel multiple
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
[
[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3, [1024]],
[-1, 1, SPPF, [1024, 5]], # 9
]
# YOLOv5 v6.0 head
head: [
[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, "nearest"]],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, "nearest"]],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 20 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 23 (P5/32-large)
[-1, 1, SEAM, [1024, 1]],
[[17, 20, 24], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
5.2 MultiSEAM的yaml文件
# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
# Parameters
nc: 80 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.25 # layer channel multiple
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
[
[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3, [1024]],
[-1, 1, SPPF, [1024, 5]], # 9
]
# YOLOv5 v6.0 head
head: [
[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, "nearest"]],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, "nearest"]],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 17 (P3/8-small)
[-1, 1, MultiSEAM, [256, 1]],
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 21 (P4/16-medium)
[-1, 1, MultiSEAM, [512, 1]], # 22
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 25 (P5/32-large)
[-1, 1, MultiSEAM, [1024, 1]], # 26
[[18, 22, 26], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
5.3 训练过程截图
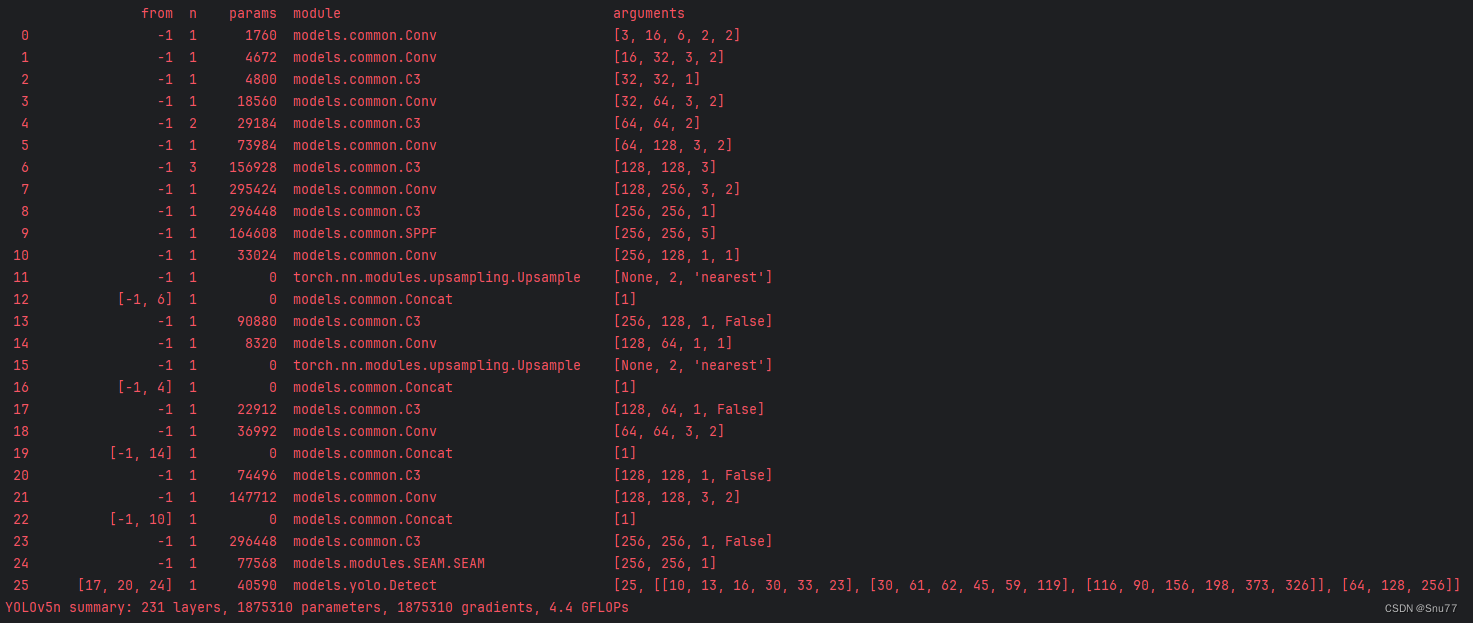
五、本文总结
到此本文的正式分享内容就结束了,在这里给大家推荐我的YOLOv8改进有效涨点专栏,本专栏目前为新开的平均质量分98分,后期我会根据各种最新的前沿顶会进行论文复现,也会对一些老的改进机制进行补充,如果大家觉得本文帮助到你了,订阅本专栏,关注后续更多的更新~
专栏回顾:YOLOv5改进专栏——持续复现各种顶会内容——内含100+创新