文章目录
- Redis 核心原理总览(全局篇)
- 前言
- 一、持久化
- 1、RDB
- 2、AOF
- 3、AOF 重写
- 4、混合持久化
- 5、对比
- 二、副本
- 1、同步模式
- 2、部分重同步
- 三、哨兵
- 1、核心能力
- 2、节点通信
- 总结
Redis 核心原理总览(全局篇)
正文开始之前,我们先思考下「如何造一个缓存组件?」
注:该片段是 Redis 原理知识地图,请仔细阅读!(基于redis6.2)
1)最小可用版:
- 要快:缓存最核心的目的是支持快速访问,硬件层面一般选择「内存」
- 远程访问:作为缓存组件,要支持单独部署,可以利用现有开源网络库,也可以自己实现。
大部分语言都提供了内存操作,条件 1 很容易满足,条件 2 要支持远程访问,就要和 TCP 连接打交道,我们可以利用开源的网络库,比如 C 版的 libc 等。
原理篇第一部分:将围绕一条请求探索 redis 高性能的核心原理。
2)进阶版:
第一步我们已经有了缓存组件最基本的雏形,并且已经达到了高性能的处理能力,这个时候我们可能有更多的诉求:
- 稳定:即 尽可能不丢数据、无故障或故障后快速恢复、自动处理故障的能力
- 可扩展:单机容量或者 QPS 达到上限,支持水平扩展能力。
原理篇第二部分:将围绕 redis 架构演进进行剖析。
全局知识地图:

前言
本文围绕「架构主线」来透视 Redis「高可靠」的核心原理,在正文开始之前,我们先思考几个问题:
- Redis 数据丢失风险?
- 持久化机制会拖慢 Redis 吗?
- fork 子进程是否会阻塞主线程?不用 fork 操作行不行?
- 有了持久化还需要副本机制?
- 能不能自己写个 HA 来代替 Redis 哨兵?
如果你对以上问题了然于胸,这篇文章读起来很容易,权当帮你串联、回顾知识点,如果不是很清楚也没关系,且听我细细道来!
一、持久化
持久化是什么?就 redis 而言,本质就是将内存中不稳定的数据,通过一些刷盘策略写入磁盘,从而达到断电等故障能恢复数据的效果。
如果让你来实现持久化,你会如何考虑?
首先,我们可以「定期全量备份」的方案,5分钟、10分钟一个备份周期,这种方式的好处是,处理起来足够简单,但由于是全量备份,每次消耗不小,因此需要「一定间隔」周期,但丢失数据风险就大了。
我们还可以考虑像 MySQL 的 binlog 方式,记录「明细」,故障时直接进行重放即可,这种方式的好处是数据丢失范围进一步减小,但故障恢复时需要更多的时间,而且数据文件占用空间也更大。
能不能结合两种优点?也是可以的,这就是「混合模式」
1、RDB
RDB 全称 redis database,是以时间为轴线的全量内存快照,存在磁盘上。快照,就是那个时间点内存数据库的全景图,就像拍照一样,把那个瞬间的所有状态“咔”的一声记录下来。
我们来看看 RDB 生成过程:

redis 提供了两种方式,一种是 save,另一种是 bgsave。两者底层处理原理都一样,最大的区别点在于:
- SAVE 由主线程执行,会阻塞客户端命令
- BGSAVE 由 fork 的子进程处理,不会阻塞执行。
redis 提供了一些契机,达到这些条件就可以触发执行 RDB 快照生成,可以在 redis.config 中配置:
save 900 1
save 300 10
save 60 10000
只要满足以下三个条件中的任意一个,BGSAVE 命令就会被执行:
- 服务器在900秒之内,对数据库进行了至少1次修改。
- 服务器在300秒之内,对数据库进行了至少10次修改。
- 服务器在60秒之内,对数据库进行了至少10000次修改。
注:save 操作由主线程阻塞执行,而 bgsave 则由子进程来完成(不过复制内存页表项的时候仍然会阻塞主线程)。
2、AOF
全称 Append Only File,像记录日志一样,记录命令明细。
我们来看看 AOF 写入文件的过程:

首先:
-
写入:指通过 write 系统调用,将数据从 aof_buf 写入 内核缓冲区。 -
落盘(同步):指的是将数据从内核缓冲区同步至磁盘中。因为,由于操作系统自身的优化策略,我们通过 write 写入的数据,都是直接进入内核缓冲区,然后会根据内核将数据同步至磁盘。
aof_buf 缓冲区:
redis 服务端提供的缓冲区,请求命令会写入 aof_buf 缓冲区,然后由 aof_buf 缓冲区写入内核缓冲区或者同步至磁盘。
落盘时机:
在主事件循环,通过 beforeSleep 方法触发 flushAppendOnlyFile 调用,这便是入口。那,一条命令,经过哪些过程最终追加到 AOF 文件呢?
- redis 接收请求命令 cmd,并执行。
- cmd 执行成功后,通过 feedAppendOnlyFile 方法将命令写入 aof_buf 缓冲区。
- 下一轮主循环中,通过 flushAppendOnlyFile 尝试写入或者同步。
3 种刷盘策略:
- no:即 redis 不做任何操作,由内核自行刷盘,Linux 默认 30s 刷一次,效率最高,安全性最低
- everysec:redis 控制,每秒刷盘一次
- always:每一轮命令执行完之后,立即刷盘,安全性最高,效率最低
注:刷盘策略是指将「内核缓冲区」的数据,通过 fsync 系统调用写入磁盘
3、AOF 重写
上文提到,AOF 实实在在的记录了每一条命令,尤其是出现大量重复 key 的操作,会使得 AOF 看起来冗余且臃肿。
AOF 重写就相当于对 AOF 文件进行压缩,同一个 key 只保留最新的操作记录。
我们来看看 AOF 重写执行过程:

1)触发重写条件(自动 or 手动)
2)redis 调用 aof.c#rewriteAppendOnlyFileBackground 方法,并 fork 子进程进行处理
- 2a)子进程重写 AOF 到临时文件
- 2b)父进程继续接收新命令并累加到 server.aof_rewrite_buf 缓冲区
3)直到 2a 完成后
4)父进程尝试将 server.aof_rewrite_buf 数据写入临时文件,并用临时文件替换原 AOF 文件。
重写时机?
redis 提供了灵活的重写机制,可以自动触发,也可以手动触发。
首先,需要确定是否开启了 AOF 策略,即:
appendonly yes
你可以在命令行输入 BGREWRITEAOF 手动触发重写:
127.0.0.1:6379> BGREWRITEAOF
Background append only file rewriting started
另外,redis 也提供了自动触发重写条件:
auto-aof-rewrite-percentage 100
auto-aof-rewrite-min-size 64mb
每次重写之后都会记录文件大小,作为下一次重写的触发条件:当前文件大小超过上次重写的百分比后,触发重写操作。
同时,为避免 AOF 文件过小而触发重写操作,提供了 auto-aof-rewrite-min-size 参数控制重写条件的下限。
注:AOF 重写并不需要从原 AOF 文件中进行压缩,而是直接扫描整个库,把每一个 key / value 转变成写命令,然后追加至临时文件,待重写操作完成后,将临时文件原子性重命名即可。
4、混合持久化
前面我们提到,RDB 记录快照,数据文件相对小,但丢失数据风险较大,AOF 记录明细,数据丢失风险小,但数据文件相对较大。
两者都不完美,能不能只取它们的优点?确实有,这就是「混合持久化」。

redis 4.0 推出了 RDB-AOF 这种混合模式,可以通过下面配置开启:
appendonly yes
aof-use-rdb-preamble yes
可以看到,使用混合模式的前提是,需要先开启 AOF,而 aof-use-rdb-preamble 参数则控制是否使用混合模式。
使用这种模式,当数据重写后,AOF 文件前半部分是 RDB 数据(采用 RDB 数据格式),AOF 文件后半部分继续追加 AOF 数据(AOF 数据格式)。
当采用 RDB-AOF 混合模式时,数据直接从 AOF 文件加载,由于 AOF 文件存储了 RDB 和 AOF 数据,也就达到了 全量加载RDB数据 和 增量加载AOF数据 的策略。
数据写入过程?
前面我们提到混合模式的数据也是直接存到 AOF 文件,前半部分存 RDB 数据、后半部分存 AOF 数据。
相信你也猜到了,整体数据写入过程与 AOF 模式类似,我们来看看:
文件追加写的部分没有变化,那变化在哪里?AOF 文件重写
你想想,我们的最终目的是「压缩文件」,采用现成的 RDB 方式就可以完成,因此,我们可以考虑直接在重写 AOF 文件时,直接存储 RDB 格式的数据:
- fork 子进程直接按照 RDB 格式将快照数据写入 AOF 文件
- aof_rewrite_buf 缓冲区数据仍然以 AOF 数据格式写入 AOF 文件
整体来看,混合模式的数据写入和 AOF 模式基本一致!!!
5、对比
截止目前 Redis 提供了 AOF、RDB 以及两者混合模式的持久化方式,主要特点如下:

二、副本
持久化机制保障了数据不丢失,但还无法做到故障秒级切换,那怎么办?副本机制,也就是我们常见的主从结构。
1、同步模式
redis 的复制功能可以分为数据同步和命令传播两部分。
- 数据同步:将从节点保持与主节点一致,一般有完全重同步和部分重同步两种模式。
- 命令传播:当主从节点状态一致后,后续新的命令通过 TCP 长连接发送至从节点。
当然,我们也可以通过以下三种具体的数据传输形式来区分:
- 完全重同步,一般是启动时或者主从断开连接过长时间
- 部分重同步,一般是主从短时间断连
- 命令传播,也就是命令实时同步

2、部分重同步
这种模式主要考虑 主从数据同步期间要尽可能的减少数据传输,你想想,主从同步是通过网络进行传输,网络具有不稳定性,如果中断了一小会,难道就要全量重新发一次吗?当然不用
如何实现?环形缓冲区
顾名思义,一块指定大小的缓冲区,可重复循环使用(即,写满了又可以从头开始写,当然就有覆盖较早数据的问题)

从节点会记录已经从主服务器接收到的数据量(复制偏移量),而主节点会维护一个「复制缓冲区」,记录自己已执行且待发送给从节点的命令请求,同时还需要记录复制缓冲区第一个字节的复制偏移量。
从节点请求时带上自己的复制偏移量,主节点接收后对比复制偏移量刻度是否还在,如果还在说明环形缓冲区还没有被覆盖,直接将这边增量数据发送给从节点。
如果复制偏移量不存在,说明已经被覆盖了,就需要完整将整个 RDB 数据文件全量发给从节点。
三、哨兵
有了副本就能实现秒级故障恢复?还不够,这个时候还需要你手动进行切换。
能不能做成自动故障切换?能,这就是哨兵,其本质就是一个监控程序。
用一个哨兵似乎就能完成?能,但不够准,网络的复杂性,经常出故障是可能的,所以,我们最好搞多个哨兵。
我画了张图,大概是这样:

1、核心能力
首先,哨兵的主要职责是保障 redis 服务能正常对外提供服务。因此,肯定是要监听 redis 主节点的在线状态。
其次,当主节点挂掉之后,需要进行故障转移,也就是需要知道所有从节点的信息。因此,哨兵的第二项职责便是监听从节点的状态。
另外,前面部分提到,单哨兵可能并不是那么健壮,我们一般需要搞一个哨兵集群。因此,第三项职责便是哨兵节点间的沟通交流。
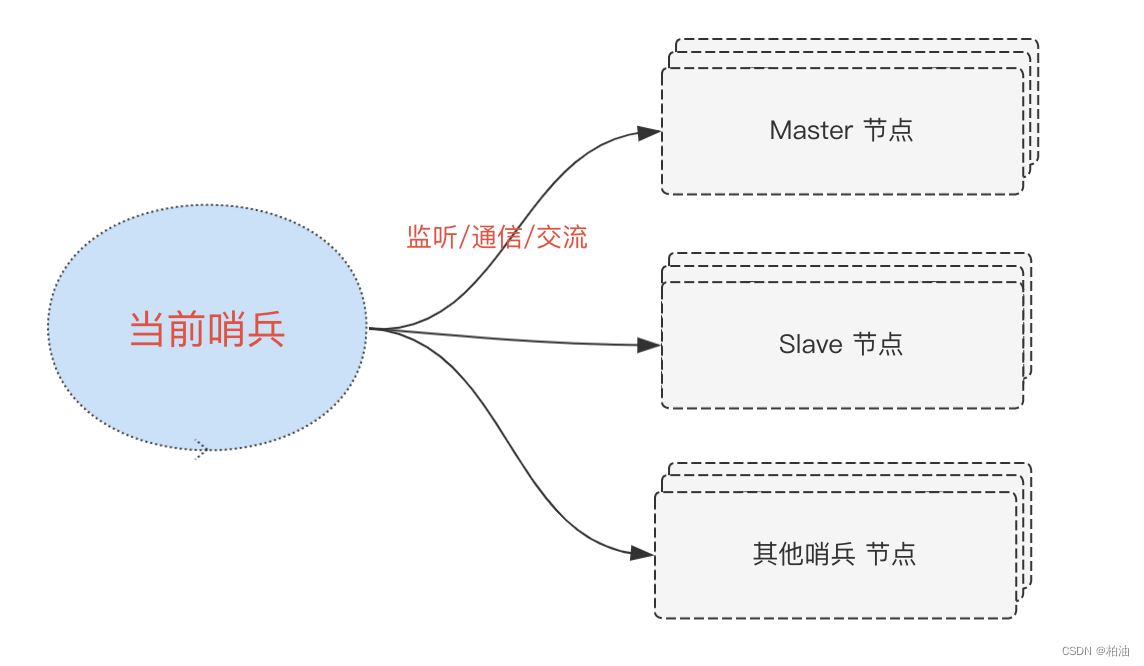
当然,监听节点的目的是为了获取信息,对这些信息进一步处理并采取相应的行动才是目的:
- 哨兵集群信息沟通交流
- master 节点下线判断
- 哨兵集群 leader 选举
- 哨兵 leader 执行故障转移
- 通知客户端,master - slave 变更信息
2、节点通信
哨兵,本质也是一个 redis 服务,既能接收请求又能定期监视相关节点,这是如何做到的?
我们知道,事件是贯穿 redis 的核心机制,客户端发来的请求封装为文件事件,另外还有一些后台周期性的任务封装为时间事件。
哨兵的工作过程号称是异步的,比如发出 PING 之后不需要等待响应,而是当响应到来时,通过回调函数来继续处理。哨兵的异步操作是如何实现的?
哨兵在启动时会创建相关连接,并将对应已连接的 fd 向操作系统内核注册,当有请求到来时,和一般的 redis 请求类似,服务正常处理请求即可。
在哨兵主动发起通信时,主要借助于客户端工具 hiredis,其封装了 RESP 通信协议,发送请求时,这个过程不必等待结果返回,因此,异步体现在这里。
我画了张图,大概是这样:
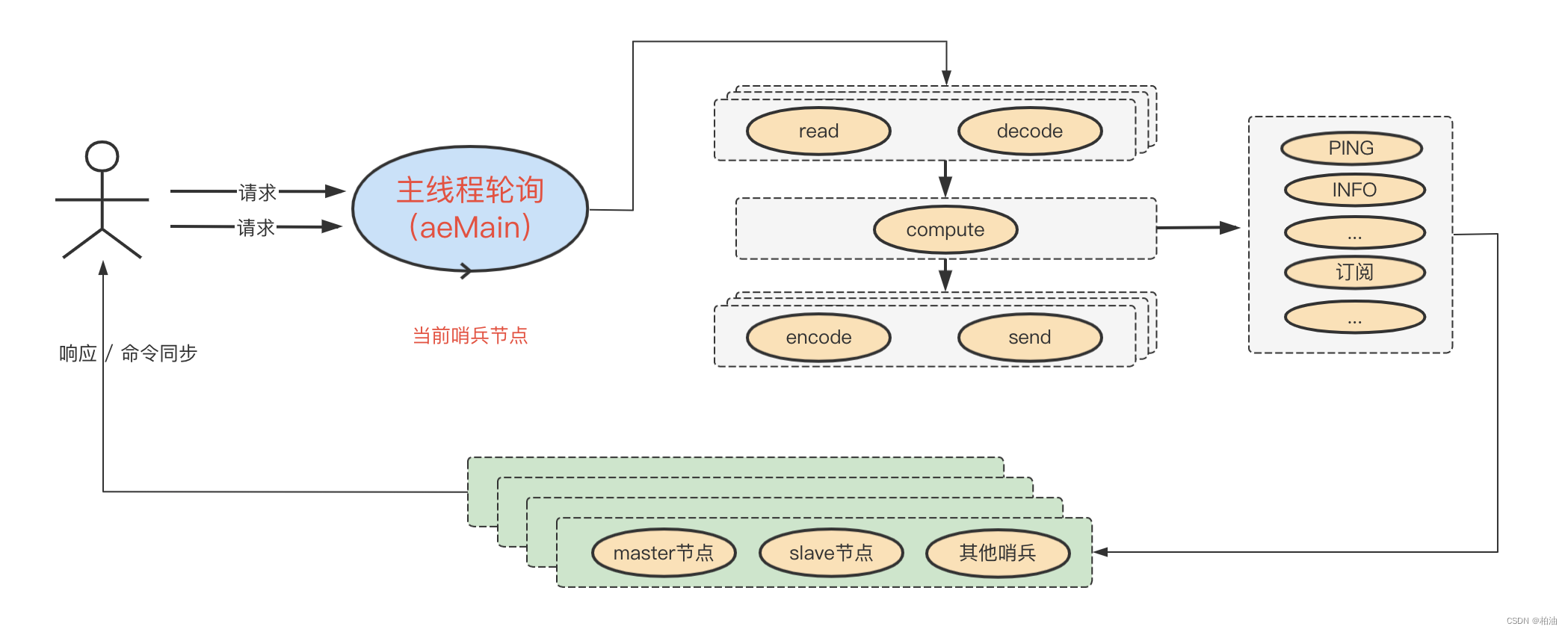
值得注意的是,redis 哨兵的异步过程是与主线程轮训(事件)紧密相连。
总结
本文主要围绕 redis 高可用 进行贯穿讲述,核心问题是要解决 如何确保 redis 无故障或秒级恢复?,我们循序渐进的讲述了三大部分内容:
- 持久化:RDB 、AOF 持久化机制
- 副本机制:一主一丛、一主多从 …
- 哨兵机制:监视、故障转移、通知
把这三部分内容串起来就是这个问题的答案。