提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
- 前言
- 一、开发工具
- 二、环境搭建
- 三、数据来源查询分析
- 四、代码实现
- 1. 发送请求
- 2.数据获取
- 3.解析数据
- 4. 保存数据
- 总结
前言
今天给大家介绍的是Python爬虫某外包平台数据,在这里给需要的小伙伴们帮助,并且给出一点小心得。
一、开发工具
Python版本: 3.6
相关模块:
import requests
import parsel
import csv
import re
二、环境搭建
安装Python并添加到环境变量,pip安装需要的相关模块即可。
文中完整代码及文件,评论区留言
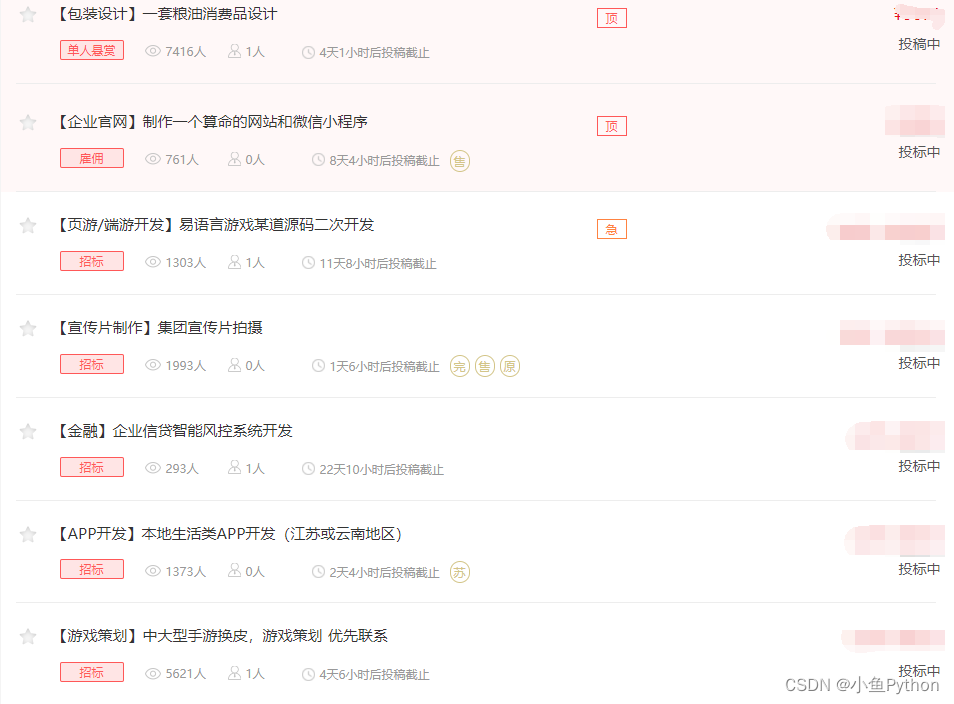
三、数据来源查询分析
浏览器中打开我们要抓的页面
按F12进入开发者工具,查看我们想要的外包平台数据
这里我们需要页面数据就可以了

四、代码实现
1. 发送请求
response = requests.get(url=url, headers=headers)
2.数据获取
print(response.text)
3.解析数据
selectors = parsel.Selector(response.text)
divs = selectors.css('.itemblock')
for div in divs:
title = div.css('div.title a::attr(title)').get()
modelName = div.css('div.modelName::text').get().strip()
num = div.css('div.browser div:nth-child(2) span::text').get().strip()
num_1 = div.css('div.browser div:nth-child(3) span::text').get().strip()
status = div.css('span.status::text').get().strip()
price = div.css('span.price::text').get().strip()
href = div.css('div.title a::attr(href)').get()
4. 保存数据
csv_writer.writerow(dit)
print(title, modelName, num, num_1, status, price, href)
总结
今天的分享到这里就结束了
顺便给大家推荐一些Python爬虫视频教程,希望对大家有所帮助:
Python爬虫实战案例教程合集
对文章有问题的,或者有其他关于python的问题,可以一起讨论
觉得我分享的文章不错的话,可以粉一下我,或者给文章点赞(/≧▽≦)/