前言:
搜索引擎的倒排索引,数据的搜索与查找技术是计算机软件的核心算法,这方面已有非常多的技术和实践经验。而对于搜索引擎来说,要面对海量的文档进行快速的内容检索、查询的话,最主要的技术是倒排索引技术。
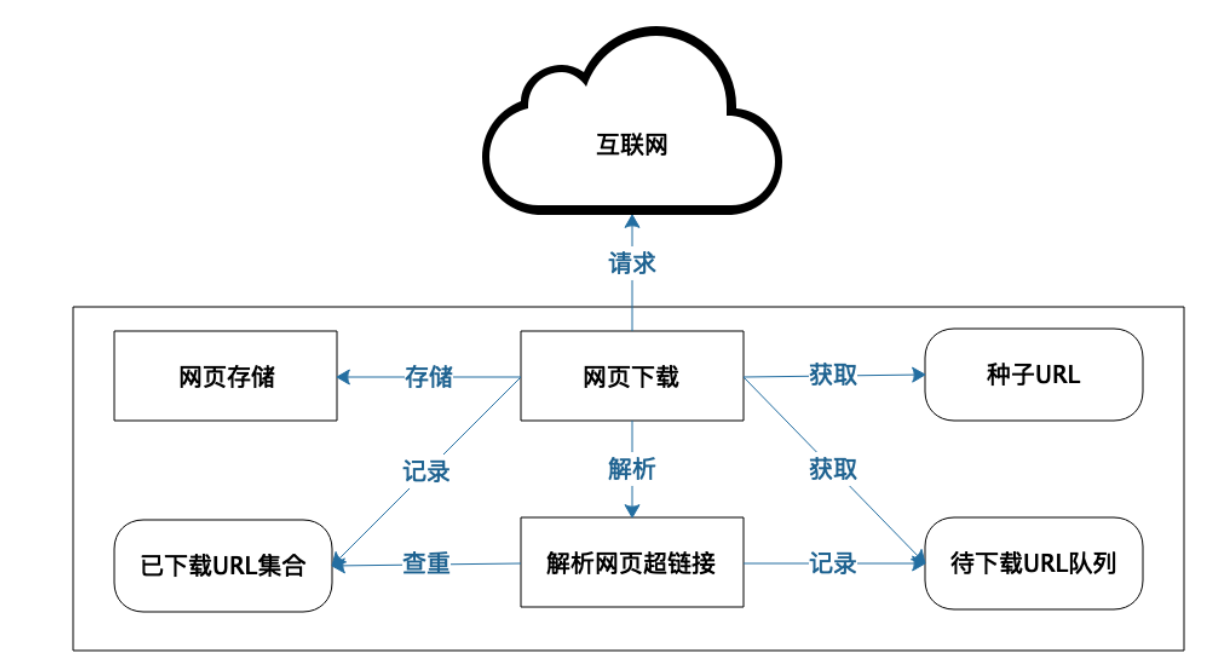
像百度这样的互联网搜索引擎来说,首先需要通过网络爬虫进行全球公开的网页进行拉取的处理。
事实上,互联网一方面是将全世界的人和网络应用联系起来,另一方面也将全世界的网络通过超链接进行联系起来处理,几乎每个网页都包含了一些其他网页的超链接,这些超链接互相连接,就让全世界的互联网构成一个大的网络。搜索引擎只是需要解析这些网页即可,得到里面的超链接,然后继续下载这些超链接的网页,继续解析,这样就可以得到所有的网页了。
过程:首先选择一些种子URL,然后通过爬虫将URL的网页爬下来。爬虫:发送URL请求,下载相关的HTML页面,然后将这些Web页面存储自己的服务器上面,并解析这些页面的HTML页面,当解析到网页里超链接URL的时候,再检查这个超链接是否已经在前面已经处理过了,如果没有处理的话,就把这个超链接放到一个队列里面取,后面的请求URL的时候,得到对应HTML页面并且解析包含的超链接,如此不断重复,就可以将全世界的Web页面存储到自己的服务器里面。
得到了网页以后,需要对每个网页进行编号,得到全部编号以后,然后再解析每个网页,提取文档里面的每个单词,英文的话,可以使用空格分隔处理,比较容易;如果是中文的话,比如说后端技术“后端技术”这四个字来说,得到就是后端、技术两个词。
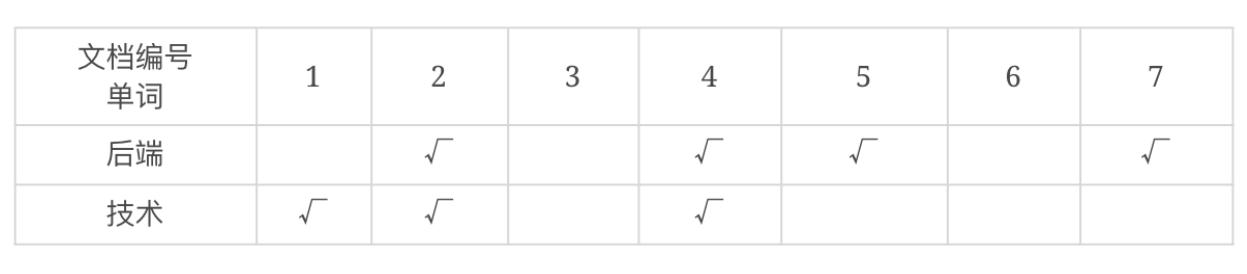
把这个单词、文档矩阵按照单词、文档列表的方式组织起来,就是倒排索引:
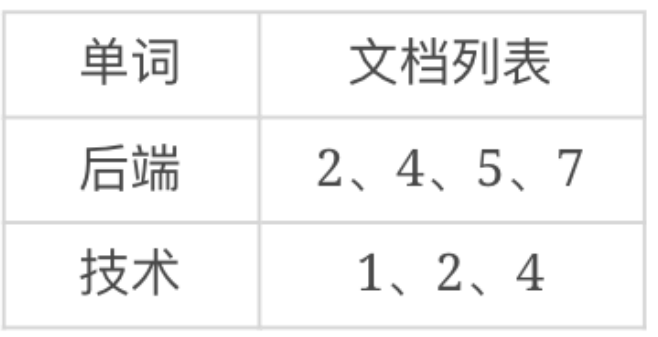
这个例子中只有两个单词、7个文档,搜索单词的时候,可以将所有的单词构成一个Hash表,根据搜索词直接查找Hash表,就可以找到对应的单词了,如果搜索词是“后端”,快速得到文档列表,有4个;如果搜索词是“后端技术”,那么首先需要对搜索词进行分词,得到“后端”、“技术”两个搜索单词,分别得到这两个单词的文档列表,然后将这两个文档列表进行交集,可以得到两个结果。
虽然搜索引擎利用倒排索引可以很快得到搜索结果了,但是实践中,搜索引擎应用还会使用缓存对搜索进行加速,将整个搜索词对应的搜索结果直接放入缓存,减少倒排索引的访问压力,以及不必要的集合计算。
搜索引擎结果排序:
google使用了一种叫PageRank的算法进行排序的处理,计算每个网页的权重,搜索结果就按照权重进行排序的处理,权重高的网页在最终结果显示的时候排在前面。
PageRank算法认为,如果一个网页里面包含了某个网页的超链接,那么就表示该网页认可某个网页,或者时候,该网页给某个网页投了一票,如下ABCD四个网页,箭头指向的就是表示超链接的方向,B的箭头指向A,表示B网页包含A网页的超链接,也就是B网页给A网页投了一票。
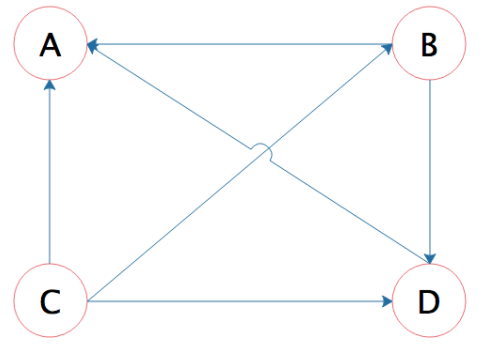
开始的时候,所有的网页都初始化权重值为1,然后根据超链接关系计算新的权重,比如说B页面包含了A和B两个页面的超链接,那么自己的权重1就被分成了两个分别投给了A和D。
经过一轮PageRank之后,每个页面都有了自己的权重,然后基于这个权重再继续一轮计算,直到所有的网页权重稳定下来,就得到最终所有网页的权重,即最终的pageRank的值。
通常一个网页中包含了另一个网页,是对另一个网页的认可,认为这个网页质量高,值得推荐,而被重要网页推荐的页面也应该是重要的,PageRank算法就是对这一设想的实现,PageRank值代表了一个网页受到推荐的程度,越受推荐越重要,就会是用户想要看到的结果。