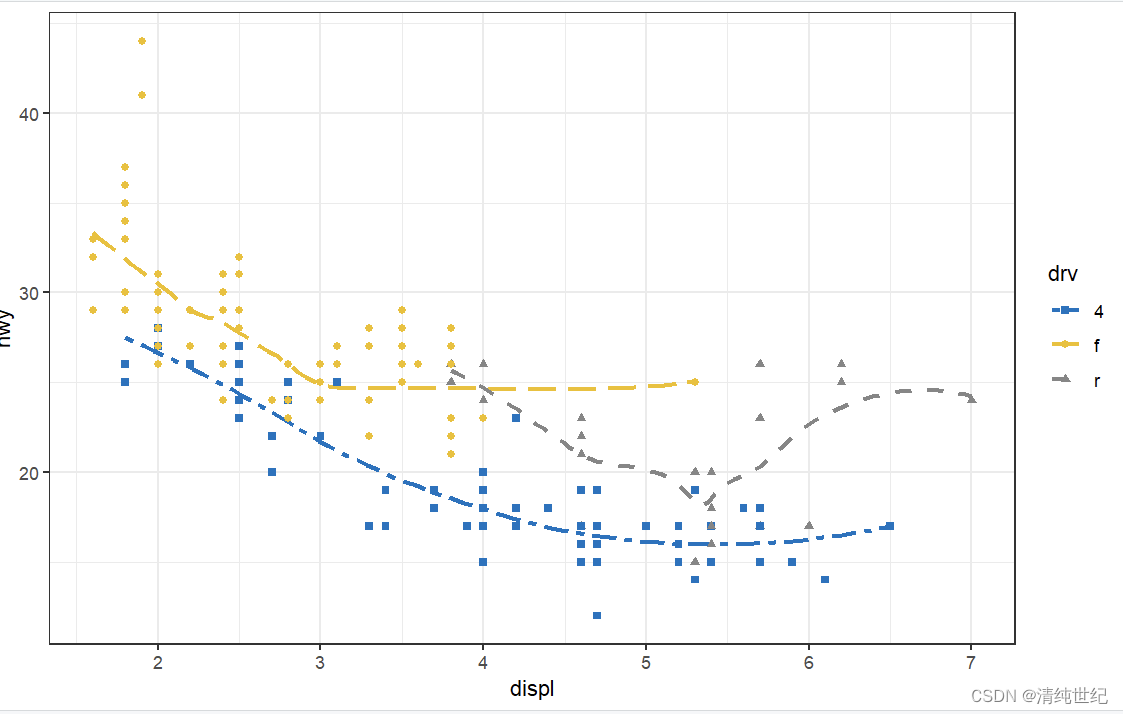
应用场景:需要根据日志文件,统计出数据从开始下发到收到回复所需的时间,包括最大值、最小值、平均值、中位数。
日志格式如图类似,每一行日志开始部分就是所需要截取的时间;1条日记是以某些关键词作为开始,获取改条日志的时间。其后的日志中找到1条对应着结束的日志,并获取时间,两者的差值就是所需要的时间值;如果没有找到结束的那条日志,那么其对应的开始那条记录是需要被舍弃掉,说明该条数据是执行失败,不需要被统计在内。

import codecs
import statistics
from datetime import datetime
f = codecs.open('test.log', mode='r', encoding='utf-8') # 打开log文件,以‘utf-8’编码读取
lineStr = f.readline() # 按行读取log文件
data = [] # 时间差值
startList = [] # 定义开始时间列数据存放在列表
endList = [] # 定义结束时间列数据存放在列表
while lineStr:
if '开始' in lineStr: # 筛选出每行中包含“开始”的数日志,作为一条数据的开始
startStr = lineStr[:23] # 提取开始时间
# 将字符串解析为datetime对象
dt = datetime.strptime(startStr, "%Y-%m-%d %H:%M:%S.%f")
# 将datetime对象转换为毫秒级时间戳
timestamp_millis = int(dt.timestamp() * 1000)
# print(timestamp_millis)
startList.append(timestamp_millis)
elif '结束' in lineStr: # 筛选出每行中包含的“结束”的日志,作为一条数据的结束
endStr = lineStr[:23]
dt = datetime.strptime(endStr, "%Y-%m-%d %H:%M:%S.%f")
# 将datetime对象转换为毫秒级时间戳
timestamp_millis = int(dt.timestamp() * 1000)
endList.append(timestamp_millis)
lineStr = f.readline()
f.close()
print("命令下发到驱动执行完成(ms):")
num1 = len(startList)
num2 = len(endList)
if num1 == num2: # 开始和结束的日志必须要是相邻的,否则开始的那条日志被舍弃
for i in range(num1):
d = int(endList[i]) - int(startList[i])
data.append(d)
else:
print("开始和结束的数量不匹配!!")
print('使用的测试数据量是:{}条'.format(num1))
# print('开始时间的数据量是:{}条'.format(num1))
# print('结束时间的数据量是:{}条'.format(num2))
# print('计算的时间差值是:{}'.format(data))
# 计算出时间差值中的最大值:
maxStr = max(data)
print('计算差值中的最大值:{}ms'.format(maxStr))
# 计算出时间差值中的最小值:
minStr = min(data)
print('计算差值中的最小值:{}ms'.format(minStr))
# 计算出时间差值中的平均值:
avgStr = statistics.mean(data)
print('计算差值中的平均值:{:.2f}ms'.format(avgStr)) # 保留两位小数
# 计算出时间差值中的中位数:
midStr = statistics.median(data)
print('计算差值中的中位数:{}ms'.format(midStr))
运行的结果: