在上一篇文章的介绍中,我们知道语义分割可以对图像中的每个像素进行类别预测。这节主要讲关于全卷积网络(Fully Convolutional Network,FCN),实现从图像像素到像素类别的变换。
那这里的卷积神经网络跟以往的有什么不一样的地方吗?
这里的网络是通过转置卷积(Transposed Convolution)层将中间层特征图的高和宽变换回输入图像的尺寸,从而令预测结果与输入图像在空间维(高和宽)上一一对应,给定空间维上的位置,通道维的输出就是该位置对应像素的类别预测。
转置卷积
转置卷积(Transposed Convolution)也是卷积运算,需要强调的是,有些地方写成反卷积,其实不是很妥当,这个转置卷积看起来像是我们以前接触的卷积运算的反运算,其实是不可逆的,由于它的名称来自于矩阵的转置操作,所以正确叫法叫做转置卷积。我们先通过一张图来对比下这个卷积运算与转置卷积运算的区别在哪儿:

第一行是我们很熟悉的卷积运算,4x4的输入,通过3x3的步幅为1的卷积核,我们得到了一个2x2的输出,这个大家都熟悉,滑动窗口做加权运算即可。
观察第二行,我们的输入尺寸是2x2,也就是说输入的特征图尺寸变小了,运算同样是通过3x3的步幅为1的卷积核的卷积运算,最终我们却得到了一个更大尺寸的输出(4x4),原因是输入特征图的周围也就是像素的上下左右填充了0,将输入尺寸变成了6x6的尺寸了,然后同样做卷积运算。
动态图如下:

通过代码我们来验证下:
import d2lzh as d2l
from mxnet import nd,init
from mxnet.gluon import nn
X=nd.arange(1,17).reshape(1,1,4,4)
K=nd.arange(1,10).reshape(1,1,3,3)
conv=nn.Conv2D(channels=1,kernel_size=3)
conv.initialize(init.Constant(K))
print(conv(X))
'''
[[[[348. 393.]
[528. 573.]]]]
<NDArray 1x1x2x2 @cpu(0)>
'''这个是正向卷积的情况,4x4的输入,经过3x3卷积之后,得到了2x2的输出。
我们从矩阵乘法的角度来了解这个卷积运算:
X=nd.arange(1,17).reshape(1,1,4,4)
K=nd.arange(1,10).reshape(1,1,3,3)
W,k=nd.zeros((4,16)),nd.zeros(11)
k[:3],k[4:7],k[8:]=K[0,0,0,:],K[0,0,1,:],K[0,0,2,:]
#print(k)#[1. 2. 3. 0. 4. 5. 6. 0. 7. 8. 9.]
W[0,0:11],W[1,1:12],W[2,4:15],W[3,5:16]=k,k,k,k
#print(W)
'''
[[1. 2. 3. 0. 4. 5. 6. 0. 7. 8. 9. 0. 0. 0. 0. 0.]
[0. 1. 2. 3. 0. 4. 5. 6. 0. 7. 8. 9. 0. 0. 0. 0.]
[0. 0. 0. 0. 1. 2. 3. 0. 4. 5. 6. 0. 7. 8. 9. 0.]
[0. 0. 0. 0. 0. 1. 2. 3. 0. 4. 5. 6. 0. 7. 8. 9.]]
'''
print(W.shape,X.reshape(16).shape)#(4, 16) (16,)
print(nd.dot(W,X.reshape(16)))#[348. 393. 528. 573.]
print(nd.dot(W,X.reshape(16)).reshape(1,1,2,2))
'''
[[[[348. 393.]
[528. 573.]]]]
<NDArray 1x1x2x2 @cpu(0)>
'''这里的权重矩阵W的形状是4x16,然后对于输入是16(4x4尺寸)的向量,卷积前向计算之后的输出长度是4(2x2尺寸)。
我们知道在反向传播中,做乘法的时候,需要乘以转置后的权重矩阵。
那不难发现,当我们的输入向量长度是4(2x2尺寸),转置权重矩阵的形状是16x4,那么转置卷积层输出的长度将是16(4x4尺寸)
X1=nd.arange(1,5)
W1=nd.arange(1,65).reshape(16,4)
print(W1.shape,X1.shape)#(16, 4) (4,)
print(nd.dot(W1,X1))#[ 30. 70. 110. 150. 190. 230. 270. 310. 350. 390. 430. 470. 510. 550. 590. 630.]<NDArray 16 @cpu(0)>填充公式与输出尺寸公式
那么这个输入特征图的填充,具体应该怎么填充,跟哪些因素有关?
这里我们来看一个步幅是2的3x3的卷积核,看下它是怎么卷积的,动态图如下:
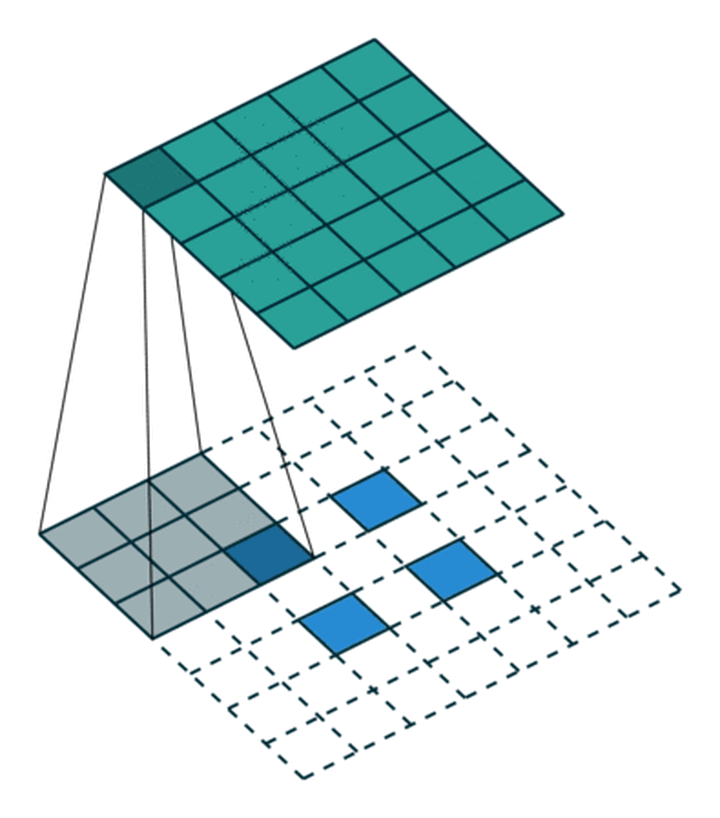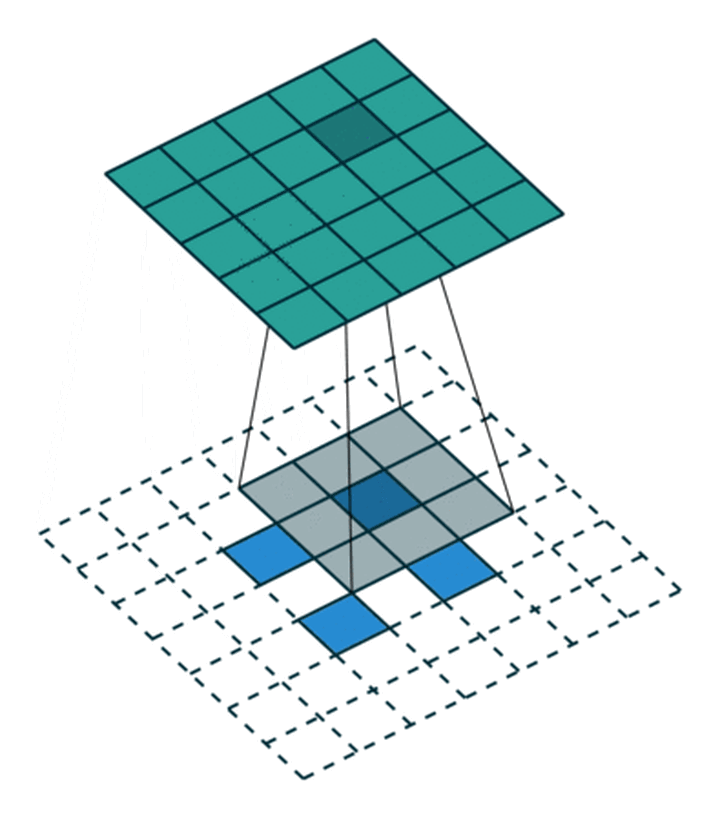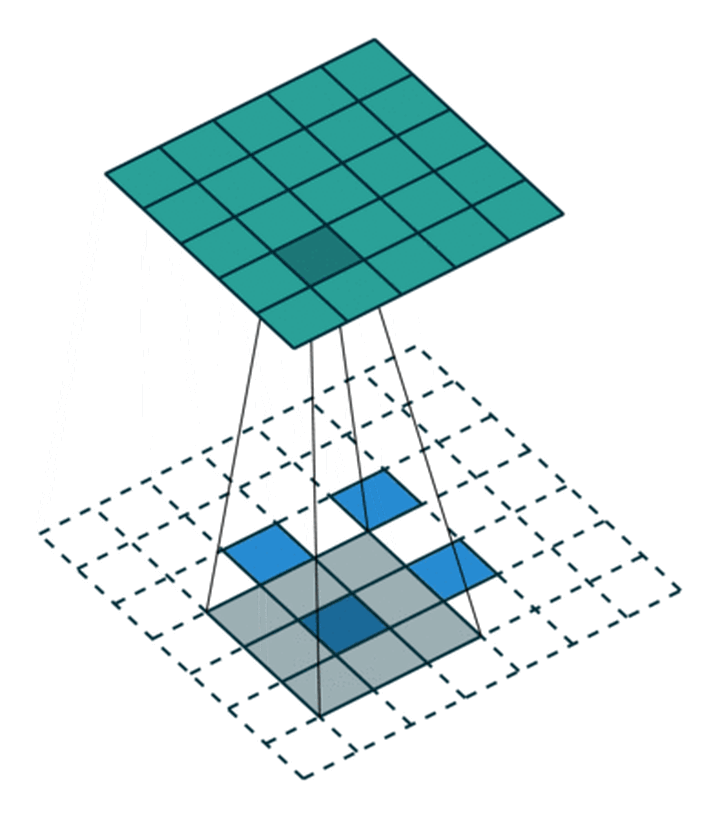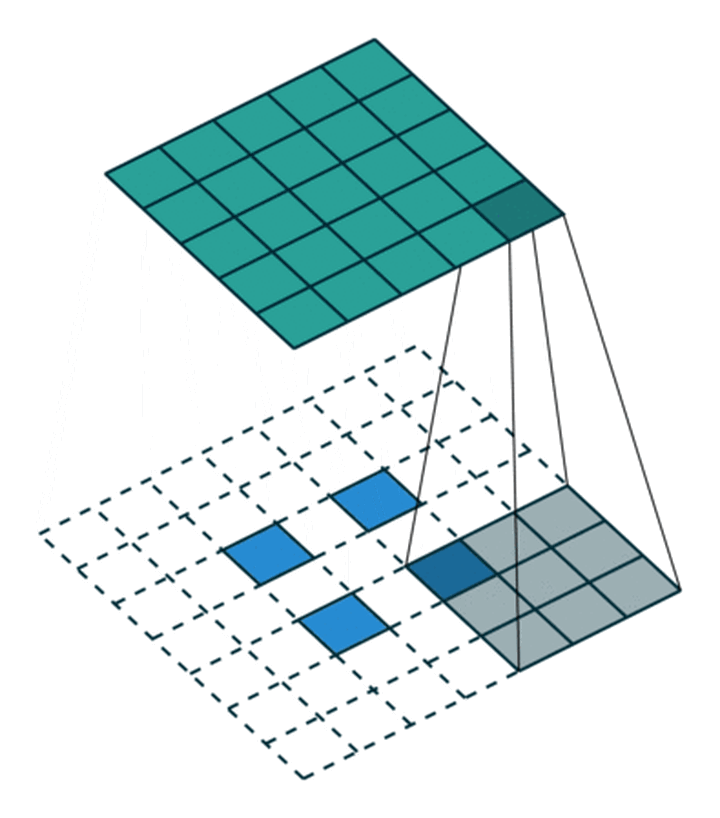
重点观察这个2x2的特征图(蓝色方块),在周边有了填充之外,在蓝色块之间也有填充,也就是说不仅是特征图周边做填充,而且在里面也做了填充。
填充公式
输入特征图像素之间填充0:取决于步幅stride-1(s-1),比如这里是2-1=1,像素之间有1个0的填充
输入特征图外的四周填充0:取决于卷积核大小kernel_size-填充padding-1,比如这里是3-0-1=2,整体特征图的上下左右就是填充2行2列的0
也就是说,对于输入特征图像,四周的填充取决于卷积核大小跟填充的大小,特征像素之间的填充取决于步幅的大小。
最后将卷积核参数上下、左右翻转之后做卷积运算即可
输出的高和宽尺寸公式
H=(输入的高h-1) x 步幅stride[0] - 2x填充padding[0] + 卷积核大小kernel[0]
H=(输入的宽w-1) x 步幅stride[0] - 2x填充padding[0] + 卷积核大小kernel[0]
比如这里的输入是2x2,步幅是1,填充是0,卷积核是3x3
计算结果就是 (2-1)x1-2x0+3=4,输出的高宽就是4x4的尺寸
再比如输入依然是2x2,当步幅是2,填充是0,卷积核大小3x3的卷积运算之后的输出(2-1)x2-2x0+3=5,跟上面动态图中一样,确实是将输入2x2的大小转置卷积之后变成了5x5的输出尺寸。
转置卷积的作用
我们知道在做卷积提取特征运算之后,输出的特征图尺寸将变小,而在语义分割当中我们需要将图像恢复到原来的尺寸以便进行进一步的计算,那就只能让输入特征扩大了,这样的目的就会让输出尺寸变大,这种操作叫做上采样(upsample),这里的转置卷积就属于这种。再次强调这个转置卷积不是我们以前接触到的卷积运算的逆运算,转置卷积也属于卷积运算,只不过对输入做了填充操作。
在全卷积网络中,当输入特征图的高宽较小时,转置卷积层可以用来将高宽放大到输入图像的尺寸。我们来看个具体例子:
conv=nn.Conv2D(10,kernel_size=4,strides=2,padding=1)
conv.initialize()
X=nd.random.uniform(shape=(1,3,64,64))
Y=conv(X)
print(Y.shape)#(1, 10, 32, 32)这里我们通过卷积运算,将通道数扩大到10,输出的尺寸缩小了一半,现在我们通过这个转置卷积层来让输出扩大到原尺寸的输入大小。
conv_trans=nn.Conv2DTranspose(3,kernel_size=4,strides=2,padding=1)
conv_trans.initialize()
print(conv_trans(Y).shape)#(1, 3, 64, 64)我们也可以通过上面的输出尺寸公式验证下:(32-1)x2-2x1+4=64
全卷积网络模型(FCN)
全卷积网络模型的基本设计:使用卷积神经网络抽取图像特征,然后通过1x1的卷积层将通道数变换为类别个数,最后通过转置卷积层将特征图的高和宽变换为输入图像的尺寸。
模型的输出跟输入图像在高和宽上相同,并在空间位置上一一对应,最终输出的通道包含了该空间位置像素的类别预测。
如下图:
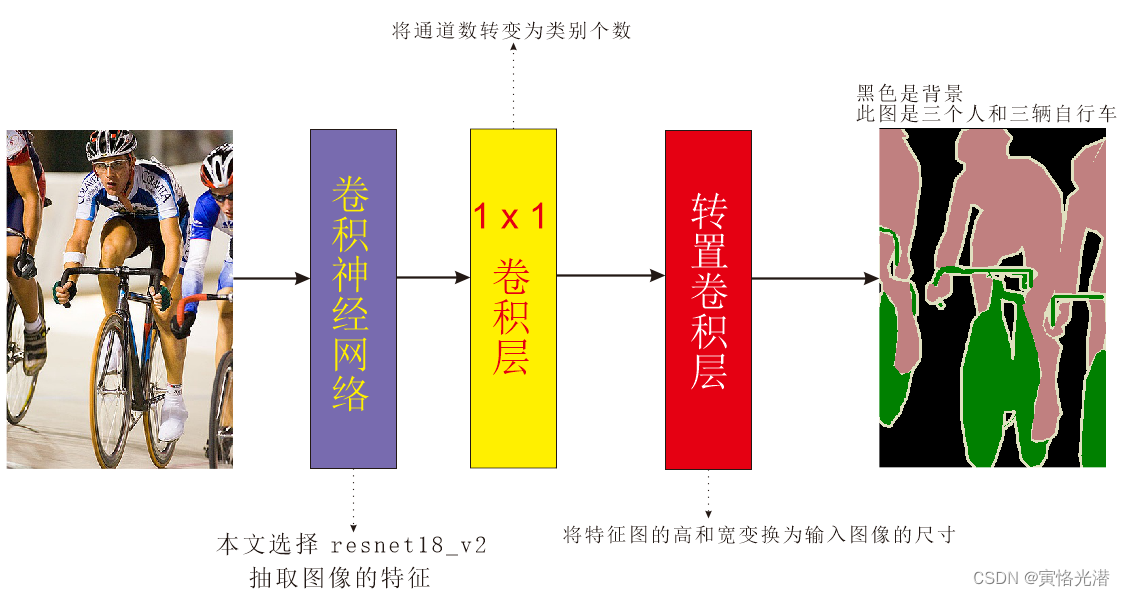
我们来构建模型,基于ImageNet数据集预训练的ResNet-18模型来抽取图像特征,其中features和output分别是特征层和输出层,这里的输出层不需要,另外features层的最后两层也去掉(最大池化层和样本变平层)
给定高宽分别是320和480,我们先来看下这个残差网络计算的结果:
from mxnet.gluon import nn, model_zoo
pretrained_net = model_zoo.vision.resnet18_v2(pretrained=True)
net = nn.HybridSequential()
for layer in pretrained_net.features[:-2]:
net.add(layer)
X = nd.random.uniform(shape=(1, 3, 320, 480))
print(net(X).shape)#(1, 512, 10, 15)这里计算之后的结果,我们看到通道数增加到512,然后高宽减小到了原尺寸的1/32,为了让这个特征图的高宽放到到32倍,跟原来尺寸一样,我们先来看下,卷积运算的输出形状的公式:
OH=1+(H+2P-FH)/S
OW=1+(W+2P-FW)/S
这个在卷积神经网络(CNN)相关的基础知识中有说明,有兴趣的可以去看看。
OH=1+(320+2P-FH)/S=10
OW=1+(480+2P-FW)/S=15
从这个公式,我们发现,当填充P=S/2,卷积核的高和宽是2S的时候,转置卷积核将输入的高和宽分别放大S倍。
于是构造一个步幅为32,填充为16,卷积核高宽为64的转置卷积层即可。
1+(320+2x16-64)/32=10
1+(480+2x16-64)/S=15
然后通过1x1的卷积层将输出通道数变换为Pascal VOC2012数据集的类别个数21
num_classes = 21
net.add(nn.Conv2D(num_classes, kernel_size=1),
nn.Conv2DTranspose(num_classes, kernel_size=64, strides=32, padding=16))双线性插值
从上面我们知道,特征图比较小,我们需要将它放大(因为有卷积运算,输出变小嘛),这个大家都知道这个操作是上采样,方法比较多,这里介绍一种使用bilinear_kernel函数构造的卷积核的转置卷积层来实现。
import d2lzh as d2l
from mxnet import nd, init,image
from mxnet.gluon import nn, model_zoo
import numpy as np
def bilinear_kernel(in_channels, out_channels, kernel_size):
'''双线性插值'''
factor = (kernel_size + 1) // 2
if kernel_size % 2 == 1:
center = factor - 1
else:
center = factor - 0.5
# 返回两个数组的列表
og = np.ogrid[:kernel_size, :kernel_size]
filt = (1 - abs(og[0] - center) / factor) * (1 - abs(og[1] - center) / factor)
weight = np.zeros((in_channels, out_channels, kernel_size, kernel_size), dtype='float32')
weight[range(in_channels), range(out_channels), :, :] = filt
return nd.array(weight)
conv_trans=nn.Conv2DTranspose(3,kernel_size=4,strides=2,padding=1)
conv_trans.initialize(init.Constant(bilinear_kernel(3,3,4)))
img=image.imread('hi.jpg')
X=img.astype('float32').transpose((2,0,1)).expand_dims(axis=0)/255#NCHW并标准化
print(X.shape)#(1, 3, 540, 485)
Y=conv_trans(X)
print(Y.shape)#(1, 3, 1080, 970)看了看到图像的宽高放大了2倍,我们使用转置卷积输出尺寸的公式,验证下:
H=(输入的高h-1)x步幅stride[0]-2x填充padding[0]+卷积核大小kernel[0]=(540-1)x2-2x1+4=1080
H=(输入的宽w-1)x步幅stride[0]-2x填充padding[0]+卷积核大小kernel[0]=(485-1)x2-2x1+4=970
我们打印图像看下:
d2l.set_figsize()
d2l.plt.imshow(img.asnumpy())
d2l.plt.show()
d2l.plt.imshow(Y[0].transpose((1,2,0)).asnumpy())
d2l.plt.show() 从上面的图片对比我们发现,除了坐标的刻度不一样之外,双线性插值放大的图像跟原图看上去没什么区别。
从上面的图片对比我们发现,除了坐标的刻度不一样之外,双线性插值放大的图像跟原图看上去没什么区别。
训练模型
我们将最后两层分别初始化之后,读取数据集进行模型训练,其中的倒数第二层是1x1的卷积层,我们使用Xavier随机初始化,倒数第一层是转置卷积层,我们用到上面的双线性插值来初始化。
net[-2].initialize(init=init.Xavier())
net[-1].initialize(init.Constant(bilinear_kernel(num_classes,num_classes,64)))初始化模型之后,我们来训练VOC2012数据集:
import d2lzh as d2l
from mxnet import nd, init, image, gluon
from mxnet.gluon import nn, model_zoo, data as gdata, loss as gloss
import numpy as np
import sys
def bilinear_kernel(in_channels, out_channels, kernel_size):
'''双线性插值'''
factor = (kernel_size + 1) // 2
if kernel_size % 2 == 1:
center = factor - 1
else:
center = factor - 0.5
# 返回两个数组的列表
og = np.ogrid[:kernel_size, :kernel_size]
filt = (1 - abs(og[0] - center) / factor) * (1 - abs(og[1] - center) / factor)
weight = np.zeros((in_channels, out_channels, kernel_size,kernel_size), dtype='float32')
weight[range(in_channels), range(out_channels), :, :] = filt
return nd.array(weight)
'--------全卷积神经网络模型FCN----------------------------'
pretrained_net = model_zoo.vision.resnet18_v2(pretrained=True,prefix='res_')
net = nn.HybridSequential(prefix='res_')
for layer in pretrained_net.features[:-2]:
with net.name_scope():
net.add(layer)
num_classes = 21
net.add(nn.Conv2D(num_classes, kernel_size=1),
nn.Conv2DTranspose(num_classes, kernel_size=64, strides=32, padding=16,prefix='res_'))
# 1x1的卷积层,采用Xavier随机初始化
net[-2].initialize(init=init.Xavier())
# 转置卷积层,初始化为双线性插值的上采样
net[-1].initialize(init.Constant(bilinear_kernel(num_classes, num_classes, 64)))
'-----------------------------------------------------'
# 配置比较低,这里的批处理大小搞小点,设置为8
crop_size, batch_size, colormap2label = (320, 480), 8, nd.zeros(256**3)
for i, cm in enumerate(d2l.VOC_COLORMAP):
colormap2label[(cm[0]*256+cm[1])*256+cm[2]] = i
voc_dir = "../data/VOCdevkit/VOC2012"
num_workers = 0 if sys.platform.startswith('win32') else 4
train_iter = gdata.DataLoader(d2l.VOCSegDataset(True, crop_size, voc_dir, colormap2label),
batch_size, shuffle=True, last_batch='discard', num_workers=num_workers)
test_iter = gdata.DataLoader(d2l.VOCSegDataset(False, crop_size, voc_dir, colormap2label),
batch_size, shuffle=True, last_batch='discard', num_workers=num_workers)
'''
read 1114 examples
read 1078 examples
'''
ctx = d2l.try_all_gpus()
loss = gloss.SoftmaxCrossEntropyLoss(axis=1)
net.collect_params().reset_ctx(ctx)
trainer = gluon.Trainer(net.collect_params(), 'sgd', {'learning_rate': 0.1, 'wd': 1e-3})
d2l.train(train_iter, test_iter, net, loss, trainer, ctx, num_epochs=5)
net.collect_params().save('myfcn.params')#训练之后保存
'''
training on [gpu(0)]
[13:00:07] c:\jenkins\workspace\mxnet-tag\mxnet\src\operator\nn\cudnn\./cudnn_algoreg-inl.h:97: Running performance tests to find the best convolution algorithm, this can take a while... (set the environment variable MXNET_CUDNN_AUTOTUNE_DEFAULT to 0 to disable)
[13:00:09] c:\jenkins\workspace\mxnet-tag\mxnet\src\operator\nn\cudnn\./cudnn_algoreg-inl.h:97: Running performance tests to find the best convolution algorithm, this can take a while... (set the environment variable MXNET_CUDNN_AUTOTUNE_DEFAULT to 0 to disable)
epoch 1, loss 1.6055, train acc 0.706, test acc 0.740, time 113.0 sec
epoch 2, loss 1.2191, train acc 0.730, test acc 0.760, time 109.9 sec
epoch 3, loss 1.2267, train acc 0.735, test acc 0.739, time 109.7 sec
epoch 4, loss 0.9452, train acc 0.752, test acc 0.769, time 108.7 sec
epoch 5, loss 0.9784, train acc 0.754, test acc 0.776, time 109.3 sec
'''其中SoftmaxCrossEntropyLoss需指定axis=1(通道维)选项,因为我们使用转置卷积层的通道维来预测像素的类别。另外保存参数文件的时候要注意指定前缀。由于这里是改造过的resnet18_v2网络,取代的是1x1卷积层与转置卷积层。所以在加载参数文件的时候,也需要同样的网络结构与指定前缀:
pretrained_net = model_zoo.vision.resnet18_v2(prefix='res_')
mynet = nn.HybridSequential(prefix='res_')
for layer in pretrained_net.features[:-2]:
with mynet.name_scope():
mynet.add(layer)
num_classes = 21
mynet.add(nn.Conv2D(num_classes, kernel_size=1),
nn.Conv2DTranspose(num_classes, kernel_size=64, strides=32, padding=16))
mynet.collect_params().load('myfcn.params')#加载训练之后的参数文件
#一些常见的用法
#print(mynet)
#print(mynet[0].params)
#print(mynet[1].weight.data())
#print(mynet[1].weight.grad())
#print(mynet.collect_params())
#print(mynet.collect_params('.*weight')) 预测像素类别
在预测时,我们需要将输入图像在各个通道做标准化,并转成卷积神经网络所需要的四维输入格式NCHW。另外由于测试数据集中的图像大小和形状各异,模型使用了步幅为32的转置卷积层,当输入图像的高宽没有被32整除的时候,那么输出的尺寸就跟原尺寸存在偏差。
这里为了简单起见,只读取几张比较大的测试图像,并从图像的左上角开始截取宽为480和高为320的区域。只有该区域用于测试。图中第二行就是该区域的测试,第一行是截取的原图,第三行是标注的类别。
import d2lzh as d2l
from mxnet import nd, image
from mxnet.gluon import nn, model_zoo, data as gdata
import sys
pretrained_net = model_zoo.vision.resnet18_v2(prefix='res_')
mynet = nn.HybridSequential(prefix='res_')
for layer in pretrained_net.features[:-2]:
with mynet.name_scope():
mynet.add(layer)
num_classes = 21
mynet.add(nn.Conv2D(num_classes, kernel_size=1),
nn.Conv2DTranspose(num_classes, kernel_size=64, strides=32, padding=16))
mynet.collect_params().load('myfcn.params')#加载训练之后的参数文件
# 配置比较低,这里的批处理大小搞小点,设置为8
crop_size, batch_size, colormap2label = (320, 480), 8, nd.zeros(256**3)
for i, cm in enumerate(d2l.VOC_COLORMAP):
colormap2label[(cm[0]*256+cm[1])*256+cm[2]] = i
voc_dir = "../data/VOCdevkit/VOC2012"
num_workers = 0 if sys.platform.startswith('win32') else 4
train_iter = gdata.DataLoader(d2l.VOCSegDataset(True, crop_size, voc_dir, colormap2label),
batch_size, shuffle=True, last_batch='discard', num_workers=num_workers)
test_iter = gdata.DataLoader(d2l.VOCSegDataset(False, crop_size, voc_dir, colormap2label),
batch_size, shuffle=True, last_batch='discard', num_workers=num_workers)
ctx = d2l.try_all_gpus()
mynet.collect_params().reset_ctx(ctx)
def predict(img):
X = test_iter._dataset.normalize_image(img)
X = X.transpose((2, 0, 1)).expand_dims(axis=0) # 增加一维,转成NCHW形状
pred = nd.argmax(mynet(X.as_in_context(ctx[0])), axis=1)
return pred.reshape((pred.shape[1], pred.shape[2]))
def label2image(pred):
colormap = nd.array(d2l.VOC_COLORMAP, ctx=ctx[0], dtype='uint8')
X = pred.astype('int32')
return colormap[X, :]
test_images, test_labels = d2l.read_voc_images(is_train=False)
n, imgs = 4, []
for i in range(n):
crop_rect = (0, 0, 480, 320)
X = image.fixed_crop(test_images[i], *crop_rect)
pred = label2image(predict(X))
imgs += [X, pred, image.fixed_crop(test_labels[i], *crop_rect)]
d2l.show_images(imgs[::3]+imgs[1::3]+imgs[2::3], 3, n)
d2l.plt.show()训练几次的效果还可以,因为我的batch_size毕竟很小,第三张船的图片识别不是很好之外都还不错。


小结:可以看到全卷积网络首先使用卷积神经网络抽取图像特征,然后通过1x1的卷积层将通道数变换为类别个数,最后通过转置卷积层将特征图的高和宽变换为输入图像的尺寸,从而输出每个像素的类别。
这里在最后也重新熟悉下如何保存训练好的参数文件以及加载参数文件的过程,我们在计算机视觉之迁移学习中的微调(fine tuning)中已有介绍过,有点区别,有兴趣的可以去了解下微调这个方法。对于参数文件可以理解成人的血肉,网络模型属于骨架,往骨架里面填满血肉,这样就成为了血肉之躯哈哈。