1、什么是自然语言处理?
自然语言处理(Natural Language Processing, NLP)是计算机科学领域与人工智能领域中的一个重要方向。它研究能实现人与计算机之间用自然语言进行有效通信的各种理论和方法。自然语言处理是一门融语言学、计算机科学、数学于一体的科学。
1.1、自然语言处理有什么用?
智能问答
机器同传
文本摘要
阅读理解
情感分析
1.2、自然语言处理的挑战

1.3、自然语言处理技术发展

2、文本预处理
文本语料在输送给模型前一般需要一系列的预处理工作,才能符合模型输入的要求,如:将文本转化成模型需要的张量,规范张量的尺寸等,而且科学的文本预处理环节还将有效指导模型超参数的选择,提升模型的评估指标。
2.1、分词
2.1.1、jieba分词器
"结巴" 中文分词:做最好的 Python 中文分词组件 "Jieba"
- 支持三种分词模式:
- 精确模式,试图将句子最精确地切开,适合文本分析;
- 全模式,把句子中所有的可以成词的词语都扫描出来,速度非常快,但是不能解决歧义;
- 搜索引擎模式,在精确模式的基础上,对长词再次切分,提高召回率,适合用于搜索引擎分词。
- 支持繁体分词
- 支持自定义词典
工信处女干事每月经过下属科室都要亲口交代24口交换机等技术性器件的安装工作
==>
['工信处', '女干事', '每月', '经过', '下属', '科室', '都', '要', '亲口', '交代', '24', '口', '交换机', '等', '技术性', '器件', '的', '安装', '工作']
2.1.2、流行中英文分词工具hanlp
中英文NLP处理工具包,基于tensorflow2.0,使用在学术界和行业中推广最先进的深度学习技术
2.2、命名实体识别(Named Entity Recognition)
识别出一段文本中可能存在的命名实体。
通常我们将人名、地名、机构名等专有名词统称命名实体,如:周杰伦、黑山县、孔子学院、24辊方钢矫直机。
2.3、词性标注(Part-Of-Speech tagging)
简称POS,标注出一段文本种每个词汇的词性。
词性:语言中对词的一种分类方法,以语法特征为主要依据、兼顾词汇意义对词进行划分的结果,常见的词性有14种,如:名词,动词,形容词等。
2.4、文本张量表示方法
将一段文本使用张量进行表示,其中一般将词汇表示成向量,称作词向量,再由各个词向量按顺序组成矩阵形成文本表示,能够使语言文本可以作为计算机处理程序的输入,进行接下来一些列的解析工作。
2.4.1、one-hot词向量表示
又称独热编码,将每个词表示成具有n个元素的向量,这个词向量中只有一个元素是1,其他元素都是0,不同词汇元素为0的位置不同,其中n的大小是整个语料中不同词汇的总数。
优势:操作简单,容易理解
劣势:完全割裂了词与词之间的联系,而且在大语料集下,每个向量的长度过大,占据大量的内存。
2.4.2、Word2vec
是一种流行的将词汇表示成向量的无监督训练方法,该过程将构建神经网络模型,将网络参数作为词汇的向量表示,它包含CBOW和skipgram两种训练模式。
2.4.2.1、CBOW(Continuous bag of words)
给定一段用于训练的文本语料,再选定某段长度(窗口)作为研究对象,使用上下文词汇预测目标词汇。

2.4.2.2、 skipgram模式
给定一段用于训练的文本语料,再选定某段长度(窗口)作为研究对象,使用目标词汇预测上下文词汇。
2.4.2.3、word embedding
- 通过一定的方式将词汇映射到指定维度(一般是更高的维度)的空间、
- 广义的word embedding 包括所有密集词汇向量的表示方法,如之前学习的word2vec,即可认为是word embedding的一种
- 侠义的word embedding 是指再神经网络中加入的embedding层,对整个网络进行训练的同时产生的embedding矩阵(embedding层的参数),这个embedding矩阵就是训练过程中所有输入词汇的向量表示组成的矩阵。
3、深度学习模型
3.1、传统RNN
优势 :由于内部结构简单, 对计算资源要求低, 相比之后我们要学习的RNN变体:LSTM和GRU模型参数总量少了很多, 在短序列任务上性能和效果都表现优异.
缺点:传统RNN在解决长序列之间的关联时, 通过实践,证明经典RNN表现很差, 原因是在进行反向传播的时候, 过长的序列导致梯度的计算异常, 发生梯度消失或爆炸.
梯度消失或爆炸的危害:
如果在训练过程中发生了梯度消失,权重无法被更新,最终导致训练失败; 梯度爆炸所带来的梯度过大,大幅度更新网络参数,在极端情况下,结果会溢出(NaN值).
3.2、LSTM模型
LSTM(Long Short-Term Memory)也称长短时记忆结构, 它是传统RNN的变体, 与经典RNN相比能够有效捕捉长序列之间的语义关联, 缓解梯度消失或爆炸现象. 同时LSTM的结构更复杂, 它的核心结构可以分为四个部分去解析:
- 遗忘门
- 输入门
- 细胞状态
- 输出门
什么是Bi-LSTM ?
Bi-LSTM即双向LSTM, 它没有改变LSTM本身任何的内部结构, 只是将LSTM应用两次且方向不同, 再将两次得到的LSTM结果进行拼接作为最终输出.
LSTM优势:
LSTM的门结构能够有效减缓长序列问题中可能出现的梯度消失或爆炸, 虽然并不能杜绝这种现象, 但在更长的序列问题上表现优于传统RNN.
LSTM缺点:
由于内部结构相对较复杂, 因此训练效率在同等算力下较传统RNN低很多.
3.3、GRU模型
GRU(Gated Recurrent Unit)也称门控循环单元结构, 它也是传统RNN的变体, 同LSTM一样能够有效捕捉长序列之间的语义关联, 缓解梯度消失或爆炸现象. 同时它的结构和计算要比LSTM更简单, 它的核心结构可以分为两个部分去解析:
更新门
重置门
GRU的优势:
GRU和LSTM作用相同, 在捕捉长序列语义关联时, 能有效抑制梯度消失或爆炸, 效果都优于传统RNN且计算复杂度相比LSTM要小.
GRU的缺点:
GRU仍然不能完全解决梯度消失问题, 同时其作用RNN的变体, 有着RNN结构本身的一大弊端, 即不可并行计算, 这在数据量和模型体量逐步增大的未来, 是RNN发展的关键瓶颈.
3.4、注意力机制
3.4.1、注意力
我们观察事物时,之所以能够快速判断一种事物(当然允许判断是错误的), 是因为我们大脑能够很快把注意力放在事物最具有辨识度的部分从而作出判断,而并非是从头到尾的观察一遍事物后,才能有判断结果. 正是基于这样的理论,就产生了注意力机制.
3.4.2、注意力计算规则
它需要三个指定的输入Q(query), K(key), V(value), 然后通过计算公式得到注意力的结果, 这个结果代表query在key和value作用下的注意力表示. 当输入的Q=K=V时, 称作自注意力计算规则.
3.4.3、注意力机制的作用
在解码器端的注意力机制: 能够根据模型目标有效的聚焦编码器的输出结果, 当其作为解码器的输入时提升效果. 改善以往编码器输出是单一定长张量, 无法存储过多信息的情况.
在编码器端的注意力机制: 主要解决表征问题, 相当于特征提取过程, 得到输入的注意力表示. 一般使用自注意力(self-attention).
3.5、HMM模型
HMM(Hidden Markov Model),中文称作隐含马尔可夫模型,因俄国数学家马尔可夫而得名。它一般以文本序列数据为输入,以该序列对应得隐含序列为输出。
隐含序列:序列数据中每个单元包含得隐性信息,这些隐性信息之间也存在一定关联,如词性就是一个隐含序列。
在NLP领域,HMM用来解决文本序列标注问题。如分词,词性标注,命名实体识别都可以看作是序列标注问题。
著名的隐马尔可夫假设:隐含序列中每个单元的可能性只与上一个单元有关。
3.6、CRF模型
CRF(Conditional Random Fields), 中文称作条件随机场, 同HMM一样, 它一般也以文本序列数据为输入, 以该序列对应的隐含序列为输出.
同HMM一样, 在NLP领域, CRF用来解决文本序列标注问题. 如分词, 词性标注, 命名实体识别.
HMM与CRF模型之间差异:
HMM模型存在隐马假设, 而CRF不存在, 因此HMM的计算速度要比CRF模型快很多, 适用于对预测性能要求较高的场合.
同样因为隐马假设, 当预测问题中隐含序列单元并不是只与上一个单元有关时, HMM的准确率会大大降低, 而CRF不受这样限制, 准确率明显高于HMM.
3.7、Bert&Transformer
2018年10月,Google发出一篇论文《BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding》, BERT模型横空出世, 并横扫NLP领域11项任务的最佳成绩!
而在BERT中发挥重要作用的结构就是Transformer, 之后又相继出现XLNET,roBERT等模型击败了BERT,但是他们的核心没有变,仍然是:Transformer.
相比之前占领市场的LSTM和GRU模型,Transformer有两个显著的优势:
- Transformer能够利用分布式GPU进行并行训练,提升模型训练效率.
- 在分析预测更长的文本时, 捕捉间隔较长的语义关联效果更好.
3.7.1、Transformer架构

Transformer总体架构可分为四个部分:
1、输入部分
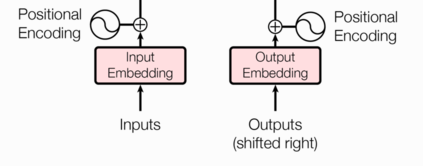
- 源文本嵌入层及其位置编码器
- 目标文本嵌入层及其位置编码器
- 无论是源文本嵌入还是目标文本嵌入,都是为了将文本中词汇的数字表示转变为向量表示, 希望在这样的高维空间捕捉词汇间的关系.
- 因为在Transformer的编码器结构中, 并没有针对词汇位置信息的处理,因此需要在Embedding层后加入位置编码器,将词汇位置不同可能会产生不同语义的信息加入到词嵌入张量中, 以弥补位置信息的缺失.
2、输出部分
输出部分包含:
- 线性层
- softmax层
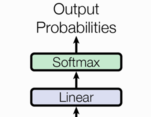
- 通过对上一步的线性变化得到指定维度的输出, 也就是转换维度的作用.
- 使最后一维的向量中的数字缩放到0-1的概率值域内, 并满足他们的和为1.
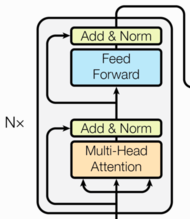
3、编码器部分
- 由N个编码器层堆叠而成
- 每个编码器层由两个子层连接结构组成
- 第一个子层连接结构包括一个多头自注意力子层和规范化层以及一个残差连接
- 第二个子层连接结构包括一个前馈全连接子层和规范化层以及一个残差连接
掩码张量的作用:
- 在transformer中, 掩码张量的主要作用在应用attention(将在下一小节讲解)时,有一些生成的attention张量中的值计算有可能已知了未来信息而得到的,未来信息被看到是因为训练时会把整个输出结果都一次性进行Embedding,但是理论上解码器的的输出却不是一次就能产生最终结果的,而是一次次通过上一次结果综合得出的,因此,未来的信息可能被提前利用. 所以,我们会进行遮掩. 关于解码器的有关知识将在后面的章节中讲解.
多头注意力机制
- 从多头注意力的结构图中,貌似这个所谓的多个头就是指多组线性变换层,其实并不是,我只有使用了一组线性变化层,即三个变换张量对Q,K,V分别进行线性变换,这些变换不会改变原有张量的尺寸,因此每个变换矩阵都是方阵,得到输出结果后,多头的作用才开始显现,每个头开始从词义层面分割输出的张量,也就是每个头都想获得一组Q,K,V进行注意力机制的计算,但是句子中的每个词的表示只获得一部分,也就是只分割了最后一维的词嵌入向量. 这就是所谓的多头,将每个头的获得的输入送到注意力机制中, 就形成多头注意力机制.
这种结构设计能让每个注意力机制去优化每个词汇的不同特征部分,从而均衡同一种注意力机制可能产生的偏差,让词义拥有来自更多元的表达,实验表明可以从而提升模型效果
规范化层
- 它是所有深层网络模型都需要的标准网络层,因为随着网络层数的增加,通过多层的计算后参数可能开始出现过大或过小的情况,这样可能会导致学习过程出现异常,模型可能收敛非常的慢. 因此都会在一定层数后接规范化层进行数值的规范化,使其特征数值在合理范围内.
前馈全连接层:
- 在Transformer中前馈全连接层就是具有两层线性层的全连接网络.
- 考虑注意力机制可能对复杂过程的拟合程度不够, 通过增加两层网络来增强模型的能力.
子层连接结构:
- 如图所示,输入到每个子层以及规范化层的过程中,还使用了残差链接(跳跃连接),因此我们把这一部分结构整体叫做子层连接(代表子层及其链接结构),在每个编码器层中,都有两个子层,这两个子层加上周围的链接结构就形成了两个子层连接结构.


4、解码器部分
解码器部分:
- 由N个解码器层堆叠而成
- 每个解码器层由三个子层连接结构组成
- 第一个子层连接结构包括一个多头自注意力子层和规范化层以及一个残差连接
- 第二个子层连接结构包括一个多头注意力子层和规范化层以及一个残差连接
- 第三个子层连接结构包括一个前馈全连接子层和规范化层以及一个残差连接
说明:
解码器层中的各个部分,如,多头注意力机制,规范化层,前馈全连接网络,子层连接结构都与编码器中的实现相同. 因此这里可以直接拿来构建解码器层.
4、NLP应用
4.1、情感分析
4.1.1、任务定义:
对带有感情色彩的主观性文本进行分析、处理、归纳和推理的过程
输入文本——> (描述实体/entity,属性/aspect,情感/opinion, 观点持有者/holder,时间/time)
昨天我买了一台新 的iphone手机, 它的触摸屏做的非 常精致炫酷
- 描述实体:iphone手机
- 属性:触摸屏
- 情感:积极
- 观点持有者:我
- 时间:昨天
4.1.2、电商评论分析

4.1.3、舆情分析

4.1.4、技术难点
- 背景知识:
- Ø 电视机的声音小(消极)
- Ø 电冰箱的声音小(积极)
- 反讽/隐晦情感表达:
- Ø 我觉得你的香水不错,你应该关起窗户省着点闻(消极)
- 网络新词:
- Ø 《觉醒时代》yyds!(积极)
4.1.5、怎么做情感分析
4.1.6、情感预训练