目录
一.前言
二.KMP算法简介
三.关键概念1:字符串的前后缀
四. 关键概念2:字符串相等前后缀与最长相等前后缀长度
五.关键概念3:Next数组
六.Next数组在算法中的应用:
七.模式串Next数组的构建

先膜拜一下三位神仙,KMP算法的三位创始人。
一.前言
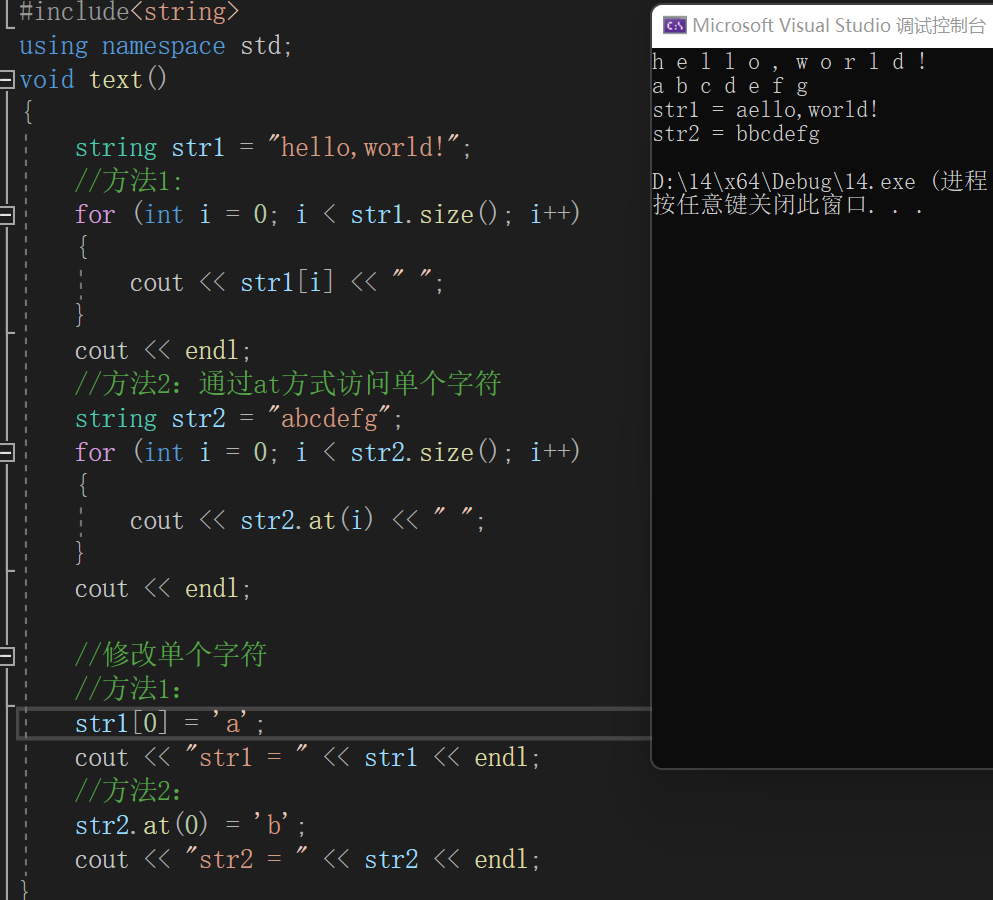
在主字符串中求子字符串(也称为模式字符串)的位置的问题中,最简单的求解方法就是用暴力匹配法,暴力匹配法也是库函数strstr的基本实现思想。
暴力匹配法的基本思路:
用两层循环来实现,外层循环用一个循环变量 i 遍历主字符串str1,每当在主字符串中找到子字符串的首元素就进入第二层循环进行两个字符串的匹配,若匹配失败,指针 i 回溯到匹配的起始位置继续寻找下一个子字符串首字符,同时 j 指针也回到子字符串的首地址,重复上述步骤。
内层循环以两个字符串的终止符或不相等的对应字符为结束标志。
匹配成功的标志是内层循环维护子串str2的指针指向子串str2的终止符。
暴力算法的动画演示:
KMP 算法讲解
代码实现:
char* my_strstr2(const char* str1, const char* str2) { assert(str1 && str2); if (!(*str2)) 如果子串为空字符串则返回主串的首地址 { return (char*)str1; } const char* pstr2 = str2; pstr1和pstr2用于内层循环进行字符串匹配 const char* pstr1 = str1; while (*str1) { pstr1 = str1; 令pstr1和pstr2指向进行字符串匹配的起始位置 pstr2 = str2; while (*pstr1 && (*pstr1 == *pstr2)) { 找到匹配过程中的终止字符或不相等的对应字符后跳出循环 pstr1++; pstr2++; if ('\0' ==*pstr2 ) 只有在匹配过程中pstr2指向子字符串终止符才算匹配成功 { return (char*)str1; } } str1++; } return NULL; } ———————————————— 版权声明:本文为CSDN博主「摆烂小青菜」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。 原文链接:https://blog.csdn.net/weixin_73470348/article/details/128588614
暴力求解的时间复杂度是O(m*n),m和n分别为主字符串和子字符串(模式串)的有效字符个数。
二.KMP算法简介
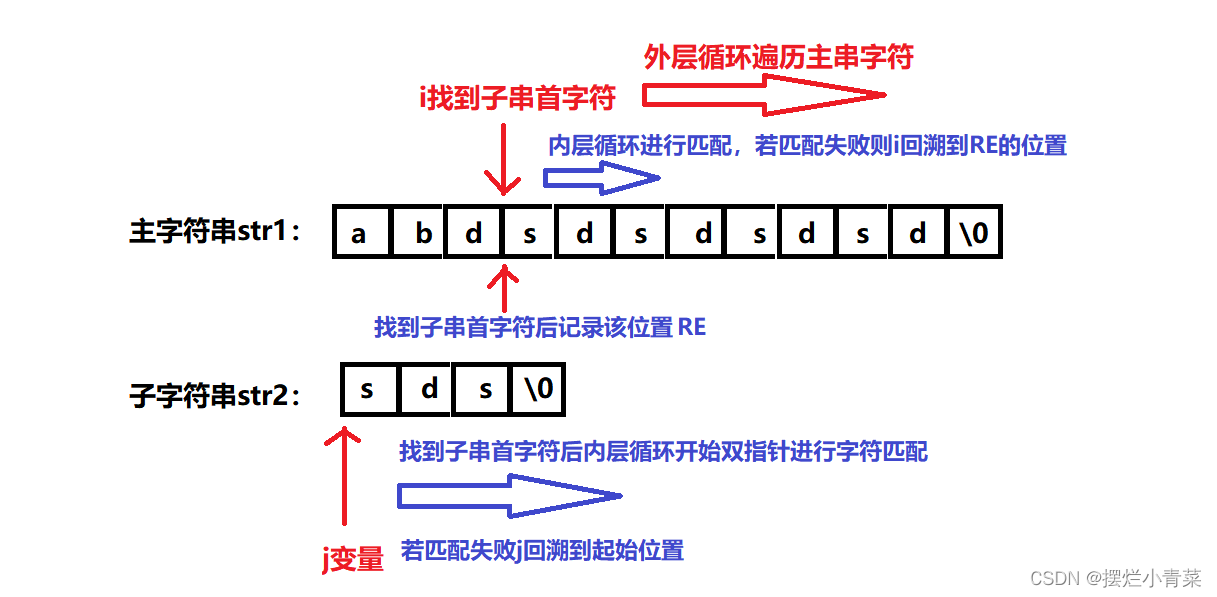
在暴力匹配算法中,每次主串和模式串匹配失败后, 维护主串和模式串的指针都要回退到匹配的起始位置。
这样的处理导致查找效率十分低下。
KMP算法在主串和模式串匹配失败时,会利用匹配过程中已经成功匹配的部分字符(上图中绿色的部分)的相关信息(字符串最大相等前后缀长度),让维护模式串的指针回退到合适的位置而维护主串的指针不进行回退操作,继续向后匹配。kmp算法中维护主串的指针只递增不回退,从而使查找的时间复杂度降为线性复杂度。
(此后统一称待查找的子串为模式串)
三.关键概念1:字符串的前后缀
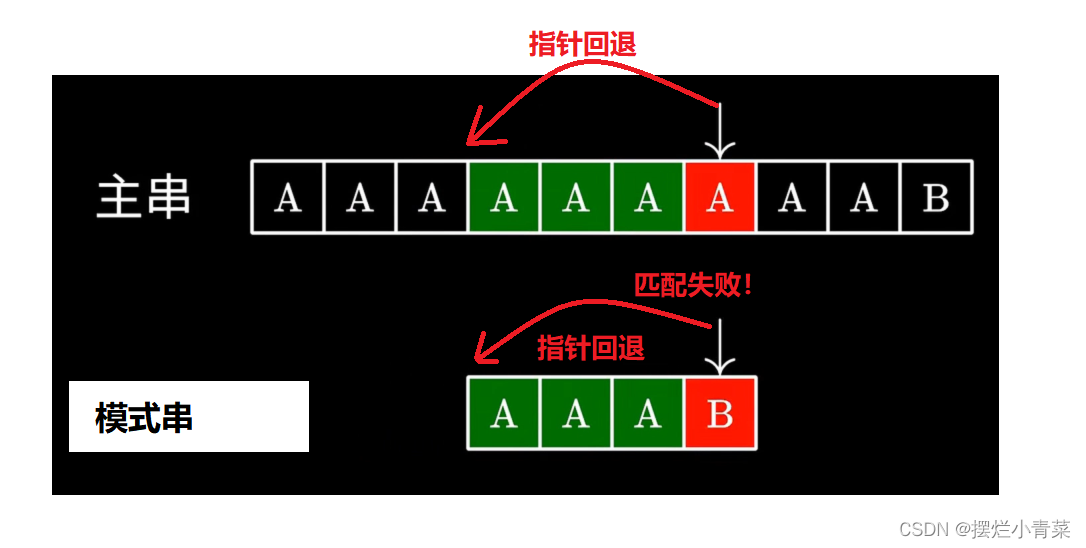
字符串的前缀:假设一个字符串的长度为n,从该字符串的第1个字符到第i个字符(其中1<=i<n)构成的子串称为该字符串的前缀。
字符串的后缀:假设一个字符串的长度为n,从该字符串的第j个字符到第n个字符(其中n=>j>1)构成的子串称为该字符串的后缀。
若使用数组下标表示字符串前后缀:
字符串的前缀:假设一个字符串的长度为n,从该字符串的第0个字符到第i个字符(其中0=<i<n-1)构成的子串称为该字符串的前缀。
字符串的后缀:假设一个字符串的长度为n,从该字符串的第j个字符到第n-1个字符(其中n-1=>j>0)构成的子串称为该字符串的后缀。

关于前后缀定义需要注意一下两点:
1.一个字符串的前后缀不包含该字符串本身
2.字符串的前缀和后缀都是从左向右读取的
四. 关键概念2:字符串相等前后缀与最长相等前后缀长度


五.关键概念3:Next数组
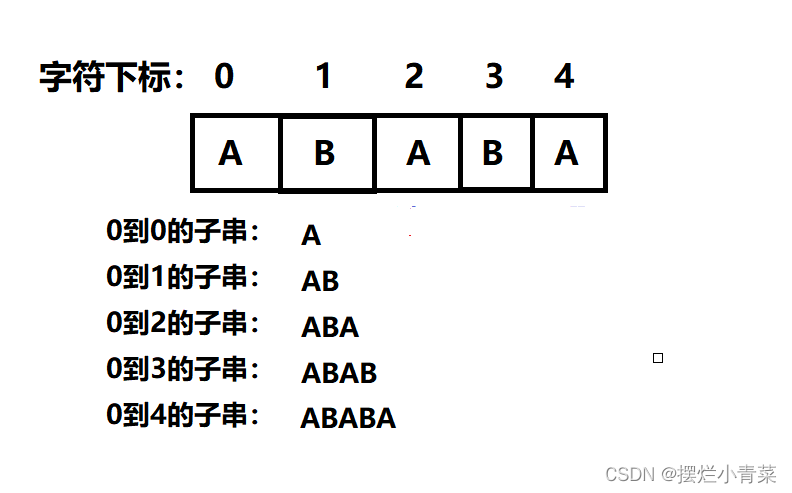
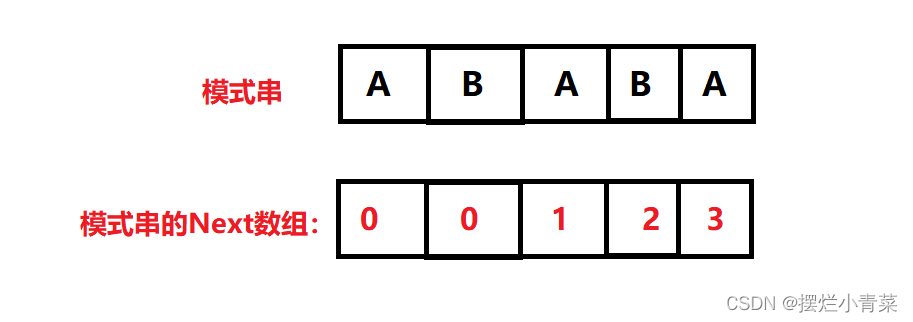
假设现在有一个模式字符串(待查找的字符串):"ABABA".
则该模式子串有4个子串分别为:
每个子串都有一个自身的最长相等前后缀长度。
(注意由于单个字符没有前后缀因此默认其最长相等前后缀长度为0)
我们将每个子串的最长相等前后缀长度存入一个命名为Next的数组中:
模式串下标0到0的子串的最长相等前后缀长度存入Next[0];
模式串下标0到1的子串的最长相等前后缀长度存入Next[1];
模式串下标0到2的子串的最长相等前后缀长度存入Next[2];
模式串下标0到3的子串的最长相等前后缀长度存入Next[3];
模式串下标0到4的子串的最长相等前后缀长度存入Next[4];
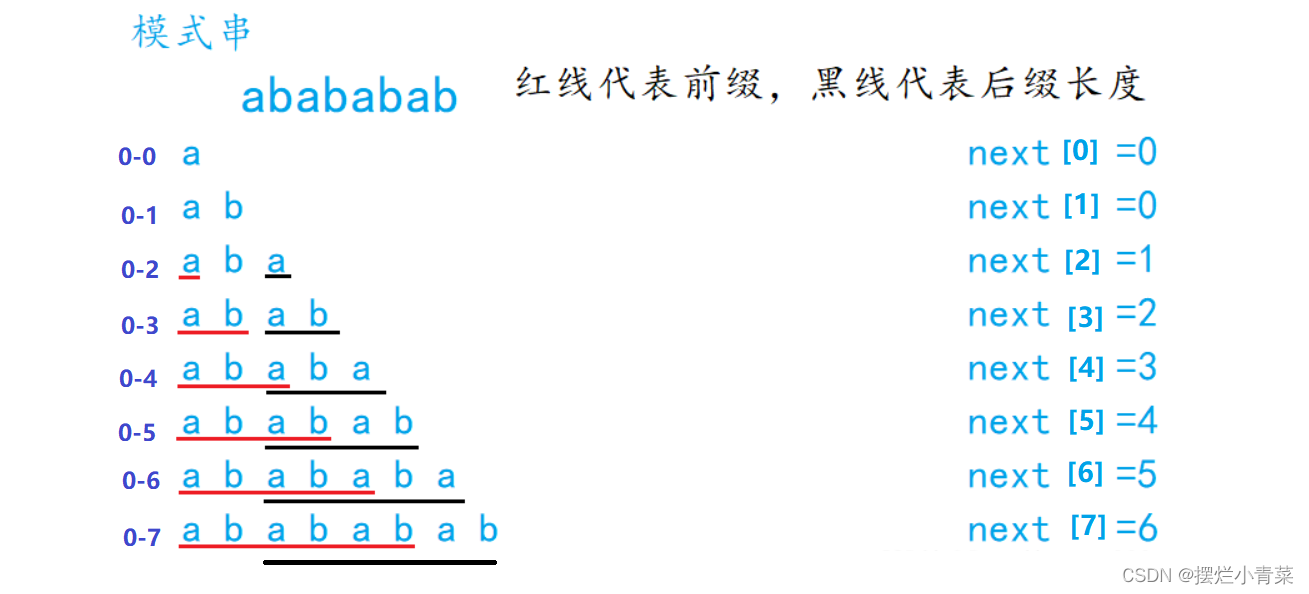
类似的实例还有:


六.Next数组在算法中的应用:
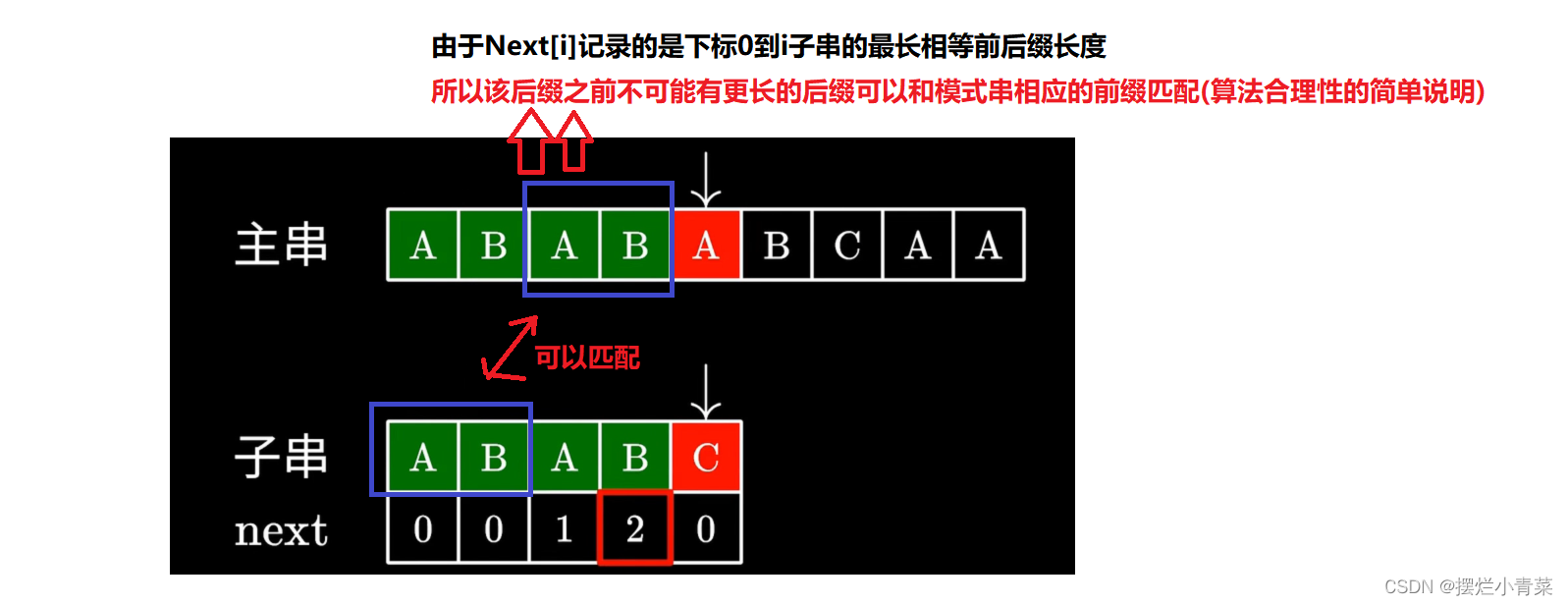
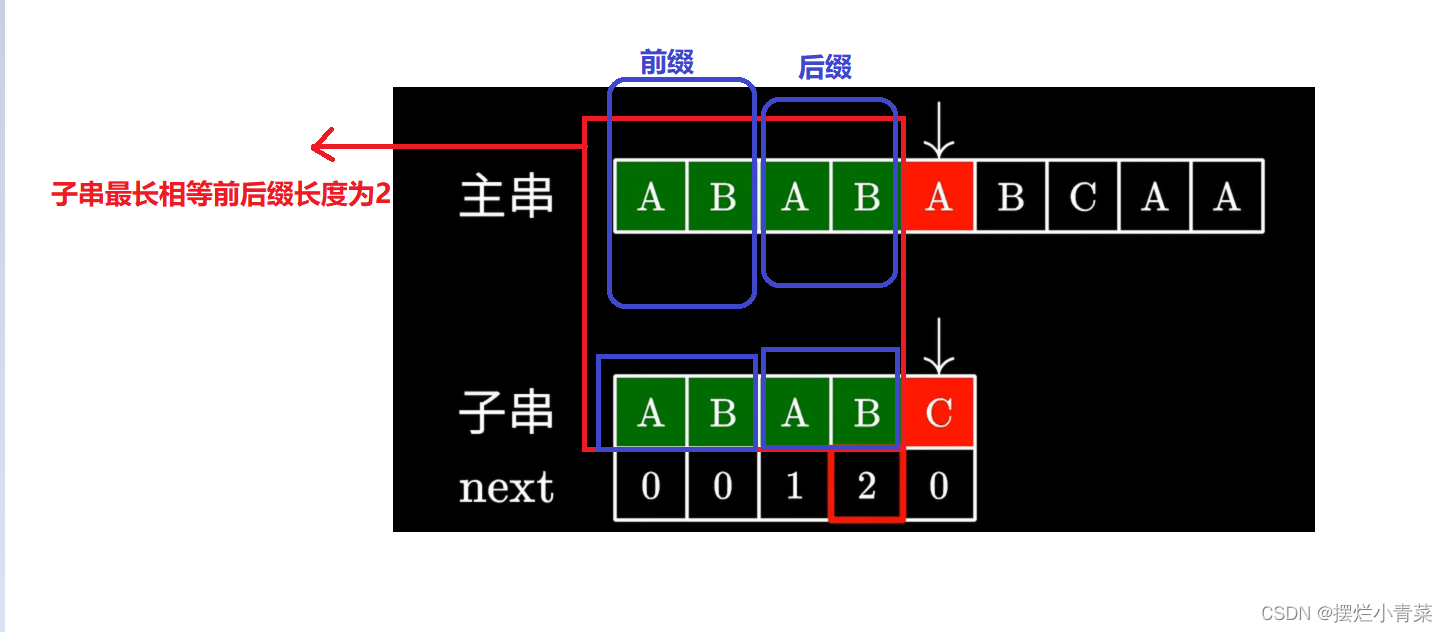
在查找主串中模式串(子串)的过程中常会有这样的情况:
主串和模式串的一部分字符已经完成匹配了,但是并没有全部匹配成功。
这时如果是暴力匹配法,维护主串的指针会回到匹配的起始位置的下一个位置接着查找匹配入口点,维护子串的指针则回到子串的起点。
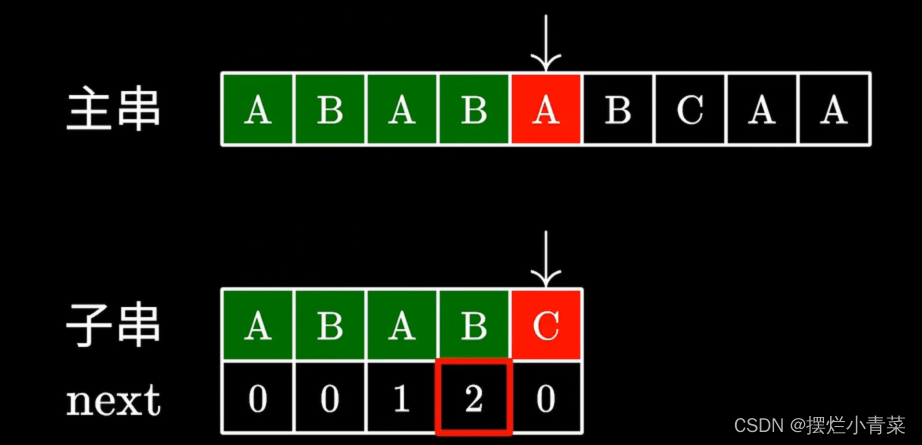
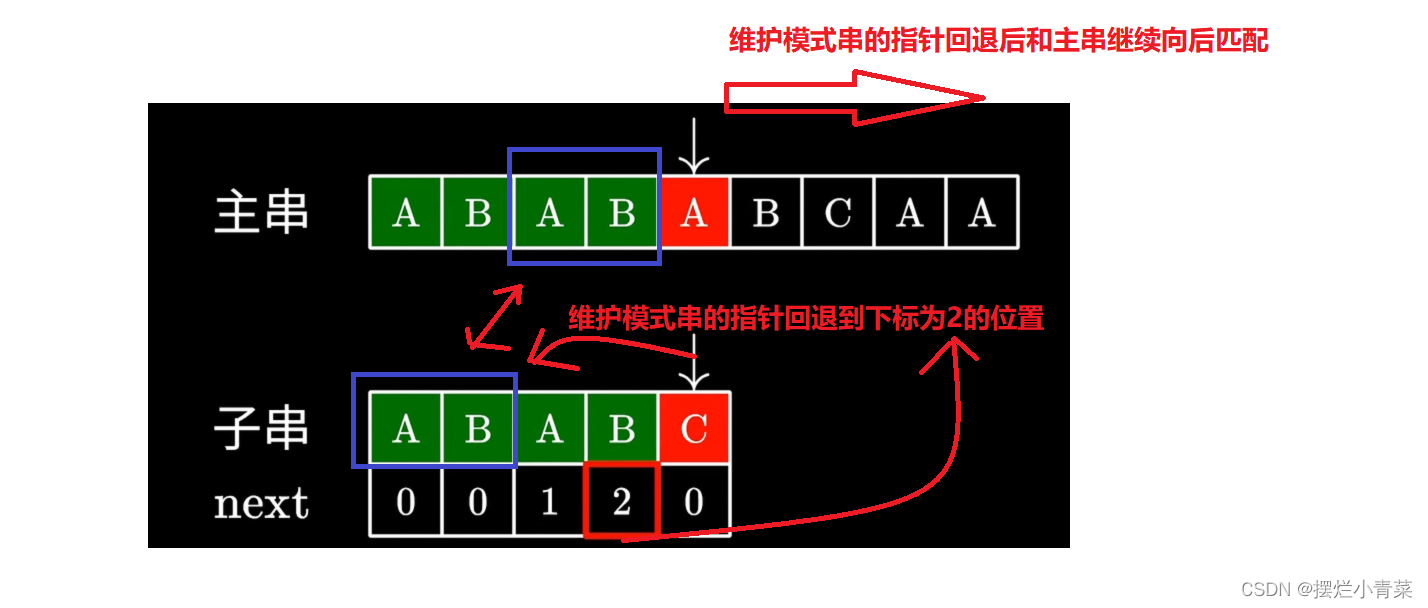
kmp算法则会根据已完成匹配的子串(比如图中模式串的0到3的子串)的最长相等前后缀长度(记录在Next数组中的对应位置),保持维护主串的指针位置不变去调整维护子串的指针位置。
算法动画:
KMP 算法讲解
KMP 算法讲解
用Next数组来查找主串中模式串的代码:
prefix是遍历模式串的变量。
i是遍历主串的变量。
mainstr是主串数组名。
modstr是模式串数组名。
kmp算法中遍历主串的指针会一直递增不回退 遍历模式串的指针在匹配失败时查Next表回退。 设计代码时保证每次循环只进行一个字符的匹配或一次prefix指针的查表回退 循环变量i每次循环最多自增一次避免越界访问的情况 prefix = 0; i = 0; while (mainstr[i]) { if (modstr[prefix] && mainstr[i] == modstr[prefix]) { prefix++; i++; } else if (!modstr[prefix]) 匹配到模式串的终止符函数返回 { return (char*)(mainstr + i - prefix); } else if(prefix) 字符不匹配且prefix不为0时,prefix指针查表回退 { prefix = Next[prefix - 1]; } else { i++; prefix查表回退到0后依然无法匹配,则i自增继续遍历主串 } } if (!modstr[prefix]) { return (char*)(mainstr + i - prefix); } else { return NULL; }
七.模式串Next数组的构建
其实Next数组的构建思路和用Next数组来查找主串中模式串的思路非常相似。
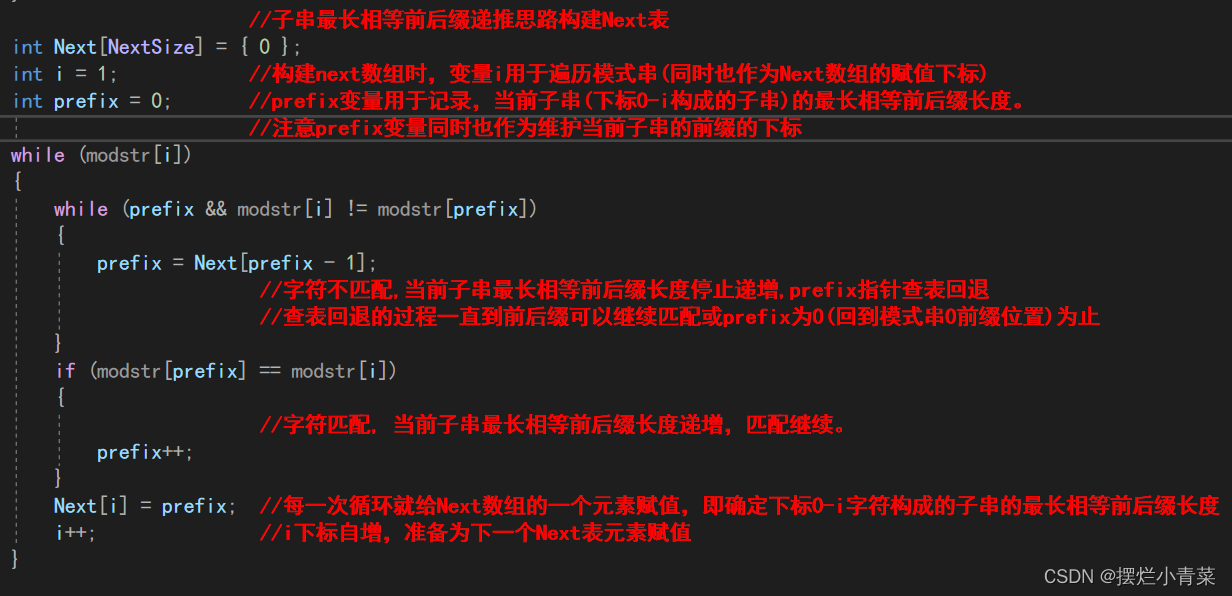
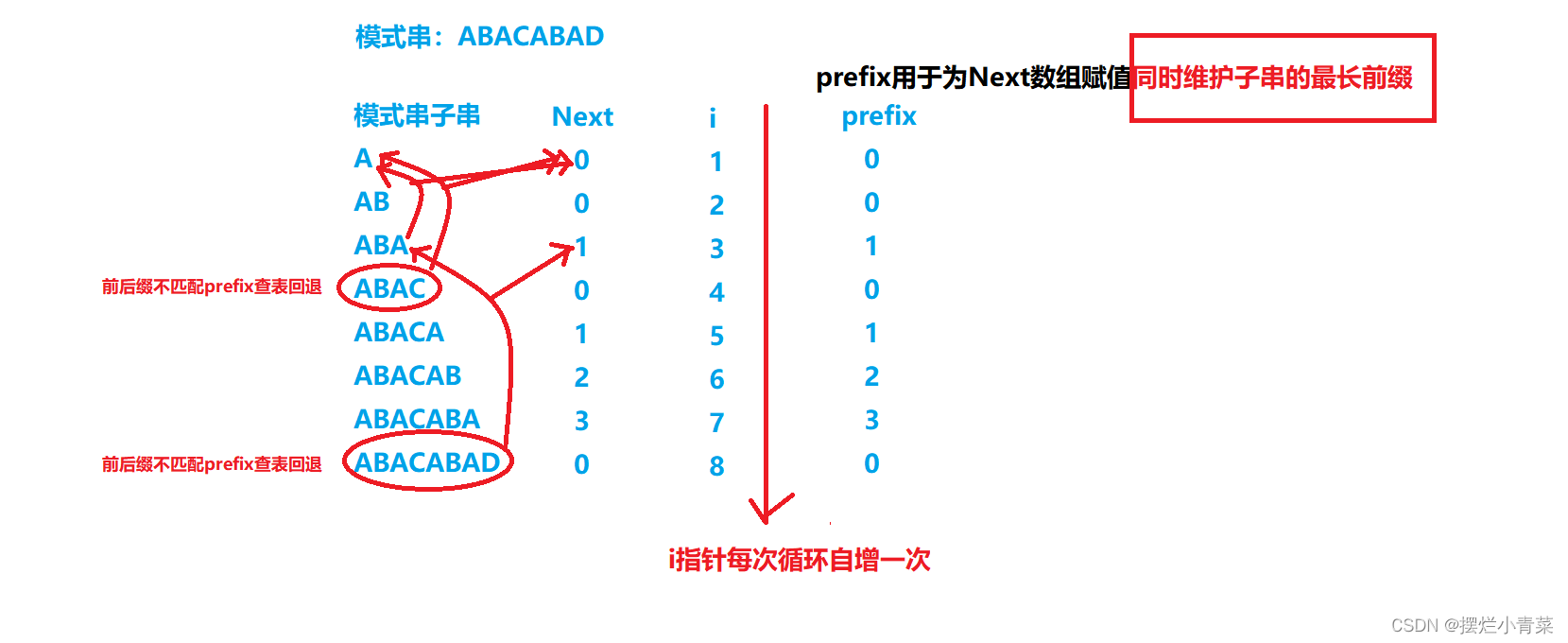
构建Next数组的核心是子串最长相等前后缀递推思路。
//子串最长相等前后缀递推思路构建Next表 int Next[NextSize] = { 0 }; int i = 1; //构建next数组时,变量i用于遍历模式串(同时也作为Next数组的赋值下标) int prefix = 0; //prefix变量用于记录,当前子串(下标0-i构成的子串)的最长相等前后缀长 //度。 //注意prefix变量同时也作为维护当前子串的前缀的下标 while (modstr[i]) { while (prefix && modstr[i] != modstr[prefix]) { prefix = Next[prefix - 1]; //字符不匹配,当前子串最长相等前后缀长度停止递增,prefix指针查表回退 //查表回退的过程一直到前后缀可以继续匹配或prefix为0(回到模式串0前缀 //位置)为止 } if (modstr[prefix] == modstr[i]) { //字符匹配, 当前子串最长相等前后缀长度递增,匹配继续。 prefix++; } Next[i] = prefix; //每一次循环就给Next数组的一个元素赋值,即确定下标0-i字符构成的子串 //的最长相等前后缀长度 i++; //i下标自增,准备为下一个Next表元素赋值 }modstr表示模式字符串数组名。
Next[0]默认等于0。
构建过程中从最短子串开始以递增的方式计算每一个子串的最长相等前后缀长度并为相应的Next数组元素赋值,若子串中的前后缀能够一直逐个字符匹配下去,则后一个子串最长相等前后缀长度就是前一个子串最长相等前后缀长度加一,若子串前后缀遇到某个字符匹配失败则prefix指针查表回退(查表回退的思路与用Next数组来查找主串中模式串的思路非常相似,利用子串的最长相等前后缀子串的最长相等前后缀长度来确定prefix回退的位置),而i指针始终递增不回退。
Next数组的生成动画演示:
KMP 算法讲解
kmp算法模拟实现字符串库函数strstr代码:
#include <stdio.h> #include <assert.h> #include <string.h> #define NextSize 100 char* kmpstrstr(const char* mainstr, const char* modstr) { if (!modstr[0]) { return (char*)mainstr; } //构建Next数组 int Next[NextSize] = { 0 }; int i = 1; int prefix = 0; while (modstr[i]) { while (prefix && modstr[i] != modstr[prefix]) { prefix = Next[prefix - 1]; } if (modstr[prefix] == modstr[i]) { prefix++; } Next[i] = prefix; i++; } //利用Next数组完成模式串查找 prefix = 0; i = 0; while (mainstr[i]) { if (modstr[prefix] && mainstr[i] == modstr[prefix]) { prefix++; i++; } else if (!modstr[prefix]) { return (char*)(mainstr + i - prefix); } else if(prefix) { prefix = Next[prefix - 1]; } else { i++; } } if (!modstr[prefix]) { return (char*)(mainstr + i - prefix); } else { return NULL; } }测试代码:
int main() { char arr1[] = "ABCABCBBCABBCBABBCBBABBCBBABBCAA"; char arr2[] = "CBBA"; char* retlib = strstr(arr1, arr2); char* retmy = kmpstrstr(arr1, arr2); if (retlib || retmy) { printf("%s\n", retlib); printf("\n"); printf("%s\n", retmy); } return 0; }

感谢观看,多多支持小青菜。