目录
前言
了解框架的概念
Spring框架
关于Spring
在Maven中使用Spring
Spring怎么管理对象
spring怎么创建对象
通过@Bean注解创建对象
通过组件扫描创建对象
关于@ComponentScan("xxxxxx")
Spring Bean的作用域
自动装配技术
什么是自动装配
补充
IoC与DI
@Qualifier注解
@Resource注解
未提到的内容
结语
前言
学过Java的小伙伴都知道,Spring框架在Java中已经不是一个简单的框架那么简单了,它是一个超级粘合平台,除了自己提供功能外,还提供粘合其他技术和框架的能力。关于其历史,博主不再介绍,今天这篇博客的作用是帮助初学者认识这个框架,了解它的基本功能,这对后续了解SSM框架乃至微服务的开发都有极其重要的作用。
了解框架的概念
框架( Framework )是构成一类特定软件可复用设计的一组相互协作的类。框架规定了你的应用的体系结构。它定义了整体结构,类和对象的分割,各部分的主要责任,类和对象怎么协作,以及控制流程。框架预定义了这些设计参数,以便于应用设计者或实现者能集中精力于应用本身的特定细节。
你可以将框架理解为现实生活中的“毛胚房”,它已经完成了住房最基础 部分的设计,例如打地基、设计住房的基本格局、预留电路、水路的线路 接入等……当你使用一个框架时,就相当于得到了一间毛胚房,如果你想住进去,你需要做的事情主要是“装修”,把这个毛胚房加工成你希望的样子。
我们可以认为框架已经帮我们做好了基础的部分。框架对我们的帮助很大,但也因此对我们造成了一定的限制。因为需要遵守框架定下来的一些规则协议。所以在学医框架时,首先要做的就是掌握框架的使用方法,这样才能达到我们预期的目标,而关于实现原理这些,可以等到彻底掌握之后再去了解不迟。
Spring框架
Spring框架主要解决了创建对象、管理对象的问题。Spring框架的核心价值在于:开发者可以通过Spring框架提供的机制,将创建对象、管理对象的任务交给Spring来完成,而开发者不必在关注这个过程,只需要在需要创建对象的时候,通过Spring来获取即可。对了,框架我们也称之为容器,所以,Spring框架也称作Spring容器,当别人在谈到容器的时候,不至于不知道说的是什么。
Spring框架很好的支持了AOP,关于AOP,这是一块比较大比较复杂的内容,所以这里暂不多做介绍,将会在后期推出专门的博客来进行说明,本篇的意义在于让大家快速的了解Spring框架,为Java入门作基础。
关于Spring
public class UserMapper {
//向用户表中中插入数据
public void insert() {
}
}这是一个mapper类,作用是来操作操作sql来执行一些增删改查的命令的,假设我们要创建一个这样的对象:
UserMapper userMapper = new UserMapper();只需要这么做就可以,但是在实际开发中,会存在类之间相互依赖的情况,一个对象可能需要被频繁创建,在客户端,我会声明一个全局变量,或者是属性,以方便在整个类中使用,在Java中我们当然希望也是这样的方式。事实上,你可以照猫画虎,也这样做,但是Java中提供了一种方式连对象初始化创建都不需要我们自己做,可以帮助我们大大提高开发的效率,而这,就是框架的好处。
比如:
public class UserController {
public UserMapper userMapper;
public void register() {
userMapper.insert();
}
}在controller中,我们要在注册的时候使用前面的那个mapper,调用insert方法插入注册的用户数据 ,userMapper需要被new出来,我们先前说了,框架提供了便捷的方式帮助我们初始化。为什么要这么做呢?如果自行创建对象,当多个类都依赖UserMapper时,各自创建UserMapper对象, 违背了“只需要1个”的思想。
在开发中,有许多类型的对象、配置值都需要常驻内存、需要有唯一性,或都需要多处使用,自行维护这些对象或值是非常繁琐的,比如单例。通过 Spring框架可以极大的简化这些操作,曾经听别人说过:Spring框架这种自动创建对象的能力也是一种“单例”,此单例非彼单例,只思想上是单例,以后有机会再讲。
在Maven中使用Spring
当使用Spring时,我们一般使用maven工程,在pom文件中添加依赖如下:
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-context</artifactId>
<version>5.3.14</version>
</dependency>版本号可按需调整。推荐大家使用旧的版本,因为相对稳定一些。
Spring怎么管理对象
spring怎么创建对象
- Spring管理对象需要先创建对象,然后spring才能获取到对象并进行管理;
- Spring管理的对象,我们称为Spring Bean;
- 创建对象我们常用两种方式:
- 通过@Bean注解
- 通过组件扫描
不懂没关系,接下来我们分别来说说他们分别是什么。
通过@Bean注解创建对象
我们先创建一个类,比如路径如下:cn.codingfire.spring.SpringBeanPro
public class SpringBeanPro {
}在类中添加方法:
@Configuration
public class SpringBeanPro {
@Bean
public Random random() {
return new Random();
}
}可自定义一个类去返回一个对象,博主懒,通过Random来做。要注意的是,@Configuration注解必不可少, 方法上的@Bean注解也必不可少,不要问为什么,因为不这么做,无法达到效果,记住即可,关于这些注解的作用,其实很难描述清楚,很多注解在不同环境下语义是不一样的,但有时候,用什么注解都是一个效果,此处可不行啊,后续会出一篇注解大全来总结介绍Java中常用的注解,请大家暂时不要纠结这些注解。
本例中:
@Configuration添加在类的生明之前,表示此类是配置类,会自动执行配置类中的@Bean方法,并解读配置类上的其他注解。
@Bean添加在配置类中用于创建对象的方法之前,使得Spring框架自动调用次方法,并管理次方法饭蝴蝶结果,@Bean方法必须存在于@Configuration注解下的类中
接着,我们需要测试我们的类是否已经被spring管理,所以,需要来测试下:
- 让Spring先跑起来,这个代码很长了,看看:
AnnotationConfigApplicationContext ac
= new AnnotationConfigApplicationContext(SpringBeanPro.class);这玩意不需要纠结,它只是用于加载Spring配置,注意,要在构造方法中添加参数,即我们的类。
- 从Spring中获取对象
Random random = (Random) ac.getBean("random");其实就是方法的名称,这里运用了反射机制,听过的大概知道原理,不懂的也不再额外介绍,嗯~大概就是通过字符串获取实体类或方法的一种机制。
- 输出测试,看看有没有获取到对象
System.out.println(random);- 结束
ac.close();以上代码,你需要知道的有三点:
- getBean方法,次方法会被重载多次:
- Object getBean(String beanName) 通过此方法,传入的beanName必须是有效的,否则将导致 NoSuchBeanDefinitionException
- T getBean(Class<T> beanClass);使用此方法时,传入的类型在Spring中必须有且仅有1个对象,如果Spring容器中没 有匹配类型的对象,将导致NoSuchBeanDefinitionException,如果有2个或更多, 将导致NoUniqueBeanDefinitionException
- T getBean(String beanName, Class<T> beanClass) ;此方法仍是根据传入的beanName获取对象,并且根据传入的beanClass进行类型转换
- 两个注解,缺一不可,有意思的是,@Configuration注解并不是必须的, 但@Bean方法的使用规范是将其声明在@Configuration类中
- 使用的@Bean注解可以传入String类型的参数,如果传入,则此注解对应的方法的返回结果的beanName就是@Bean注解中传入的String参数值,后续调用getBean() 方法时,如果需要传入beanName,就应该传入在@Bean注解中配置的String参数值,而不是方法名
@Configuration
public class SpringBeanPro {
@Bean("random")
public Random xxxxx() {
return new Random();
}
}通过组件扫描创建对象
话不多说,直接上代码:
package cn.codingfire.spring;
import org.springframework.stereotype.Component;
@Component
public class UserMapper {
}package cn.codingfire.spring;
import org.springframework.context.annotation.ComponentScan;
import org.springframework.context.annotation.Configuration;
@Configuration
@ComponentScan("cn.codingfire.spring")
public class SpringConfig {
}接着进行测试,和上面其实是一样的:
AnnotationConfigApplicationContext ac = new AnnotationConfigApplicationContext(SpringConfig.class);
UserMapper bean = ac.getBean(UserMapper.class);
System.out.println(bean);
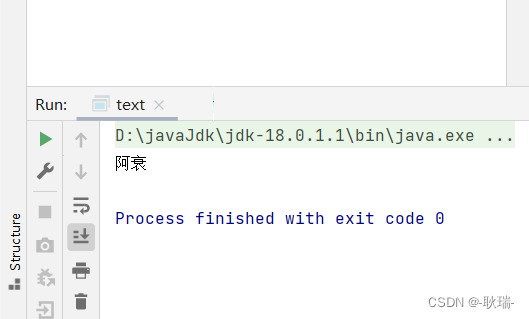
ac.close();刚刚没有把跑的结果贴出来,这里贴出来给大家看看:
cn.codingfire.spring.UserMapper@52aa2946
Process finished with exit code 0可以看到获取到的对象是真实存在的。 这里对关键部位做个说明:
@ComponentScan注解是执行组件扫描的关键,当创建AnnotationConfigApplicationContext对象时,传入的SpringConfig配置类添加了这个注解,Spring框架就会扫描配置下的包中的所有组件类,然后为组件创建对象并管理,而UserMapper类必须在@ComponentScan注解配置的包中,否则Spring框架找不到这个类,无法创建对象。@Component仅表示此类是一个组件类,但也很重要,没有此注解,将不会创建此对象。
@ComponentScan("cn.codingfire.spring")相当重要,这是扫描的路径,如果括号中内容变成,cn.codingfire,它下面有这些包:cn.codingfire.spring,cn.codingfire.controller,cn.codingfire.mapper,cn.codingfire.pojo等等,这些包统统都会被扫描到,这一点要注意,不要扫描不需要的包,对性能是有影响的。
另外,前面说过getBean扫描的方式,这里再次重申一遍:不指定beanName,默认的beanName都是类的首字母小写的名字,仅适用于类名中的第1个字母是大写,且第2个字母是小写的情况,否则,将传入完整的类名。一般我们指定beanName多一些,会更安全。
为@Component注解指定beanName案例:
@Component("userMapperBeanName")关于@ComponentScan("xxxxxx")
我们点进去看下源码:
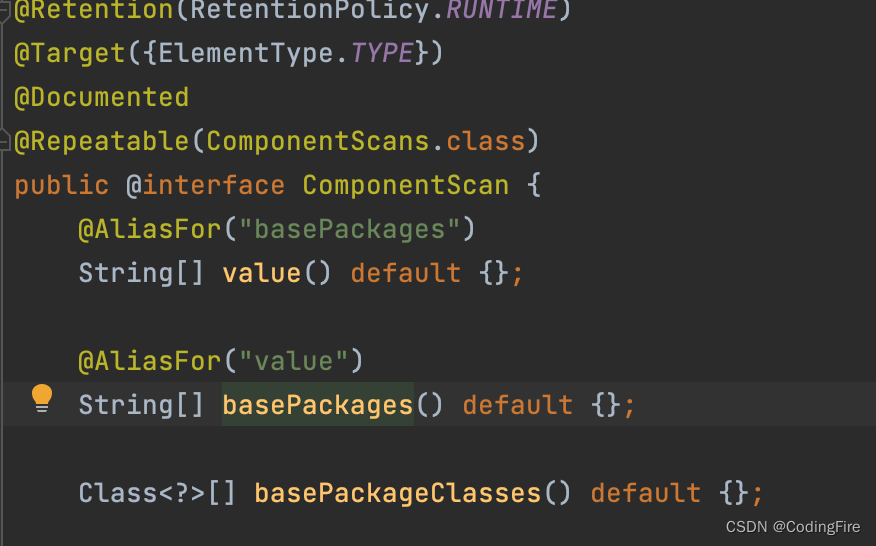
可以知道@ComponentScan("xxxxx")中的参数,如果传一个,可以不显示的指定默认参数名:value,如果需要配置多个属性,需要显示指定。
传入多个参数时,比如要扫描多个包的情况,我们看到
String[] value() default {};
说明它是一个数组类型的,可以传多个包名,但需要使用大括号:
@ComponentScan({"xxxxx"})
Spring Bean的作用域
前面提到,Spring这种创建管理对象的方式很像单例,所以:
- 我们通常认为,Spring Bean的作用域是单例的
- 单例的特点是:实例唯一,任何时候,类的实例对象只能有一个,创建出来后,需常驻内存,直到程序运行结束或者ApplicationContext调用了销毁的方法
- 上面也提到过,此单例非彼单例,莫要混为一谈,只是作用域的表现完全和单例一致
那么作用域是否可以修改呢?答案是肯定的。通过在@Bean注解之前添加过@Scope注解来改变其作用域,作用域有三类,默认是单例的:
- singleton:单例的,这是默认值,在scopeName属性的源码上明确的说明了:Defaults to an empty string "" which implies ConfigurableBeanFactory.SCOPE_SINGLETON
- prototype:原型,也就是非单例的
- 还有其它取值,都是不常用取值,可不用关心,自定了解即可
Spring Bean是预加载的,关于此,我们知道的还有一个懒加载,通过@Lazy来表示,如必要,可创建为懒加载的。@Lazy注解的value属性是boolean类型的,表示“是否懒加载” 。
预加载何懒加载,我不说,大家也应该知道这是什么意思,在其他语言中,我们很多时候使用懒加载来降低资源的损耗,但是在Java中略有不同,为了避免高并发时懒加载去创建对象出现问题,我们通常在Java只能够采用预加载的方式。
自动装配技术
什么是自动装配
Spring的自动装配是,当某个量需要被赋值时,可以使用特定的语法,使得Spring尝试从容器找到合适的值,并自动完成赋值其中最典型的代表是@Autowired注解,Spring会尝试从容器中找到生明的对象并初始化来为此属性赋值。
举个例子:
package cn.codingfire.spring;
import org.springframework.context.annotation.ComponentScan;
import org.springframework.context.annotation.Configuration;
@Configuration
@ComponentScan("cn.codingfire.spring")
public class SpringConfig {
}package cn.codingfire.spring;
import org.springframework.stereotype.Component;
@Repository
public class UserMapper {
public void insert() {}
}package cn.codingfire.spring;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Controller;
@Controller
public class UserController {
@Autowired //使用了自动装配的注解
private UserMapper userMapper;
public void registor() {
userMapper.insert(); //这里调用了userMapper属性的方法
}
}看到没?看到没?userMapper我们没有自己初始化,但我就是可以在注册方法中使用它的insert方法,有点小激动,有木有?
测试部分不再贴了,大家可以复制代码自行尝试下,注意包名,千万要写自己的包名,也可以按照博主的包名来创建。
关于@Autowired注解,作用就是自动装配,体现为,当某个属性需要被Spring注解装配值时,在属性之前添加此注解,另外,此注解可以添加在setter方法,构造方法之前,用于在存在多个构造方法的情况下,执行加了此注解的方法,这里也不再多讲了,等你成为一只老鸟,你会在很多地方看到这种用法,但通常我们不需要这么做。
对方法的参数自动装配时,如果方法有多个参数,各参数的先后顺序是不重要的。
关于@Autowired的装配机制,它会根据需要装配的数据的类型,在 Spring容器中统计匹配的Bean(对象)的数量 。
当匹配的Bean数量为0个时,判断@Autowired注解的required属性值,true(默认):装配失败,启动项目时即抛出NoSuchBeanDefinitionException,若是设置为false:放弃自动装配,不会报告异常,使用此属性时,会出现NPE ,即null异常。
当匹配的Bean数量为1个时,将直接装配,并装配成功。
当匹配的Bean数量为多个时:自动尝试按照名称实现装配,存在与属性名称匹配的Spring Bean时装配成功,不存在时装配失败,会抛出NoUniqueBeanDefinitionExcept。
补充
IoC与DI
IoC(Inversion of Control:控制反转)是Spring框架的核心,在传统的开发模式下,是由开发者创建对象、为对象的属性赋值、管理对象的作 用域和生命周期等,所以,是开发者拥有“控制权”,当使用了Spring之 后,这些都交给Spring框架去完成了,开发者不必关心这些操作的具体实现,所以,称之为“控制反转” 。
DI(Dependency Injection:依赖注入)是Spring框架实现IoC的核心实现,当某个类中声明了另一个类的属性(例如在UserController类中声明 了UserMapper类型的属性),则称之为依赖(即UserController依赖了 UserMapper),Spring框架会帮你完成依赖项的赋值,称为注入。
@Qualifier注解
此注解用于在自动装配中指定beanName,在同时存在多个类型匹配的bean时才会用得到,一般来说,我们不太会让这种情况发生,谁也不想给自己找事不是?具体表现为:
@Controller
public class UserController {
@Autowired
@Qualifier("userMapper")
private UserMapper mapper;
public void registor() {
mapper.insert();
}
}这里要解说下,自动装配,Bean注解这些,名字是有要求的,要和类名的首字母小写后一致,若是我不想用呢?就可以用mapper,但是我通过Qualifier注解来指定正确的名字,这样也是可以的。总感觉这么做会比较累,大家看看就好,实际开发中不要这么做,把自己搞乱了就不好了。
@Resource注解
先尝试根据名称进行装配(即:要求属 性名称与beanName相同),如果失败,则尝试根据类型装配,如果不存此在类型的Bean,则抛出NoSuchBeanDefinitionException,如果只有1 个匹配类型的Bean,则装配成功,如果匹配类型的Bean超过1个,则抛出NoUniqueBeanDefinitionException。
这里说的都是特殊情况,实际开发中,其实很难出现两个相同的Bean,我们不会给自己找不痛快。
和@Autowired,@Resource区别:
- @Autowired可以添加在构造方法的声明之前,@Resource不可以
- @Resource可以添加在类的声明之前(但不会装配属性的值),@Autowired不可以
- 如果有多个同类型的Bean时,@Autowired需要通过@Qualifier指定beanName,而@Resource可以 直接配置name属性以指定beanName。
- 当装配方法的参数时(例如添加了@Autowired的构造方法的参数),@Autowired仍可使用@Qualifier指定beanName,而@Resource无法解决此问题
未提到的内容
阿西吧,写了好久啊,感觉还是有些遗漏的,后续博客慢慢补充吧。遗漏部分,个人认为比较重要的:
- AOP
- Spring Bean生命周期
还有一些细碎的知识,后续的内容中都会根据实例进行说明,这里两块内容其实很大很多,结合实例来说比较好,暂时不在这里进行说明,掌握了这些,Spring框架你已经可以使用一些基础功能了。
结语
可能在所有的写Spring的博主中,我写的不是最好的,但我也是一步步学的Java,也经历过从什么都不懂到上手写项目。道路千条万条,适合自己的才是最好的。这些内容只是Spring的基础,等你真正开始写项目后,你会发现,这些东西都是最最基础的东西,很常用,也很简单。