分布式ID生成策略-雪花算法Snowflake
- 一、其他分布式ID策略
- 1.UUID
- 2.数据库自增与优化
- 2.1 优化1 - 共用id自增表
- 2.2 优化2 - 分段获取id
- 3.Reids的incr和incrby
- 二、雪花算法Snowflake
- 1.雪花算法的定义
- 2.基础雪花算法源码解读
- 3.并发1000测试
- 4.如何设置机房和机器id
- 4.雪花算法时钟回拨问题
这里主要总结雪花算法,其他的分布式ID策略不常用,这里简要描述,而且各大公司生产基本都是选择雪花算法,所以这里针对雪花算法进行详细解读,其他常见的分布式id策略则只做简略描述。
一、其他分布式ID策略
分布式ID是分布式架构中比较基础和重要的场景,好的分布式ID策略可以提供更强大的并发,保障业务的正常展开。各大公司最为常用的是雪花算法,和在雪花算法基础上进行改进的算法,当然也有其他的比如数据库自增等,这里先对其他分布式ID策略的简述,这样才能更清晰比对和雪花算法的差异。
1.UUID
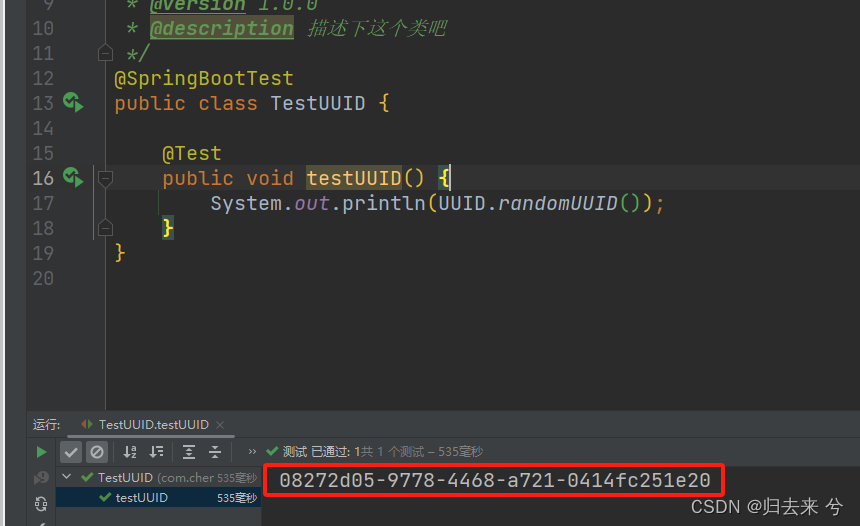
UUID是一串32个字符,128位的随机字符串。UUID在数据库比较小并发量不高的服务中使用是完全可以的,他的最大的特点就是简单易用,使用简洁,对于数据量不大的系统推荐使用,比如OA等公司内部系统。JDK自带UUID的api,可以直接使用:
package com.cheng.common.snowflake.api.test;
import org.junit.Test;
import org.springframework.boot.test.context.SpringBootTest;
import java.util.UUID;
/**
* @author pcc
* @version 1.0.0
* @description 描述下这个类吧
*/
@SpringBootTest
public class TestUUID {
@Test
public void testUUID() {
System.out.println(UUID.randomUUID());
}
}
只需要上面一行简单的代码就可以获取到UUID了,使用起来可以说是非常简单了。
优点:简单易用、生成效率高
缺点:字符串随机生成,当数据量特别大时使用mysql数据库,插入效率会比较低下,原因是因为Mysql的索引是B+Tree,B+Tree所有数据都存储在叶子节点上,且按顺序排列,若是随机字符串会增加寻址成本,造成插入效率低下,因为是随机字符串在进行范围查询时索引效率也很低下。
使用总结:不推荐使用,如果用只能用在数据量比较小的服务,这是一个悖论,数据量小也没有必要使用分布式服务分布式id了,直接使用数据库自增就行,所以这里不推荐使用。
2.数据库自增与优化
这里的数据库自增就是指数据库的auto_increment,当我们为主键设置auto_increment时,那么这个主键就会随着表记录创建而填充且id是逐个递增的,数据量不大的情况是是完全可以使用这种方式的,但当有分库分表时,数据量和并发量大时数据写入就会变慢,因为首先单库的并发量是有限的,其次单表数据量增大后单表操作就会越来越慢,也会影响性能,所以需要对数据库进行垂直和水平拆分(分库分表)。
2.1 优化1 - 共用id自增表
上面的数据库自增很显然在分库分表时是无法满足数据库id唯一且自增的,因为是多个库多个表,所以这里需要进行优化,优化的方式也比较简单,就是单独使用一个表来维护id,数据插入之前通过这个表来分配数据库的id。这样就可以保证多个库多个表的主键的不冲突了,但当并发量继续增高时,即使这个表单独只做id分配也会吃力,此时还需要为这个表提供优化,此时还可以考虑将这个表所在的库做主-主的设置,来提升并发能力。
那这个优化的核心其实就是获取id的这个表了。这种方式会将表结构设置为如下:
CREATE TABLE `gene_id` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`stub` varchar(255) DEFAULT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `stub` (`stub`)
);
这里需要注意两点:
- 主键需要自增AUTO_INCREMENT,因为id需要靠这个表来维持,所以需要设置id自增
- stub需要唯一约束,这个字段是需要根据值进行替换达到id自增的目的的辅助列,所以需要唯一约束(根据唯一值进行替换)。
表结构出来以后,需要处理的是如何正确的自增id,网上的说法都是使用这个:
BEGIN;
REPLACE INTO gene_id (stub) values ('stub');
SELECT LAST_INSERT_ID();
COMMIT;
这里简单说下这个sql,REPLACE INTO的作用是如果存在则删除重新插入,如果不存在则直接插入。所以可以实现id主键的自增。LAST_INSERT_ID则是msyql内置的方法可以获取到上一次增加的id,使用这种方式可以一次获取到我们想要的id
思考:这个获取id的方式会不会存在幻读问题
假如我们不使用上面这个方式获取id,我们使用的是select 通过id倒排获取最大id是很可能会出现幻读的问题的,幻读就会导致大家可能获取的id是同一个,从而出现了数据id的重复。那这里会不会呢,这里其实是不会的,因为使用的是LAST_INSERT_ID,这个方法只会返回当前事物中新增的id,对于其他事务的新增id并不会返回,所以不会有幻读的问题,所以使用这种方式获取自增的id才是正确的姿势。
2.2 优化2 - 分段获取id
上面的2.1 其实还可以继续优化,而且这里的优化也是美团实际在用的,废话不多说,如何优化呢?核心思想就是减少和数据库的交互,从而提升性能,现在是获取一次id就需要和id管理表交互一次,优化的思想是分段获取id,比如一次获取1000个id,那么就可以减少获取id数量的999次交互,而获取到的1000个id可以放入到内存中,当需要时从内存中获取id,这样无疑会提升很多性能。
这种方式也可能会面临临界点时id获取多线程阻塞问题,可以通过提前加载的方式来解决这种问题。
3.Reids的incr和incrby
Redis因为真正执行CRUD的操作是单线程,所以他的操作是原子性的,此时我们可以利用他的命令incr(redis的++操作),incrby(incrby key 10意思是将key的值增加10),这种命令来实现和数据库类似的id的自增,而且redis也是支持持久化的,我们可以同时开启redis的rdb和aof来保证数据的不丢失。而且redis本身也是支持高并发的,对redis进行集群扩展也比较方便,所以使用redis也是可以的。
二、雪花算法Snowflake
1.雪花算法的定义
雪花算法最早由Twitter开源,用于产生一个64bit的整数(换算成10进制则是19位)。同时64bit在java中正好是long的长度(long是8字节,一字节是8bit),在数据库mysql中正好是BIGINT的长度。在雪花算法中64bit的整数被划分了4部分:1位符号位+41位时间戳位+10位机器位+12位随机数位,如下:

-
1位符号位:
二进制数据中首位表示正负,这里是0不可变 -
41位的时间戳:
41位用来标识时间戳,最大值是2的41次方-1为:2199023255552,转换成时间戳的话是2039-09-07 23:47:35,所以这个41为的时间戳如果不特殊处理可以表示最大的范围就是到2039年(从1970年算是69年),

2039年对于大部分公司来说肯定是不行的(不能说用到2039年就不用了吧)所以一般这个41位的时间戳不会直接用当前的时间戳来直接填充,而是使用当前时间戳减去一个默认的时间戳这样就可以获得更大的表示范围了,这个默认的时间戳通常是系统的上线时间,假如系统上线时间是2024年3月1号,根据上面的69年的表示范围那么这个分布式id的时间范围就可以表示到2093年。2093年对于任何公司来说都是可用的了,尚不说公司能不能存在到那时候,即使存在了系统肯定也早需要重构了,不会有任何系统给你用这么久的。
-
10位的机器位:
机器位最大为10位,一般做法是5位用于机房id的标识,5位用于机器id的标识。这样无论是机房和机器都可以最大容纳2的五次方减1(31)的数量。不过实际使用时可以根据实际情况进行调整,因为机房数量一般也到不了31,就是机器数量到达31的也不多。所以可以根据实际情况来进行调整机器位10个bit的分配。 -
12位的随机数:
12位的随机数最大可以表示2的12次方减1的数据(4095)所以也就是说最大我们可以在1ms内产生4095个id(时间戳位是ms),那么1s内就是4095000≈400W。而且这是单台机器上的每秒可产生的不重复id,如果横向扩展机器的话,这个值还会更大。所以12位的随机数位是肯定够用的了,当然真正使用时是不能使用随机数的,而是应该进行整数的自增,这样才能保证不重复。
总结一句话就是雪花算法是一个可以在单机每秒钟最高产生400w不重复id的id生成算法(假如机器性能扛得住)。在横向扩展后这个值会更大,如果是3台机器则是1200w,所以分布式id基本上可以适用任何并发场景。
2.基础雪花算法源码解读
雪花算法并不难,只需要知道生成策略其实大部分人应该都是可以写出来的,所以说最重要的一直不是动手的能力而是你思维的能力,可以做到的远比可以想到的要多得多。
package com.cheng.ebbing.message.snowflake;
import java.util.concurrent.ConcurrentHashMap;
/**
* @author pcc
* @version 1.0.0
* @description 雪花算法生成id
*/
public class SnowflakeIdGenerator {
// 起始的时间戳
private final long twepoch = 1288834974657L;
// 每一部分占用的位数
private final long workerIdBits = 5L;
private final long datacenterIdBits = 5L;
private final long sequenceBits = 12L;
// 每一部分的最大值
private final long maxWorkerId = -1L ^ (-1L << workerIdBits);
private final long maxDatacenterId = -1L ^ (-1L << datacenterIdBits);
private final long maxSequence = -1L ^ (-1L << sequenceBits);
// 每一部分向左的位移
private final long workerIdShift = sequenceBits;
private final long datacenterIdShift = sequenceBits + workerIdBits;
private final long timestampLeftShift = sequenceBits + workerIdBits + datacenterIdBits;
// 记录上一次生成ID的时间戳
private long lastTimestamp = -1L;
// 0,并发控制
private long sequence = 0L;
private final long workerId;
private final long datacenterId;
public SnowflakeIdGenerator(long workerId, long datacenterId) {
if (workerId > maxWorkerId || workerId < 0) {
throw new IllegalArgumentException("Worker ID can't be greater than " + maxWorkerId + " or less than 0");
}
if (datacenterId > maxDatacenterId || datacenterId < 0) {
throw new IllegalArgumentException("Datacenter ID can't be greater than " + maxDatacenterId + " or less than 0");
}
this.workerId = workerId;
this.datacenterId = datacenterId;
}
public synchronized long generateId() {
long timestamp = timeGen();
// 时钟回拨直接异常
if (timestamp < lastTimestamp) {
throw new RuntimeException("Clock moved backwards. Refusing to generate id for " + (lastTimestamp - timestamp) + " milliseconds.");
}
if (timestamp == lastTimestamp) {
// 按位与只要都为1才为1否则为0
// 4095的十进制数在二进制中表示为111111111111,而4096的十进制数在二进制中表示为1000000000000。
sequence = (sequence + 1) & maxSequence;
if (sequence == 0L) {
// 当前毫秒的序列号已经用完,等待下一毫秒
timestamp = tilNextMillis(lastTimestamp);
}
} else {
// 不同毫秒内,序列号重置为0
sequence = 0L;
}
// 记录上一次生成ID的时间戳
lastTimestamp = timestamp;
// 计算时间戳左移22位,加上数据中心ID左移17位,加上机器ID左移12位,加上序列号
return ((timestamp - twepoch) << timestampLeftShift) |
(datacenterId << datacenterIdShift) |
(workerId << workerIdShift) |
sequence;
}
private long tilNextMillis(long lastTimestamp) {
long timestamp = timeGen();
while (timestamp <= lastTimestamp) {
timestamp = timeGen();
}
return timestamp;
}
private long timeGen() {
return System.currentTimeMillis();
}
}
上面是一个雪花算法的生成源码很简单,应该是一看就懂了,唯一可能需要说的是生成id的时候这个对于位运算和按位或操作不熟悉的可能有些懵,之类简单说下。二进制的位运算可以类比十进制的乘以10的操作,假如11(十进制的3)这个二进制数左移两位则表示在末尾添加两个00,也就是1100(十进制12),不清楚的这么记就行。而按位或则是对比操作的两个数的相同位,有一个为1则记为1,否则为0,这里左移以后末尾补零,左移按位或就可以理解为10进制的加法了,相同与有一个10禁止的1乘以100以后,在他的个位和10位上进行加数。
3.并发1000测试
这里使用1000个线程并发来压测,其实肯定不会有重复的,这里将产生的id放入到ConcurrentHashMap的key中,如果最后key的数量和线程数保持一致,则说明这个源码没有问题:
// 示例用法
public static void main(String[] args) {
// 数据中心ID和机器ID分别为1和1
SnowflakeIdGenerator idGenerator = new SnowflakeIdGenerator(1, 1);
// 用于存放产生的id
ConcurrentHashMap<Long, Long> ids = new ConcurrentHashMap<>();
// 假设有1000个线程同时生成id,那么这时候测试下是否有重复的id
for (int i = 0; i < 1000; i++) {
new Thread(
()->{
ids.put(idGenerator.generateId(),1L);
}
).start();
}
// 等待所有线程执行完毕
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
// 如果重复,那么肯定是小于线程数的
System.out.println("生成的id数量:" + ids.size());
}
测试结果自然是和我们声明的线程量是一致的。
生成的id数量:1000
进程已结束,退出代码0
上面的id生成例子用起来其实没啥大问题,但一般也不会直接用,还需要考虑如下一些场景的适配。
4.如何设置机房和机器id
这里得机器id和机房id都是通过传入的,那生产环境该如何定义这个值呢,主要是两种方案:
- 1.通过注册中心定义
分布式id的服务如果有多个,可以都注册到注册中心里,在服务启动后获取所有实例,根据实例ip进行排序然后分配机器id和机房id。 - 2.服务器直接定义
也可以直接在机器上定义一个变量,项目中根据服务器上定义的变量定义机器id和服务器id,springboot配置文件中使用${workid}这种方式来获取机器上定义的环境变量。
4.雪花算法时钟回拨问题
时钟回拨问题是指,单台机子上时间出现回退导致id出现重复的问题,可以说只要时间回退了id重复的概率基本是99%了,此外不要想着时间回退不容易碰到,这个基本都会碰到。有以下几种可能会出现时间回退:
- 1.润秒:
世界时间(国际原子时)与地球自转时间(世界时)之间存在微小差异。为了使时间保持同步,国际原子时不时地进行调整,即通过插入或删除“润秒”(leap second)来实现,这种如果是删除就会导致时间回退。 - 2.时间漂移
服务器因硬件、温度问题导致的时间不一致 - 3.时间同步问题
每个电脑都不是和标准时间实时同步的,都是间隔一段时间去同步一次,这个时间也是可能出现回退的。 - 4.手动调整
这种也有可能发生,服务器管理员进行了手动调整,且时间向后调整了
所以说时间回退是很可能会碰到的,这个问题也是必须要解决的,而上面的代码是没有解决这个问题的。时间回退造成的问题是出现了相同的时间戳,而因为是同一台机器同一个机房所以id重复概率很高。下面来说下通常解决时间回退问题的解决方案。
- 方案一:阻塞等待
这个适合时间回退没有太久时,可以在上面代码中进行判断下,根据自己的业务并发量进行计算下看看可以接受多大时间的阻塞而不会影响线上的运行。 - 方案二:id接续生成
这个需要记录下每个ms内id生成的最大数,当然这个数量也不能存储过多,顶多存储个几十秒的每毫秒的最大id。当出现时间回退时,我们可以接着出现回退的ms内的最大id继续生成,这样也不会有id重复的问题,但是如果时间回退的较多使用这种方式也是不合适的。 - 方案三:预留时间回退位
当时间回退较多时,无论是阻塞还是id接续生成都是不合适的,此时还可以考虑针对64位的数据进行预留时间回退位置,比如我们可以在10位的机器和机房id中预留2位用以标识时间回退,让机房id和机器id只占8位具体如何分配可以根据自己实际情况来说,当出现时间回退时可以打开该标识。 - 方案四:下线时间回退机器
这个是有风险的,虽然下线了服务器,但是如果是因为润秒原因导致的时间回退,很可能会导致大片机器同时下线,所以这种方式是很有安全隐患的。





![搜索旋转排序数组[中等]](https://img-blog.csdnimg.cn/direct/86550e81369a4f02a837f2af184325b6.jpeg)