scikit-learn 线性回归 LinearRegression 参数详解
- LinearRegression 参数详解
- 参考文献
LinearRegression 参数详解
# 从 sklearn 中引入线性模型模块
from sklearn import linear_model
# 建立线性回归对象 reg
reg = linear_model.LinearRegression(fit_intercept=True,copy_X=True,n_jobs=-1,positive=False)
fit_intercept: 是 bool 值只支持 True /False, 默认是 True
意思是,模型是否拟合截距项
w
0
w_0
w0 一般情况下我们都需要拟合
w
0
w_0
w0 也就是我们使用 True 选项,但是对于一些已经中心化的数据,其截距项可以确定为 0 我们就可以使用 False 选项,不拟合截距项。
例如:
# 从 sklearn 中引入线性模型模块
from sklearn import linear_model
# 建立线性回归对象 reg
reg = linear_model.LinearRegression(fit_intercept=False)
# 通过建立的对象拟合数据 x 为 [[0, 0], [1, 1], [2, 2]], y 为 [0, 1, 2]
reg.fit([[0, 0], [1, 1], [2, 2]], [0, 1, 2])
# 拟合的参数系数如下 y = 0.5x1 + 0.5x2
print(reg.coef_)
print(reg.intercept_)

作为对比我们看另一个例子
# 从 sklearn 中引入线性模型模块
from sklearn import linear_model
# 建立线性回归对象 reg
reg = linear_model.LinearRegression(fit_intercept=True)
# 通过建立的对象拟合数据 x 为 [[0, 0], [1, 1], [2, 2]], y 为 [0, 1, 2]
reg.fit([[0, 0], [1, 1], [2, 2]], [0, 1, 2])
# 拟合的参数系数如下 y = 1.1102230246251565e-16 + 0.5x1 + 0.5x2
print(reg.coef_)
print(reg.intercept_)
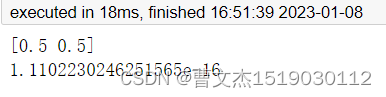
我们可以看到这两个拟合结果一个截距项确定为 0,一个截距项是非常接近 0 的数,这就是 fit_intercept 参数的作用。
copy_X: 是 bool 值只支持 True /False, 默认是 True
意思是我们的特征矩阵 X 是否需要拷贝,如果拷贝一份的话 scikit-learn 做的运算不会影响我们的原始数据,否则我们的 X 矩阵有可能会被覆盖。一般而言这个选项我们都使用 True,毕竟我们不希望原始数据被修改。
n_jobs 是 int 型,默认是 None (在这种情况下相当于 1)
意思是使用多少个 processor 完成这个拟合任务,通常来说对于少量数据我们可以使用默认选项 None,但是对于数据量较大且我们电脑 CPU 性能较好且有多核的情况下我们可以使用 -1 这个参数,调用所有 processor 为我们计算,减少运算所使用的时间。
positive 是 bool 型,默认是 False
意思是拟合的系数是否限制为正数,一般来说我们都使用 False 选项。
使用 True 选项往往是因为实际问题中参数存在限制,比如一些有具体含义的参数(必须是正数),需要注意的是 True 选项可能只支持 dense array (个人理解就是不支持带约束的稀疏矩阵的相关运算)。
参考文献
https://scikit-learn.org/stable/modules/generated/sklearn.linear_model.LinearRegression.html#sklearn.linear_model.LinearRegression