机器学习笔记之深度信念网络——背景介绍与模型表示
- 引言
- 深度信念网络
- 场景构建
- 深度信念网络的联合概率分布
引言
从本节开始,将介绍深度信念网络。
深度信念网络
深度信念网络(Deep Belief Network,DBN)是杰弗里·辛顿(Geoffrey Hinton)于2006年提出的模型,并正式提出了深度学习的概念。
在当时,将深度信念网络应用在分类问题中,其超过了当时主流的支持向量机 + 核技巧的分类效果。
在Sigmoid信念网络中介绍过,信念网络指的就是贝叶斯网络,也就是有向图模型。
但实际上,和
Sigmoid
\text{Sigmoid}
Sigmoid信念网络不同,深度信念网络是一个混合模型(Hybrid Model):
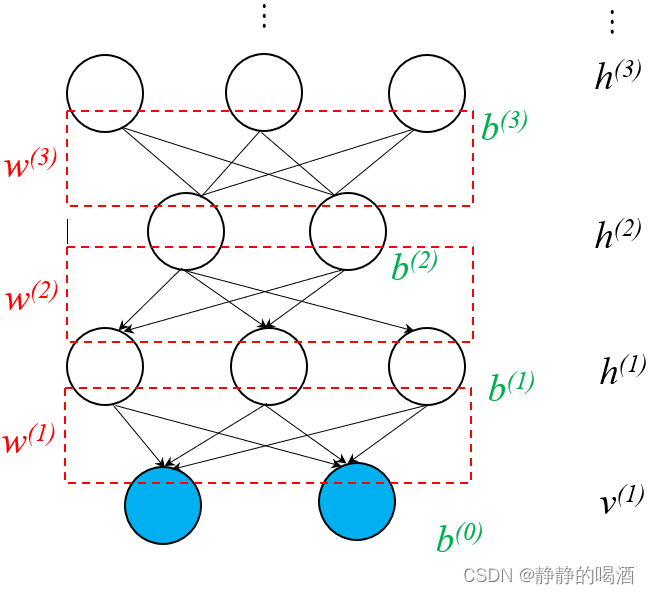
其中,
v
v
v表示观测变量所在层(输入部分),
h
(
1
)
,
h
(
2
)
,
h
(
3
)
h^{(1)},h^{(2)},h^{(3)}
h(1),h(2),h(3)分别表示不同隐藏层对应的编号。从上图中可以看出,
v
(
1
)
,
h
(
1
)
,
h
(
2
)
v^{(1)},h^{(1)},h^{(2)}
v(1),h(1),h(2)三层明显是一个
Sigmoid
\text{Sigmoid}
Sigmoid信念网络;而
h
(
2
)
,
h
(
3
)
h^{(2)},h^{(3)}
h(2),h(3)两层则是受限玻尔兹曼机(Restricted Boltzmann Machine,RBM)。
当然这里仅描述了一层受限玻尔兹曼机和一层
Sigmoid
\text{Sigmoid}
Sigmoid信念网络的组合现象,实际上可以通过对受限玻尔兹曼机的堆叠(Stacking RBM)向更深层次进行延伸。
并且它也是一个基于深度学习的概率生成模型,它对应的数据同样是不包含标签信息的。至此,观察一下该模型的定义。
场景构建
为了更好地描述定义,我们对各符号进行设定:
- 各层之间的权重信息(图中的红色虚线部分)分别使用 W ( 1 ) , W ( 2 ) , W ( 3 ) \mathcal W^{(1)},\mathcal W^{(2)},\mathcal W^{(3)} W(1),W(2),W(3)进行表示;
- 深度信念网络中每一层均包含偏置项信息,定义从 v ( 1 ) , h ( 1 ) , h ( 2 ) , h ( 3 ) v^{(1)},h^{(1)},h^{(2)},h^{(3)} v(1),h(1),h(2),h(3)顺序对应的偏置分别表示为 b ( 0 ) , b ( 1 ) , b ( 2 ) , b ( 3 ) b^{(0)},b^{(1)},b^{(2)},b^{(3)} b(0),b(1),b(2),b(3)(图中的绿色部分);
- 由于上标已经被占用,因此这里不同于之前对于样本的定义 v ( i ) ∈ V ( i = 1 , 2 , ⋯ , N ) v^{(i)} \in \mathcal V(i=1,2,\cdots,N) v(i)∈V(i=1,2,⋯,N),这里仅使用 v ∈ V v \in \mathcal V v∈V来描述样本集合 V \mathcal V V中的某一各具体样本。
深度信念网络的联合概率分布
上述示例中描述的所有结点均是随机变量,并且除了观测变量是样本集合给定的之外,其余所有变量均是隐变量。其分布和玻尔兹曼机、受限玻尔兹曼机、
Sigmoid
\text{Sigmoid}
Sigmoid信念网络相同,所有随机变量均服从伯努利分布:
这里直接使用
v
(
1
)
v^{(1)}
v(1)表示观测变量层中的所有随机变量结点组成的集合,其余层均同理。
D
\mathcal D
D表示观测变量结点的数量。
v
(
1
)
=
{
v
1
(
1
)
,
v
2
(
1
)
,
⋯
,
v
D
(
1
)
}
∈
{
0
,
1
}
D
v^{(1)} = \left\{v_1^{(1)},v_2^{(1)},\cdots, v_{\mathcal D}^{(1)}\right\} \in \{0,1\}^{\mathcal D}
v(1)={v1(1),v2(1),⋯,vD(1)}∈{0,1}D
至此,示例中所有随机变量(隐变量、观测变量)的联合概率分布可表示为:
将观测变量、隐变量分开。
P
(
v
(
1
)
,
h
(
1
)
,
h
(
2
)
,
h
(
3
)
)
=
P
(
v
(
1
)
∣
h
(
1
)
,
h
(
2
)
,
h
(
3
)
)
⋅
P
(
h
(
1
)
,
h
(
2
)
,
h
(
3
)
)
\begin{aligned} \mathcal P(v^{(1)},h^{(1)},h^{(2)},h^{(3)}) & = \mathcal P(v^{(1)} \mid h^{(1)},h^{(2)},h^{(3)}) \cdot \mathcal P(h^{(1)},h^{(2)},h^{(3)}) \\ \end{aligned}
P(v(1),h(1),h(2),h(3))=P(v(1)∣h(1),h(2),h(3))⋅P(h(1),h(2),h(3))
- 通过观察,观测变量集合
v
(
1
)
v^{(1)}
v(1)仅和隐变量集合
h
(
1
)
h^{(1)}
h(1)相关,和其他隐变量集合
h
(
2
)
,
h
(
3
)
h^{(2)},h^{(3)}
h(2),h(3)之间条件独立。因此,可以将上式化简为:
这明显是‘贝叶斯网络’中的顺序结构:在h ( 1 ) h^{(1)} h(1)可观测的条件下,v ( 1 ) v^{(1)} v(1)与h ( 2 ) , h ( 3 ) h^{(2)},h^{(3)} h(2),h(3)之间条件独立。
P ( v ( 1 ) , h ( 1 ) , h ( 2 ) , h ( 3 ) ) = P ( v ( 1 ) ∣ h ( 1 ) ) ⋅ P ( h ( 1 ) , h ( 2 ) , h ( 3 ) ) \mathcal P(v^{(1)},h^{(1)},h^{(2)},h^{(3)}) = \mathcal P(v^{(1)} \mid h^{(1)}) \cdot \mathcal P(h^{(1)},h^{(2)},h^{(3)}) P(v(1),h(1),h(2),h(3))=P(v(1)∣h(1))⋅P(h(1),h(2),h(3))
同理,关于联合概率分布 P ( h ( 1 ) , h ( 2 ) , h ( 3 ) ) P(h^{(1)},h^{(2)},h^{(3)}) P(h(1),h(2),h(3)), h ( 1 ) h^{(1)} h(1)仅和 h ( 2 ) h^{(2)} h(2)之间存在关联关系。因而它的联合概率分布可表示为:
此时,不同于v ( 1 ) v^{(1)} v(1)和h ( 1 ) h^{(1)} h(1)之间的关联关系,此时的模型结构是‘混合模型’,但是对条件独立性并不影响。
P ( h ( 1 ) , h ( 2 ) , h ( 3 ) ) = P ( h ( 1 ) ∣ h ( 2 ) , h ( 3 ) ) ⋅ P ( h ( 2 ) , h ( 3 ) ) = P ( h ( 1 ) ∣ h ( 2 ) ) ⋅ P ( h ( 2 ) , h ( 3 ) ) \begin{aligned} \mathcal P(h^{(1)},h^{(2)},h^{(3)}) & = \mathcal P(h^{(1)} \mid h^{(2)},h^{(3)}) \cdot \mathcal P(h^{(2)},h^{(3)}) \\ & = \mathcal P(h^{(1)} \mid h^{(2)}) \cdot \mathcal P(h^{(2)},h^{(3)}) \end{aligned} P(h(1),h(2),h(3))=P(h(1)∣h(2),h(3))⋅P(h(2),h(3))=P(h(1)∣h(2))⋅P(h(2),h(3))
最终,联合概率分布 P ( v ( 1 ) , h ( 1 ) , h ( 2 ) , h ( 3 ) ) \mathcal P(v^{(1)},h^{(1)},h^{(2)},h^{(3)}) P(v(1),h(1),h(2),h(3))表示为:
P ( v ( 1 ) , h ( 1 ) , h ( 2 ) , h ( 3 ) ) = P ( v ( 1 ) ∣ h ( 1 ) ) ⋅ P ( h ( 1 ) ∣ h ( 2 ) ) ⋅ P ( h ( 2 ) , h ( 3 ) ) \mathcal P(v^{(1)},h^{(1)},h^{(2)},h^{(3)}) = P(v^{(1)} \mid h^{(1)}) \cdot \mathcal P(h^{(1)} \mid h^{(2)}) \cdot \mathcal P(h^{(2)},h^{(3)}) P(v(1),h(1),h(2),h(3))=P(v(1)∣h(1))⋅P(h(1)∣h(2))⋅P(h(2),h(3)) - 观察等式右侧,其中
P
(
v
(
1
)
∣
h
(
1
)
)
,
P
(
h
(
1
)
∣
h
(
2
)
)
\mathcal P(v^{(1)} \mid h^{(1)}),\mathcal P(h^{(1)} \mid h^{(2)})
P(v(1)∣h(1)),P(h(1)∣h(2))均表示基于
Sigmoid
\text{Sigmoid}
Sigmoid信念网络下关于随机变量集合的后验概率分布,以
v
(
1
)
,
h
(
1
)
v^{(1)},h^{(1)}
v(1),h(1)之间的关联关系为例,
h
(
1
)
h^{(1)}
h(1)中的任意结点指向
v
(
1
)
v^{(1)}
v(1),其组成的关联关系均属于同父结构,因此实际上,
v
(
1
)
v^{(1)}
v(1)中任意观测变量结点之间在
h
(
1
)
h^{(1)}
h(1)可观测的条件下均条件独立。因此,
P
(
v
(
1
)
∣
h
(
1
)
)
\mathcal P(v^{(1)} \mid h^{(1)})
P(v(1)∣h(1))可表示为:
P ( v ( 1 ) ∣ h ( 1 ) ) = ∏ i = 1 D P ( v i ( 1 ) ∣ h ( 1 ) ) \mathcal P(v^{(1)} \mid h^{(1)}) = \prod_{i=1}^{\mathcal D} \mathcal P(v_i^{(1)} \mid h^{(1)}) P(v(1)∣h(1))=i=1∏DP(vi(1)∣h(1))
同理, P ( h ( 1 ) ∣ h ( 2 ) ) \mathcal P(h^{(1)} \mid h^{(2)}) P(h(1)∣h(2))也可表示为:
这里P ( 1 ) \mathcal P^{(1)} P(1)表示随机变量集合h ( 1 ) h^{(1)} h(1)中包含的随机变量的数量。
P ( h ( 1 ) ∣ h ( 2 ) ) = ∏ j = 1 P ( 1 ) P ( h j ( 1 ) ∣ h ( 2 ) ) \mathcal P(h^{(1)} \mid h^{(2)}) = \prod_{j=1}^{\mathcal P^{(1)}} \mathcal P(h_j^{(1)} \mid h^{(2)}) P(h(1)∣h(2))=j=1∏P(1)P(hj(1)∣h(2))
至此, P ( v ( 1 ) , h ( 1 ) , h ( 2 ) , h ( 3 ) ) \mathcal P(v^{(1)},h^{(1)},h^{(2)},h^{(3)}) P(v(1),h(1),h(2),h(3))可展开为:
P ( v ( 1 ) , h ( 1 ) , h ( 2 ) , h ( 3 ) ) = ∏ i = 1 D P ( v i ( 1 ) ∣ h ( 1 ) ) ⋅ ∏ j = 1 P ( 1 ) P ( h j ( 1 ) ∣ h ( 2 ) ) ⋅ P ( h ( 2 ) , h ( 3 ) ) \mathcal P(v^{(1)},h^{(1)},h^{(2)},h^{(3)}) = \prod_{i=1}^{\mathcal D} \mathcal P(v_i^{(1)} \mid h^{(1)}) \cdot \prod_{j=1}^{\mathcal P^{(1)}} \mathcal P(h_j^{(1)} \mid h^{(2)}) \cdot \mathcal P(h^{(2)},h^{(3)}) P(v(1),h(1),h(2),h(3))=i=1∏DP(vi(1)∣h(1))⋅j=1∏P(1)P(hj(1)∣h(2))⋅P(h(2),h(3)) - 继续观察,
P
(
v
i
(
1
)
∣
h
(
1
)
)
\mathcal P(v_i^{(1)} \mid h^{(1)})
P(vi(1)∣h(1))要如何进行表示呢?观察下图:
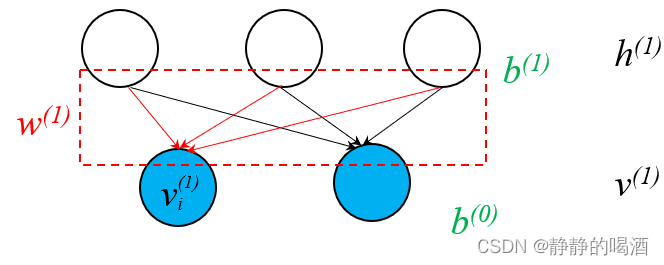
根据Sigmoid信念网络的定义,后验概率 P ( v i ( 1 ) ∣ h ( 1 ) ) \mathcal P(v_i^{(1)} \mid h^{(1)}) P(vi(1)∣h(1))可表示为:
W h ( 1 ) → v i ( 1 ) \mathcal W_{h^{(1)} \to v_i^{(1)}} Wh(1)→vi(1)表示h ( 1 ) h^{(1)} h(1)随机变量集合中的各隐变量结点指向v i ( 1 ) v_i^{(1)} vi(1)的权重信息,上图中的红色线部分。
P ( v i ( 1 ) ∣ h ( 1 ) ) = Sigmoid { [ W h ( 1 ) → v i ( 1 ) ] T h ( 1 ) + b i ( 0 ) } [ W h ( 1 ) → v i ( 1 ) ] P ( 1 ) × 1 ∈ W ( 1 ) \mathcal P(v_i^{(1)} \mid h^{(1)}) = \text{Sigmoid} \left\{\left[\mathcal W_{h^{(1)} \to v_i^{(1)}}\right]^T h^{(1)} + b_i^{(0)}\right\} \quad \left[\mathcal W_{h^{(1)} \to v_i^{(1)}}\right]_{\mathcal P^{(1)} \times 1} \in \mathcal W^{(1)} P(vi(1)∣h(1))=Sigmoid{[Wh(1)→vi(1)]Th(1)+bi(0)}[Wh(1)→vi(1)]P(1)×1∈W(1)
同理, P ( h j ( 1 ) ∣ h ( 2 ) ) \mathcal P(h_j^{(1)} \mid h^{(2)}) P(hj(1)∣h(2))可表示为:
P ( h j ( 1 ) ∣ h ( 2 ) ) = Sigmoid { [ W h ( 2 ) → h j ( 1 ) ] T h ( 2 ) + b j ( 1 ) } [ W h ( 2 ) → h j ( 1 ) ] P ( 2 ) × 1 ∈ W ( 2 ) \mathcal P(h_j^{(1)} \mid h^{(2)}) = \text{Sigmoid} \left\{\left[\mathcal W_{h^{(2)} \to h_j^{(1)}}\right]^T h^{(2)} + b_j^{(1)}\right\} \quad \left[\mathcal W_{h^{(2)} \to h_j^{(1)}}\right]_{\mathcal P^{(2)} \times 1} \in \mathcal W^{(2)} P(hj(1)∣h(2))=Sigmoid{[Wh(2)→hj(1)]Th(2)+bj(1)}[Wh(2)→hj(1)]P(2)×1∈W(2)
而最终 P ( h ( 2 ) , h ( 3 ) ) \mathcal P(h^{(2)},h^{(3)}) P(h(2),h(3))是关于受限玻尔兹曼机的联合概率分布,其结果可表示为:
在受限玻尔兹曼机中介绍过,各层内的随机变量之间均条件独立,这里偏置项中乘的信息实际上就是各随机变量与自身之间关联关系信息。
P ( h ( 2 ) , h ( 3 ) ) = 1 Z exp { [ h ( 3 ) ] T W ( 3 ) ⋅ h ( 2 ) + [ h ( 2 ) ] T ⋅ b ( 2 ) + [ h ( 3 ) ] T b ( 3 ) } \mathcal P(h^{(2)},h^{(3)}) = \frac{1}{\mathcal Z} \exp \left\{ \left[h^{(3)}\right]^T \mathcal W^{(3)} \cdot h^{(2)} + \left[h^{(2)}\right]^T\cdot b^{(2)} + \left[h^{(3)}\right]^Tb^{(3)}\right\} P(h(2),h(3))=Z1exp{[h(3)]TW(3)⋅h(2)+[h(2)]T⋅b(2)+[h(3)]Tb(3)}
至此,联合概率分布
P
(
v
(
1
)
,
h
(
1
)
,
h
(
2
)
,
h
(
3
)
)
\mathcal P(v^{(1)},h^{(1)},h^{(2)},h^{(3)})
P(v(1),h(1),h(2),h(3))可表示为:
P
(
v
(
1
)
,
h
(
1
)
,
h
(
2
)
,
h
(
3
)
)
=
∏
i
=
1
D
P
(
v
i
(
1
)
∣
h
(
1
)
)
⋅
∏
j
=
1
P
(
1
)
P
(
h
j
(
1
)
∣
h
(
2
)
)
⋅
P
(
h
(
2
)
,
h
(
3
)
)
{
P
(
v
i
(
1
)
∣
h
(
1
)
)
=
Sigmoid
{
[
W
h
(
1
)
→
v
i
(
1
)
]
T
h
(
1
)
+
b
i
(
0
)
}
[
W
h
(
1
)
→
v
i
(
1
)
]
P
(
1
)
×
1
∈
W
(
1
)
P
(
h
j
(
1
)
∣
h
(
2
)
)
=
Sigmoid
{
[
W
h
(
2
)
→
h
j
(
1
)
]
T
h
(
2
)
+
b
j
(
1
)
}
[
W
h
(
2
)
→
h
j
(
1
)
]
P
(
2
)
×
1
∈
W
(
2
)
P
(
h
(
2
)
,
h
(
3
)
)
=
1
Z
exp
{
[
h
(
3
)
]
T
W
(
3
)
⋅
h
(
2
)
+
[
h
(
2
)
]
T
⋅
b
(
2
)
+
[
h
(
3
)
]
T
b
(
3
)
}
\begin{aligned} & \mathcal P(v^{(1)},h^{(1)},h^{(2)},h^{(3)}) = \prod_{i=1}^{\mathcal D} \mathcal P(v_i^{(1)} \mid h^{(1)}) \cdot \prod_{j=1}^{\mathcal P^{(1)}} \mathcal P(h_j^{(1)} \mid h^{(2)}) \cdot \mathcal P(h^{(2)},h^{(3)}) \\ & \begin{cases} \mathcal P(v_i^{(1)} \mid h^{(1)}) = \text{Sigmoid} \left\{\left[\mathcal W_{h^{(1)} \to v_i^{(1)}}\right]^T h^{(1)} + b_i^{(0)}\right\} \quad \left[\mathcal W_{h^{(1)} \to v_i^{(1)}}\right]_{\mathcal P^{(1)} \times 1} \in \mathcal W^{(1)} \\ \mathcal P(h_j^{(1)} \mid h^{(2)}) = \text{Sigmoid} \left\{\left[\mathcal W_{h^{(2)} \to h_j^{(1)}}\right]^T h^{(2)} + b_j^{(1)}\right\} \quad \left[\mathcal W_{h^{(2)} \to h_j^{(1)}}\right]_{\mathcal P^{(2)} \times 1} \in \mathcal W^{(2)} \\ \mathcal P(h^{(2)},h^{(3)}) = \frac{1}{\mathcal Z} \exp \left\{ \left[h^{(3)}\right]^T \mathcal W^{(3)} \cdot h^{(2)} + \left[h^{(2)}\right]^T\cdot b^{(2)} + \left[h^{(3)}\right]^Tb^{(3)}\right\} \\ \end{cases} \end{aligned}
P(v(1),h(1),h(2),h(3))=i=1∏DP(vi(1)∣h(1))⋅j=1∏P(1)P(hj(1)∣h(2))⋅P(h(2),h(3))⎩
⎨
⎧P(vi(1)∣h(1))=Sigmoid{[Wh(1)→vi(1)]Th(1)+bi(0)}[Wh(1)→vi(1)]P(1)×1∈W(1)P(hj(1)∣h(2))=Sigmoid{[Wh(2)→hj(1)]Th(2)+bj(1)}[Wh(2)→hj(1)]P(2)×1∈W(2)P(h(2),h(3))=Z1exp{[h(3)]TW(3)⋅h(2)+[h(2)]T⋅b(2)+[h(3)]Tb(3)}
对应的模型参数有:
θ
=
{
W
(
1
)
,
W
(
2
)
,
W
(
3
)
,
b
(
0
)
,
b
(
1
)
,
b
(
2
)
,
b
(
3
)
}
\theta = \{\mathcal W^{(1)},\mathcal W^{(2)},\mathcal W^{(3)},b^{(0)},b^{(1)},b^{(2)},b^{(3)}\}
θ={W(1),W(2),W(3),b(0),b(1),b(2),b(3)}
下一节将介绍:为什么要设计乘多个 RBM \text{RBM} RBM叠加的方式,或者说,叠加 RBM \text{RBM} RBM的动机。
相关参考:
(系列二十七)深度信念网络1-背景介绍




![[ 数据结构 ] 赫夫曼编码--------数据、文件压缩解压](https://img-blog.csdnimg.cn/img_convert/6b0989bd347f5758e732ba4a967f914f.png)






![[cpp进阶]C++异常](https://img-blog.csdnimg.cn/e757eed495244cbead947a8b94d26eec.png)