目录
一、stack
实现一个stack
二、queue
实现一个queue
三、deque(双端对列)了解
1、deque的概念
2、为什么采用deque作为stack和queue的底层容器?
3、deque的缺点
3.1随机访问速度不如vector
3.2中间插入、删除速度不如list
3.3deque不适合遍历及排序
四、优先级队列
1、优先级队列的介绍
2、优先级队列中的仿函数(函数对象)
3、模拟实现优先级队列
五、反向迭代器
1、反向迭代器的底层
2、模拟实现反向迭代器
vector、list被称为容器,而stack和queue却被称为容器适配器。

stack和queue的类模板中第二个模板参数的意义是底层选用哪种容器来实现容器适配器,官方文档使用deque作为默认容器。当然,生成模板类的时候可以生成数组栈、链式栈或链式队列等,可以自由切换stack和queue的底层结构。这就是stack和queue被称为容器适配器的原因。这种设计模式被称为适配器模式。
适配器模式:用已有的东西封装转换出想要的东西。
这是博主另一篇使用C语言实现栈和队列的文章:【数据结构】栈和队列的实现及应用。
一、stack
栈的特点是先进后出,stack不提供迭代器。
实现一个stack
#include <list>
#include <vector>
#include <deque>
namespace jly
{
template <class T, class Container=deque<T>>
class stack
{
public:
bool empty()const
{
return _con.empty();
}
void push(const T& x)
{
_con.push_back(x);
}
void pop()
{
_con.pop_back();
}
size_t size()const
{
return _con.size();
}
const T& top()const
{
return _con.back();
}
private:
Container _con;
};
}stack的底层可以是vector或list等支持尾插尾删的线性容器。
二、queue
队列的特点是先进先出,queue不提供迭代器。
实现一个queue
#include <list>
#include <vector>
#include <deque>
namespace jly
{
template <class T, class Container = deque<T>>
class queue
{
public:
bool empty()const
{
return _con.empty();
}
void push(const T& x)
{
_con.push_back(x);
}
void pop()
{
_con.pop_front();
}
size_t size()const
{
return _con.size();
}
const T& front()const
{
return _con.front();
}
const T& back()const
{
return _con.back();
}
private:
Container _con;
};
}queue的底层可以是list等支持尾插头删的线性容器,但并不支持vector,因为数组头插头删效率不行。
三、deque(双端对列)了解
1、deque的概念
deque是具有动态大小的顺序容器,可以在两端扩展或收缩。
2、为什么采用deque作为stack和queue的底层容器?
deque强就强在头尾插入删除数据效率高。
1、在栈和队列这种只在头尾进行数据操作的结构中,并不需要遍历。
2、栈的元素增长时,vector的扩容需要挪动数据,而deque扩容时并不需要对原生数据进行挪动,只需拷贝中控数组和段空间的映射关系即可。队列的元素增长时,deque效率高,同时三级缓存命中率及空间利用率比list高。
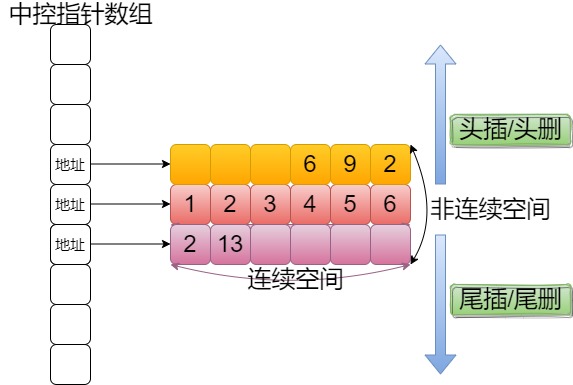
3、deque的缺点
deque也有它的缺点。
3.1随机访问速度不如vector
由于deque的中控数组中指向的一段段地址空间之间并不连续,所以随机访问时需要计算目标数据处于哪段buffer中的第几个数据。计算方式与磁盘定位扇区类似(LBA地址转化为CHS地址)。所以deque的随机访问速度并没有vector快。
3.2中间插入、删除速度不如list
从deque的底层结构图中可以看出,中间插入、删除数据仍会产生数据的挪动。deque中间插入、删除数据的速度不如list。
3.3deque不适合遍历及排序
deque迭代器原理:当cur等于last,说明本段空间已被使用完毕,通过node++找到中控数组中下一段内存空间的地址。在遍历时,deque的迭代器需要频繁判断cur的位置,造成效率低下。

四、优先级队列
1、优先级队列的介绍

优先级队列的特点是优先级高的先出。
优先级队列是一种容器适配器,不提供迭代器,它的底层是一个堆(默认是大堆),这个堆默认使用vector进行适配。
priority_queue<int> pq;//pq底层为大堆
priority_queue<int,vector<int>,greater<int>> pq;//pq底层为小堆这是博主使用C语言写的一篇关于堆的文章:【数据结构】动图详解二叉树——堆及堆排序
2、优先级队列中的仿函数(函数对象)
仿函数,又称函数对象,它是一个类,类中重载了函数调用符号();这个运算符重载的返回值根据需要去给。
namespace jly
{
template <class T>
struct less
{
bool operator()(const T& x, const T& y)
{
return x < y;
}
};
template <class T>
struct greater
{
bool operator()(const T& x, const T& y)
{
return x > y;
}
};
}
int main()
{
jly::less<int> func;
func(1,2);
func.operator()(1,2);//等价
return 0;
}看到func(1,2);会让人感觉这是函数调用,但其实这里的func是一个对象,通过对象,调用运算符重载operator()。
3、模拟实现优先级队列
#pragma once
#include <vector>
namespace jly
{
template <class T>
struct less
{
bool operator()(const T& x, const T& y)
{
return x < y;
}
};
template <class T>
struct greater
{
bool operator()(const T& x, const T& y)
{
return x > y;
}
};
template <class T, class Container = std::vector<T>,class Compare=less<int>>
class priority_queue
{
private:
void AdjustUp(size_t child)
{
Compare com;//构造一个仿函数对象
size_t parent = (child - 1) / 2;//当child=0时,parent会很大
while (parent<_con.size()&&com(_con[parent] ,_con[child]))
{
std::swap(_con[parent], _con[child]);
child = parent;
parent = (child - 1) / 2;
}
}
void AdjustDown(size_t parent)
{
Compare com;//构造一个仿函数对象
size_t minChild = 2 * parent + 1;
while (minChild<_con.size())
{
if (minChild + 1 < _con.size() && com(_con[minChild] , _con[minChild + 1]))
{
++minChild;
}
if(com(_con[parent], _con[minChild]))
{
std::swap(_con[minChild], _con[parent]);
parent = minChild;
}
else
break;
}
}
public:
//构造函数
priority_queue()
{
}
template <class InputIterator>
priority_queue(InputIterator first, InputIterator last)
:_con(first,last)
{
for (int i = 0; i < (_con.size-1-1)/2; ++i)
{
AdjustDown(i);
}
}
void push(const T& x)
{
_con.push_back(x);
AdjustUp(_con.size()-1);//从size-1开始调整
}
void pop()
{
std::swap(_con.front(), _con.back());//交换首尾数据
_con.pop_back();//尾删
AdjustDown(0);
}
const T& top()const
{
return _con.front();
}
bool empty()const
{
return _con.empty();
}
size_t size()const
{
return _con.size();
}
private:
Container _con;
};
}仿函数和C语言的函数指针的作用有点类似,函数指针是传入目标函数的地址,通过函数回调来执行目标函数的功能。而仿函数是一个类,对于模板函数,根据传入函数的类对象调用类中的operator()来控制不同的结果;对于模板类,通过在类中构造仿函数对象,在需要功能“分叉”的地方调用仿函数类中的operator()来达到不同的效果。(白话:泛型中的仿函数影响逻辑,通过仿函数来控制一个“水龙头”出冷水还是出热水······)
还有一种情况:优先级队列存的是某个类的地址,但是需要比较指针指向值的优先级。那这个时候就不能用<functional>中的less和greater控制建堆,需要自己写仿函数。(仿函数也可以加上模板特化)
五、反向迭代器
1、反向迭代器的底层
反向迭代器的本质就是对正向迭代器的封装,它同样是一个适配器。
STL源码中的反向迭代器的实现:反向迭代器用正向迭代器进行构造。
reverse_iterator rbegin(){return reverse_iterator(end());}
reverse_iterator rend(){return reverse_iterator(begin());}画个图,其实正向迭代器和反向迭代器的位置是对称的。

通过图示,rbegin()迭代器是最后一个数据的下一个位置,但是通过rbegin()访问的数据应该是4,这是通过运算符重载operator*()来解决。
template <class Iterator, class Ref, class Ptr>
Ref operator*()
{
Iterator tmp = _it;
return *--(tmp);
}
typedef ReserveIterator<iterator, T&, T*> reverse_iterator;
typedef ReserveIterator<const_iterator, const T&, const T*> const_reverse_iterator;2、模拟实现反向迭代器
namespace jly
{
template <class Iterator, class Ref, class Ptr>
class ReserveIterator
{
public:
ReserveIterator(Iterator it)//使用正向迭代器构造反向迭代器
:_it(it)
{
}
Ref operator*()
{
Iterator tmp = _it;
return *--(tmp);
}
Ptr operator->()//operator->()返回数据的地址
{
return &(operator*());
}
ReserveIterator<Iterator, Ref, Ptr>& operator++()//返回值不要写成Iterator,因为反向迭代器++返回的是反向迭代器,不是传入的迭代器类型
{
--_it;
return *this;
}
ReserveIterator<Iterator, Ref, Ptr>& operator--()
{
++_it;
return *this;
}
bool operator!=(const ReserveIterator<Iterator, Ref, Ptr>& rit)const
{
return _it != rit._it;
}
private:
Iterator _it;//底层是传入类型的迭代器
};
}