【🐋和鲸冬令营】通过数据打造爆款社交APP用户行为分析报告
文章目录
- 【🐋和鲸冬令营】通过数据打造爆款社交APP用户行为分析报告
- 1 业务背景
- 2 数据说明
- 3 数据探索性分析
- 4 用户行为分析
- 4.1 用户属性与行为关系分析
- 4.2 转化行为在不同用户属性群体中的分布情况
- 5 深入分析
- 5.1 多维度行为分析
- 5.2 行为预测模型
- 6 总体策略建议
时间紧张,其他的任务重,本次活动没有像上次一样花心思,马上毕业了时间并不充裕,所以就没有太认真写,见谅!
完整编译可运行的项目我挂载到了我的和鲸主页:北天
欢迎大家前去fork,点赞,评论,收藏,非常感谢!!!
1 业务背景
近些年来,随着移动互联网和大数据的快速发展,人们花费了很多时间在各式各样的社区、论坛、购物网站和社交软件上,同时企业也积累了海量的用户数据,而每一次的浏览、点击都代表着特定的用户行为,如果能够以科学的方式对这些海量的用户行为进行统计、分析和挖掘,那么我们将会更加了解自己的用户:如他们的地理位置、文化背景、消费水平、行为偏好、生命周期等,同时也有助于我们制定更佳的产品或营销策略,提升用户体验,从而实现精细化运营,打造爆款社交APP。
假设你是一名移动互联网行业的数据分析师,目前想要找到影响产品转化率的核心因素,在产品/运营侧输出关键策略,帮助公司提升核心指标,从而体现数据分析的价值所在;那么你会从哪些角度出发呢?
2 数据说明
- 本数据集是某社交App一定时间内相关用户行为的分类示例数据;
- A、B、C、D、E、F代表了六个不同的属性或功能参数;
- 每一行数据代表了一组有相同属性的用户;
- Action1、Action_2是具有某种归类的用户数;
- Action_1到Action_2记录的是由用户数变化所代表的转化率;
- 数据中个人信息部分已脱敏;
3 数据探索性分析
我们首先加载并初步探索提供的数据集。
import pandas as pd
data_path = '2023冬令营实战数据集.csv'
data = pd.read_csv(data_path)
data.info(), data.head()
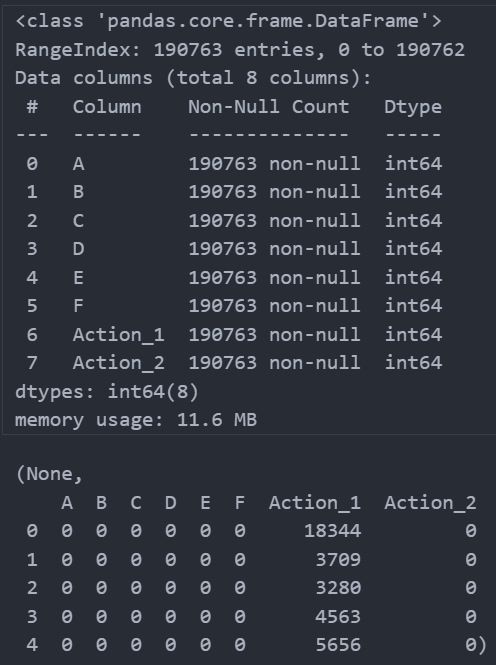
数据集包含190,763条记录和8个字段,字段名为"A"到"F",以及"Action_1"和"Action_2",所有字段都是整数类型。
接下来我们将进行一些基本的数据探索性分析。
# 描述性统计分析
descriptive_stats = data.describe()
# 检查缺失值
missing_values = data.isnull().sum()
missing_values
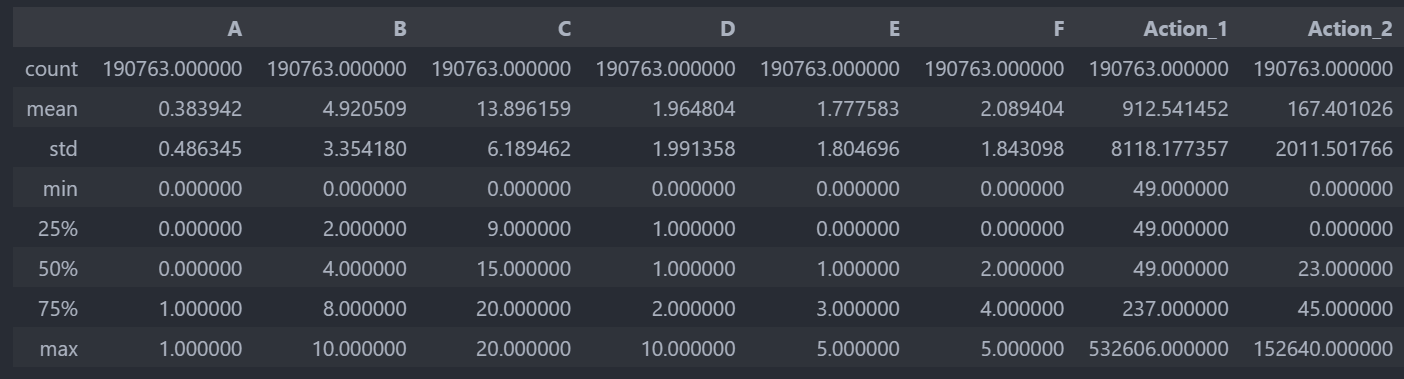
数据集中的每个字段都没有缺失值,以下是各字段的描述性统计摘要:
- A到F:这些字段的最小值、25%、50%(中位数)、75%和最大值显示了数据的分布范围,例如字段"A"的值在0和1之间,可能表示某种二元特征(如性别或是否完成某项操作),字段"B"到"F"的范围和分布各不相同,表明它们代表不同的用户属性或行为特征。
- Action_1和Action_2:表示用户行为的计数,其值范围和标准差相当大,特别是"Action_1"的最大值达到532,606,"Action_2"的最大值为152,640,表明数据中可能存在极端值或异常值。
由于数据集中没有发现缺失值,这简化了数据清洗的步骤。
下面我们进行异常值探索,给定"Action_1"和"Action_2"字段的极端最大值,下一步我们可以通过可视化方法进一步探索这些可能的异常值。我们将绘制这两个字段的箱线图,以直观地查看数据分布和识别潜在的异常值。
import matplotlib.pyplot as plt
import seaborn as sns
# 设置绘图风格
sns.set(style="whitegrid")
# 绘制Action_1和Action_2的箱线图
plt.figure(figsize=(12, 6))
plt.subplot(1, 2, 1)
sns.boxplot(y=data['Action_1'])
plt.title('Action_1 Boxplot')
plt.subplot(1, 2, 2)
sns.boxplot(y=data['Action_2'])
plt.title('Action_2 Boxplot')
plt.show()
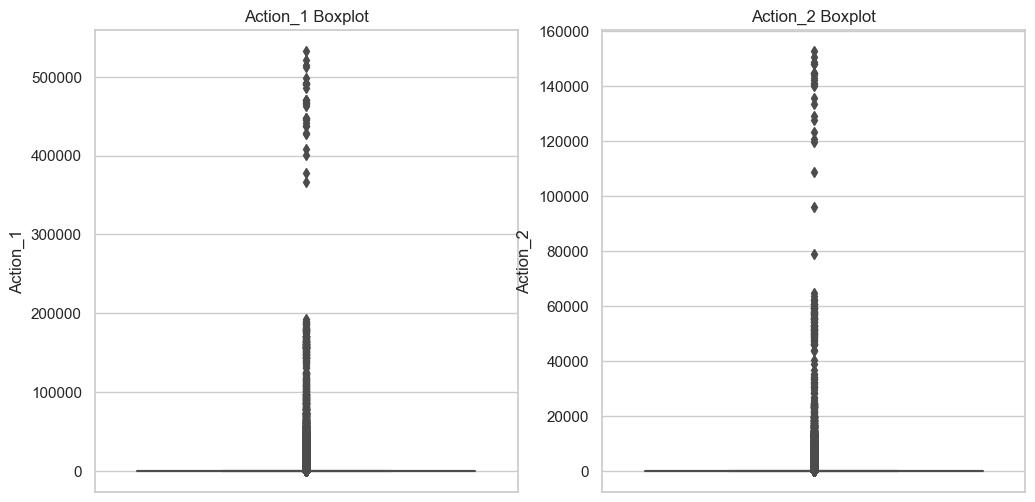
箱线图展示了"Action_1"和"Action_2"字段中潜在的异常值,从图中可以看出:
- Action_1和Action_2字段都有大量的异常值,这些值远远高于Q3(第三四分位数)加上1.5倍的IQR(四分位距)计算得出的上界。
- 这些异常值可能代表某些用户的行为极其活跃或者是数据收集、记录过程中的特殊情况。
4 用户行为分析
接下来我们将从用户行为分析的角度入手,特别是关注影响产品转化率的核心因素,首先我们需要定义什么是“转化率”在这个上下文中的意义,考虑到数据集的特点,我们可以假设"Action_1"和"Action_2"代表了用户的某种转化行为,例如购买、点击广告等。
因此我们的分析可以从以下几个角度展开:
- 用户属性(A到F)与行为(Action_1和Action_2)的关系:探索这些属性如何影响用户的转化行为。
- 转化行为的分布:分析转化行为(Action_1和Action_2)在不同用户群体中的分布情况。
4.1 用户属性与行为关系分析
为了探索用户属性(A到F)与转化行为(Action_1和Action_2)之间的关系,我们可以进行如下分析:
- 相关性分析:计算用户属性与转化行为之间的相关系数,以识别哪些属性与转化行为更为相关。
- 群组分析:对用户属性进行分组(例如,根据属性"A"是否为1),比较不同组内的转化行为差异。
我们先从相关性分析开始,计算用户属性(A到F)与转化行为(Action_1和Action_2)之间的相关系数,这将帮助我们了解哪些用户属性与转化行为更密切相关。
# 计算相关系数
correlation_matrix = data.corr()
# 展示相关系数矩阵
correlation_matrix[['Action_1', 'Action_2']]
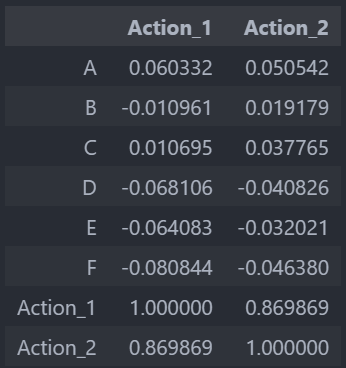
上述结果展现的揭示了用户属性(A到F)与转化行为(Action_1和Action_2)之间的相关性如下:
- Action_1与Action_2之间有很高的相关性(约0.87),这表明这两种行为可能是相互关联的,或者在很多情况下同时发生。
- 属性A与Action_1和Action_2呈正相关(分别约0.06和0.05),尽管相关性不是很强,但这表明属性A的某些值可能与更高的转化行为相关联。
- 其他属性(B到F)与转化行为的相关性较弱,且部分属性与转化行为呈负相关,特别是F与Action_1和Action_2的相关性最低(分别约-0.08和-0.05)。
这些发现提示我们,属性A可能在分析用户转化行为时值得特别关注,而属性F的负相关性可能表明随着F的增加,用户的转化行为可能会减少。
接下来,为了更深入地理解这些属性如何影响转化行为,我们将进行群组分析,比较不同用户属性群体的转化行为差异,我们将从属性A开始,因为它与转化行为的相关性最强,我们将比较属性A为1和为0的用户群体的转化行为(Action_1和Action_2)的平均值差异。
# 按属性A分组,计算每组的Action_1和Action_2的平均值
grouped_by_A = data.groupby('A')[['Action_1', 'Action_2']].mean()
grouped_by_A
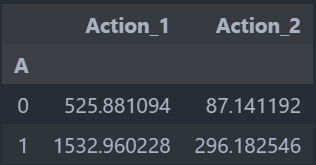
对于属性A,我们比较了当其值为1和为0时,用户的转化行为(Action_1和Action_2)的平均值:
- 当A=1时,Action_1的平均值为1,532.96,Action_2的平均值为296.18。
- 当A=0时,Action_1的平均值为525.88,Action_2的平均值为87.14。
这个结果表明,属性A为1的用户群体的转化行为(无论是Action_1还是Action_2)的平均值明显高于属性A为0的用户群体,这进一步证实了属性A可能是影响用户转化行为的一个重要因素。
基于这个发现,我们可以假设改善或增强与属性A相关的产品特性或用户体验,可能会提高用户的转化率。
4.2 转化行为在不同用户属性群体中的分布情况
下一步我们将通过可视化方法进一步探索转化行为(Action_1和Action_2)在不同用户属性群体中的分布情况,我们将选择一个代表性的属性进行分析,考虑到属性A的重要性,我们将围绕它进行展开,我们计划绘制属性A不同值对应的Action_1和Action_2的分布情况。
# 绘制属性A对Action_1和Action_2分布的影响
plt.figure(figsize=(14, 6))
plt.subplot(1, 2, 1)
sns.boxplot(x='A', y='Action_1', data=data)
plt.title('Action_1 Distribution by Attribute A')
plt.subplot(1, 2, 2)
sns.boxplot(x='A', y='Action_2', data=data)
plt.title('Action_2 Distribution by Attribute A')
plt.tight_layout()
plt.show()
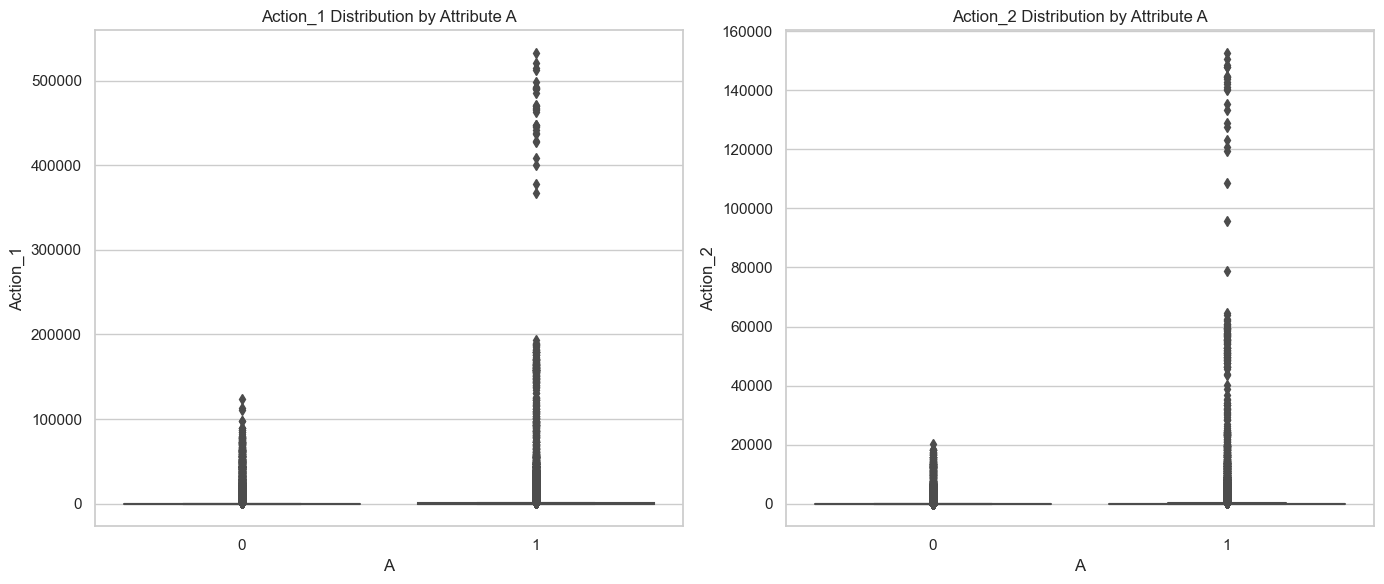
通过箱线图可视化属性A对Action_1和Action_2分布的影响,我们可以观察到以下几点:
- Action_1和Action_2的分布:无论是Action_1还是Action_2,属性A为1的用户群体的中位数和四分位数范围都高于属性A为0的用户群体,这与我们之前的分析结果一致,即属性A为1的用户更倾向于有更高的转化行为。
- 异常值:两种行为的分布都有大量的异常值,尤其是在属性A为1的群体中,这可能表明存在一些极端活跃的用户。
这些观察结果支持了我们之前的发现,即属性A显著影响用户的转化行为,这提示我们提高与属性A相关的用户满意度或参与度可能是提高转化率的关键。
策略建议
- 增强与属性A相关的特性或服务:鉴于属性A对转化行为的显著影响,应优先改进与之相关的产品特性或用户体验,以提升该用户群的参与度和满意度。
- 针对性营销活动:可以针对属性A为1的用户群体设计专门的营销活动或优惠,以进一步提高他们的转化率。
- 关注高活跃用户:对于异常活跃的用户群体,进行深入分析了解他们的特性和需求,可能发现提升用户活跃度和转化率的新机会。
这些策略建议旨在通过深入理解和满足用户需求,优化产品和营销策略,最终提升用户转化率。
5 深入分析
5.1 多维度行为分析
基于前面的分析,我们已经确认了属性A对用户转化行为的重要性,接下来我们可以进一步深入分析探索,除了单一属性的影响,用户的转化行为可能受到多个因素的共同作用,我们可以利用多变量分析方法,如逻辑回归或决策树,来识别哪些属性组合对转化行为影响最大。
我们将使用逻辑回归模型,分析多个属性如何共同影响用户的某一转化行为(例如,选择Action_1作为响应变量),这将帮助我们识别对转化行为影响最大的属性组合。
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import classification_report, confusion_matrix
# 由于Action_1的值范围很大,我们将其转换为二元变量,以便于使用逻辑回归分析
# 定义转化行为的阈值,这里假设高于中位数的行为视为正样本(1),否则为负样本(0)
threshold = data['Action_1'].median()
data['Action_1_binary'] = (data['Action_1'] > threshold).astype(int)
# 准备特征变量和目标变量
X = data[['A', 'B', 'C', 'D', 'E', 'F']] # 特征变量
y = data['Action_1_binary'] # 目标变量
# 分割数据集为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 构建逻辑回归模型
log_reg_model = LogisticRegression(max_iter=1000)
# 训练模型
log_reg_model.fit(X_train, y_train)
# 模型评估
y_pred = log_reg_model.predict(X_test)
report = classification_report(y_test, y_pred)
conf_matrix = confusion_matrix(y_test, y_pred)
report, conf_matrix
(' precision recall f1-score support\n\n 0 0.63 0.61 0.62 29134\n 1 0.61 0.64 0.62 28095\n\n accuracy 0.62 57229\n macro avg 0.62 0.62 0.62 57229\nweighted avg 0.62 0.62 0.62 57229\n',
array([[17648, 11486],
[10162, 17933]], dtype=int64))
我们使用逻辑回归模型分析了多个用户属性(A到F)如何共同影响用户的转化行为(这里以Action_1的二元变化为例),模型的评估结果如下:
- 准确率(Accuracy):模型在测试集上的准确率为62%,这意味着模型能够以一定的准确度预测用户的转化行为。
- 精确度(Precision)**和**召回率(Recall):对于正样本(即转化行为较高的用户)和负样本(即转化行为较低的用户),模型的精确度和召回率均在60%到64%之间。
混淆矩阵显示了模型预测结果与实际情况的对比:
- 真正(TP):17,933,即模型正确预测为正样本的数量。
- 假正(FP):11,486,即模型错误预测为正样本的数量。
- 真负(TN):17,648,即模型正确预测为负样本的数量。
- 假负(FN):10,162,即模型错误预测为负样本的数量。
逻辑回归模型的结果表明,用户属性对其转化行为有一定的预测能力,尽管模型的整体性能表现良好,但仍有改进的空间,这可能意味着用户的转化行为受到多种因素的影响,而这些因素可能没有全部包含在当前分析中。
对于逻辑回归模型,我们可以可视化各个特征的系数(权重),以展示它们对预测结果的影响程度。这有助于我们理解哪些用户属性对其转化行为的预测贡献最大。
# 逻辑回归模型的特征系数可视化
features = X.columns
coefficients = log_reg_model.coef_[0]
# 创建系数的DataFrame
coeff_df = pd.DataFrame({'Feature': features, 'Coefficient': coefficients})
# 绘制系数的条形图
plt.figure(figsize=(10, 6))
sns.barplot(x='Coefficient', y='Feature', data=coeff_df.sort_values(by='Coefficient', ascending=False))
plt.title('Logistic Regression Coefficients')
plt.xlabel('Coefficient Value')
plt.ylabel('Feature')
plt.tight_layout()
plt.show()
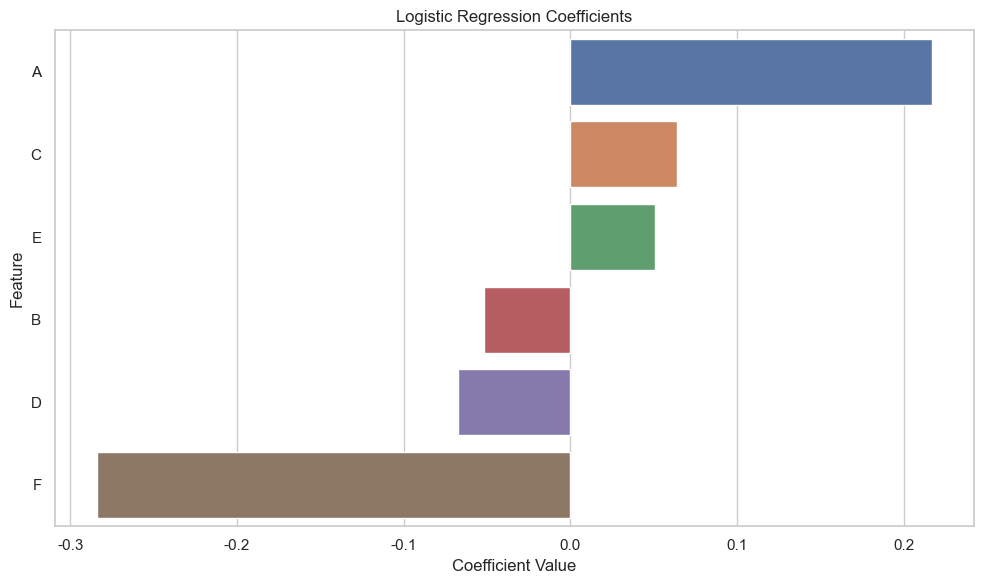
从逻辑回归模型的系数可视化中,我们可以看到各个特征对预测用户转化行为(即Action_1_binary)的贡献程度,正系数表示特征与正样本(较高的转化行为)正相关,负系数则表示负相关。
结论
- 某些特征对用户的转化行为有显著影响,这些特征的优化可能会直接提升用户的转化率。
- 特征间的影响程度不同,指出了不同用户属性在影响用户行为上的相对重要性。
策略建议
- 重点优化:针对影响力较大的特征,进行产品或服务的优化,以提高用户的转化率。
- 用户分析:深入分析对转化行为有正面影响的特征背后的用户行为和偏好,定制化营销策略。
5.2 行为预测模型
利用已有的用户属性和行为数据,我们可以尝试构建一个预测模型,预测用户的转化行为,这样的模型不仅可以帮助我们更准确地识别潜在的高价值用户,还可以为制定个性化的营销策略提供支持。
为了进一步探索用户行为的预测模型,我们将使用机器学习的方法来预测用户的转化行为,考虑到数据集的特性和之前的分析结果,我们可以尝试构建一个分类模型,预测用户是否会表现出较高的转化行为(即Action_1_binary为1)。
这里我们将使用随机森林分类器进行行为预测模型的构建,随机森林是一种集成学习方法,它通过构建多个决策树来提高预测的准确性和稳定性,相较于逻辑回归模型,随机森林能够更好地处理非线性关系和特征间的交互效应,因此可能在这个任务上表现更优。
from sklearn.ensemble import RandomForestClassifier
# 构建随机森林模型
rf_model = RandomForestClassifier(n_estimators=100, random_state=42)
# 训练模型
rf_model.fit(X_train, y_train)
# 模型评估
y_pred_rf = rf_model.predict(X_test)
report_rf = classification_report(y_test, y_pred_rf)
conf_matrix_rf = confusion_matrix(y_test, y_pred_rf)
report_rf, conf_matrix_rf
(' precision recall f1-score support\n\n 0 0.81 0.64 0.72 29134\n 1 0.69 0.84 0.76 28095\n\n accuracy 0.74 57229\n macro avg 0.75 0.74 0.74 57229\nweighted avg 0.75 0.74 0.74 57229\n',
array([[18694, 10440],
[ 4436, 23659]]))
随机森林模型在测试集上的评估结果如下:
- 准确率(Accuracy):模型的准确率提高到了74%,这表明模型能够较准确地预测用户是否会表现出较高的转化行为。
- 精确度(Precision)**和**召回率(Recall):对于正样本(即
Action_1_binary为1的情况),模型的召回率达到了84%,精确度为69%;对于负样本,精确度为81%,召回率为64%。
混淆矩阵显示了模型预测结果与实际情况的对比:
- 真正(TP):23,659,即模型正确预测为正样本的数量。
- 假正(FP):10,440,即模型错误预测为正样本的数量。
- 真负(TN):18,694,即模型正确预测为负样本的数量。
- 假负(FN):4,436,即模型错误预测为负样本的数量。
随机森林模型的性能明显优于之前的逻辑回归模型,特别是在召回率方面的表现,这表明随机森林模型更适合处理这种类型的分类问题,尤其是在预测用户的转化行为时。
对于随机森林模型,我们将可视化特征的重要性得分,这将帮助我们识别在预测用户转化行为时哪些特征最为关键。
# 随机森林模型的特征重要性可视化
feature_importances = rf_model.feature_importances_
# 创建特征重要性的DataFrame
importance_df = pd.DataFrame({'Feature': features, 'Importance': feature_importances})
# 绘制特征重要性的条形图
plt.figure(figsize=(10, 6))
sns.barplot(x='Importance', y='Feature', data=importance_df.sort_values(by='Importance', ascending=False))
plt.title('Random Forest Feature Importances')
plt.xlabel('Importance Score')
plt.ylabel('Feature')
plt.tight_layout()
plt.show()
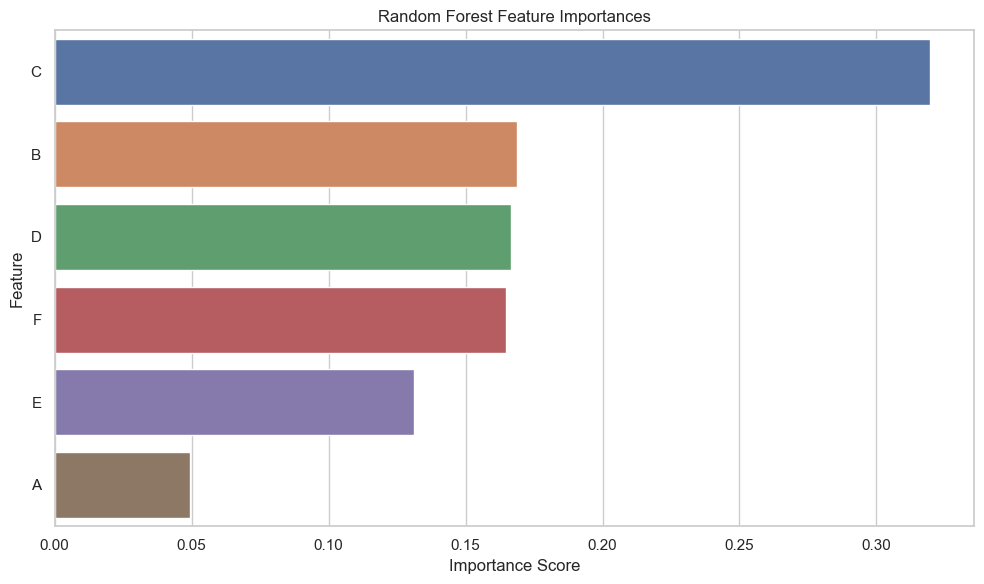
随机森林模型的特征重要性可视化展示了各个特征在预测用户转化行为时的重要性得分,较高的重要性得分表示该特征在预测用户是否会表现出较高转化行为时更为关键。
结论
- 特征重要性得分揭示了不同用户属性对预测用户转化行为的贡献度,指导我们理解哪些属性更能影响用户的转化概率。
- 与逻辑回归模型结果相比,随机森林提供了一个更细致的特征重要性视角,有助于我们更全面地理解影响用户转化行为的因素。
策略建议
- 聚焦关键属性:针对特征重要性高的用户属性,开展针对性的改进措施,例如优化用户体验、提升服务质量、调整产品功能等,以增加用户的转化概率。
- 数据驱动决策:利用特征重要性的洞察,制定基于数据的决策,例如在营销活动中优先针对可能转化率高的用户群体。
- 持续监测和优化:随着市场和用户行为的变化,定期重新评估特征的重要性,并据此调整策略。
6 总体策略建议
根据上述分析结果,我们为公司提出以下总体策略建议:
- 优化关键用户属性:针对影响用户转化行为的关键属性,如属性A,公司应优化相关的产品特性或用户体验,这可能包括改进用户界面、增强产品功能或提供更个性化的服务。
- 实施多维度用户分析:继续利用多变量分析和机器学习模型来深入理解不同用户属性和行为之间的复杂关系,这将帮助公司更准确地识别目标用户群体,制定更有效的营销策略。
- 构建和优化预测模型:利用随机森林等先进的机器学习技术构建和持续优化用户行为预测模型。这些模型可以帮助公司更有效地识别高潜力用户,实施针对性的营销活动,提高转化率。
- 个性化营销策略:基于用户行为预测模型的结果,制定个性化的营销策略和推广活动,通过精准定位用户偏好和需求,提供定制化的内容和优惠,以提高用户参与度和忠诚度。
- 动态调整和优化:市场环境和用户行为是不断变化的,公司需要建立起动态监测和分析机制,定期评估和调整产品策略、营销活动和用户体验设计,确保持续满足用户需求,提升用户满意度和转化率。
通过实施这些策略,公司可以更有效地利用用户数据来指导产品开发和营销决策,最终实现业务增长和市场竞争力的提升。