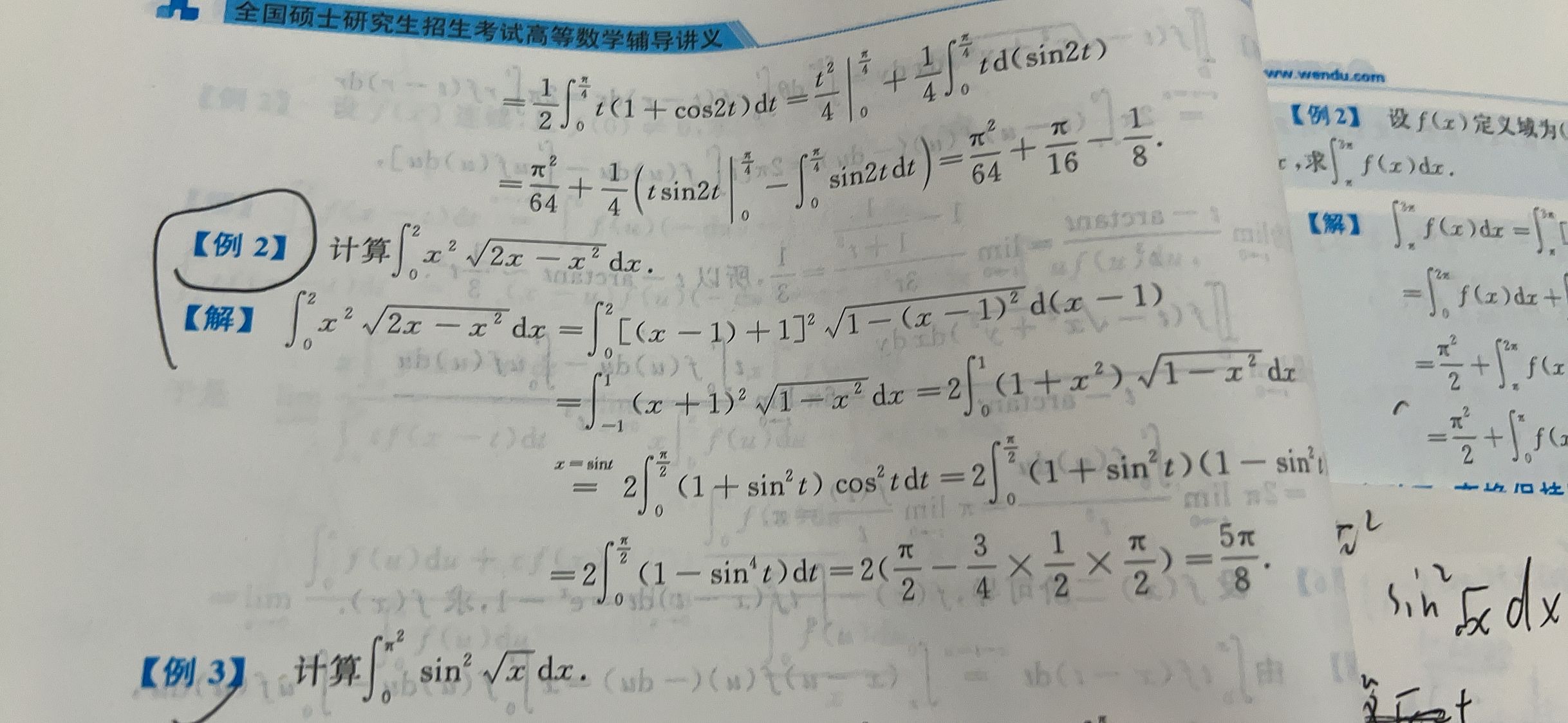专栏介绍:YOLOv9改进系列 | 包含深度学习最新创新,主力高效涨点!!!
一、本文介绍
本文只有代码及注意力模块简介,YOLOv9中的添加教程:可以看这篇文章。
YOLOv9有效提点|加入SE、CBAM、ECA、SimAM等几十种注意力机制(一)
MobileViT:《MOBILEVIT: LIGHT-WEIGHT, GENERAL-PURPOSE, AND MOBILE-FRIENDLY VISION TRANSFORMER》
MobileViT是一种轻量级和通用视觉转换器,用于移动设备上的视觉任务。MobileViT结合了CNN和ViT的优点,提供了一个不同的视角来进行全局信息处理。
from torch import nn
import torch
from einops import rearrange
class PreNorm(nn.Module):
def __init__(self, dim, fn):
super().__init__()
self.ln = nn.LayerNorm(dim)
self.fn = fn
def forward(self, x, **kwargs):
return self.fn(self.ln(x), **kwargs)
class FeedForward(nn.Module):
def __init__(self, dim, mlp_dim, dropout):
super().__init__()
self.net = nn.Sequential(
nn.Linear(dim, mlp_dim),
nn.SiLU(),
nn.Dropout(dropout),
nn.Linear(mlp_dim, dim),
nn.Dropout(dropout)
)
def forward(self, x):
return self.net(x)
class Attention(nn.Module):
def __init__(self, dim, heads, head_dim, dropout):
super().__init__()
inner_dim = heads * head_dim
project_out = not (heads == 1 and head_dim == dim)
self.heads = heads
self.scale = head_dim ** -0.5
self.attend = nn.Softmax(dim=-1)
self.to_qkv = nn.Linear(dim, inner_dim * 3, bias=False)
self.to_out = nn.Sequential(
nn.Linear(inner_dim, dim),
nn.Dropout(dropout)
) if project_out else nn.Identity()
def forward(self, x):
qkv = self.to_qkv(x).chunk(3, dim=-1)
q, k, v = map(lambda t: rearrange(t, 'b p n (h d) -> b p h n d', h=self.heads), qkv)
dots = torch.matmul(q, k.transpose(-1, -2)) * self.scale
attn = self.attend(dots)
out = torch.matmul(attn, v)
out = rearrange(out, 'b p h n d -> b p n (h d)')
return self.to_out(out)
class Transformer(nn.Module):
def __init__(self, dim, depth, heads, head_dim, mlp_dim, dropout=0.):
super().__init__()
self.layers = nn.ModuleList([])
for _ in range(depth):
self.layers.append(nn.ModuleList([
PreNorm(dim, Attention(dim, heads, head_dim, dropout)),
PreNorm(dim, FeedForward(dim, mlp_dim, dropout))
]))
def forward(self, x):
out = x
for att, ffn in self.layers:
out = out + att(out)
out = out + ffn(out)
return out
class MobileViTAttention(nn.Module):
def __init__(self, in_channel=3, dim=512, kernel_size=3, patch_size=7):
super().__init__()
self.ph, self.pw = patch_size, patch_size
self.conv1 = nn.Conv2d(in_channel, in_channel, kernel_size=kernel_size, padding=kernel_size // 2)
self.conv2 = nn.Conv2d(in_channel, dim, kernel_size=1)
self.trans = Transformer(dim=dim, depth=3, heads=8, head_dim=64, mlp_dim=1024)
self.conv3 = nn.Conv2d(dim, in_channel, kernel_size=1)
self.conv4 = nn.Conv2d(2 * in_channel, in_channel, kernel_size=kernel_size, padding=kernel_size // 2)
def forward(self, x):
y = x.clone() # bs,c,h,w
## Local Representation
y = self.conv2(self.conv1(x)) # bs,dim,h,w
## Global Representation
_, _, h, w = y.shape
y = rearrange(y, 'bs dim (nh ph) (nw pw) -> bs (ph pw) (nh nw) dim', ph=self.ph, pw=self.pw) # bs,h,w,dim
y = self.trans(y)
y = rearrange(y, 'bs (ph pw) (nh nw) dim -> bs dim (nh ph) (nw pw)', ph=self.ph, pw=self.pw, nh=h // self.ph,
nw=w // self.pw) # bs,dim,h,w
## Fusion
y = self.conv3(y) # bs,dim,h,w
y = torch.cat([x, y], 1) # bs,2*dim,h,w
y = self.conv4(y) # bs,c,h,w
return y
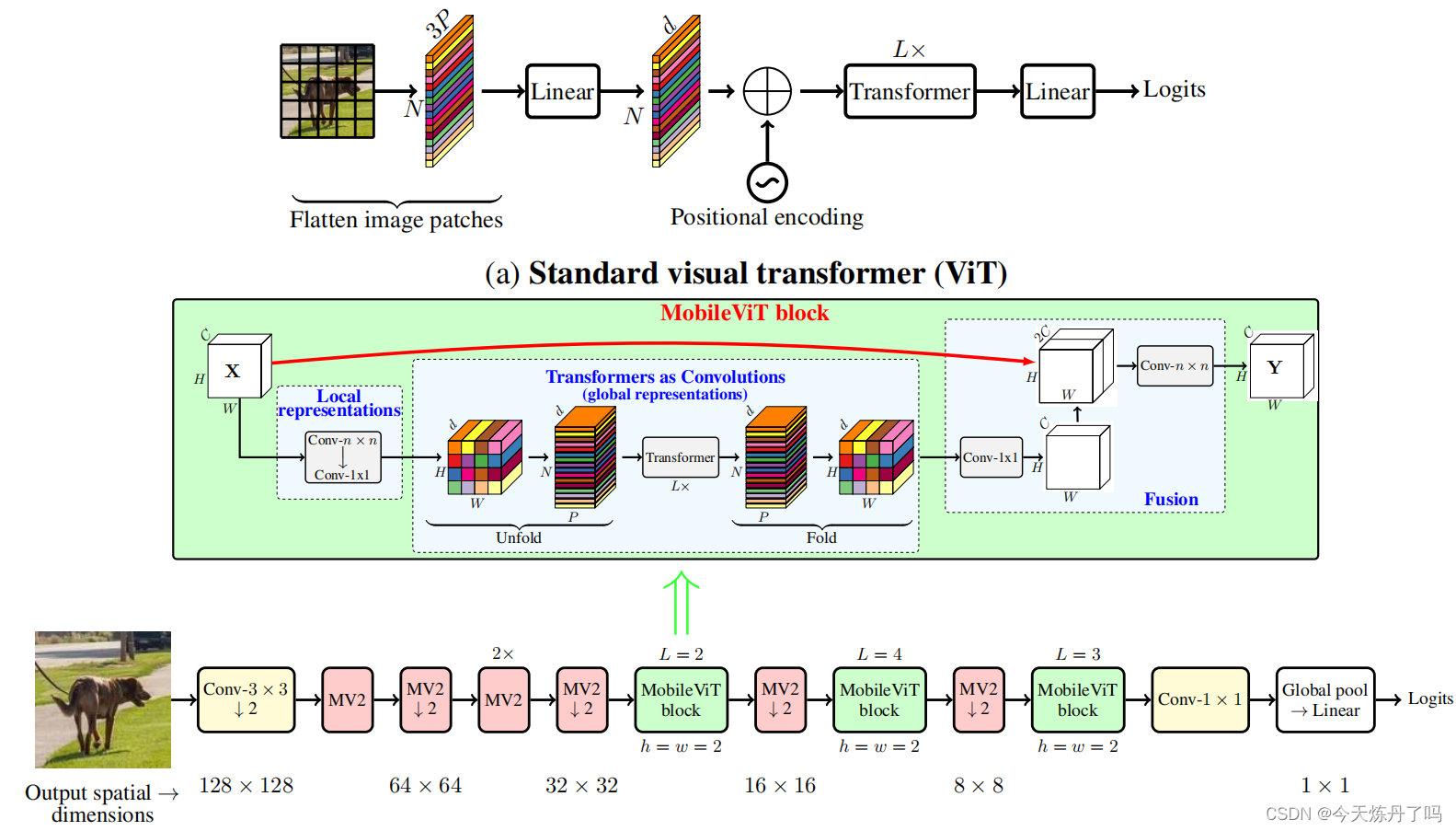
《Selective Kernel Networks》
SK是一个动态选择机制,允许每个神经元根据输入信息动态调整其感受野大小。设计了选择性核(SK)单元作为构建块,其中不同核大小的多个分支通过由这些分支中的信息引导的softmax注意力进行融合。这些分支上的不同注意力会产生融合层中神经元的不同大小的有效的感受野。多个SK单元堆叠成一个称为选择性核网络(SKNet)的深层网络。
import numpy as np
import torch
from torch import nn
from torch.nn import init
from collections import OrderedDict
class SKAttention(nn.Module):
def __init__(self, channel=512, kernels=[1, 3, 5, 7], reduction=16, group=1, L=32):
super().__init__()
self.d = max(L, channel // reduction)
self.convs = nn.ModuleList([])
for k in kernels:
self.convs.append(
nn.Sequential(OrderedDict([
('conv', nn.Conv2d(channel, channel, kernel_size=k, padding=k // 2, groups=group)),
('bn', nn.BatchNorm2d(channel)),
('relu', nn.ReLU())
]))
)
self.fc = nn.Linear(channel, self.d)
self.fcs = nn.ModuleList([])
for i in range(len(kernels)):
self.fcs.append(nn.Linear(self.d, channel))
self.softmax = nn.Softmax(dim=0)
def forward(self, x):
bs, c, _, _ = x.size()
conv_outs = []
### split
for conv in self.convs:
conv_outs.append(conv(x))
feats = torch.stack(conv_outs, 0) # k,bs,channel,h,w
### fuse
U = sum(conv_outs) # bs,c,h,w
### reduction channel
S = U.mean(-1).mean(-1) # bs,c
Z = self.fc(S) # bs,d
### calculate attention weight
weights = []
for fc in self.fcs:
weight = fc(Z)
weights.append(weight.view(bs, c, 1, 1)) # bs,channel
attention_weughts = torch.stack(weights, 0) # k,bs,channel,1,1
attention_weughts = self.softmax(attention_weughts) # k,bs,channel,1,1
### fuse
V = (attention_weughts * feats).sum(0)
return V
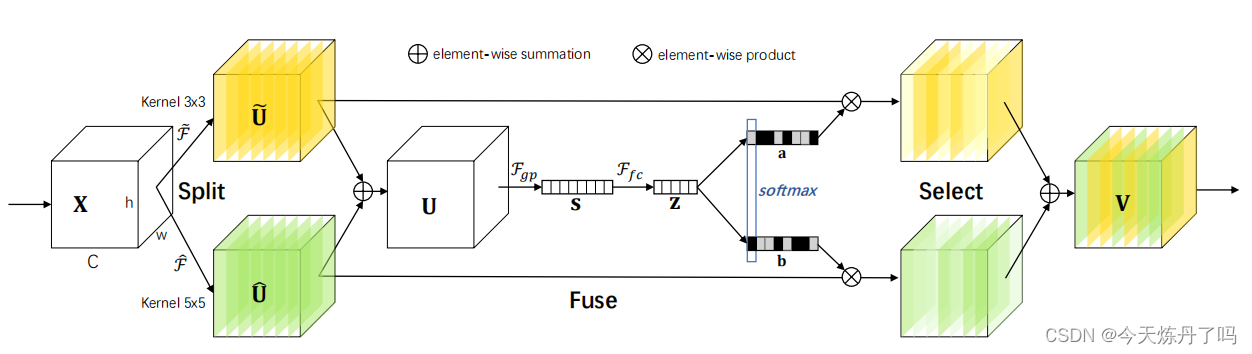
《A2 -Nets: Double Attention Networks》
A2Nets是一种新的神经网络组件,名为“双注意力块”,它能够从整个输入图像/视频中提取重要的全局特征,并使神经网络更有效地访问整个空间的特征,从而提高识别任务的性能。实验表明,配备双注意力块的神经网络在图像和动作识别任务上均优于现有的更大规模神经网络,同时参数和计算量也减少。

import numpy as np
import torch
from torch import nn
from torch.nn import init
from torch.nn import functional as F
class DoubleAttention(nn.Module):
def __init__(self, in_channels,c_m=128,c_n=128,reconstruct = True):
super().__init__()
self.in_channels=in_channels
self.reconstruct = reconstruct
self.c_m=c_m
self.c_n=c_n
self.convA=nn.Conv2d(in_channels,c_m,1)
self.convB=nn.Conv2d(in_channels,c_n,1)
self.convV=nn.Conv2d(in_channels,c_n,1)
if self.reconstruct:
self.conv_reconstruct = nn.Conv2d(c_m, in_channels, kernel_size = 1)
self.init_weights()
def init_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
init.kaiming_normal_(m.weight, mode='fan_out')
if m.bias is not None:
init.constant_(m.bias, 0)
elif isinstance(m, nn.BatchNorm2d):
init.constant_(m.weight, 1)
init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
init.normal_(m.weight, std=0.001)
if m.bias is not None:
init.constant_(m.bias, 0)
def forward(self, x):
b, c, h,w=x.shape
assert c==self.in_channels
A=self.convA(x) #b,c_m,h,w
B=self.convB(x) #b,c_n,h,w
V=self.convV(x) #b,c_n,h,w
tmpA=A.view(b,self.c_m,-1)
attention_maps=F.softmax(B.view(b,self.c_n,-1))
attention_vectors=F.softmax(V.view(b,self.c_n,-1))
# step 1: feature gating
global_descriptors=torch.bmm(tmpA,attention_maps.permute(0,2,1)) #b.c_m,c_n
# step 2: feature distribution
tmpZ = global_descriptors.matmul(attention_vectors) #b,c_m,h*w
tmpZ=tmpZ.view(b,self.c_m,h,w) #b,c_m,h,w
if self.reconstruct:
tmpZ=self.conv_reconstruct(tmpZ)
return tmpZ
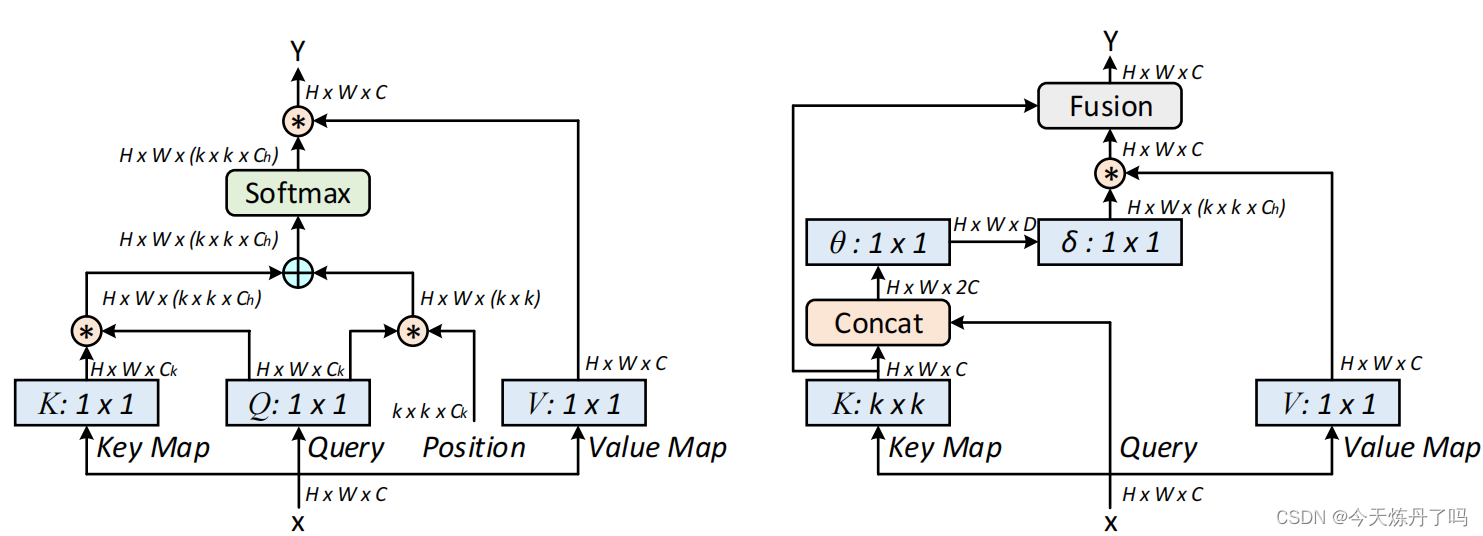
《Large Selective Kernel Network for Remote Sensing Object Detection》
CoTAttention网络是一种用于多模态场景下的视觉问答(Visual Question Answering,VQA)任务的神经网络模型。它是在经典的注意力机制(Attention Mechanism)上进行了改进,能够自适应地对不同的视觉和语言输入进行注意力分配,从而更好地完成VQA任务。CoTAttention网络中的“CoT”代表“Cross-modal Transformer”,即跨模态Transformer。在该网络中,视觉和语言输入分别被编码为一组特征向量,然后通过一个跨模态的Transformer模块进行交互和整合。在这个跨模态的Transformer模块中,Co-Attention机制被用来计算视觉和语言特征之间的交互注意力,从而实现更好的信息交换和整合。在计算机视觉和自然语言处理紧密结合的VQA任务中,CoTAttention取得了很好的效果。
此代码暂没调试,代码地址:https://github.com/JDAI-CV/CoTNet/tree/master/cot_experiments



![[通用] iPad 用于 Windows 扩展屏解决方案 Moonlight + Sunshine + Easy Virtual Display](https://img-blog.csdnimg.cn/direct/2e0d41da05164192b2c59ceabf5afbcc.png)



![[AutoSar]BSW_Com08 CAN driver 模块介绍及参数配置说明 (一)](https://img-blog.csdnimg.cn/direct/1b3bc82bec7643d39e5385246ca54cd6.png)