0 引出

如上图:给定字符串按定长编码处理,最终对应二进制长度为359
思考:如何压缩,将359有效降低? ----回顾:赫夫曼树
1 数据压缩
- 拿到数据(字符串)的第一反应,虽然知道应该也像上面一样转为字节数组,但就不知道该怎么办了?
- 统计数组中各字节使用的次数,将次数作为权值,字节值作为数据,创建节点,用于构建赫夫曼树,思考为什么创建赫夫曼树?
- 使用赫夫曼树的目的? 答案是前缀编码,因为当你知道哪个字节出现的多,你本能就想把较小的编码分给它,举例:数据统计得到100个a,50个b,10个c,那么你会这样编码:a=0,b=1,c=10,那么当你解压时会很头痛,解压遇到10,你知道这是ba还是c吗?
- 通过赫夫曼树得到的编码,能避免一个字节的编码是另一个编码的前缀,比如:b的编码是c的前缀
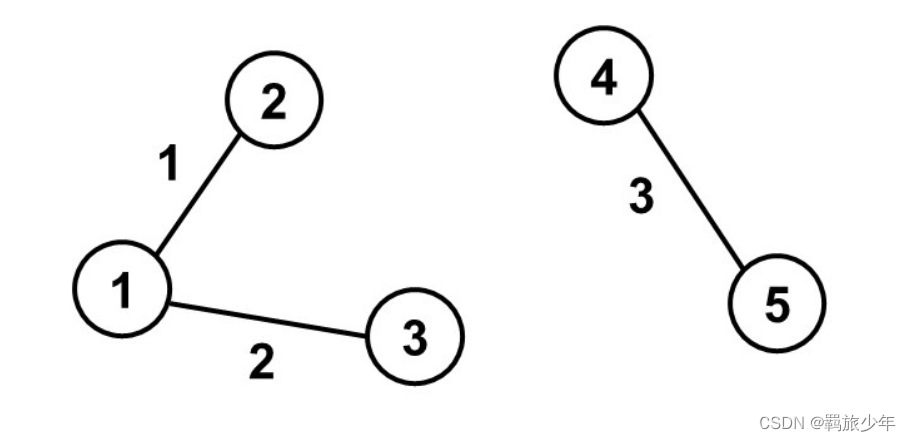
- 赫夫曼树构建完毕,如何得到编码表? 编写递归(回溯)方法,收集所有叶子节点的路径表示的二进制数,向左则路径追加0,向右则追加1,直到遇到叶子节点,得到编码表{32=01, 97=100, 100=11000, 117=11001, 101=1110, 118=11011, 105=101, 121=11010, 106=0010, 107=1111, 108=000, 111=0011},下图图解(图为引用,所以与本文有出入,但不影响理解)
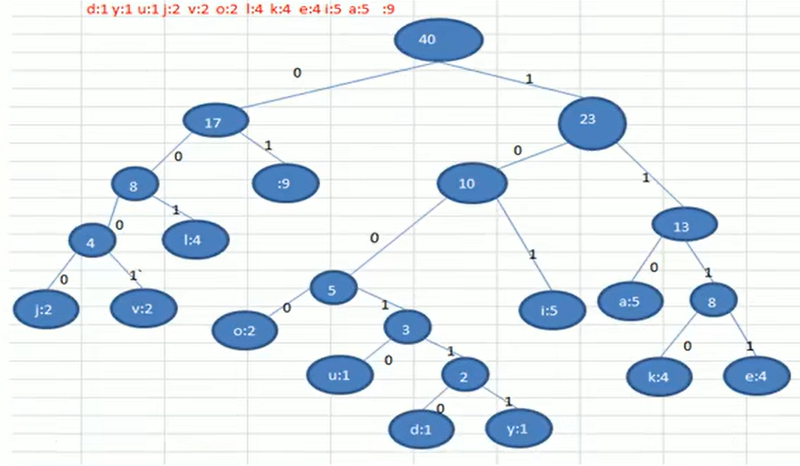
- 有了编码表,对照将第一步中的字节数组转换,得到二进制序列(长度133),按8位一次转为字节数组,压缩完毕
- 最终统计:二进制序列压缩比133/359,对应的字节数组压缩比17/40
2 数据解压缩
- 拿到压缩后的字节数组,和编码表,如何恢复呢?
- 首先,将字节数组中的每个字节转为二进制字符串,并追加为一个长二进制字符串
- 处理编码表,将键值位置互换,准备匹配
- 对照处理后的编码表,对二进制字符串暴力匹配,将匹配的字节收集到数组中
- 利用结果数组创建字符串,完成解压缩
3 文件压缩与恢复
压缩:
- 通过字节输入流读取外部文件,并将内容存放在字节数组中
- 对字节数组使用第一章的赫夫曼压缩,得到压缩后字节数组
- 将压缩后的字节数组序列化到外部路径
- 完成文件的压缩,得到压缩文件
恢复:
- 将4中的压缩文件反序列化,得到压缩后的字节数组
- 对压缩后的字节数组调用第二章的解压方法,恢复到原来的字节数组
- 将原字节数组通过字节输出流,写出到外部路径
- 完成文件的解压,得到原大小文件
4 代码合集
//赫夫曼压缩
public class App03_HuffmanCode {
public static void main(String[] args) {
//得到待压缩字符串,转字节数组->统计各字节的使用次数(权值),构建树节点->创建赫夫曼树->生成赫夫曼编码表->对字节数组进行压缩
String str = "i like like like java do you like a java";
byte[] bytes = str.getBytes();
//压缩
byte[] huffmanCodeBytes = huffmanZip(bytes);
System.out.println(result);
System.out.println(Arrays.toString(huffmanCodeBytes));
//解压
System.out.println(new String(decode(result, huffmanCodeBytes)));
//压缩文件
// zipFile();
//解压文件
// unzipFile();
//测试
// System.out.println((byte)Integer.parseInt("10101000",2));
// System.out.println(byteToBitString((byte) -90, 8));
// System.out.println(byteToBitString((byte) 28, 6));
// System.out.println(byteToBitString((byte) 1, 8));
}
//解压文件
public static void unzipFile(String src, String dest) {
FileInputStream is = null;
FileOutputStream os = null;
ObjectInputStream ois = null;
try {
is = new FileInputStream(src);
ois = new ObjectInputStream(is);
byte[] hmBytes = (byte[]) ois.readObject();
HashMap<Byte, String> hmCode = (HashMap<Byte, String>) ois.readObject();
byte[] bytes = decode(hmCode, hmBytes);
os = new FileOutputStream(dest);
os.write(bytes);
} catch (Exception e) {
e.getMessage();
} finally {
try {
os.close();
ois.close();
is.close();
System.out.println("解压成功~");
} catch (Exception e) {
System.out.println(e.getMessage());
}
}
}
//压缩文件
public static void zipFile(String src, String dest) {
FileInputStream is = null;
FileOutputStream os = null;
ObjectOutputStream oos = null;
try {
is = new FileInputStream(src);
byte[] bytes = new byte[is.available()];
is.read(bytes);
byte[] hmBytes = huffmanZip(bytes);
os = new FileOutputStream(dest);
oos = new ObjectOutputStream(os);
oos.writeObject(hmBytes);
oos.writeObject(result);
} catch (Exception e) {
e.getMessage();
} finally {
try {
oos.close();
os.close();
is.close();
System.out.println("压缩成功~");
} catch (Exception e) {
System.out.println(e.getMessage());
}
}
}
//解压缩:使用赫夫曼编码表对压缩字节数组解压缩
public static byte[] decode(Map<Byte, String> code, byte[] huffmanBytes) {
StringBuilder stringBuilder = new StringBuilder();
for (int i = 0; i < huffmanBytes.length; i++) {
int len = (i == (huffmanBytes.length - 1)) ? 5 : 8;//这里为什么是5需要知道原二进制码字符串的总长
stringBuilder.append(byteToBitString(huffmanBytes[i], len));
}
// System.out.println(stringBuilder.toString());
HashMap<String, Byte> map = new HashMap<>();
for (Map.Entry<Byte, String> entry : code.entrySet()) {
map.put(entry.getValue(), entry.getKey());
}
// System.out.println(map);
ArrayList<Byte> list = new ArrayList<>();
int index = 0;
for (int i = 1; i <= stringBuilder.length(); i++) {
if (map.get(stringBuilder.substring(index, i)) != null) {
list.add(map.get(stringBuilder.substring(index, i)));
index = i;//左闭右开,i需要取到huffmanBytes.length
}
}
byte[] bytes = new byte[list.size()];
for (int i = 0; i < list.size(); i++) {
bytes[i] = list.get(i);
}
return bytes;
}
//解码工具:将byte转二进制字符串
//该方法仅对8位的byte转换有效,至于不足8位需考虑去高位,而且得知道保留几位,28=00011100=011100
public static String byteToBitString(byte b,int len) {
//转换后问题:负数需要截取,正数需要补
//做法:先按位与再转再截取低8位
int temp = b;
temp |= 256;
String str = Integer.toBinaryString(temp);
String s = str.substring(str.length() - 8);
return s.substring(s.length() - len);
}
//赫夫曼压缩(封装):直接压缩字节数组并返回压缩后的
public static byte[] huffmanZip(byte[] bytes) {
List<Node> nodes = getNodes(bytes);
Node root = createHuffmanTree(nodes);
getCodesFromRoot(root);
return zip(bytes, result);
}
//压缩之四:将字节数组对照编码表转二进制,再转回字节数组
public static byte[] zip(byte[] bytes, HashMap<Byte, String> hashMap) {
StringBuilder stringBuilder = new StringBuilder();
for (byte b : bytes) {
stringBuilder.append(hashMap.get(b));
}
//133位二进制序列
// System.out.println(stringBuilder.toString());
int len = (stringBuilder.length() + 7) / 8;
byte[] bys = new byte[len];
int index = 0;
if (stringBuilder.length() % 8 == 0) {
for (int i = 0; i< stringBuilder.length(); i += 8) {
//八位二进制取真值(补码求源码),借用Integer的API
bys[index++] = (byte) Integer.parseInt(stringBuilder.substring(i, i + 8),2);
}
} else {
int i = 0;
while (i+8 < stringBuilder.length()) {
bys[index++] = (byte) Integer.parseInt(stringBuilder.substring(i, i + 8),2);
i += 8;
}
//不足8位则高位补0
bys[len-1]=(byte) Integer.parseInt(stringBuilder.substring(i),2);
}
return bys;
}
//压缩之三:getCodes编码方法的封装
public static void getCodesFromRoot(Node root) {
if (root != null) {
getCodes(root.getLeft(),"0");
path.delete(path.length() - 1, path.length());
//这里不是递归调用,不会对上面的代码造成影响,因为找没找到都结束了,所以可以不回溯
//可以理解为:最后一道大题都解完了(所有路径收集完毕),辅助线擦不擦无所谓了
getCodes(root.getRight(),"1");
path.delete(path.length() - 1, path.length());
}
}
//路径
private static StringBuilder path = new StringBuilder("");
//结果集
private static HashMap<Byte, String> result = new HashMap<>();
//压缩之三:收集叶子的路径作为编码,即生成编码表
//节点为空之前,先到叶子节点,递归直接终止了,因此可以不加节点的空校验
public static void getCodes(Node node,String code) {
path.append(code);
//当前为叶子节点
if (node.getData()!= null) {
result.put(node.getData(), path.toString());
return;
}
getCodes(node.getLeft(),"0");
//为什么需要回溯?
//只要进入调用的方法,路径就会变化,方法有2种操作,1:递归终止,取消路径变化;2:继续递归,暂时保留路径变化
//因此需要回溯以取消对该节点的操作
//简单理解就是解几何题过程中,需要画辅助线,如果解题完成,则需要擦除辅助线,否则需要不停画辅助线以解出答案
path.delete(path.length() - 1, path.length());
getCodes(node.getRight(),"1");
//这里不算解题完成吗,为什么辅助线不能擦? 上一行执行完毕,只能说明找到一个叶子节点,即仅拿到一条路径
path.delete(path.length() - 1, path.length());
}
//压缩之二:创建赫夫曼树
public static Node createHuffmanTree(List<Node> list) {
while (list.size() > 1) {
Collections.sort(list);
Node left = list.get(0);
Node right = list.get(1);
Node parent = new Node(null, left.getweight() + right.getweight());
parent.setLeft(left);
parent.setRight(right);
list.remove(left);
list.remove(right);
list.add(parent);
}
return list.get(0);
}
//压缩之一:字节数组转为节点集合
public static List<Node> getNodes(byte[] bytes) {
ArrayList<Node> nodes = new ArrayList<>();
HashMap<Byte, Integer> temp = new HashMap<>();
for (byte b : bytes) {
temp.put(b, temp.get(b) == null ? 1 : temp.get(b) + 1);
}
Set<Map.Entry<Byte, Integer>> entries = temp.entrySet();
for (Map.Entry<Byte, Integer> entry : entries) {
nodes.add(new Node(entry.getKey(), entry.getValue()));
}
return nodes;
}
}
class Node implements Comparable<Node>{
private Byte data;
private int weight;
private Node left;
private Node right;
public Node(Byte data,int weight) {
this.data = data;
this.weight = weight;
}
public Byte getData() {
return data;
}
public void setData(Byte data) {
this.data = data;
}
public int getweight() {
return weight;
}
public void setweight(int weight) {
this.weight = weight;
}
public Node getLeft() {
return left;
}
public void setLeft(Node left) {
this.left = left;
}
public Node getRight() {
return right;
}
public void setRight(Node right) {
this.right = right;
}
@Override
public String toString() {
return "Node [data="+data+",weight=" + weight + "]";
}
//升序
@Override
public int compareTo(Node Node) {
return this.weight-Node.weight;
}
public void preOrder() {
System.out.println(this);
if (this.left != null) {
left.preOrder();
}
if (this.right != null) {
right.preOrder();
}
}
}






![[cpp进阶]C++异常](https://img-blog.csdnimg.cn/e757eed495244cbead947a8b94d26eec.png)