摘要:最近,Transformer在计算机视觉方面取得了令人鼓舞的进展。在本研究中,本文通过增加(1)线性复杂度注意层、(2)重叠贴片嵌入和(3)卷积前馈网络三种设计,改进了原始的金字塔视觉转换器(PVT v1),提出了新的基线。通过这些改进,PVT v2将PVT v1的计算复杂度降为线性,并在分类、检测和分割等基本视觉任务上实现了显著改进。值得注意的是,PVT v2与Swin Transformer等最近的作品相比,取得了相当或更好的性能。本文希望这项工作将促进最先进的变压器在计算机视觉的研究。
相较于PVT,PVTv2增加了三部分 (1) Linear complexity attention layer, (2) Overlapping patch embedding (3) Convolutional feed-forward network.
PVT存在的三点限制:
(1)与ViT类似,当处理高分辨率输入时,PVT v1的计算复杂度相对较大
(2)PVT v1将图像视为非重叠块序列,这在一定程度上失去图像的局部连续
(3)PVT v1中的位置编码是固定大小,这对于任意大小的处理图像是不灵活的
Linear Spatial Reduction Attention (Linear SRA)
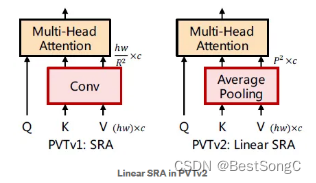
首先为了降低注意操作引起的高计算成本,本文提出了线性空间注意(Linear SRA)层,与使用卷积进行空间约简的SRA不同,线性SRA使用平均池化将空间维数(即h×w)降低到固定的大小(即P×P)。因此线性SRA就像卷积层一样具有线性计算和内存成本
Overlapping Patch Embedding (OPE)
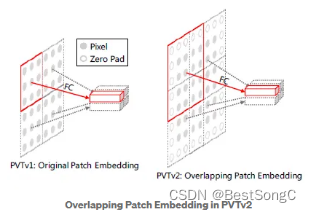
其次,为了对局部连续性信息进行建模,本文利用重叠斑块嵌入技术对图像进行标记化。本文扩大了补丁窗口,使相邻的窗口重叠了一半的区域,并用零填充特征图以保持分辨率。在这项工作中,本文使用卷积与零的padding来实现重叠的补丁嵌入。具体来说,给定大小为h×w×c的输入,本文将其与S的stride、2S−1的核kernel、S−1的padding进行卷积
Convolutional Feed-Forward Network
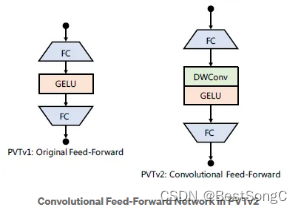
第三本文删除了固定大小的位置编码,并在PVT中引入零填充位置编码,本文在前馈网络中第一个全连接层和GELU之间添加了3×3的深度可分离卷积。 在PVT V1中,位置编码是使用nn.Parameter生成一组可学习的位置编码,在PVT V2中,直接删除了位置编码(作者直接删除了位置编码,在MLP层中添加了深度卷积,用0进行权重初始化)。
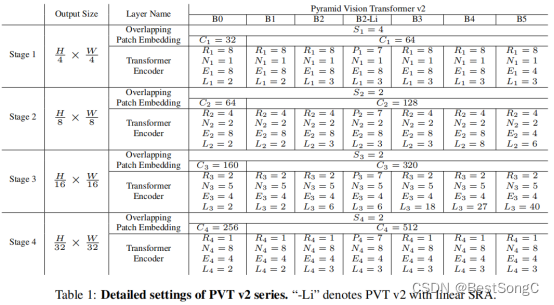
PVTv2变体的具体参数配置如下表所示:
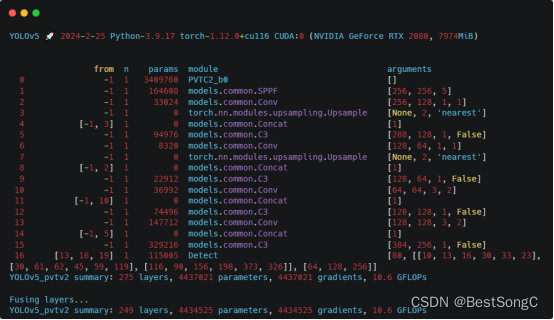
在YOLOv5项目中添加PVTv2模型作为Backbone使用的教程:
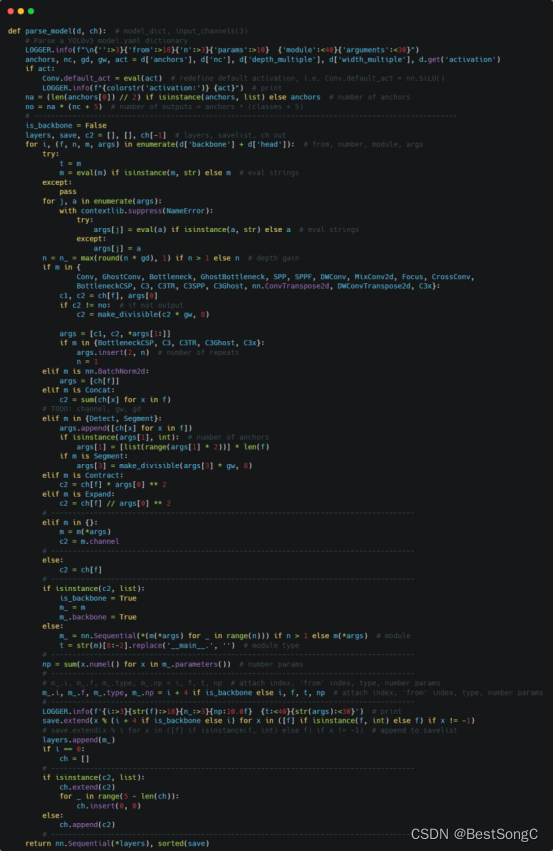
(1)将YOLOv5项目的models/yolo.py修改parse_model函数以及BaseModel的_forward_once函数
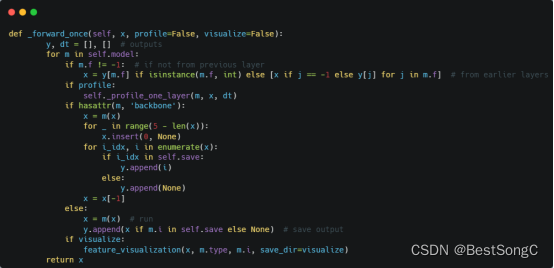
(2)在models/backbone(新建)文件下新建pvtv2.py,添加如下的代码:

(3)在models/yolo.py导入模型并在parse_model函数中修改如下:

(4)在model下面新建配置文件:yolov5_pvtv2.yaml
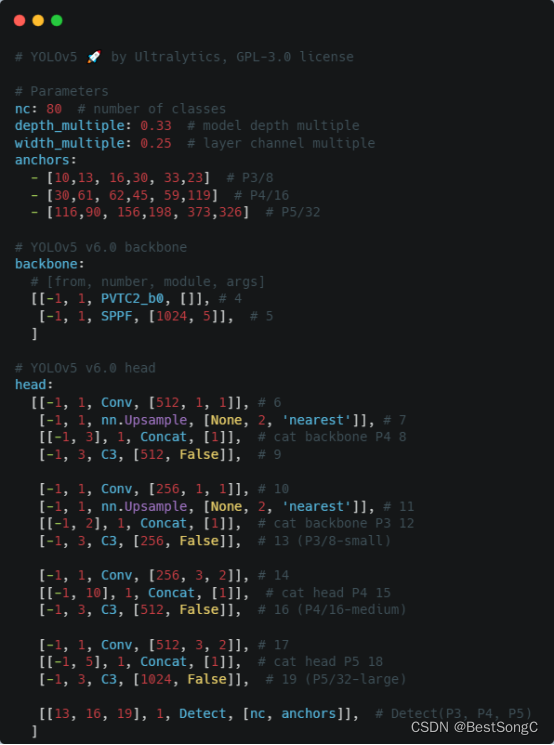
(5)运行验证:在models/yolo.py文件指定–cfg参数为新建的yolov5_pvtv2.yaml