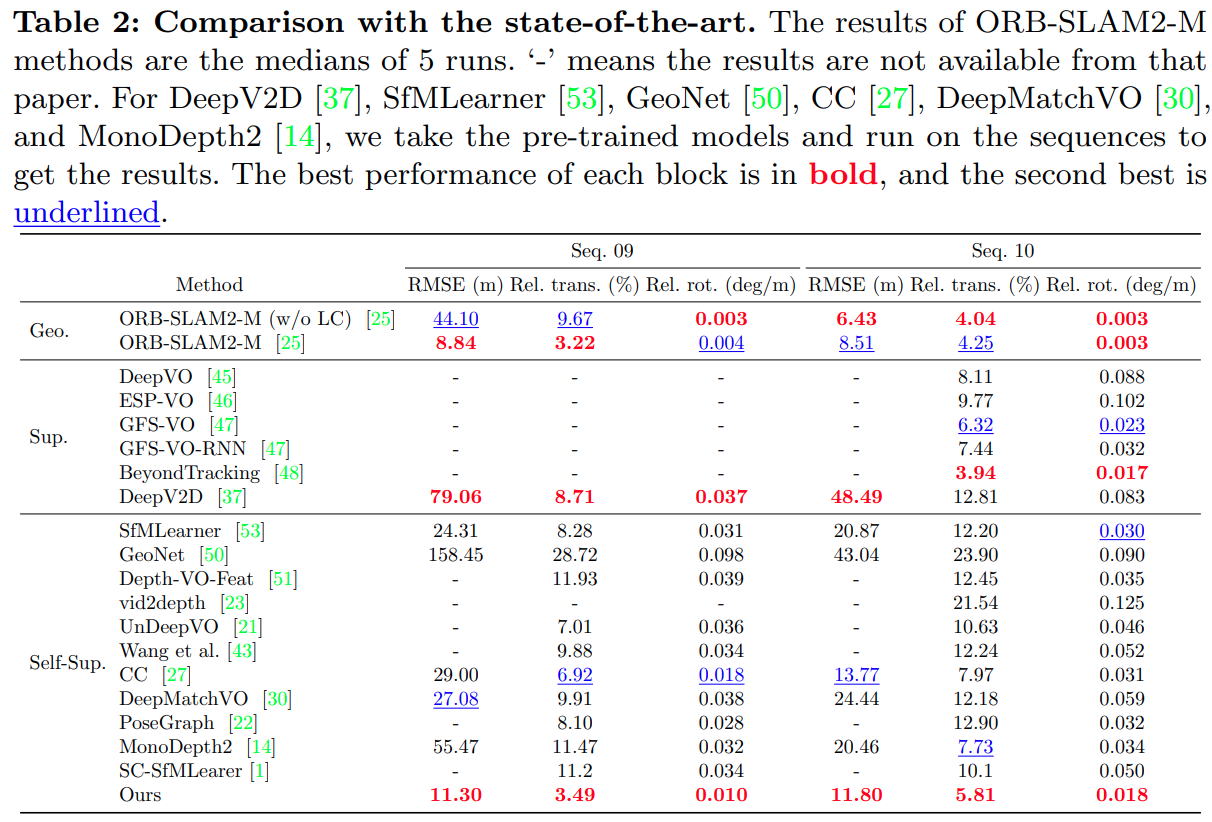
什么是跳表
只要是平衡搜索二叉树能实现的功能,跳表都能实现,且时间复杂度都相同
例如:
- 哈希表的功能:插入,查找,删除
- 有序表的功能:查找大于某值最小的数,小于某值最大的数,按顺序遍历
这些操作的时间复杂度都为O(logN)
跳表在原有的有序链表上面增加了多级索引,通过索引来实现快速查找。跳表不仅能提高搜索性能,同时也可以提高插入和删除操作的性能
整体结构
跳表由一个个节点组成,节点之间按照顺序连接,最左边是头结点
每个节点是一个多层的结构,除了记录值val外,还用nexts记录层级信息,每一层的指针指向下一个节点
我们设计的跳表支持重复插入,需要用count记录数量
static class SkipNode {
int val;
int count;
private List<SkipNode> nexts;
public SkipNode(int val) {
this.val = val;
this.count = 1;
this.nexts = new ArrayList<>();
}
}
至于有多少层,完全根据概率决定,层级越高,概率越低。因此跳表中需要维护一个概率rate
同时需要记录最左边的头结点head,和最大的层数maxLevel
static class SkipMap {
private double rate;
private SkipNode head;
private int maxLevel;
public SkipMap(double rate) {
this.rate = rate;
this.head = new SkipNode(0);
// 初始化第0层
this.head.nexts.add(null);
this.maxLevel = 0;
}
每个节点按照一定的顺序从左往右排列,相同的层级会用指针串联起来
例如下图的跳表:节点0,3只有一层,节点2,4有至少两层,因此head中level等于1的指针会直接连向节点2,再从2连向节点4

查找
流程
要查找跳表中是否有元素key:
- 从head节点maxLevel层开始找,
找每一层小于key的最后一个节点,记为cur
- 因为是从head开始找,我们假设head的节点值为无限小,那么在每一层一定能找到最后一个小于key的节点
- 然后从cur的下一层开始寻找,重复步骤1
- 直到找到最后一层节点为止
例如,要在如下的跳表中查看是否有元素3:
- 从head节点的第maxLevel层,也就是第3层开始找,其下一个节点值为4,大于等于3,因此从第2层开始找
- 第2层的下一个节点还是4,继续降低层级
- 第1层的下一个节点为2,比3小,跳到该节点,继续看该节点的下一个节点为4,大于等于3,降低层级
- 第0层的下一个节点为3,就等于参数key,返回下一个节点
整个流程如下图所示:

怎么判断跳表中是否存在元素key?
因为跳表中的节点一层存在第0层,现在找到了第0层中,小于key最右边的的节点cur
如果key存在,那么cur右边的节点的值一定为key
因此判断cur.nexts.get(0).val== key就好了
正确性证明
这种做法有没有在可能查找的路径中漏掉一些元素,导致跳表中客观上有该元素,却返回没找到?
根据概率,层级越高的节点越稀疏,因此从高层开始查找,一次可能跳过很多节点
示例中,当路径从head到节点2时,跳过了节点0,节点2小于key,由于跳表中的节点按照顺序从左到右排列,那些被跳过的节点一定也小于key,而又在节点2的左边,不可能成为小于key且最右边的节点,因此跳过这些节点没有问题
当cur的下一个节点的值大于等于key时,不能再往右跳了,需要在当前节点降低层级查找
下一层级可能有更多的节点,next连到了小于key的节点,又能继续跳
由于只排除了不可能成为答案的节点,因此正确性没有问题
时间复杂度
当数据量较大时,概率分布均匀,平均每层跳过剩余节点的一半的节点,因此时间复杂度为O(logN)
代码实现
在level层里找小于key最右的节点:
// level:在哪一层找
// cur:从哪个节点开始找
// key:需要小于的值
public SkipNode mostRightLessKeyInLevel(int level, SkipNode cur,int key) {
SkipNode next = cur.nexts.get(level);
while (next != null && next.val < key) {
cur = next;
next = next.nexts.get(level);
}
return cur;
}
查找:
public SkipNode find(int key) {
int level = maxLevel;
SkipNode cur = head;
while (level >= 0) {
cur = mostRightLessKeyInLevel(level,cur,key);
level--;
}
if (cur.nexts.get(0) != null && cur.nexts.get(0).val == key) {
return cur.nexts.get(0);
}
return null;
}
插入
往跳表中插入节点的步骤如下:
-
随机决定层数newLevel
- 生成0~1的随机数,如果小于rate,就增加层数,直到大于rate位置
需要控制跳表的平均层级时,可以将rate调小,一般使用可以设置为0.5,redis设置为0.25,因此redis的跳表平均层数很低
-
如果maxLevel小于newLevel,将head的层级增加到newLevel
-
新建待插入节点newNode,初始化有newLevel个层级
-
从head节点,maxLevel层开始
- 每一层找比key小,最右的节点,将newNode串到该节点后面
- 去下一层级找,不断重复这个过程,直到第0层串完为止
例如:往下图的跳表中插入key为4,newLevel为6的节点:

代码实现如下:
public void put(int key) {
SkipNode existNode = find(key);
if (existNode != null) {
existNode.count++;
return;
}
size++;
// 随机决定层数
int newLevel = 0;
while (Math.random() <= this.rate) {
newLevel++;
}
// 将head增加到和newLevel一样的层数
while (maxLevel < newLevel) {
head.nexts.add(null);
maxLevel++;
}
// 新建待插入节点newNode,初始化有newLevel个层级
SkipNode newNode = new SkipNode(key);
for (int i = 0;i <= newLevel;i++) {
newNode.nexts.add(null);
}
int level = maxLevel;
SkipNode pre = head;
while (level >= 0) {
// 找到当前层,比key小的最右的节点
pre = mostRightLessKeyInLevel(level, pre, key);
// 只有降到newLevel层才将newNode串到跳表中
if (level <= newLevel) {
// 将newNode串到pre的后面
newNode.nexts.set(level, pre.nexts.get(level));
pre.nexts.set(level, newNode);
}
level--;
}
}
删除
删除的逻辑和插入类似,从head节点的maxLevel层开始找:
- 每一层找比key小,最右的节点,将该节点的next删除
- 降低层级,去下一层找到并删除,直到删完所有层级的数据为止
代码实现如下:
public void remove(int key) {
SkipNode existNode = find(key);
if (existNode != null) {
existNode.count--;
if (existNode.count != 0) {
return;
}
}
size--;
int level = maxLevel;
SkipNode cur = head;
while (level >= 0) {
cur = mostRightLessKeyInLevel(level,cur,key);
SkipNode next = cur.nexts.get(level);
if (next != null && next.val == key) {
cur.nexts.set(level, next.nexts.get(level));
}
level--;
}
}



![【寒假每日一题】洛谷 P6206 [USACO06OCT] Another Cow Number Game G](https://img-blog.csdnimg.cn/b459940c6c4347b49e1b9f256bf4c3c8.png)






![BUUCTF 之 [ACTF2020 新生赛]Exec(命令执行漏洞)](https://img-blog.csdnimg.cn/7b1b089062d4453e87589c85877e7ec7.png)