Paper name
Learning Monocular Visual Odometry via Self-Supervised Long-Term Modeling
Paper Reading Note
URL: https://arxiv.org/pdf/2007.10983.pdf
TL;DR
- ECCV 2020 文章,该文章认为在短时间序列上训练无法在长时间序列上良好泛华,所以受到传统 vo 方案的启发提出了一种基于长时间序列建模的 learning-based vo 方案,取得了当时自监督训练的 sota 效果
Introduction
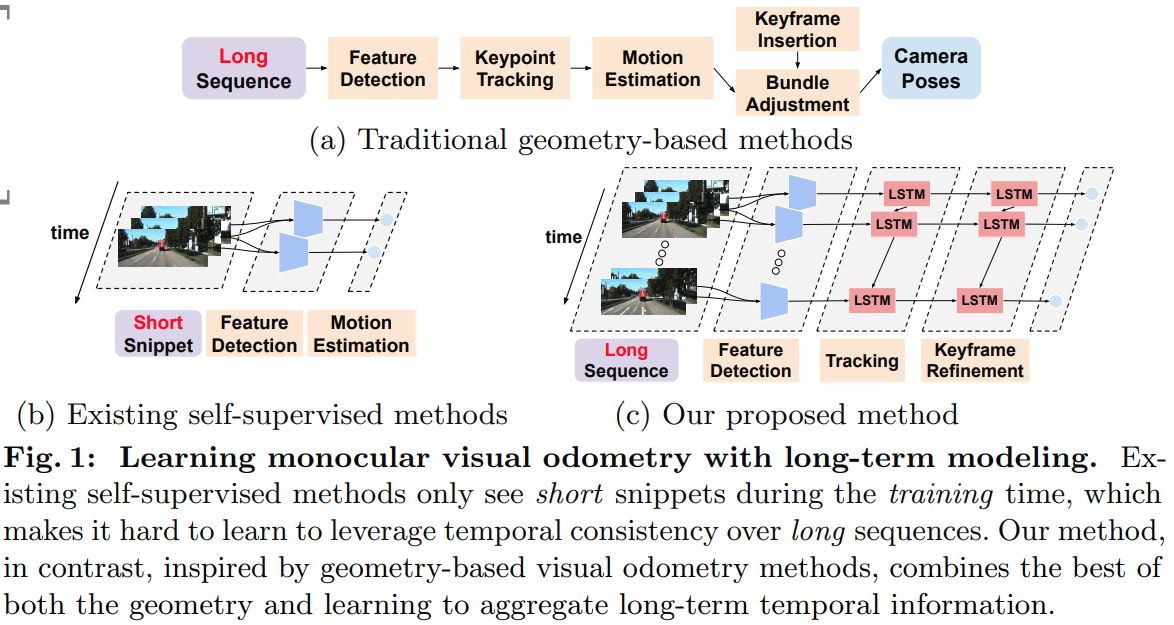
- 单目 vo 一般分为传统 vo 方案和 learning-based vo 方案
- 传统单目 vo 方案如下图,流程为特征点检测、特征点匹配、运动估计、keyframe选取、BA 等环节。
- 关键的思路是通过观察长时间的全局信息来进行状态(6DoF camera poses)更新
- 问题是在低运动场景初始化困难、大范围低纹理区域、快速运动、rolling shutter、不确定的相机内参等困难场景下容易挂
- learning-based vo 方案有潜力通过在得到丰富的先验知识情况下在上述困难场景下做得更好,但目前 learning-based vo 方案的效果一般不如传统 vo 方案
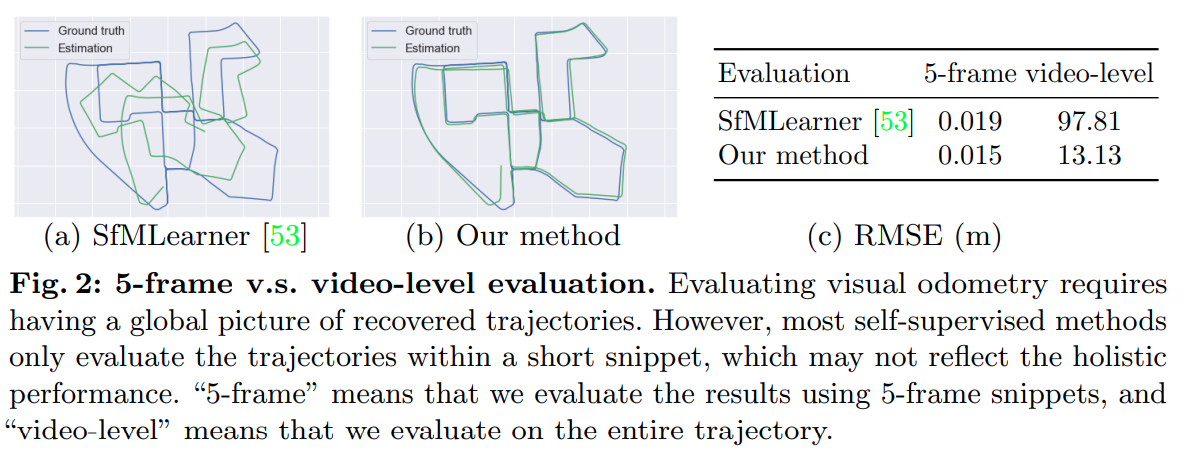
- 作者分析 learning-based 方案效果差的原因是没有利用上长时间序列的时序相关性,因为训练过程中这些网络一般只基于 3 帧或 5 帧数据进行训练,在短时间序列下的评测甚至会比传统方案好,然而将所有短时间序列预测整合后成整体轨迹后效果不好,对比图如下
- 所以本文受到传统 vo 方案的启发,提出一种长时间序列建模的 learning-based VO 方案
- two-layer LSTM 用于建立长时间的时序信息
- 参考传统 vo 方案中的 loop closure 设计的 cycle consistency 约束
- two stage 训练阶段,分别考虑 short-term 和 long-term 约束
Dataset/Algorithm/Model/Experiment Detail
实现方式
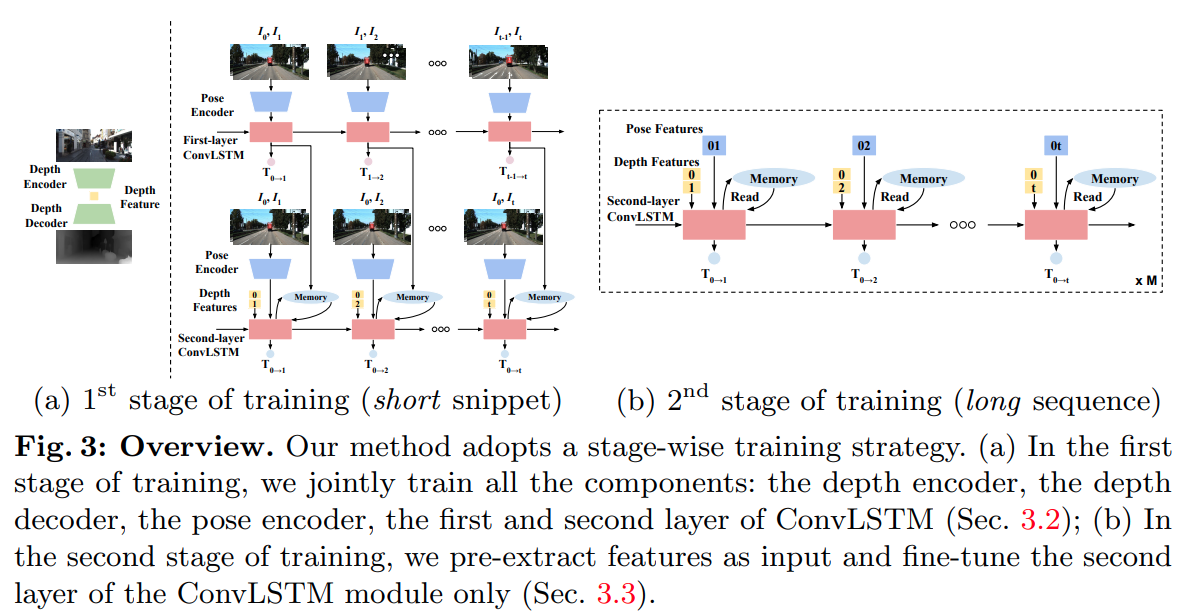
- 分别参考 monodepth 和 flownet 设计了深度估计模块和 pose 估计模块
- depth net:与 monodepth2 一样
- pose network:FlowNet backbone、two-layer LSTM module、two pose prediction head(每个 LSTM 层接一个,第一层聚焦于预测连续帧间运动、第二层修正第一层的预测)
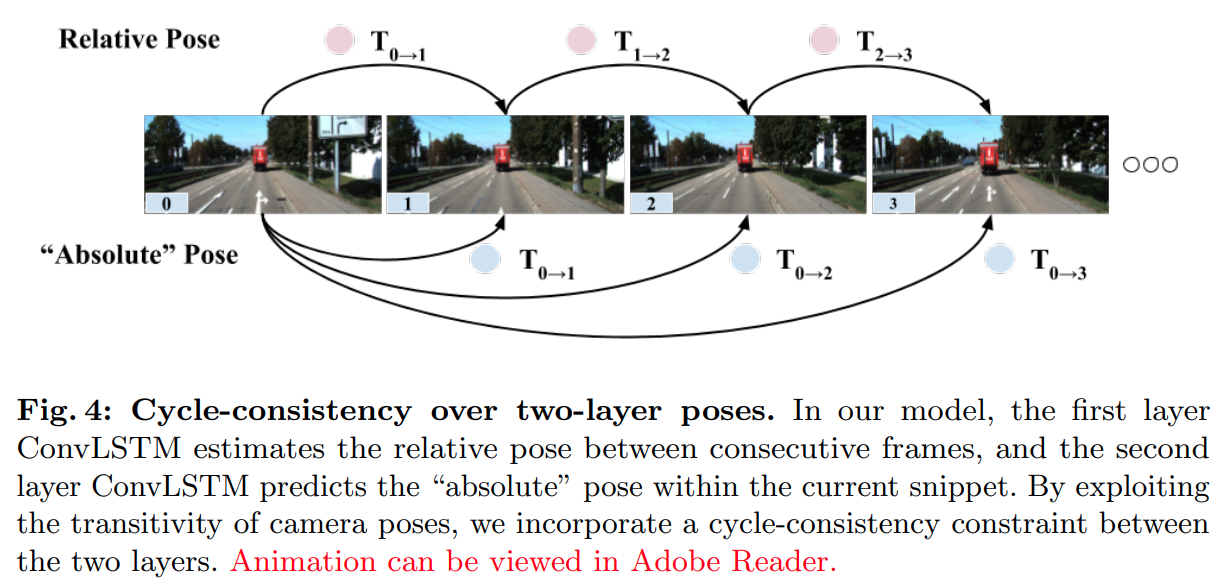
- Cycle-consistency over two-layer poses:确保第一层与第二层预测的 pose 的一致性
- Long-range constraints via stage-wise training:
- 第一层使用短时间序列训练: 7 帧,训练所有 network
- 第二层使用长时间序列训练:97 帧,只训练第二层 LSTM

实验结果
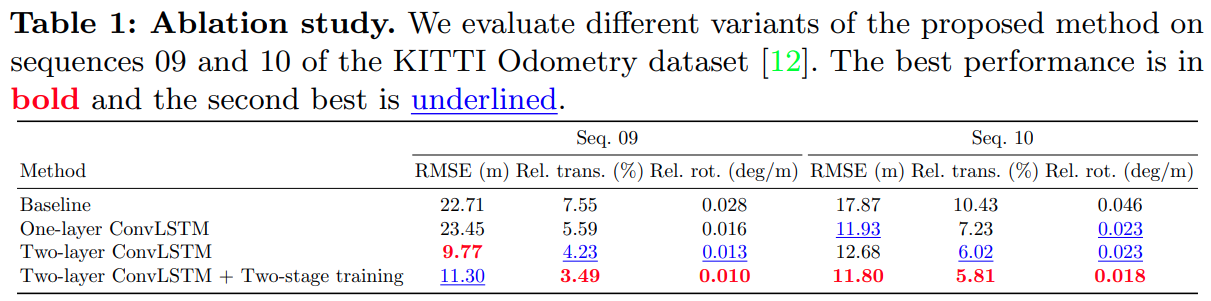
- KITTI 数据集上的消融实验
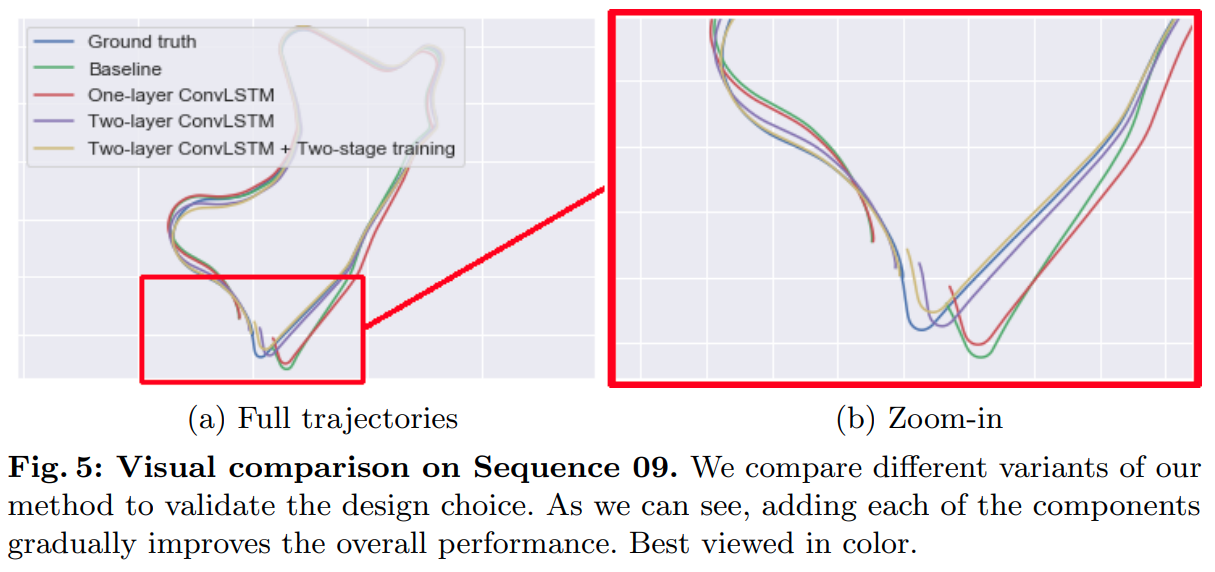
- 可视化对比
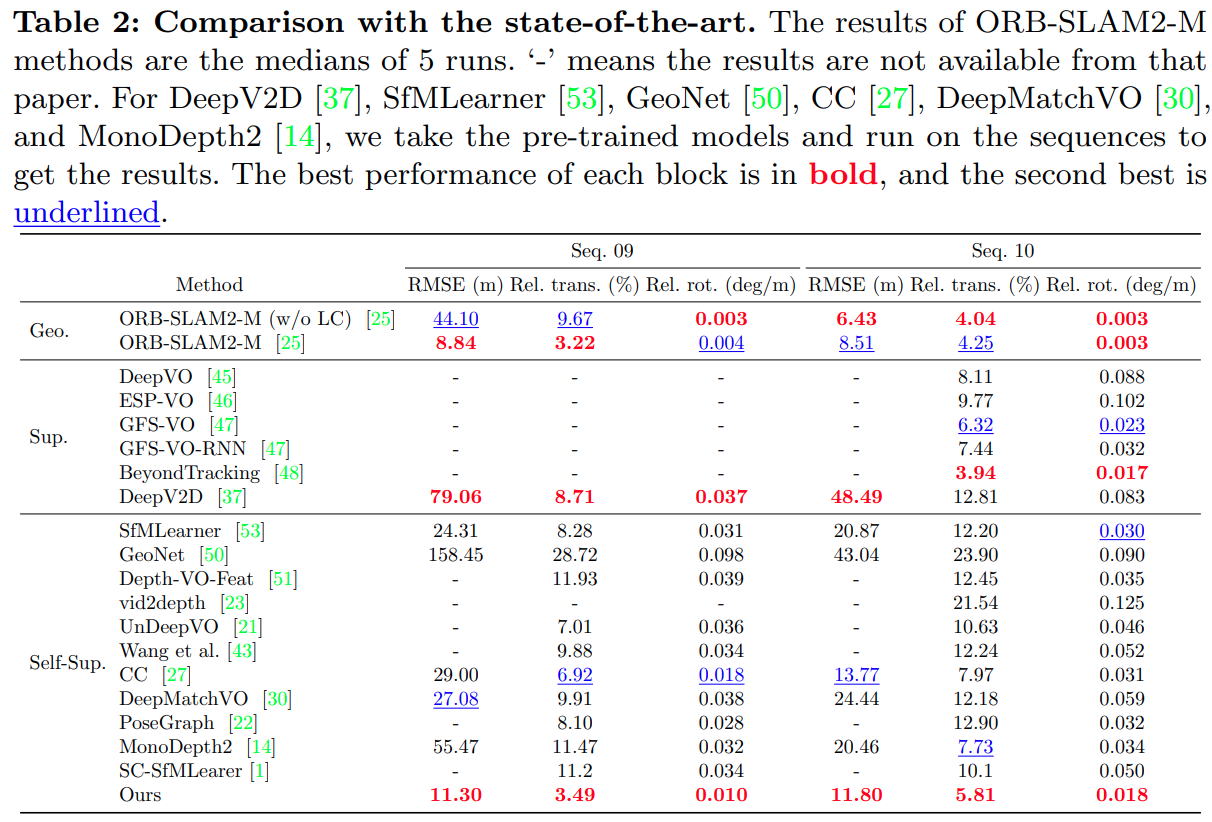
- 与 SOTA 方法对比,在自监督方法中是最好的,binary监督方法精度也高,但是和 orbslam2 等传统 vo 方案比还是稍差一点
Thoughts
- 结合传统方案的优势融入到 learning-based 方案的设计值得借鉴