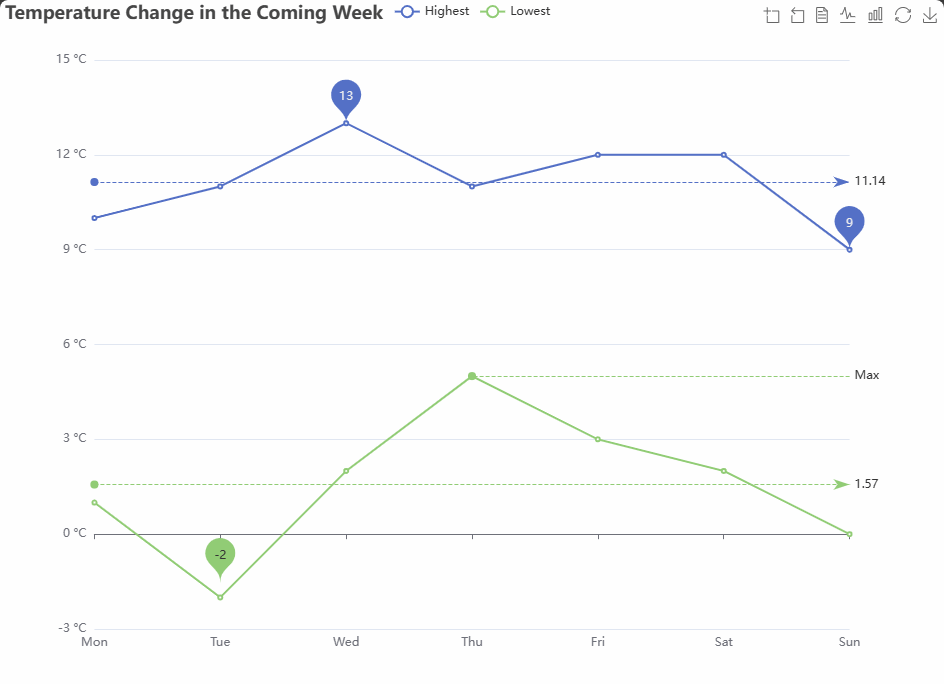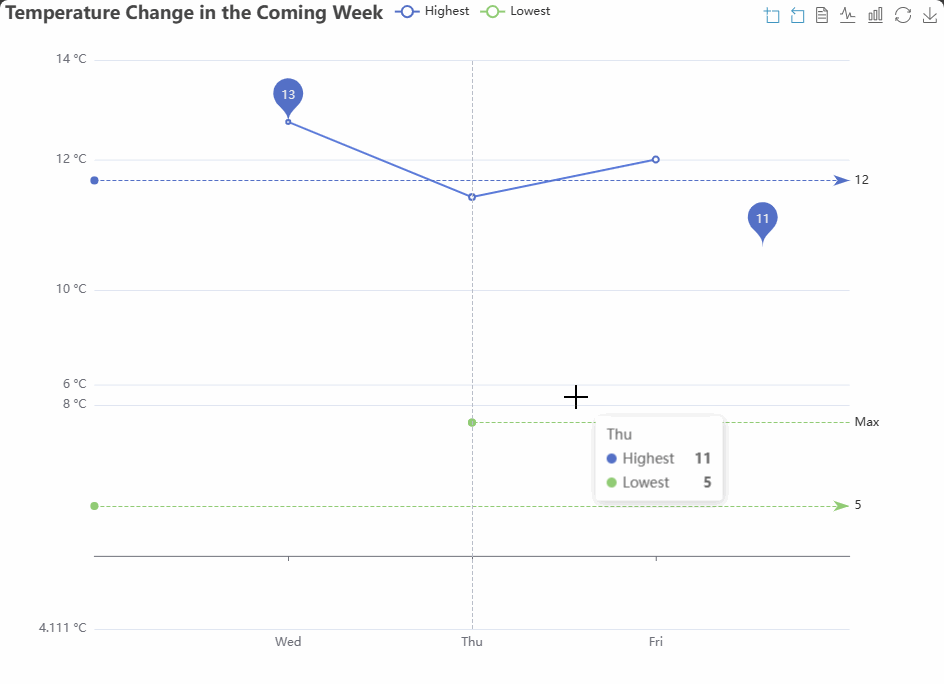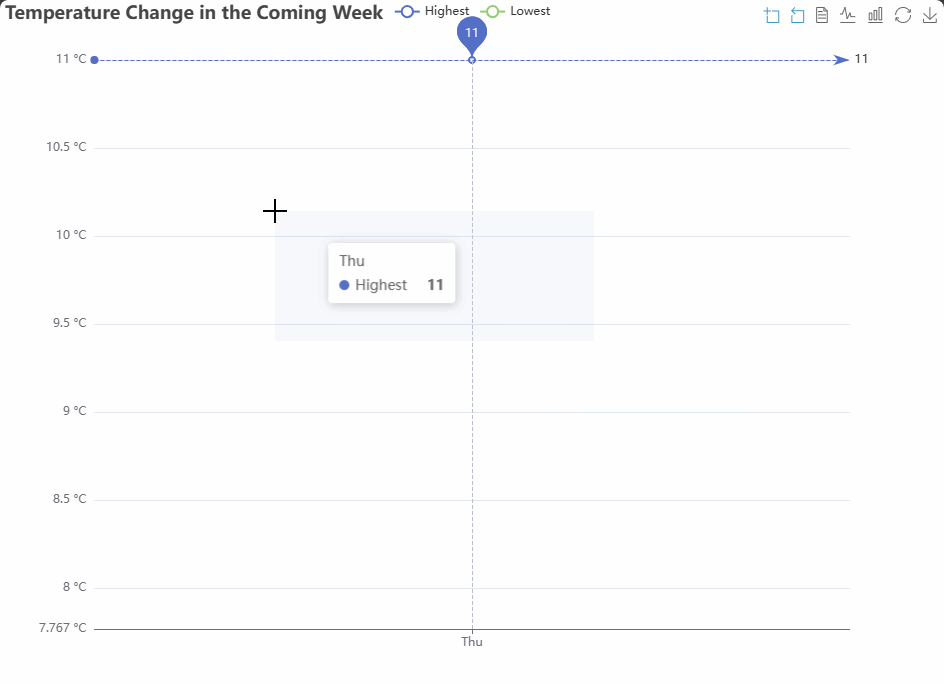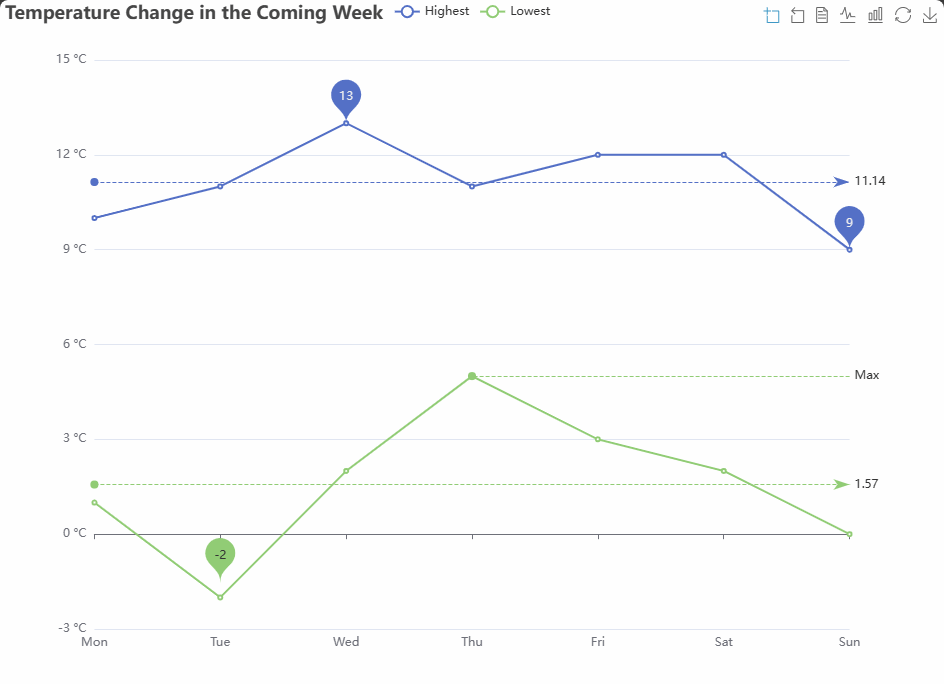
前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家。点击跳转到网站AI学习网站。

目录
前言
什么是Pipeline?
Pipeline的基本用法
Pipeline的高级用法
1. 动态调参
2. 并行处理
3. 多输出
实际应用场景
1. 文本分类任务
2. 特征工程
3. 时间序列预测
总结
前言
在Python数据科学领域,Pipeline(管道)是一个强大的工具,能够将多个数据处理步骤串联起来,形成一个完整的数据处理流程。它不仅能够提高代码的可读性和可维护性,还能够简化数据处理过程,节省大量的开发时间。本文将深入探讨Python中Pipeline的使用方法和技巧,并通过丰富的示例代码来演示其魔法般的效果。
什么是Pipeline?
Pipeline是一种数据处理模式,它将数据处理流程分解为多个独立的步骤,并将这些步骤有序地串联起来,形成一个完整的处理流程。每个步骤都是一个数据处理操作,可以是数据预处理、特征提取、特征选择、模型训练等。Pipeline将这些操作组合在一起,形成一个整体,使得数据处理过程更加清晰和高效。
Pipeline的基本用法
在Python中,可以使用 Pipeline 类来构建一个数据处理管道。
下面是一个简单的示例:
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
from sklearn.linear_model import LogisticRegression
# 创建一个Pipeline
pipeline = Pipeline([
('scaler', StandardScaler()), # 第一个步骤:数据标准化
('pca', PCA(n_components=2)), # 第二个步骤:PCA降维
('classifier', LogisticRegression()) # 第三个步骤:逻辑回归分类器
])
# 使用Pipeline进行数据处理和模型训练
pipeline.fit(X_train, y_train)
# 使用训练好的Pipeline进行预测
y_pred = pipeline.predict(X_test)
在上面的示例中,首先创建了一个Pipeline对象,其中包含了三个步骤:数据标准化、PCA降维和逻辑回归分类器。然后,使用Pipeline对象对训练数据进行拟合,进而进行模型训练和预测。
Pipeline的高级用法
除了基本用法外,Pipeline还提供了许多高级功能,如动态调参、并行处理、多输出等。
1. 动态调参
from sklearn.model_selection import GridSearchCV
# 定义参数网格
param_grid = {
'scaler': [StandardScaler(), MinMaxScaler()],
'pca__n_components': [2, 3, 4],
'classifier__C': [0.1, 1, 10]
}
# 创建带参数网格的Pipeline
grid_search = GridSearchCV(pipeline, param_grid, cv=5)
grid_search.fit(X_train, y_train)
# 获取最佳模型和参数
best_model = grid_search.best_estimator_
best_params = grid_search.best_params_
2. 并行处理
from sklearn.pipeline import make_pipeline
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.feature_extraction.text import TfidfTransformer
from sklearn.naive_bayes import MultinomialNB
# 创建并行Pipeline
pipeline = make_pipeline(
CountVectorizer(),
TfidfTransformer(),
MultinomialNB()
)
3. 多输出
from sklearn.pipeline import FeatureUnion
from sklearn.decomposition import PCA
from sklearn.decomposition import KernelPCA
# 创建多输出Pipeline
pipeline = FeatureUnion([
('pca', PCA(n_components=2)),
('kernel_pca', KernelPCA(n_components=2))
])
实际应用场景
Pipeline 在实际应用中有着广泛的应用场景,下面将介绍一些具体的应用案例,并附上相应的示例代码。
1. 文本分类任务
在文本分类任务中,通常需要对文本数据进行一系列的预处理操作,如文本清洗、分词、词频统计、TF-IDF转换等,然后再使用分类器进行模型训练。Pipeline 可以很好地组织这些处理步骤,使得代码更加清晰和易于管理。
from sklearn.pipeline import Pipeline
from sklearn.feature_extraction.text import CountVectorizer, TfidfTransformer
from sklearn.naive_bayes import MultinomialNB
# 创建文本分类 Pipeline
text_clf = Pipeline([
('vect', CountVectorizer()),
('tfidf', TfidfTransformer()),
('clf', MultinomialNB())
])
# 使用 Pipeline 进行模型训练和预测
text_clf.fit(X_train, y_train)
predicted = text_clf.predict(X_test)
2. 特征工程
在特征工程中,通常需要对不同类型的特征进行不同的处理,如数值型特征进行标准化、类别型特征进行独热编码等。Pipeline 可以将这些处理步骤有序地组合起来,并简化代码结构。
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler, OneHotEncoder
from sklearn.impute import SimpleImputer
from sklearn.compose import ColumnTransformer
# 数值型特征处理 Pipeline
numeric_features = ['age', 'income']
numeric_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='mean')),
('scaler', StandardScaler())
])
# 类别型特征处理 Pipeline
categorical_features = ['gender', 'education']
categorical_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='constant', fill_value='missing')),
('onehot', OneHotEncoder(handle_unknown='ignore'))
])
# 组合不同类型的特征处理 Pipeline
preprocessor = ColumnTransformer(
transformers=[
('num', numeric_transformer, numeric_features),
('cat', categorical_transformer, categorical_features)
])
# 最终 Pipeline 包括特征处理和模型训练
clf = Pipeline(steps=[('preprocessor', preprocessor),
('classifier', LogisticRegression())])
# 使用 Pipeline 进行模型训练和预测
clf.fit(X_train, y_train)
predicted = clf.predict(X_test)
3. 时间序列预测
在时间序列预测任务中,需要对时间序列数据进行滑动窗口分割、特征提取、模型训练等一系列处理。Pipeline 可以将这些处理步骤有序地串联起来,使得代码更加简洁和易于理解。
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import TimeSeriesSplit
# 创建时间序列预测 Pipeline
pipeline = Pipeline([
('scaler', StandardScaler()), # 数据标准化
('regressor', LinearRegression()) # 线性回归模型
])
# 使用 TimeSeriesSplit 进行交叉验证
tscv = TimeSeriesSplit(n_splits=5)
for train_index, test_index in tscv.split(X):
X_train, X_test = X[train_index], X[test_index]
y_train, y_test = y[train_index], y[test_index]
pipeline.fit(X_train, y_train)
predicted = pipeline.predict(X_test)
总结
通过本文的介绍,深入探讨了Python中Pipeline的使用方法和技巧,以及其在实际应用中的价值和优势。Pipeline能够轻松构建复杂的数据处理流程,并提高数据处理和建模的效率。希望本文能够帮助大家更好地理解和应用Pipeline,在数据科学项目中发挥其强大的作用。
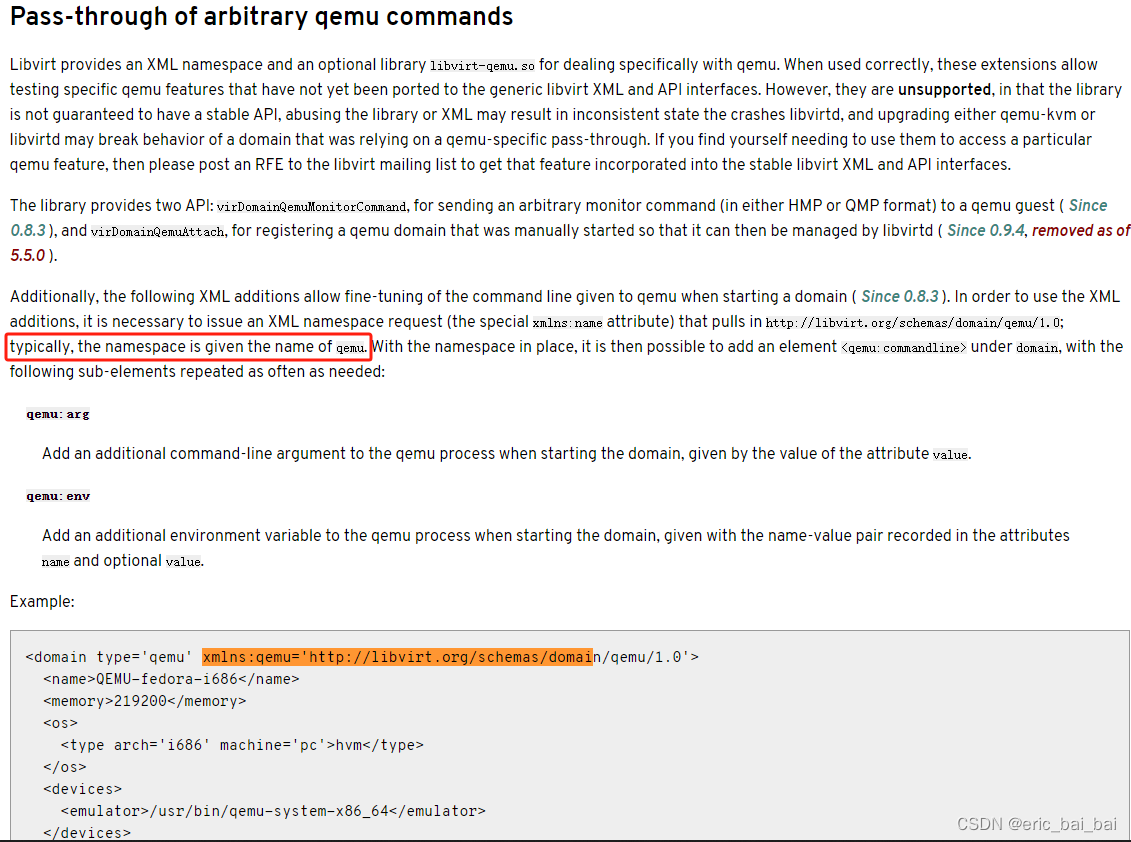


![gcd+线性dp,[蓝桥杯 2018 国 B] 矩阵求和](https://img-blog.csdnimg.cn/direct/089dfcfe8ad64cef994d8e798dcd2922.png)