注解
什么是注解(Annotation)?注解是放在Java源码的类、方法、字段、参数前的一种特殊“注释”
// this is a component:
@Resource("hello")
public class Hello {
@Inject
int n;
@PostConstruct
public void hello(@Param String name) {
System.out.println(name);
}
@Override
public String toString() {
return "Hello";
}
}
注释会被编译器直接忽略,注解则可以被编译器打包进入class文件,因此,注解是一种用作标注的“元数据”。
注解的作用
从JVM的角度看,注解本身对代码逻辑没有任何影响,如何使用注解完全由工具决定。
Java的注解可以分为三类:
- 由编译器使用的注解,
例如:
@Override:让编译器检查该方法是否正确地实现了覆写;
@SuppressWarnings:告诉编译器忽略此处代码产生的警告
这类注解不会被编译进class文件中。
- 第二类是由工具处理.class文件使用的注解,比如有些工具会在加载class的时候,对class做动态修改,实现一些特殊的功能。一般只被底层库使用,不必自己处理。
- 第三类是在程序运行期能够读取的注解,它们在加载后一直存在于JVM中,这也是最常用的注解。例如,一个配置了@PostConstruct的方法会在调用构造方法后自动被调用(这是Java代码读取该注解实现的功能,JVM并不会识别该注解)
定义一个注解时,还可以定义配置参数。配置参数可以包括:
所有基本类型; String; 枚举类型; 基本类型、String、Class以及枚举的数组。
public class Hello {
@Check(min=0, max=100, value=55)
public int n;
@Check(value=99)
public int p;
@Check(99) // @Check(value=99)
public int x;
@Check
public int y;
}
@Check就是一个注解。第一个@Check(min=0, max=100, value=55)明确定义了三个参数,第二个@Check(value=99)只定义了一个value参数,它实际上和@Check(99)是完全一样的。最后一个@Check表示所有参数都使用默认值。
定义注解
java 用@interface定义注解,然后添加参数、默认值:
public @interface Report {
int type() default 0;
String level() default "info";
String value() default "";
}
接着有一些可以用于注解的注解,成为元注解。如
@Target(ElementType.TYPE)
@Retention(RetentionPolicy.RUNTIME)
public @interface Report {
int type() default 0;
String level() default "info";
String value() default "";
}
@Target定义该注解能注解什么东西
类或接口:ElementType.TYPE;
字段:ElementType.FIELD;
方法:ElementType.METHOD;
构造方法:ElementType.CONSTRUCTOR;
方法参数:ElementType.PARAMETER。
@Retention定义该注解的生命周期,如上就是定义在runtime的时候运行,因为我们自己写的注解一般在runtime的时候执行。
仅编译期:RetentionPolicy.SOURCE;
仅class文件:RetentionPolicy.CLASS;
运行期:RetentionPolicy.RUNTIME。
其次还有@Repeatable定义该注解是否可以重复使用在同一个地方,@Inherited定义是否可以继承父类的注解。
处理注解
Java的注解本身对代码逻辑没有任何影响。根据@Retention的配置:
- SOURCE类型的注解在编译期就被丢掉了;
- CLASS类型的注解仅保存在class文件中,它们不会被加载进JVM;
- RUNTIME类型的注解会被加载进JVM,并且在运行期可以被程序读取。
使用注解
// 定义一个注解
@Retention(RetentionPolicy.RUNTIME) // runtime时运行,会打入jvm
@Target(ElementType.FIELD) // 作用于字段
@interface Range {
int min() default 0;
int max() default 255;
}
class Person1 {
@Range(min = 1, max = 20)
public String name;
@Range(max = 10)
public String city;
}
定义了注解,本身对程序逻辑没有任何影响。我们必须自己编写代码来使用注解。
void check(Person person) throws IllegalArgumentException, ReflectiveOperationException {
// 遍历所有Field:
for (Field field : person.getClass().getFields()) {
// 获取Field定义的@Range:
Range range = field.getAnnotation(Range.class);
// 如果@Range存在:
if (range != null) {
// 获取Field的值:
Object value = field.get(person);
// 如果值是String:
if (value instanceof String s) {
// 判断值是否满足@Range的min/max:
if (s.length() < range.min() || s.length() > range.max()) {
throw new IllegalArgumentException("Invalid field: " + field.getName());
}
}
}
}
}
集合
什么是集合(Collection)?集合就是“由若干个确定的元素所构成的整体”。
在Java中,如果一个Java对象可以在内部持有若干其他Java对象(注意是对象,而不是基础类型,比如Integer可以,但是int不行),并对外提供访问接口,我们把这种Java对象称为集合。很显然,Java的数组可以看作是一种集合:
String[] ss = new String[10]; // 可以持有10个String对象
ss[0] = "Hello"; // 可以放入String对象
String first = ss[0]; // 可以获取String对象
数组的限制,长度固定,数据只能通过索引获取。
我们需要各种不同类型的集合类来处理不同的数据,例如:
- 可变大小的顺序链表;
- 保证无重复元素的集合;
Collection
Java标准库自带的java.util包提供了集合类:Collection,它是除Map外所有其他集合类的根接口
ava的java.util包主要提供了以下三种类型的集合:
- List 一种有序列表的集合,例如,按索引排列的Student的List,如ArrayList, LinkedList
- Set 一种保证没有重复元素的集合,例如,所有无重复名称的Student的Set
- Map 一种通过键值(key-value)查找的映射表集合,例如,根据Student的name查找对应Student的Map
Java集合设计的特点
- 实现了 接口和 实现类 相分离,如有序表的接口是List,具体的实现类有ArrayList,LinkedList等
- 支持泛型 List list = new ArrayList<>(); // 只能放入String类型
- 访问集合都是通过迭代器(Iterator)的形式访问的,它最明显的好处在于无需知道集合内部元素是按什么方式存储的。(类似于js的实现Symbol.iterator,实现对象的迭代,外部无需知道他是怎么存储的。)
List
List是最基础的一种集合:它是一种有序列,数组和List非常相似。但是数组进行增删操作会非常麻烦。反观List
当我们需要增删操作的时候,可以使用ArrayList,
如 一个ArrayList拥有5个元素,实际数组大小为6(即有一个空位)
- 当添加一个元素并指定索引如2到ArrayList时,ArrayList自动移动需要移动的元素,把2及后面的元素移动。
- 然后,往内部指定索引的数组位置添加一个元素,然后把size加1
- 此时继续添加元素的时候,数组已满,没有空闲位置的时候,ArrayList先创建一个更大的新数组,然后把旧数组的所有元素复制到新数组,紧接着用新数组取代旧数组。
可见,ArrayList把添加和删除的操作封装起来,让我们操作List类似于操作数组,却不用关心内部元素如何移动。
List < T >主要的接口方法
在末尾添加一个元素:boolean add(E e)
在指定索引添加一个元素:boolean add(int index, E e)
删除指定索引的元素:E remove(int index)
删除某个元素:boolean remove(Object e)
获取指定索引的元素:E get(int index)
获取链表大小(包含元素的个数):int size()
上述是通过数组实现的List,实际上,使用链表也能实现。
在LinkedList中,它的内部每个元素都指向下一个元素:
┌───┬───┐ ┌───┬───┐ ┌───┬───┐ ┌───┬───┐
HEAD ──>│ A │ ●─┼──>│ B │ ●─┼──>│ C │ ●─┼──>│ D │ │
└───┴───┘ └───┴───┘ └───┴───┘ └───┴───┘
我们来比较一下ArrayList和LinkedList:
| 123 | ArrayList | LinkedList |
|---|---|---|
| 获取指定元素 | 速度很快 | 需要从头开始查找元素 |
| 添加元素到末尾 | 速度很快 | 速度很快 |
| 在指定位置添加/删除 | 需要移动元素 | 不需要移动元素 |
| 内存占用 | 少 | 较大 |
使用
List<String> list = new ArrayList<>();
list.add("apple");
list.add("pear");
List<String> list1 = new LinkedList<>();
list1.add("test1");
list1.add("test2");
// Java 9
List<Integer> list2 = List.of(1, 2, 5);
System.out.println(list);
System.out.println(list1);
遍历List,使用for循环
for (int i = 0; i < list.size(); i++) {
String s = list.get(i);
System.out.println(s);
}
这种方法并不推荐
一是代码复杂,二是因为get(int)方法只有ArrayList的实现是高效的,换成LinkedList后,索引越大,访问速度越慢。
要始终坚持使用迭代器Iterator来访问List。Iterator本身也是一个对象,但它是由List的实例调用iterator()方法的时候创建的。
for (Iterator<String> it = list.iterator();it.hasNext();) {
String s = it.next();
System.out.println(s);
}
调用iterator获取一个iterator对象,跟js的迭代器很类似。it.hasNext()判断是否还有下一个元素,it.next()返回下一个元素
以上是一种固定写法,第二个参数需要搭配it.hasNext()返回一个boolen判断是否继续循环。
Java的for each循环本身就可以帮我们使用Iterator遍历
for (String it1 : list1) {
System.out.println(it1);
}
可以直接遍历获取值。
实际上,只要实现了Iterable接口的集合类都可以直接用for each循环来遍历,Java编译器本身并不知道如何遍历集合对象,但它会自动把for each循环变成Iterator的调用,原因就在于Iterable接口定义了一个Iterator<E> iterator()方法,强迫集合类必须返回一个Iterator实例。
有点像js中,只要实现了Symbol.iterator方法的对象,就可以使用for of进行遍历。因为Symbol.iteraotr方法返回了一个迭代器对象。
List和Array互相转换
- 把List变为Array有三种方法,第一种是调用toArray()方法直接返回一个Object[]数组,不常用,因为类型可能会丢失
- 第二种方式是给toArray(T[])传入一个类型相同的Array,List内部自动把元素复制到传入的Array中。这里的T和List< E>不一样,所以toArray可以传其他类型的数组,但不兼容会报错。
List<String> list1 = new LinkedList<>();
list1.add("test1");
list1.add("test2");
String[] test2 = list1.toArray(new String[2]);
Integer[] test3 = list1.toArray(new Integer[2]); //会报错
传入的数组如果不够大,那么List内部会创建一个新的数组,大小一样。
如果传入的数组过大,那么多余的元素全部填充null。
Array to List
// JAVA 9
Integer[] array = { 1, 2, 3 };
List<Integer> list = List.of(array);
// JAVA 9 之前
List<String> list3 = Arrays.asList(test2);
注意,这种返回的List不一定是ArrayList或者LinkedList,因为返回的List是只读的,在操作会报错。’
编写equals方法
List提供了contains方法,来判断当前list是否包含哪些内容。提供了indexOf(obj)方法来判断obj在当前list的位置
List<String> list3 = new ArrayList<>();
list3.add("S");
list3.add("C");
System.out.println(list3.contains(new String("S"))); // true
System.out.println(list3.indexOf("S")); //0
这里contains我们传入了一个全新的String对象,但是结果还是为true,这是因为contains的实现是
public class ArrayList {
Object[] elementData;
public boolean contains(Object o) {
for (int i = 0; i < elementData.length; i++) {
if (o.equals(elementData[i])) {
return true;
}
}
return false;
}
}
拿传入的对象,调用其equals方法,所以,要向正确的使用contains和indexOf,传入的对象就必须正确的实现equals方法。而String和Integer等对象,java已经帮我们实现了equals方法。
如何编写equals方法
- 先确定实例“相等”的逻辑,即哪些字段相等,就认为实例相等;
- 用instanceof判断传入的待比较的Object是不是当前类型,如果是,继续比较,否则,返回false;
- 对引用类型用Objects.equals()比较,对基本类型直接用==比较。
class Person {
private String name;
private int age;
public Person(String name, int age) {
this.name = name;
this.age = age;
}
public boolean equals(Object o) {
if (o instanceof Person) {
Person p = (Person) o;
boolean nameEquals = false;
if (this.name == null && p.name == null) {
nameEquals = true;
}
if (this.name != null) {
nameEquals = this.name.equals(p.name);
}
return nameEquals && this.age == p.age;
}
return false;
}
// 使用Objects.equals()比较两个引用类型是否相等的目的是省去了判断null的麻烦。两个引用类型都是null时它们也是相等的。
public boolean equals1(Object o) {
if (o instanceof Person) {
Person p = (Person) o;
return Objects.equals(this.name, p.name) && this.age == p.age;
}
return false;
}
}
Map
有个需求,在存放Students 集合 List中查找一个名为小明的,查看他的成绩。
这时候我们需要遍历List,然后判断到name微小明的,就取他的成绩。这样效率很低。
而Map这种key value的形式刚好可以满足。
Map<String, Person> map = new HashMap<>();
map.put("lin", new Person("lin", 20));
Person Target = map.get("lin");
和List类似,Map也是一个接口,最常用的实现类是HashMap。如果只是想查询某个key是否存在,可以调用boolean containsKey(K key)方法。
其他与js的Map类似。
遍历
Person Target = map.get("lin");
for (String key : map.keySet()) {
System.out.println(key);
}
for (Map.Entry<String, Person> entry : map.entrySet()) {
String key = entry.getKey();
Person value = entry.getValue();
System.out.println(key);
System.out.println(value);
}
map.keySet()获取key,map.entrySet()获取key-value
- Map不保证顺序
编写equals 和 hashCode
Map之所以能很快通过key获取value,是因为内部通过空间换时间的处理。
Map内部用很大的数组存放数据,然后通过特殊的计算,比如f函数 f(key) = index,传入同一个key,index总是相同的,然后通过index存放value,取数据的时候也是通过f(key) = index计算出index,然后通过数组[index]去获取数据。但这样有个问题,如果传入的两个key是不同的对象呢。
Map<String, String> map2 = new HashMap<>();
map2.put("2", "123");
System.out.println(map2.get(new String("2"))); // 123
传入不同的String还是能拿到正确的值,因为跟List一样,key值得比对也是通过equals方法。
其次,通过key获取index是通过hashCode方法获取的,
正确使用Map必须保证:
- 作为key的对象必须正确覆写equals()方法,相等的两个key实例调用equals()必须返回true;
- 作为key的对象还必须正确覆写hashCode()方法,且hashCode()方法要严格遵循以下规范:
- 如果两个对象相等,则两个对象的hashCode()必须相等;
- 如果两个对象不相等,则两个对象的hashCode()尽量不要相等
public class Person {
String firstName;
String lastName;
int age;
@Override
int hashCode() {
int h = 0;
h = 31 * h + firstName.hashCode();
h = 31 * h + lastName.hashCode();
h = 31 * h + age;
return h;
}
}
// 借助Objects.hash
int hashCode() {
return Objects.hash(firstName, lastName, age);
}
equals()用到的用于比较的每一个字段,都必须在hashCode()中用于计算;
equals()中没有使用到的字段,绝不可放在hashCode()中计算。
这里注意,两个对象的hashCode尽量不要想等,也就是有可能相等。
我们把不同的key具有相同的hashCode()的情况称之为哈希冲突。在冲突的时候,一种最简单的解决办法是用List存储hashCode()相同的key-value。显然,如果冲突的概率越大,这个List就越长,Map的get()方法效率就越低,这就是为什么要尽量满足条件二。

hashCode()方法编写得越好,HashMap工作的效率就越高。
计算hash code,相同hash code用一个List存放。
EnumMap
HsahMap通过空间换时间,计算index从数组直接拿数据。
如果key是Enum的话,可以用EnumMap ,在内部以一个非常紧凑的数组存储value,并且根据enum类型的key直接定位到内部数组的索引,并不需要计算hashCode(),不但效率最高,而且没有额外的空间浪费。
public class Main {
public static void main(String[] args) {
Map<DayOfWeek, String> map = new EnumMap<>(DayOfWeek.class);
map.put(DayOfWeek.MONDAY, "星期一");
map.put(DayOfWeek.TUESDAY, "星期二");
map.put(DayOfWeek.WEDNESDAY, "星期三");
map.put(DayOfWeek.THURSDAY, "星期四");
map.put(DayOfWeek.FRIDAY, "星期五");
map.put(DayOfWeek.SATURDAY, "星期六");
map.put(DayOfWeek.SUNDAY, "星期日");
System.out.println(map);
System.out.println(map.get(DayOfWeek.MONDAY));
}
}
TreeMap
HashMap无序,还有一种Map,它在内部会对Key进行排序,这种Map就是SortedMap。注意到SortedMap是接口,它的实现类是TreeMap。
┌───┐
│Map│
└───┘
▲
┌────┴─────┐
│ │
┌───────┐ ┌─────────┐
│HashMap│ │SortedMap│
└───────┘ └─────────┘
▲
│
┌─────────┐
│ TreeMap │
└─────────┘
SortedMap保证遍历时以Key的顺序来进行排序。例如,放入的Key是"apple"、“pear”、“orange”,遍历的顺序一定是"apple"、“orange”、“pear”,因为String默认按字母排序
public static void main(String[] args) {
Map<String, Integer> map = new TreeMap<>();
map.put("orange", 1);
map.put("apple", 2);
map.put("pear", 3);
for (String key : map.keySet()) {
System.out.println(key);
}
// apple, orange, pear
}
TreeMap要求实现Comparable方法
没有的话需要在使用TreeMap的时候指定排序方法,
public class Main {
public static void main(String[] args) {
Map<Person, Integer> map = new TreeMap<>(new Comparator<Person>() {
public int compare(Person p1, Person p2) {
return p1.name.compareTo(p2.name);
}
});
map.put(new Person("Tom"), 1);
map.put(new Person("Bob"), 2);
map.put(new Person("Lily"), 3);
for (Person key : map.keySet()) {
System.out.println(key);
}
// {Person: Bob}, {Person: Lily}, {Person: Tom}
System.out.println(map.get(new Person("Bob"))); // 2
}
}
Comparator接口要求实现一个比较方法,它负责比较传入的两个元素a和b,如果a<b,则返回负数,通常是-1,如果a==b,则返回0,如果a>b,则返回正数,通常是1。TreeMap内部根据比较结果对Key进行排序
- SortedMap在遍历时严格按照Key的顺序遍历,最常用的实现类是TreeMap;
- 作为SortedMap的Key必须实现Comparable接口,或者传入Comparator;
- 要严格按照compare()规范实现比较逻辑,否则,TreeMap将不能正常工作。
Set
不重复的集合,且不需要value,类似于js的Set
Set<String> set = new HashSet<>();
System.out.println(set.add("abc")); // true
System.out.println(set.add("xyz")); // true
System.out.println(set.add("xyz")); // false,添加失败,因为元素已存在
System.out.println(set.contains("xyz")); // true,元素存在
System.out.println(set.contains("XYZ")); // false,元素不存在
System.out.println(set.remove("hello")); // false,删除失败,因为元素不存在
System.out.println(set.size()); // 2,一共两个元素
set.add, set.contains, set.remove, set.resize
Set实际上相当于只存储key、不存储value的Map。我们经常用Set用于去除重复元素。
因为放入Set的元素和Map的key类似,都要正确实现equals()和hashCode()方法,否则该元素无法正确地放入Set
HashSet其实是封装HashMap
public class HashSet<E> implements Set<E> {
// 持有一个HashMap:
private HashMap<E, Object> map = new HashMap<>();
// 放入HashMap的value:
private static final Object PRESENT = new Object();
public boolean add(E e) {
return map.put(e, PRESENT) == null;
}
public boolean contains(Object o) {
return map.containsKey(o);
}
public boolean remove(Object o) {
return map.remove(o) == PRESENT;
}
}
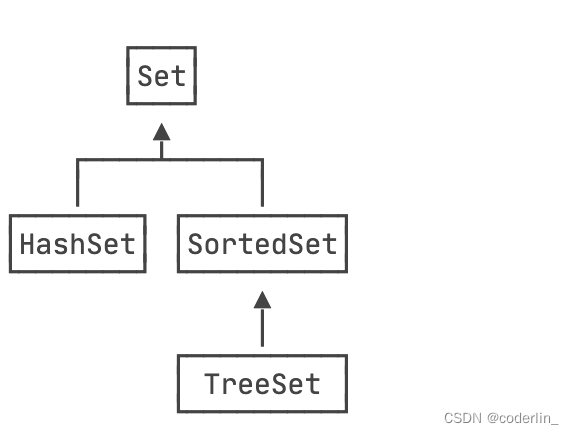
HasHSet是无序的,而SortedSet是有序的,但他只是个接口,实现的类是TreeSet
public class Main {
public static void main(String[] args) {
Set<String> set = new TreeSet<>();
set.add("apple");
set.add("banana");
set.add("pear");
set.add("orange");
for (String s : set) {
System.out.println(s);
}
}
}
使用TreeSet和使用TreeMap的要求一样,添加的元素必须正确实现Comparable接口,如果没有实现Comparable接口,那么创建TreeSet时必须传入一个Comparator对象。
Queue
队列,先进先出
它和List的区别在于,List可以在任意位置添加和删除元素,而Queue只有两个操作:
把元素添加到队列末尾;
从队列头部取出元素。
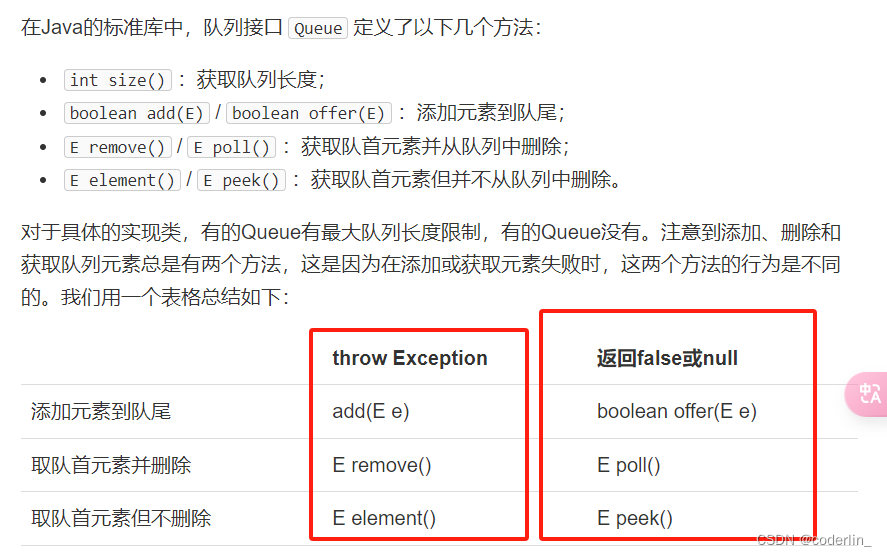
这些操作有两个方法,一个会抛出错误,一个返回false/null。
// 这是一个List:
List<String> list = new LinkedList<>();
// 这是一个Queue:
Queue<String> queue = new LinkedList<>();
LinkedList(链表)类实现了Queue接口和List接口
PriorityQueue
上述的Queue是先进先出,但是如果有优先级的处理,就像react中优先级高的渲染,就出现了优先级队列PriorityQueue,
PriorityQueue和Queue的区别在于,它的出队顺序与元素的优先级有关,对PriorityQueue调用remove()或poll()方法,返回的总是优先级最高的元素。(react-sceduler的实现类似)
public class Main {
public static void main(String[] args) {
Queue<String> q = new PriorityQueue<>();
// 添加3个元素到队列:
q.offer("apple");
q.offer("pear");
q.offer("banana");
// 按照元素顺序
System.out.println(q.poll()); // apple
System.out.println(q.poll()); // banana
System.out.println(q.poll()); // pear
System.out.println(q.poll()); // null,因为队列为空
}
}
放入PriorityQueue的元素,必须实现Comparable接口,PriorityQueue会根据元素的排序顺序决定出队的优先级。
也可以在创建PriorityQeue的时候提供一个comparator对象来判断两个元素的顺序,跟TreeMap类似。
public class Main {
public static void main(String[] args) {
Queue<User> q = new PriorityQueue<>(new UserComparator());
// 添加3个元素到队列:
q.offer(new User("Bob", "A1"));
q.offer(new User("Alice", "A2"));
q.offer(new User("Boss", "V1"));
System.out.println(q.poll()); // Boss/V1
System.out.println(q.poll()); // Bob/A1
System.out.println(q.poll()); // Alice/A2
System.out.println(q.poll()); // null,因为队列为空
}
}
class UserComparator implements Comparator<User> {
public int compare(User u1, User u2) {
if (u1.number.charAt(0) == u2.number.charAt(0)) {
// 如果两人的号都是A开头或者都是V开头,比较号的大小:
return u1.number.compareTo(u2.number);
}
if (u1.number.charAt(0) == 'V') {
// u1的号码是V开头,优先级高:
return -1;
} else {
return 1;
}
}
}
Deque双端队列
,允许两头都进,两头都出,这种队列叫双端队列
Java集合提供了接口Deque来实现一个双端队列,它的功能是:
既可以添加到队尾,也可以添加到队首;
既可以从队首获取,又可以从队尾获取。
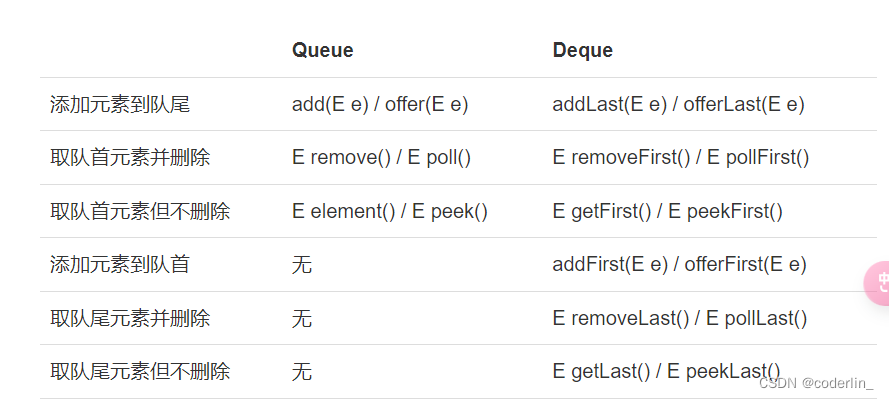
Deque是一个接口,它的实现类有ArrayDeque和LinkedList。
Stack 先进后出

将十进制转为16进制
public static void main(String[] args) {
String hex = toHex(12500);
System.out.println(hex);
if (hex.equalsIgnoreCase("30D4")) {
System.out.println("测试通过");
} else {
System.out.println("测试失败");
}
}
static String toHex(int n) {
Deque<String> dq = new LinkedList<>();
int num = n % 16;
int num1 = n / 16;
while (num1 != 0) {
dq.addFirst(Integer.toHexString(num));
num = num1 % 16;
num1 = num1 / 16;
}
dq.addFirst(Integer.toHexString(num));
String result = "";
String s = dq.pollFirst();
System.out.println(s);
while (s != null) {
result += s;
s = dq.pollFirst();
}
return result;
}
循环求余数压入栈中,再循环取出。
Iterator
Java的集合类都可以使用for each循环,List、Set和Queue会迭代每个元素,Map会迭代每个key。因为他们都实现了Iterator对象
Java编译器并不知道如何遍历List。上述代码能够编译通过,只是因为编译器把for each循环通过Iterator改写为了普通的for循环:
for (Iterator<String> it = list.iterator(); it.hasNext(); ) {
String s = it.next();
System.out.println(s);
}
for (String s : list) {
System.out.println(s);
}
类似于js的Symbol.Iterator迭代器,只要实现了Symbol.iterator,就可以用for of循环。
实现一个集合,需要实现他的Iterator方法,并且返回一个Iterator对象
class ReverseList<T> implements Iterable<T> {
private List<T> list = new ArrayList<>();
public void add(T t) {
list.add(t);
}
@Override
public Iterator<T> iterator() {
return new ReverseIterator(list.size());
}
class ReverseIterator implements Iterator<T> {
int index;
ReverseIterator(int index) {
this.index = index;
}
@Override
public boolean hasNext() {
return index > 0;
}
@Override
public T next() {
index--;
return ReverseList.this.list.get(index);
}
}
}
可以看到迭代器主要实现hasNext方法和next方法。js的Symbol.Iterator则是实现{done: ture, value: ‘’}来判断是否已经遍历结束。
Collections
Collections是JDK提供的工具类,同样位于java.util包中。它提供了一系列静态方法,能更方便地操作各种集合。
// 空集合
List<String> list2 = Collections.emptyList(); // 返回不可变List
// 单元素集合
List<String> list3 = Collections.singletonList("apple"); // 返回不可变List
List<String> list4 = Arrays.asList("1230", "456", "132"); // 返回不可变List
// 排序
Collections.sort(list4); // 排序回修改List元素的位置,所以需要传入可变List
System.out.println(list4);
Collections.shuffle(list4); // 打乱List的顺序
System.out.println(list4);
// 变为不可变集合 假设List4是可变List
List<String> list5 = Collections.unmodifiableList(list4);
// list5.add("orange"); // UnsupportedOperationException!
list4.add("2222");
list4 = null; // 转变后立马扔掉老的引用
System.out.println(list5); // 老的List修改影响不可变List
小结
List
- Java集合使用统一的Iterator遍历
- 有序集合 List -> ArrayList(通过数组实现,) LinkedList(通过链表实现),可以用for each遍历。存放List的对象需要实现equals方法,便于调用List的contains和indexOf方法。
Map
-
key-value 映射表 -> Map , Map集合无序,可以通过for each遍历keySet(),也可以通过for each遍历entrySet(),直接获取key-value。最常用的Map就是HashMap
-
HashMap通过数组的形式存放,调用key.hashCode()获取索引,通过key.equals()判断是否相等,所以HashMap存放到对象需要实现hashCode和equals方法,而且equals方法返回true,则hashCode返回的索引一定相等,如果equals返回false,那么hashCode返回的值尽两不要相等。
- 但是万一相等了呢,HashMap的数组存放的是List<Entry<string, Object>>,当不同的key的HashCode返回的索引相等的时候,会拿到一个List,再通过key.equlas去获取到对应的值。
-
如果Map的key是enum类型,推荐使用EnumMap,既保证速度,也不浪费空间。使用EnumMap的时候,根据面向抽象编程的原则,应持有Map接口。
-
HashMap是无序的,但是Map下面还有一个SortedMap接口,TreeMap类实现了这个接口,他是有序的。
- TreeMap怎么排序呢,通过存放的每个对象实现一个comparable接口,或者在定义TreeMap的时候,指定一个自定义排序算法
-
Map<Person, Integer> map = new TreeMap<>(new Comparator<Person>() { public int compare(Person p1, Person p2) { return p1.name.compareTo(p2.name); } }); - Comparator接口要求实现一个比较方法,它负责比较传入的两个元素a和b,如果a<b,则返回负数,通常是-1,如果a==b,则返回0,如果a>b,则返回正数,通常是1。TreeMap内部根据比较结果对Key进行排序。
Set
- 只需要存储不重复的key,并不需要存储映射的value,那么就可以使用Set。
- 最常用的Set是HashSet,他是HashMap的封装
- 此外HashSet是无序的,但同时,SrotedSet是有序的,他是一个接口,TreeSet实现了这个接口
- 跟TreeMap一样,TreeSet也要求一个compator接口,来判断两个对象的顺序。
Queue 通过LinkedList类实现该接口
- 队列先进先出,通过add()/offer()方法将元素添加到队尾
- 通过remove/poll获取队首元素并挪去。
- 通过element()/peek()获取队首元素但不去掉。
- 前面的add/remove/eleemtn执行出错会报错,而offer/poll/peek只返回对应的false/null
- PriorityQueue优先级队列,优先级队列需要实现Comparable接口,priorityQueue根据元素的优先顺序决定谁先出队。
- PriorityQueue默认按元素比较的顺序排序(必须实现Comparable接口),也可以通过Comparator自定义排序算法(元素就不必实现Comparable接口)。
Deque 双头队列 也是LinkedList实现
- Deque其实也是继承于Queue的
- addLast/offerLast addFirst/offerFirst 从队头/队尾插入
- removeFirst/pollFirst removeLast/pollLast 从对头/队尾取出并删除
- getFirst/peekFirst getLast/peekLast 从对头/队尾取出但不删除
Stack 栈,先进后厨
- 利用Deque实现栈即可
- 只调用对应的offerFirst/peekFirst/getFirst三个方法。
- Stack作用很大,比如计算机调用方法通过执行栈维护等等
Iterator
Iterator是一种抽象的数据访问模型。使用Iterator模式进行迭代的好处有:
- 对任何集合都采用同一种访问模型;
- 调用者对集合内部结构一无所知;
- 集合类返回的Iterator对象知道如何迭代。
- Java提供了标准的迭代器模型,即集合类实现java.util.Iterable接口,返回java.util.Iterator实例。
Collections
Collections类提供了一组工具方法来方便使用集合类:
- Collections.emptyList()创建空集合 返回不可变集合
- Collections.singletonList(“test”)创建单个集合 返回不可变集合
- Collections.unmodifiableList(可变集合),将可变集合变成不可变集合
- Collections.sort()排序集合, Collections.shuffle() 将集合的顺序重新打乱(洗牌)